Andrej Karpathy-MicroGrad
2.5 hr video of micrgrad.
I wish I could’ve watched this video 5 yrs earlier! It clears out so many questions about loss.backward()!
1 Some Python notes
I actually learn quite some about Python operations here :)
def __repr__(self):
# will be used to call the object itself
def __add__(self, other):
# a+b == a.__add__(b)
# make sure a + 1 works
other = other if isinstance(other, Value) else Value(other)
# Make sure 1 + a works
def __radd__(self, other): # other + self
return self + other
def __mul__(self, other):
# make sure a * 2 works
other = other if isinstance(other, Value) else Value(other)
# a*b == a.__mul__(b)
# Make sure 2 * a works
def __rmul__(self, other): # other * self
return self * other
# Define division
def __truediv__(self, other): #self / other
return self * other ** -1
# Define substraction
def __neg__(self): #-self
return self * -1
def __sub__(self, other): # self - other
return self + (-other)
2 Gradients
The fundamental idea is to apply chain rules. Here are some exampels of find gradients of exp and power functions
def exp(self):
x = self.data
out = Value(math.exp(x), (self, ), 'exp')
def _backward():
self.grad += out.data * out.grad
out._backward = _backward
return out
def __pow__(self, other):
assert isinstance(other, (int, float)), "only supporting int/float powers for now"
out = Value(self.data**other, (self,), f'**{other}')
def _backward():
self.grad += other * (self.data ** (other - 1)) * out.grad
out._backward = _backward
return out
3 Backpropogation
- Define
_backpropfor each operation, to get thegradforselfand/orother
def __add__(self, other):
...
def _backward():
self.grad += 1.0 * out.grad
other.grad += 1.0 * out.grad
out._backward = _backward
return out
def __mul__(self, other):
...
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
- Accumulate grads
use+=instead of= - Topological sort
topo = [] visited = set() def build_topo(v): if v not in visited: visited.add(v) for child in v._prev: build_topo(child) topo.append(v) build_topo(self) - Traversal the reversed list
def backward(self): # Alwasy starts with 1.0 self.grad = 1.0 for node in reversed(topo): node._backward()
4 Pytorch implementation
# Python by default uses Double
x1 = torch.Tensor([2.0]).double()
# Force to get grad. for this variable
x1.requires_grad = True
# Get the value by call .item()
print('x1', x1.grad.item())
5 NN implementation
- Neron
def __call__(self, x): # w * x + b # Sum needs () for generators # Sum takes a 2nd param as starting point act = sum((wi*xi for wi, xi in zip(self.w, x)), self.b) out = act.tanh() return out - Layer
class Layer: def __init__(self, nin, nout): self.neurons = [Neuron(nin) for _ in range(nout)] def __call__(self, x): outs = [n(x) for n in self.neurons] return outs[0] if len(outs) == 1 else outs - MLP
class MLP:
def __init__(self, nin, nouts):
# nin is integer of input dim
# nouts is List of layers
sz = [nin] + nouts
self.layers = [Layer(sz[i], sz[i+1]) for i in range(len(nouts))]
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x
6 Gradient Desceond Updates
- find all the parameters from neurons
# Only W and B in Neuron def parameters(self): return self.w + [self.b] # Two loops in list comprehension def parameters(self): return [p for neuron in self.neurons for p in neuron.parameters()] # Two loops in list comprehension def parameters(self): return [p for layer in self.layers for p in layer.parameters()] - Find the loss and backprop to get all the grads
# Get the predictions
ypred = [n(x) for x in xs]
# Square root loss
loss = sum((yout - ygt)**2 for ygt, yout in zip(ys, ypred))
loss.backward()
- GD updates
#Just update the data by NEGATIVE learning rate x grad. for p in n.parameters(): p.data += -0.1 * p.grad - A common BUG!
Item 3 here!
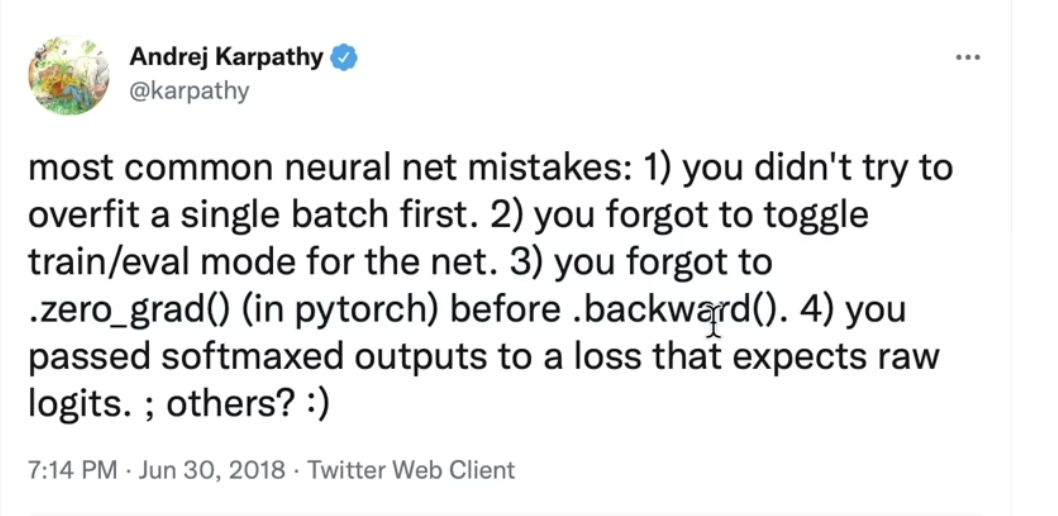
# Pytorch zero_grad()
for p in n.parameters():
p.grad = 0.0
loss.backward()