Pytest Debug and vLLM Processing
Debug Pytest for vLLM and get a closer look at the processing workflow. So working from the test case is a much clearly way to understand the workflow.
1 Pytest Debug
Pytest is actually a python module, so we can debug it with proper config in the launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "Pytest: Current File",
"type": "debugpy",
"request": "launch",
"module": "pytest",
"args": ["${file}"],
"justMyCode": true,
},
{
"name": "Python Debugger: Current File",
"type": "debugpy",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": false
}
]
}
2 vLLM Processing
Here is the workflow overview
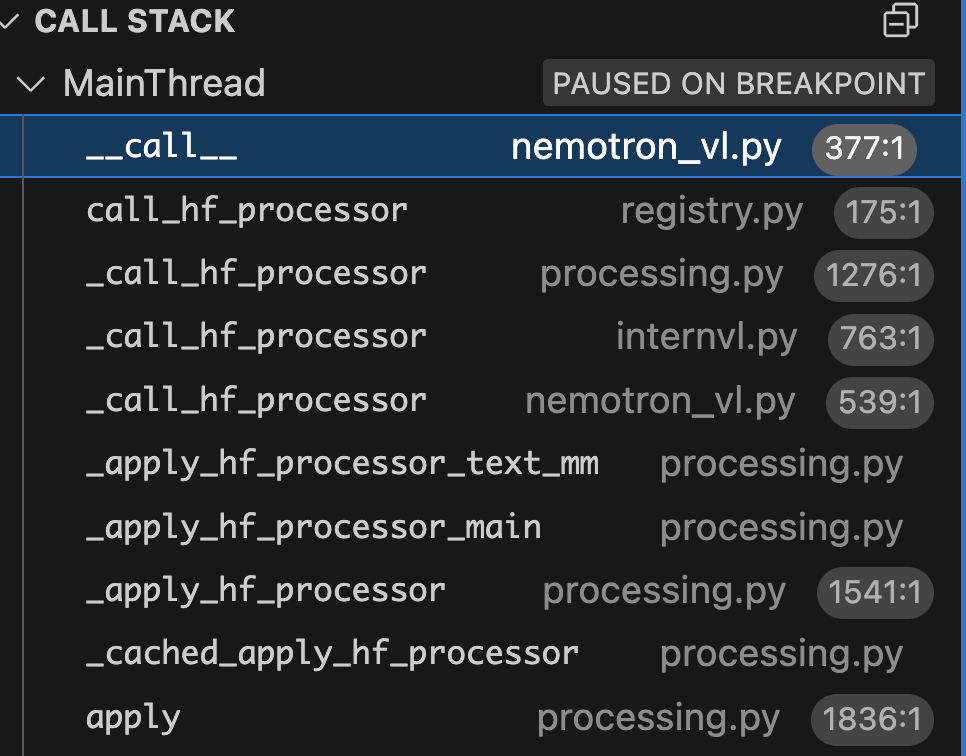 It starts with
It starts with MultiModalProcessor class: _apply_hf_processor calls _apply_hf_processor_main and calls _apply_hf_processor_text_mm for multimodal.
class BaseMultiModalProcessor(ABC):
...
def _apply_hf_processor_text_mm(...):
...
processed_data = self._call_hf_processor(
prompt=prompt_text,
mm_data=processor_data,
mm_kwargs=hf_processor_mm_kwargs,
tok_kwargs=tokenization_kwargs,
)
...
and the __call_hf_processor is actually overridden in the derived classes, but it always call super()._call_hf_processor so it will trace back to the parent class.
class NemotronVLMultiModalProcessor(
BaseInternVLMultiModalProcessor[NemotronVLProcessingInfo]):
def _call_hf_processor(...):
processed_outputs = super()._call_hf_processor(...)
...
class BaseInternVLMultiModalProcessor(BaseMultiModalProcessor[_I]):
def _call_hf_processor(self,...) -> Mapping[str, NestedTensors]:
processed_outputs = super()._call_hf_processor(...)
...
# Now it calls BaseMultiModalProcessor._call_hf_processor()
In processing info’ context, it get hf processor by self.info.get_hf_processor and actually calls this processor, which links to NemotronVLProcessor.__call__()
class BaseMultiModalProcessor(ABC):
def _call_hf_processor(self,...) -> "BatchFeature":
return self.info.ctx.call_hf_processor(
self.info.get_hf_processor(**mm_kwargs),
dict(text=prompt, **mm_data),
dict(**mm_kwargs, **tok_kwargs),
)
class InputProcessingContext(InputContext):
...
def call_hf_processor(...):
output = hf_processor(**data, **merged_kwargs, return_tensors="pt")
...
class NemotronVLProcessor(BaseNemotronVLProcessor):
def __call__(...):
##The ACTUALLY PROCESSING##
3 Placeholder replacement
For images, <image> is hard coded to be the initial placeholder for images. and will be replaced by <img_start><img_context>...<img_context><img_end> in the BaseMultiModalProcessor._find_mm_placeholders() subroutine
It’s def _iter_placeholders() defined in processing.py to looks for pattern maches.