Llama2 tricks
A good youtube video explained several tricks applied in Llama2
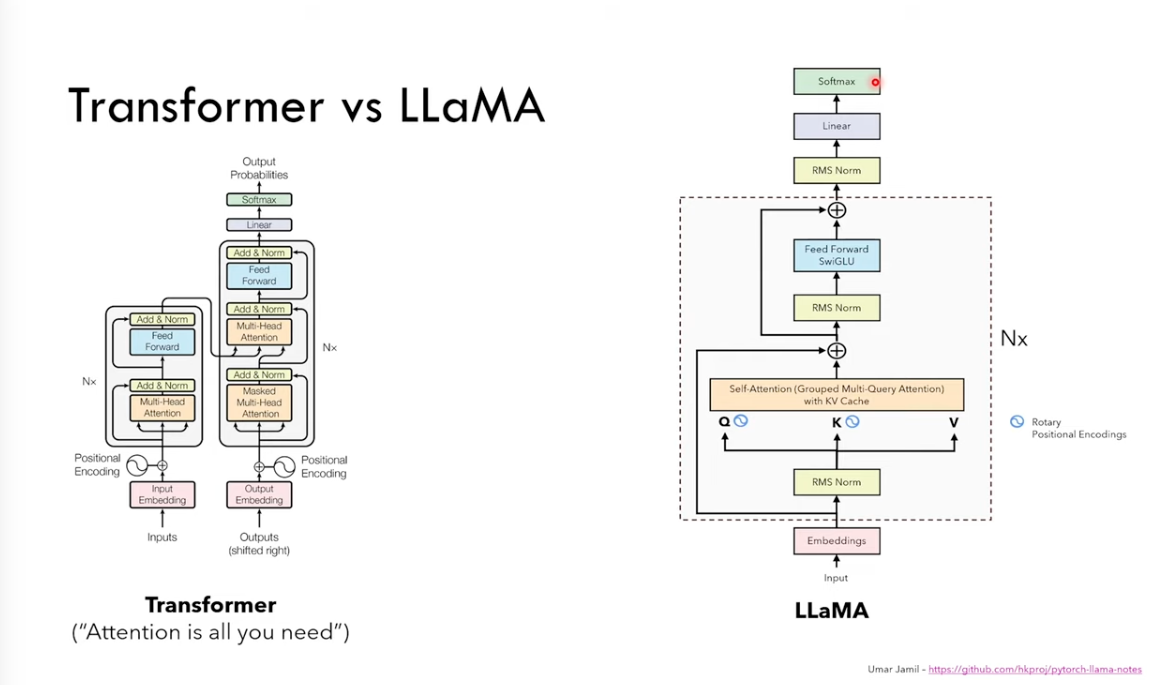 Here is the study notes.
Here is the study notes.
1. Layer normalization
Batch norm: normalized by columns (same feature, different data)
Layer norm: normalized by rows (same data, different features)
It can help to solve Internal Covariate Shift, which means drastically changes in the output, and it leads to drastically changes in input in the next layer
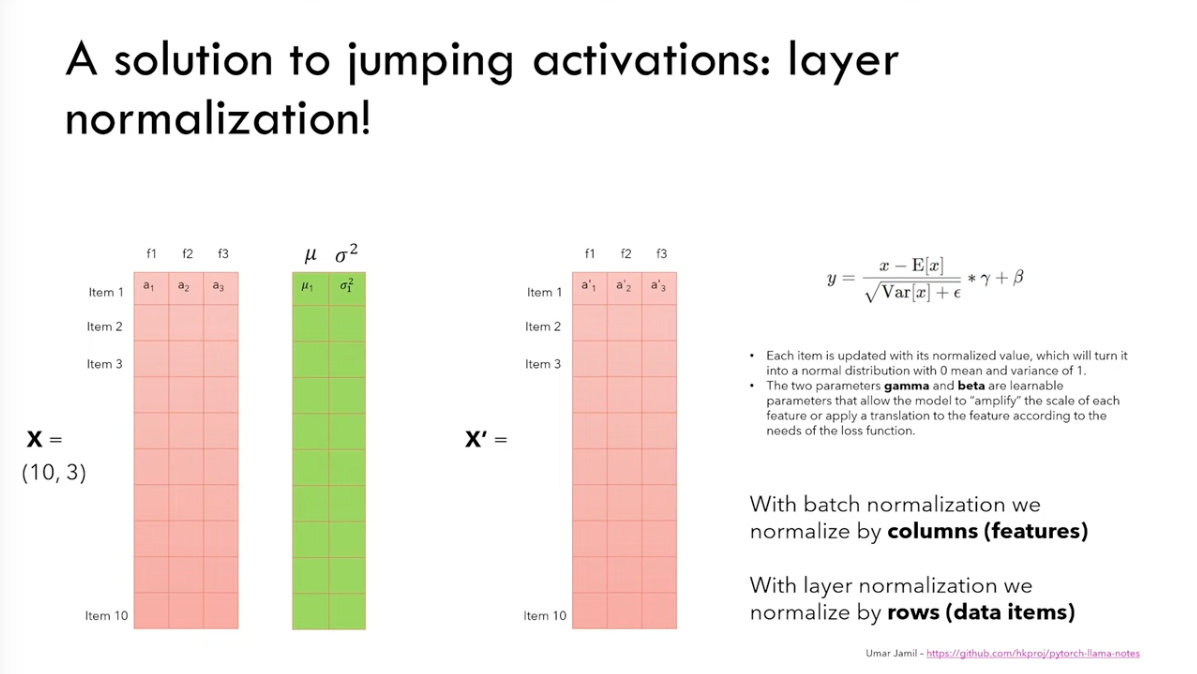 Rescale is more important than re-center, which leads to RMSnorm
Rescale is more important than re-center, which leads to RMSnorm

2. RoPE
RoPE(Rotary Position Encoding) is based on relative position encoding
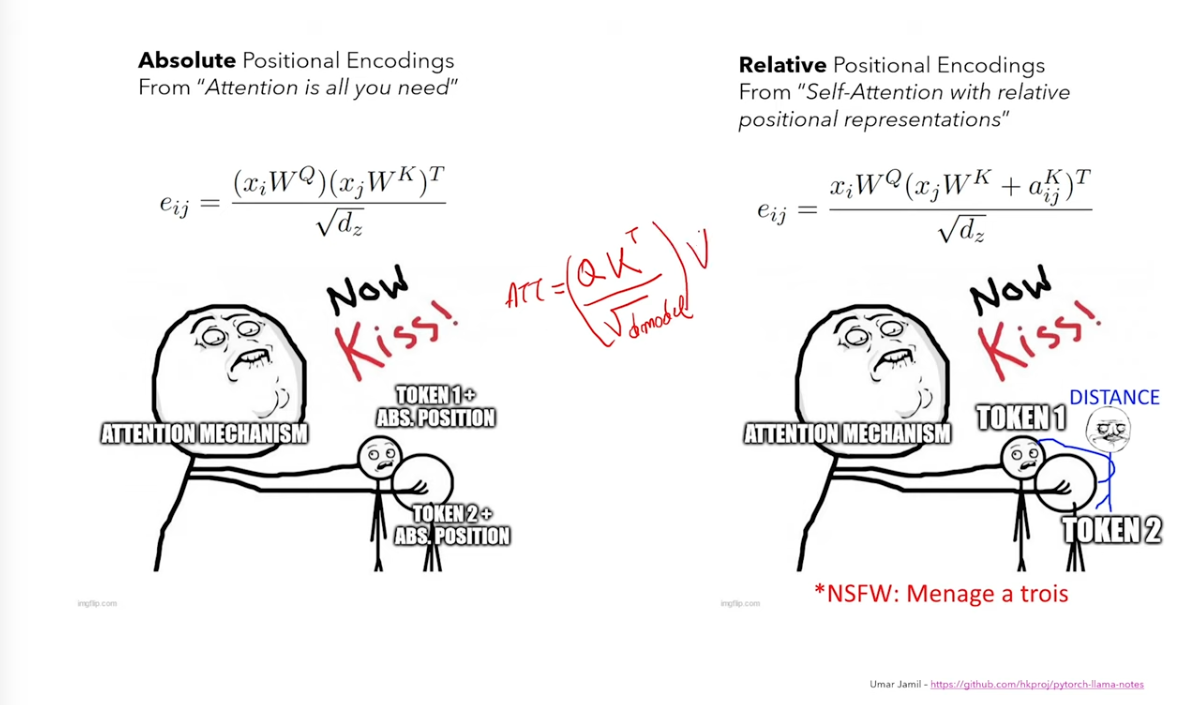
 Absolute encoding is added to embeddings
Absolute encoding is added to embeddings
 Relative encoding is added to the key matrix, making it menage a trios
Relative encoding is added to the key matrix, making it menage a trios
 RoPE is introduced in following paper, from a Chinese company called Zhuiyi(追一)
RoPE is introduced in following paper, from a Chinese company called Zhuiyi(追一)
 And when trying find a formula for the relative position, we actually introduced the rotary formula, that’s how it gets the name
And when trying find a formula for the relative position, we actually introduced the rotary formula, that’s how it gets the name

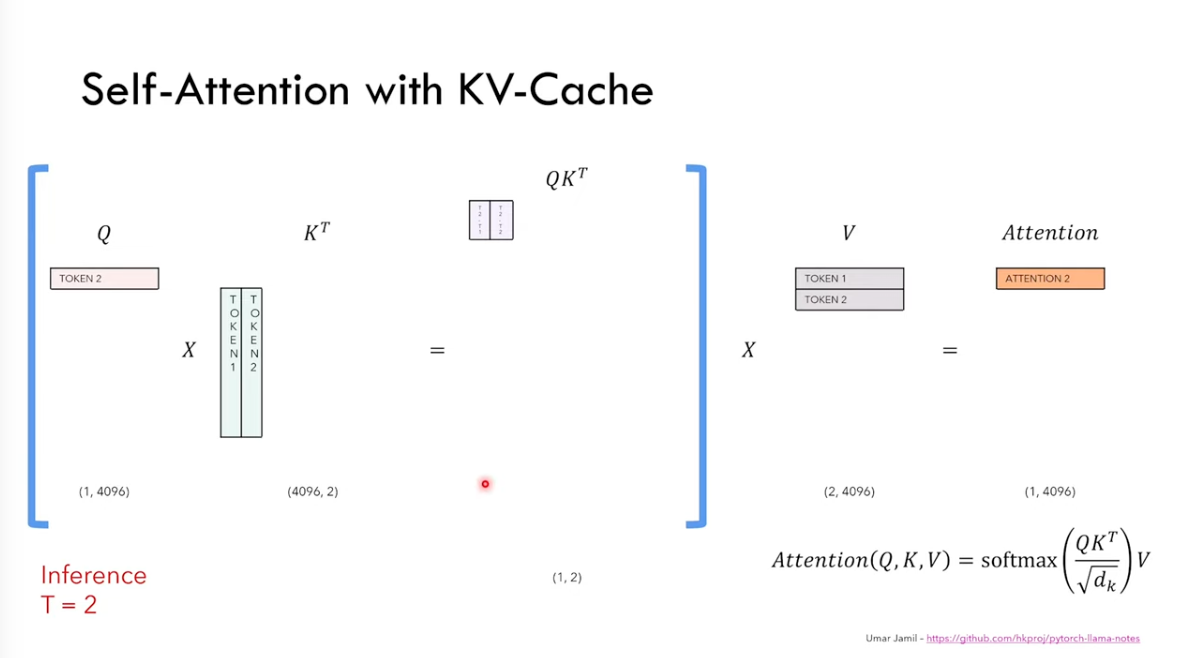
3. KV Cache
To avoid repeatly calculation for previous tokens, we cache the calculated results
 For regular inferences, tokens are repeatly calculated
For regular inferences, tokens are repeatly calculated
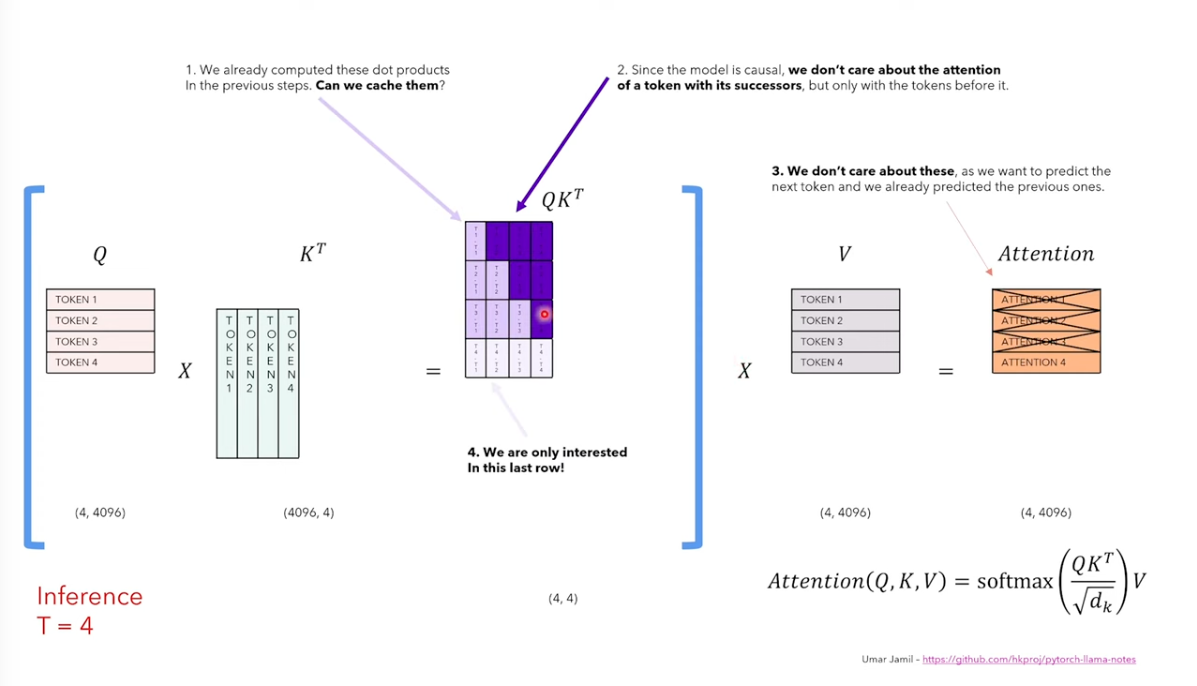 With KV cache, only the output token are put into next rounds’ calculation
With KV cache, only the output token are put into next rounds’ calculation

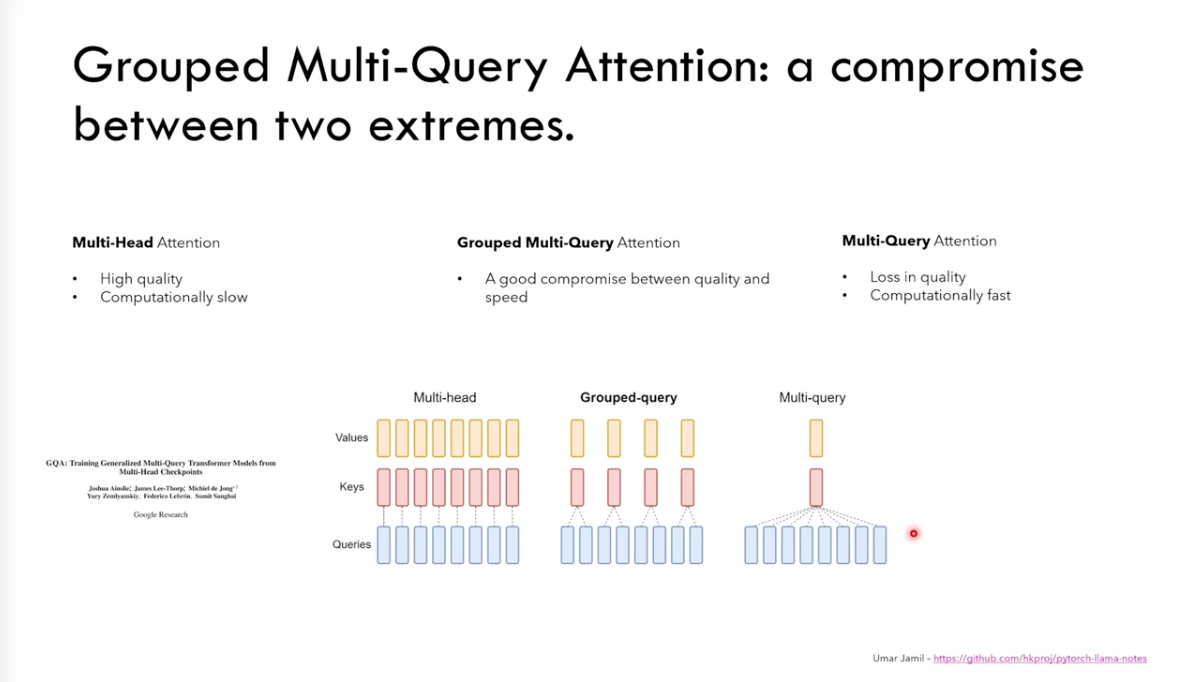
4.MQA
MQA(Multi-Query Attention) is paper from Noam Shazeer, who is the CEO of Character.ai, and author for transformers’ paper and who invented multi-head attention.
 The GPU is too fast for the memory bandwidth to catchup
The GPU is too fast for the memory bandwidth to catchup
 This is NOT a problem for vanilla transformers
This is NOT a problem for vanilla transformers
 But for mutli-head transformers, which is used in practice, the ratio O(n/d+1/b) may become bottle neck
But for mutli-head transformers, which is used in practice, the ratio O(n/d+1/b) may become bottle neck
 MQA is the solution here, which removes h dimension from K and V, but only keeps in Q
MQA is the solution here, which removes h dimension from K and V, but only keeps in Q
 From the comparison below, you can see Grouped Multi-Query is the combination of multi-qeury and multi-head transformers.
From the comparison below, you can see Grouped Multi-Query is the combination of multi-qeury and multi-head transformers.
5. SwiGLU
This is from Noam again
 It’s actually an activation function with modification from Sigmoid.
It’s actually an activation function with modification from Sigmoid.
 Here is the most interesting results, why does this method work? It’s divine benevolence
Here is the most interesting results, why does this method work? It’s divine benevolence
