Reward Model
Read some latest publish from Cameron’s blog and got some knowledge refresh for Reward model, DPO (will be my next blog) and review on PPO (like always)
0 Overview of how RW is used
Standard LLM post-training steps in RLHF:
- Supervised finetuning (SFT)—a.k.a. instruction finetuning (IFT)
trains the model using next-token prediction over examples of good completions. - A reward model (RM) is trained over a human preference dataset
- RL is used to finetune the LLM by using the output of the RM as a training signal.
1 Bradley-Terry Model of Preference
The RW is actually based on BT model, which I learnt during Elo score calculation.
 and RW function is used here
and RW function is used here
 and leads to standard training loss
and leads to standard training loss

2 Different Types of RMs
- Train a custom classifier to serve as an RM
- LLM-as-a-judge
- Outcome Reward Models (ORMs),
Unlike a standard RM that predicts the reward at a sequence level, the ORM predicts correctness on a per-token basis
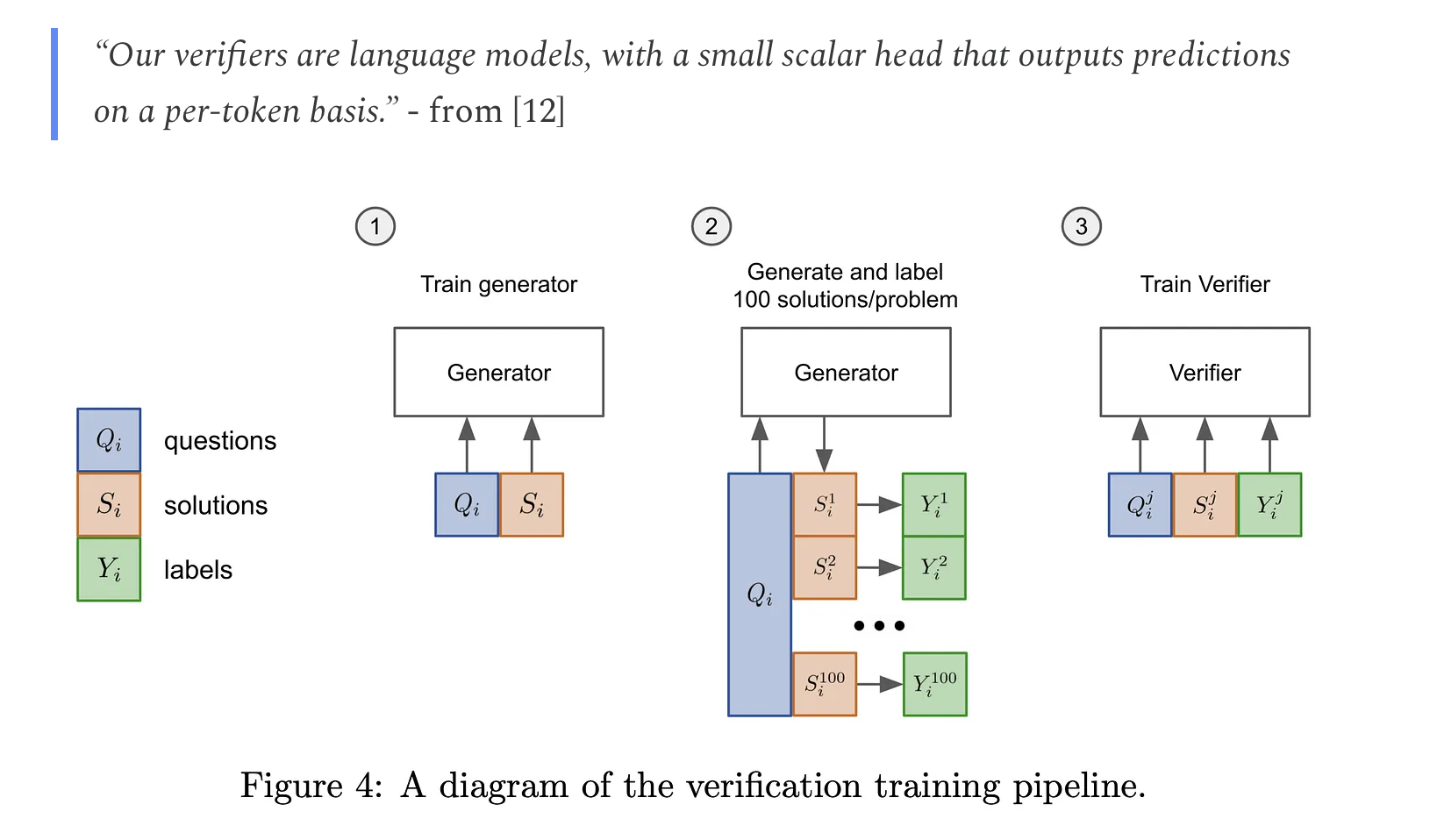
- Process Reward Models (PRMs) PRMs make predictions after every step of the reasoning process rather than after every token.Collecting training data for PRMs is difficult, as they require granular supervision.
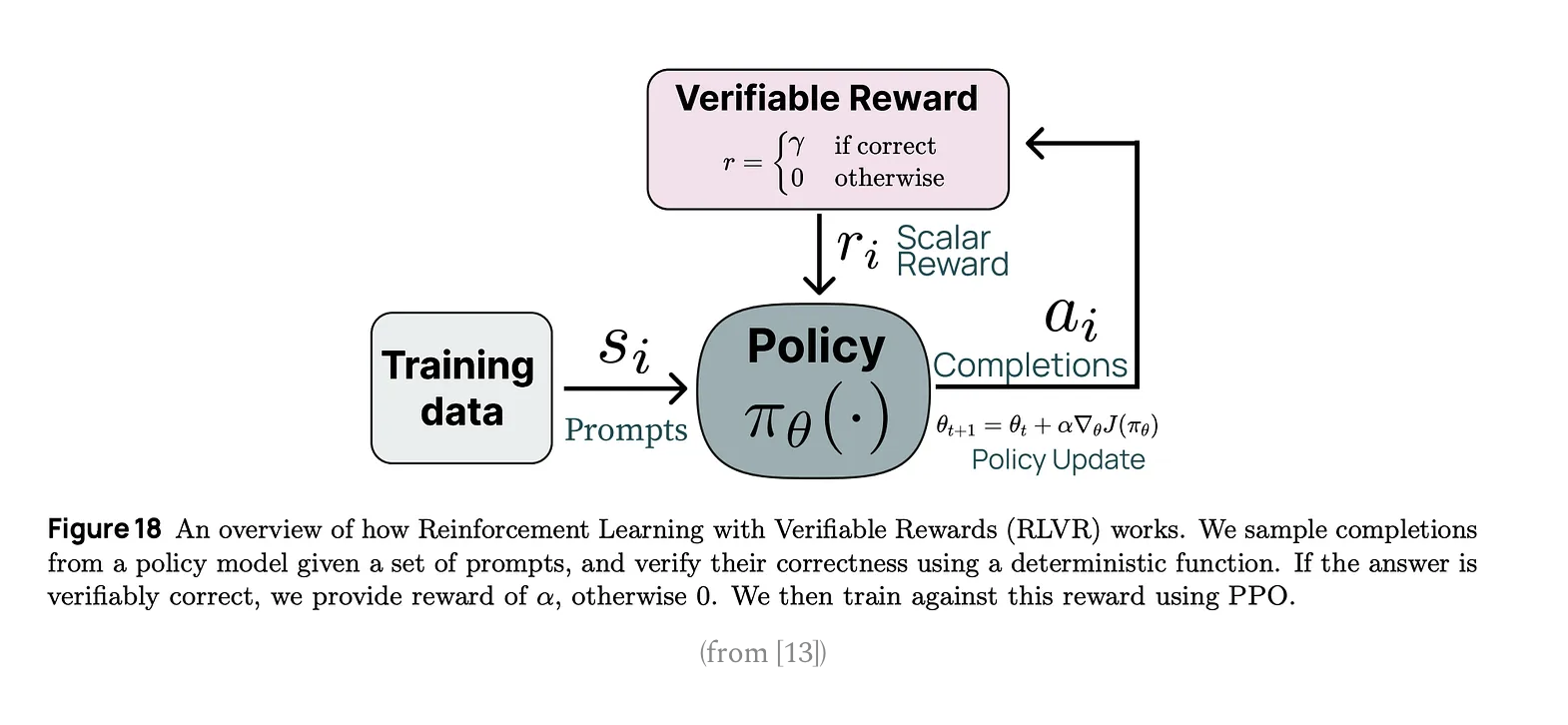
3 RLVR(Reinforcement Learning with Verifiable Rewards)
Two criteriors for a verifiable results
- has ground truth answer
- has a rule-based technique that can be used to verify correctness