Vision LLM
I was busy working on Dynamo related projects so didn’t work on vLLM for a while. I wanted to pick it up again with adding support to NV-Nemotron-VL model but had so many concepts need to clarify before I can make some progress. So here is a good summary from the blog of Nvidian Jian Hu. Also some details from zhihu
Update: This one single post from zhihu is one really good resource for data processing details
1 Image Processor
VLLM cuts image, into square patches with size (patch_size * patch_size), patch_size=14. It either
- Resize image so that both h/w are integer of patch size
- (count_h * patch_size) x (count_w * patch_size)
- Find the closest aspect ratio for tiles of size (SxS),S=448, with num of tiles $n_{tiles}$ (12) (dynamo resolution)
- with 12 tiles, will have 35 candidat ratios
- List all ratios $i/j$ for $i*j\in[n_{min}, n_{max}]$ ([1/1],[1/2]..[2/6])
-
$r_{best}=\argmin W/H-r_{target} $ - $W_{new}=S\times i_{best},H_{new}=S\times j_{best}$
Here is an example of resize a 800x1300 image.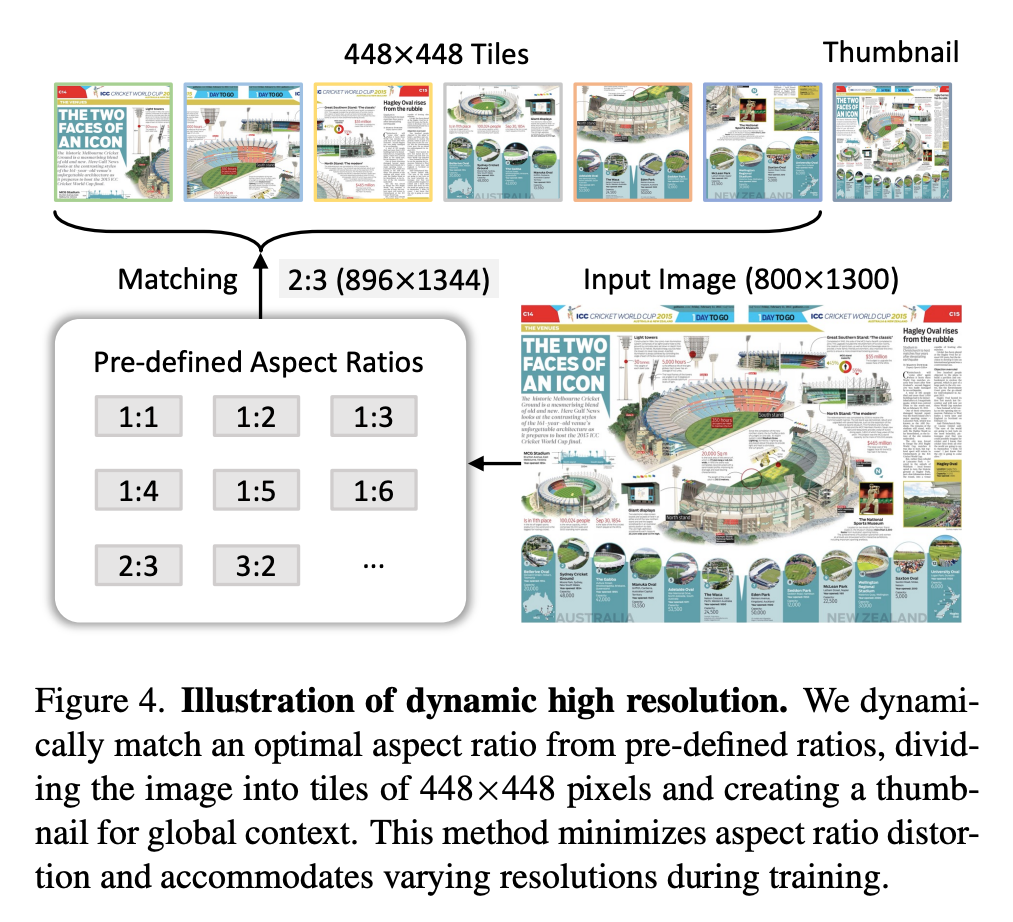 For video, add a temporal dimentsion with patch size
For video, add a temporal dimentsion with patch size self.temporal_patch_size = 2.# This is key to understanding what the image processor is doing flatten_patches = patches.reshape( grid_t * grid_h * grid_w, channel * self.temporal_patch_size * self.patch_size * self.patch_size )Qwen2-VL “stack” images into 2 frames, creating “two-frame identical” videolets, allowing images and videos to use the same patch segmentation methods.
if patches.shape[0] == 1: # This step duplicates the image along the temporal dimension, creating a "2-frame small video" patches = np.tile(patches, (self.temporal_patch_size, 1, 1, 1))
2 Video Encoding
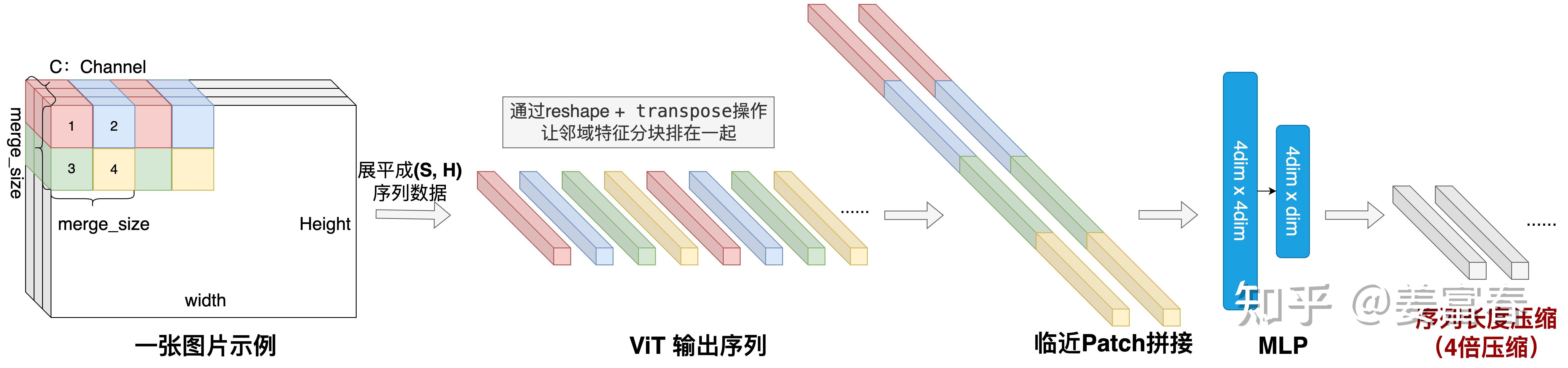
All the patches will be merged by 4. That’s why the pixels sizes are multiple of 4. and the LLM dim length is 1/4 of patch length.
preprocessor_config.json
{
"min_pixels": 3136,
"max_pixels": 12845056, # 12845056 / 14 / 14 = 65536 (4*16384)
}
# h1 = mlp(f1 , f2 , f5 , f6)
# h2 = mlp(f3 , f4 , f7 , f8)
# h3 = mlp(f9 ,f10 , f13 , f14)
# h4 = mlp(f11 , f12 , f15 , f16)
feature = [ h1 , h2 , h3 , h4 ]
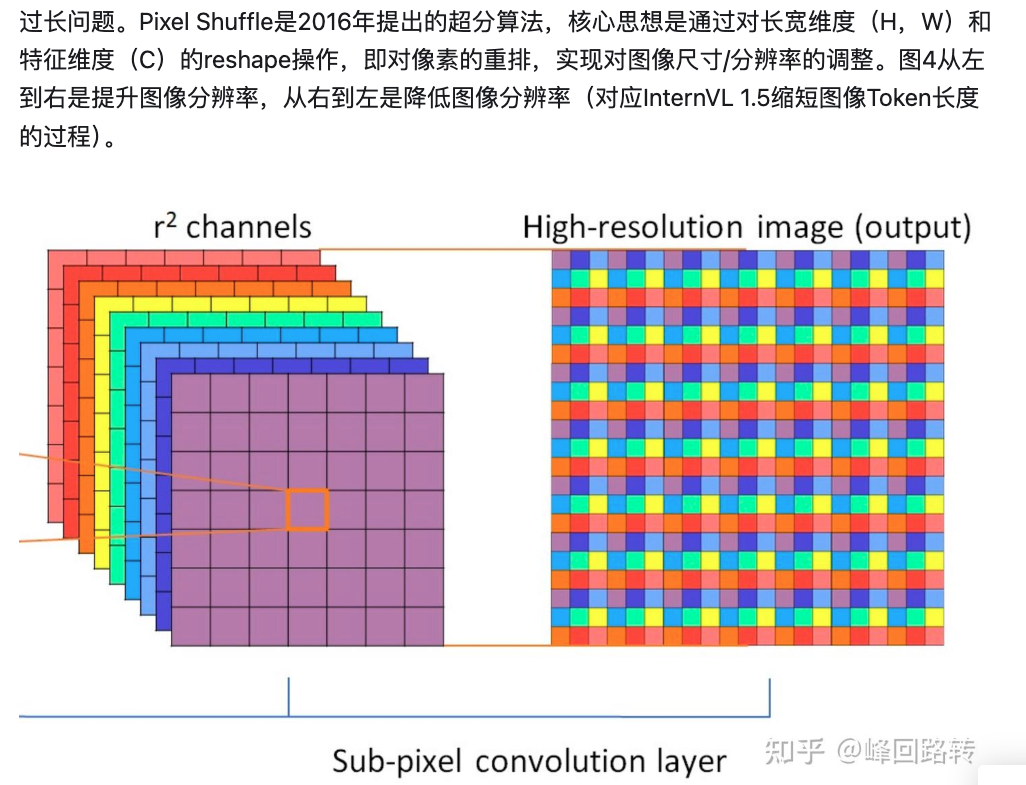
Intern2.5VL uses pixel shuffle to achieve similar effect
with upscale_factor = 0.5
![]()
Use 800x1300 picture as an examples
- Original reshape to 448x448, has 1024 tokens(448/14=32, 32x32=1024)
- Dynamic resolution reshpae to (448x2 x 448x3), has 6*1024 + 1024 tokens (one more 448x448 thumbnail)
- So 7x tokens. But use pixel shuffle can reduce to 1/4 as before
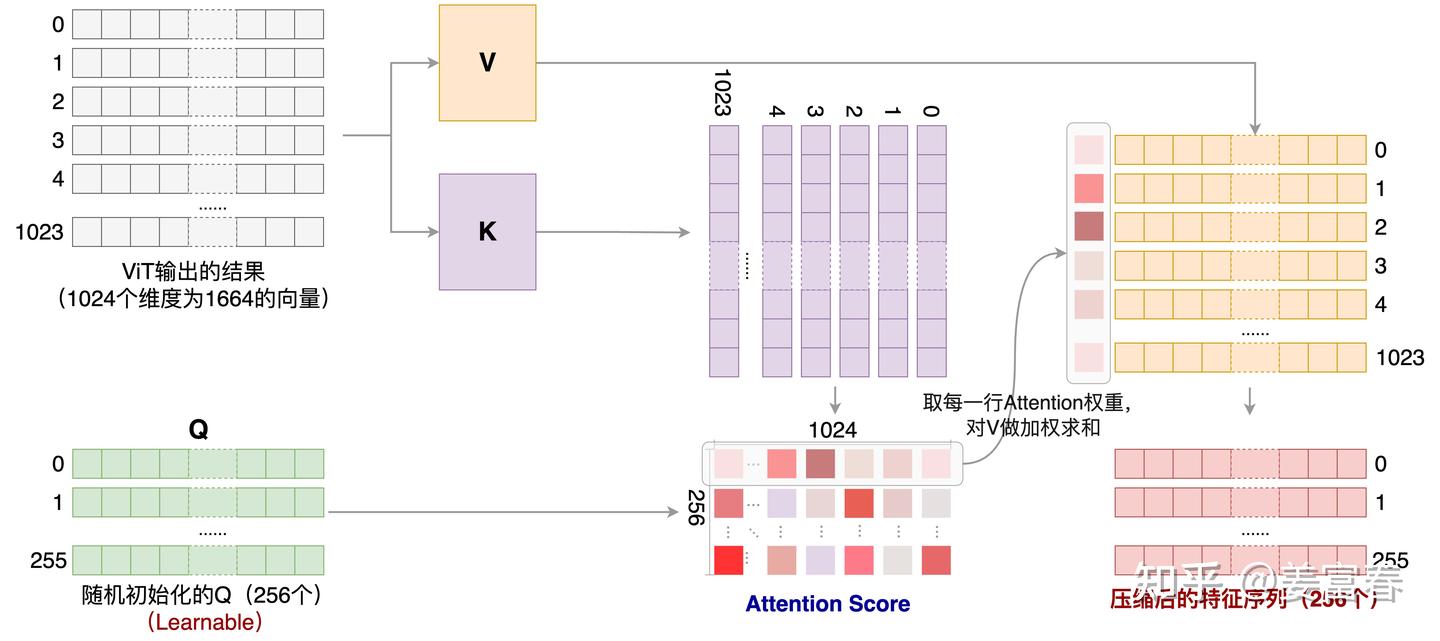
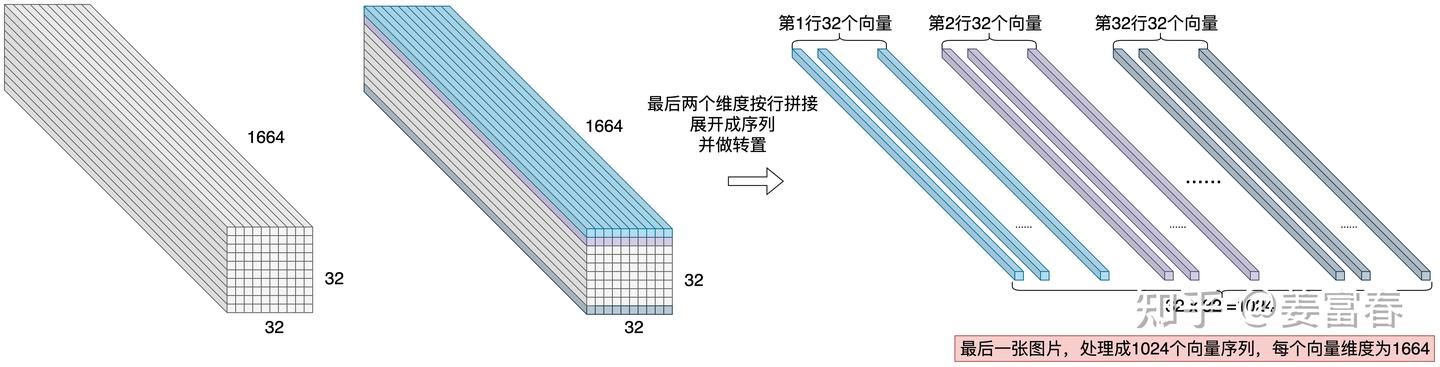
More details from zhihu
- [3,448,448]->CNN->[1664,32,32]
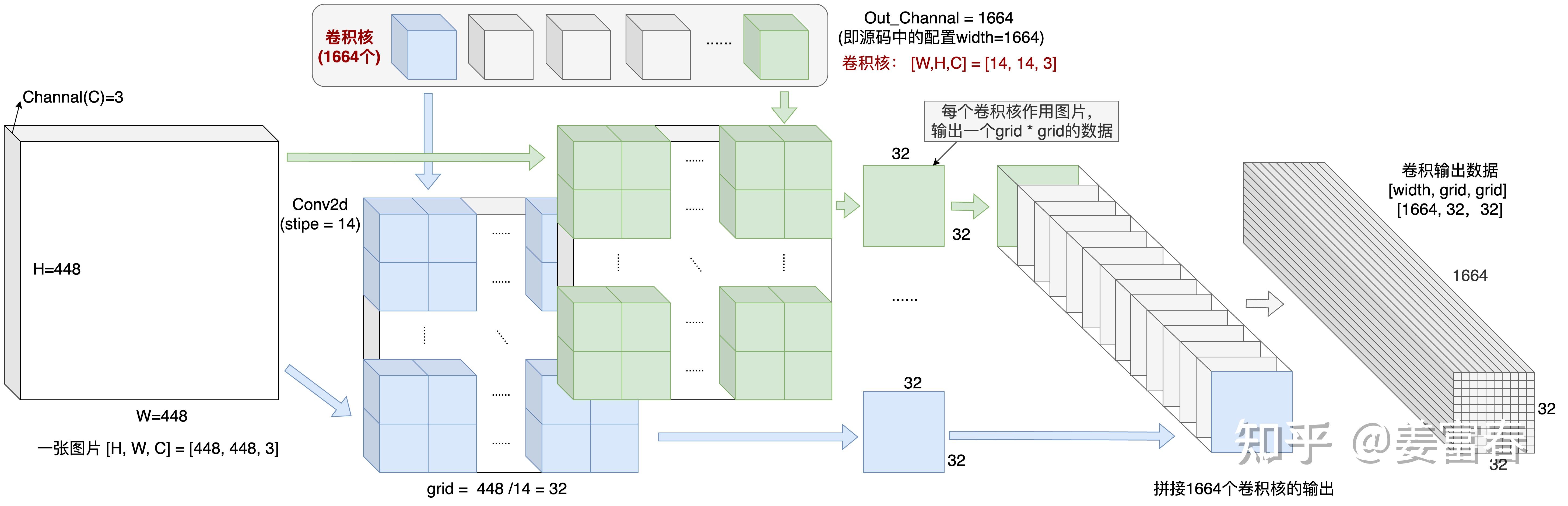
- [1664,32,32]->[1024,1664]
3 Chat Template
- The image content is user message will be replaced as
<|vision_start|><|image_pad|><|vision_end|> Picturewill be appended ifadd_vision_idoption selected.<|image_pad|>will repeatgrid_t*gird_h*grid_w/4timesself.image_processor.merge_size = 2 merge_length = self.image_processor.merge_size**2 index = 0 for i in range(len(text)): while "<|image_pad|>" in text[i]: text[i] = text[i].replace( "<|image_pad|>", "<|placeholder|>" * (image_grid_thw[index].prod() // merge_length), 1 ) index += 1 # change back from placehodler to image_pad?? text[i] = text[i].replace("<|placeholder|>", "<|image_pad|>") )4 Visual & Text Fusion
- Unified Embedding
Simply concatenate tokens from ViT+MLP with text tokens. So it can adapt to multimodality without a specially pre-trained LLM
- Cross-Attention
- Queries from one modality (text)
- Keys and Values from another modality (images)