DPO - Direct Preference Optimization
Continue with another blog from Cameron and greate explanation and super easy to digest math details
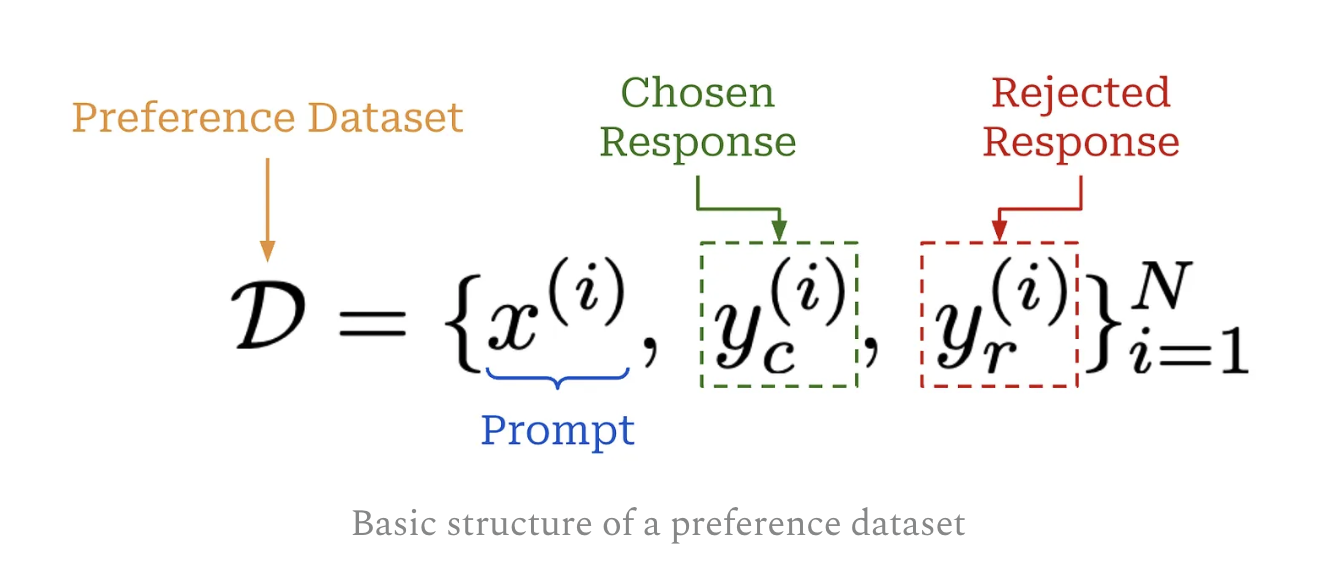
1 Preference dataset
PD of prompts with an associated “chosen” and “rejected” response.
 and it can be integrated in to Bradley-Terry model
and it can be integrated in to Bradley-Terry model
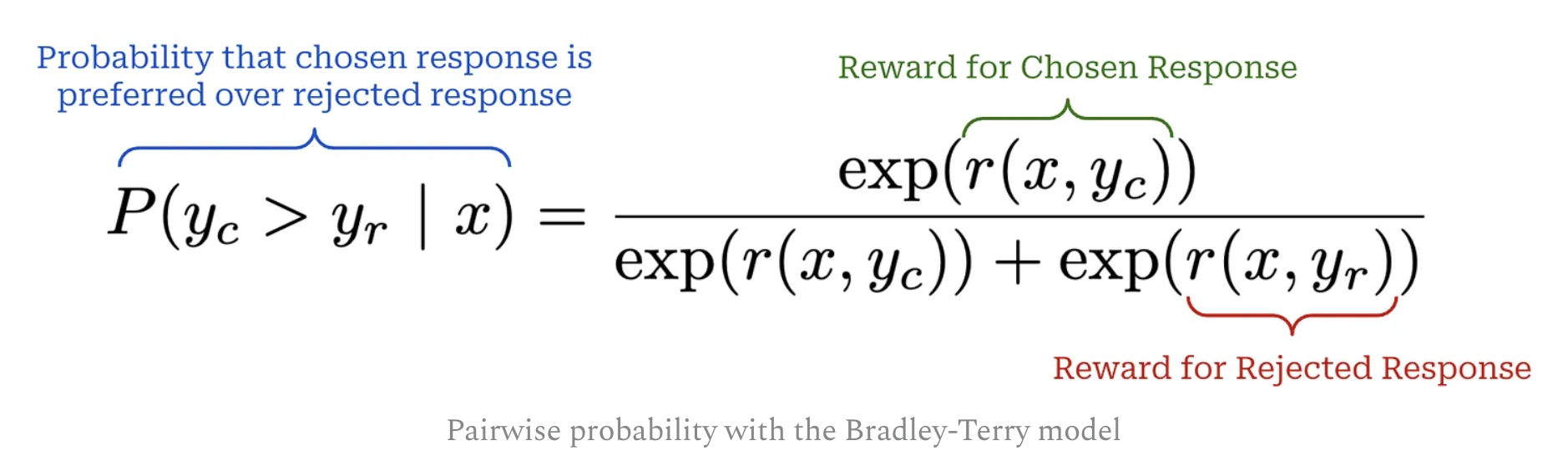
2 DPO in LLM Training
The DPO is replacing RLHF in the LLM training workflow
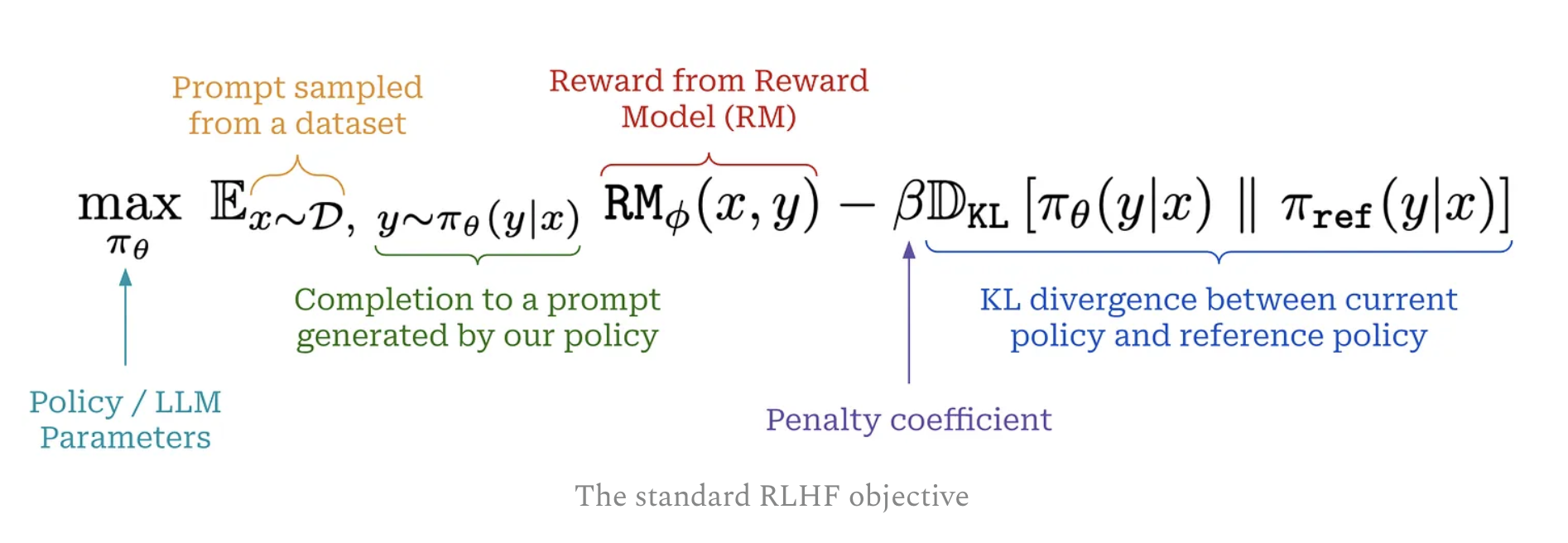
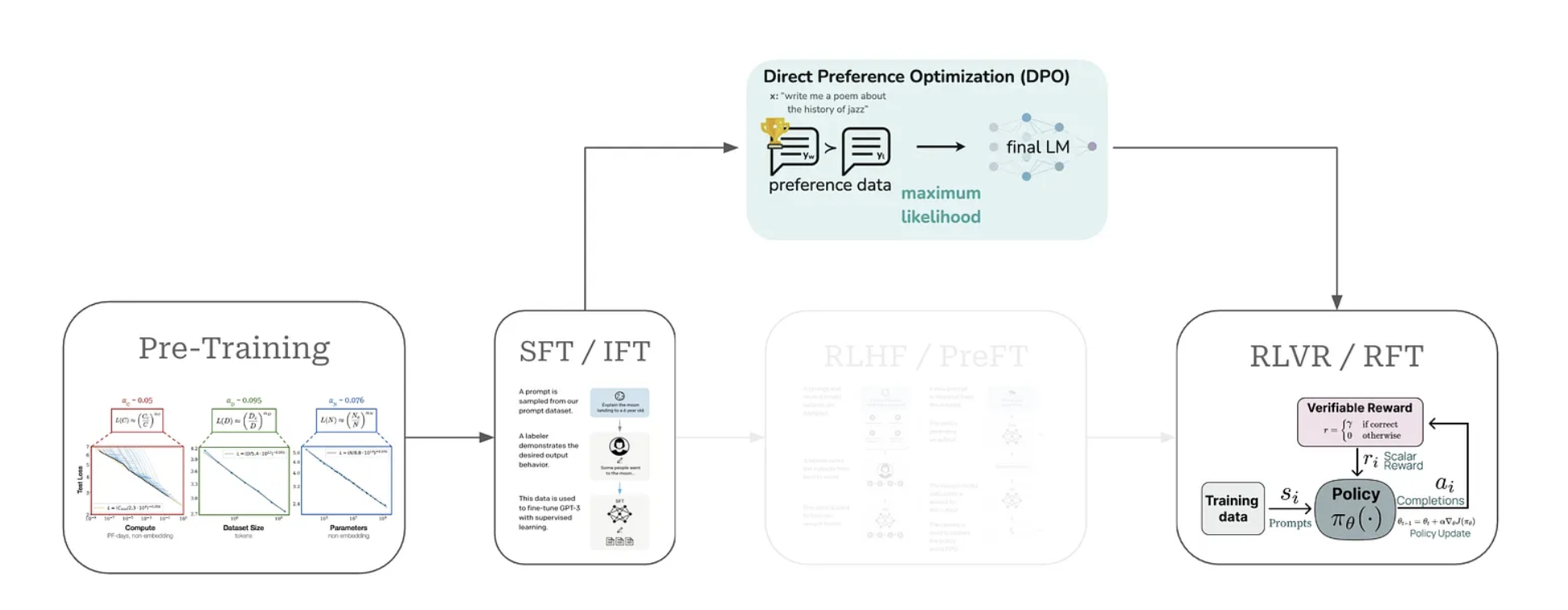 The standard RFHF has a reward model within its objective function
The standard RFHF has a reward model within its objective function
- It uses explicit reward model
- Use PPO to train RL
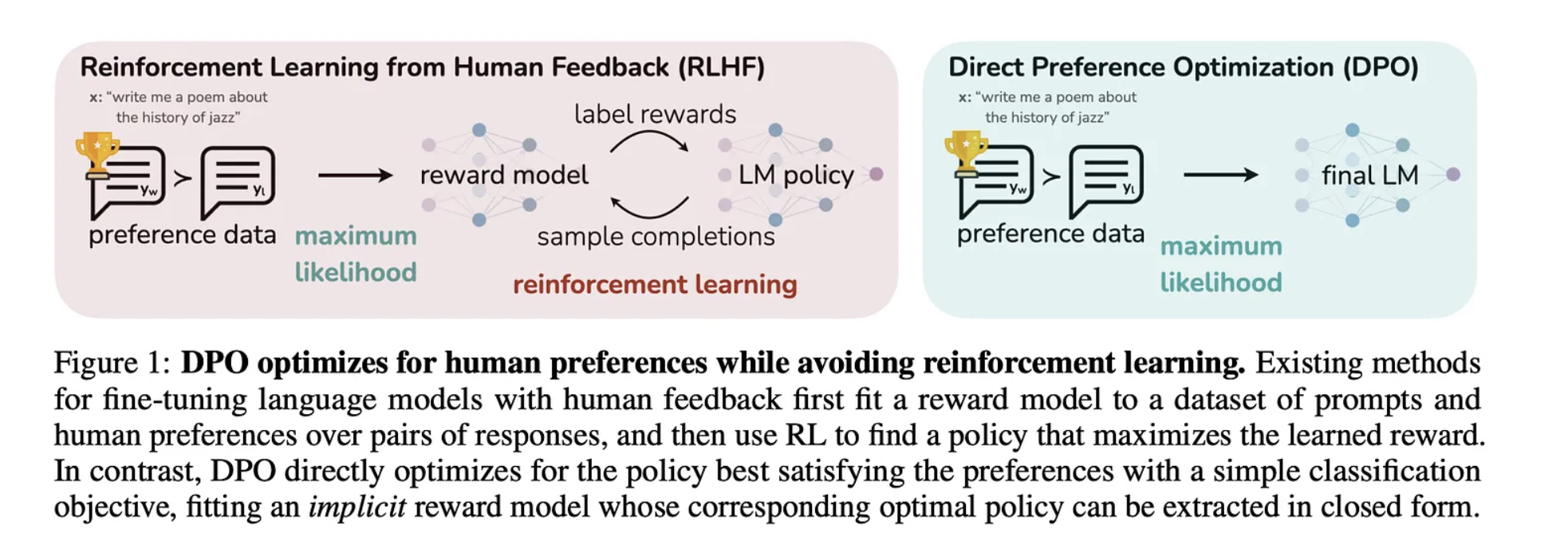
 But with DPO, we use
But with DPO, we use - implicit reward model within the policy itsel
- indirectly derives the optimal policy from
Here is the loss function for DPO
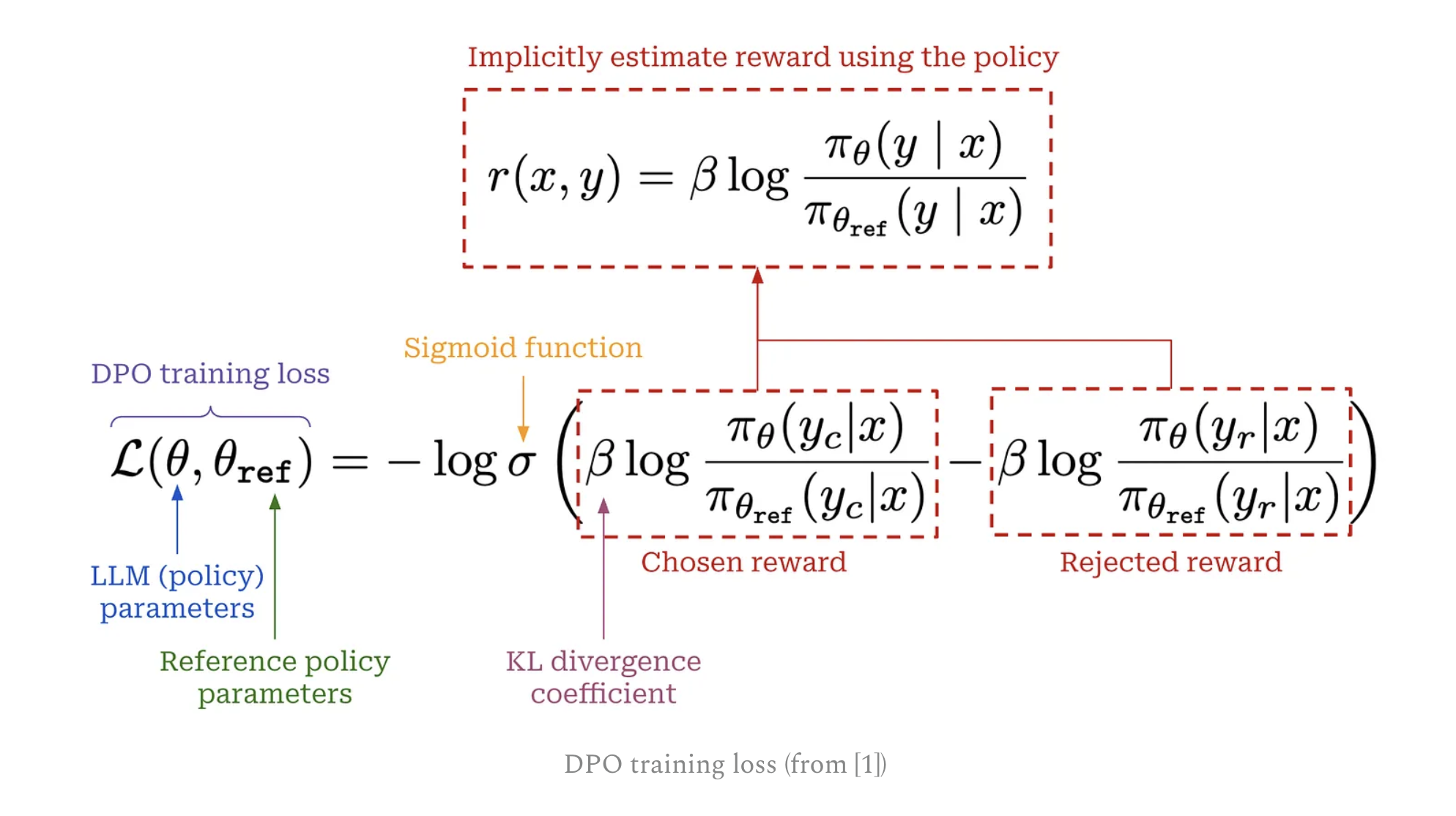 This is actually very close to the loss function we used to train reward model
This is actually very close to the loss function we used to train reward model
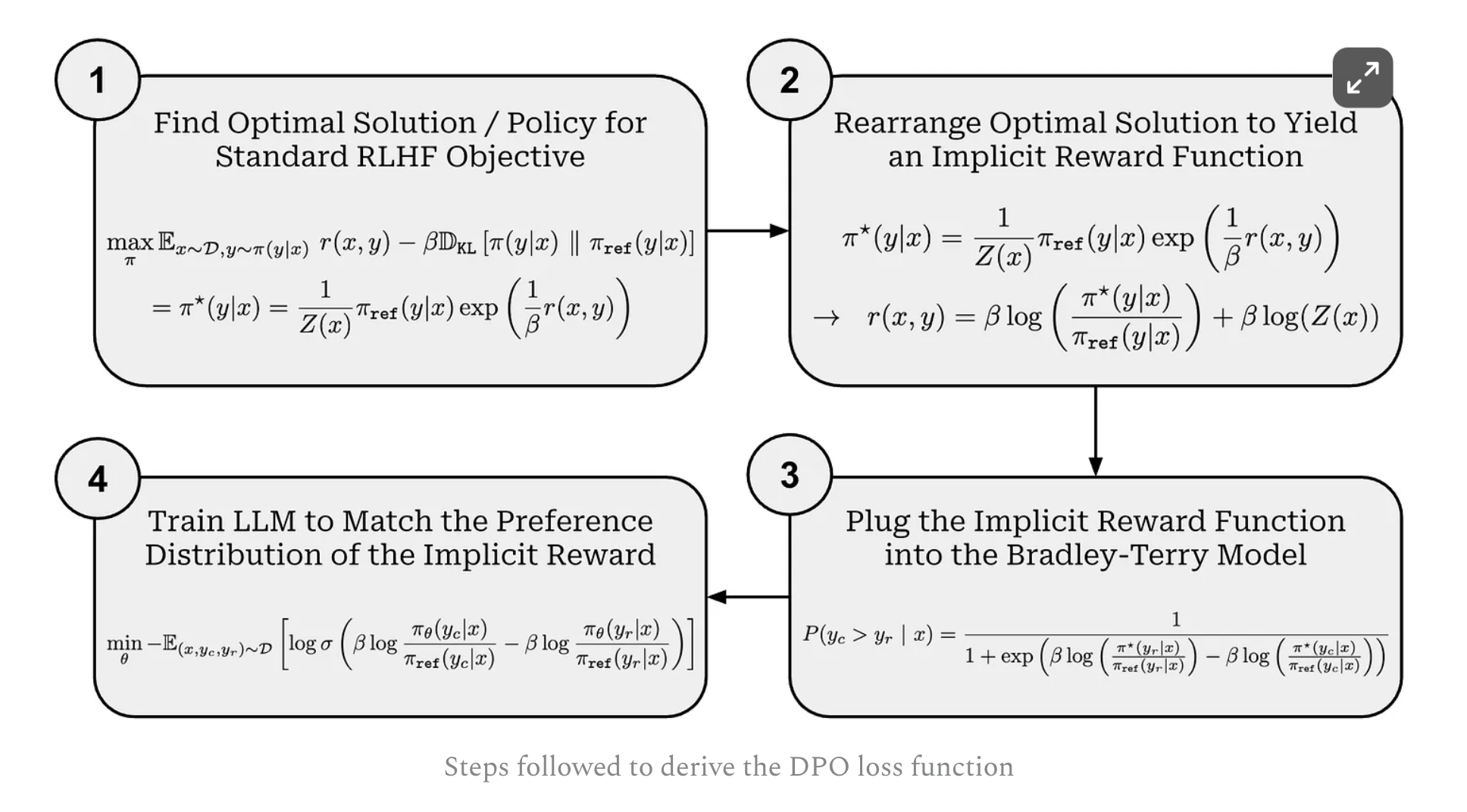
3 Derive of DPO
- Deriving an expression for the optimal policy in RLHF.
This step defines a partition function
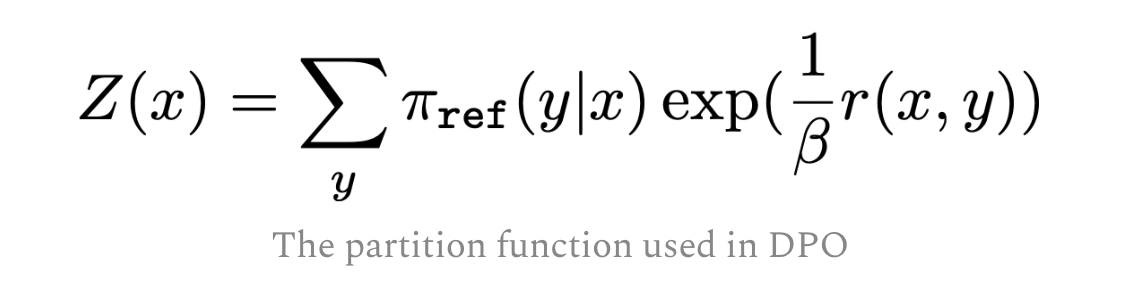 and defines optimal policyas below
and defines optimal policyas below
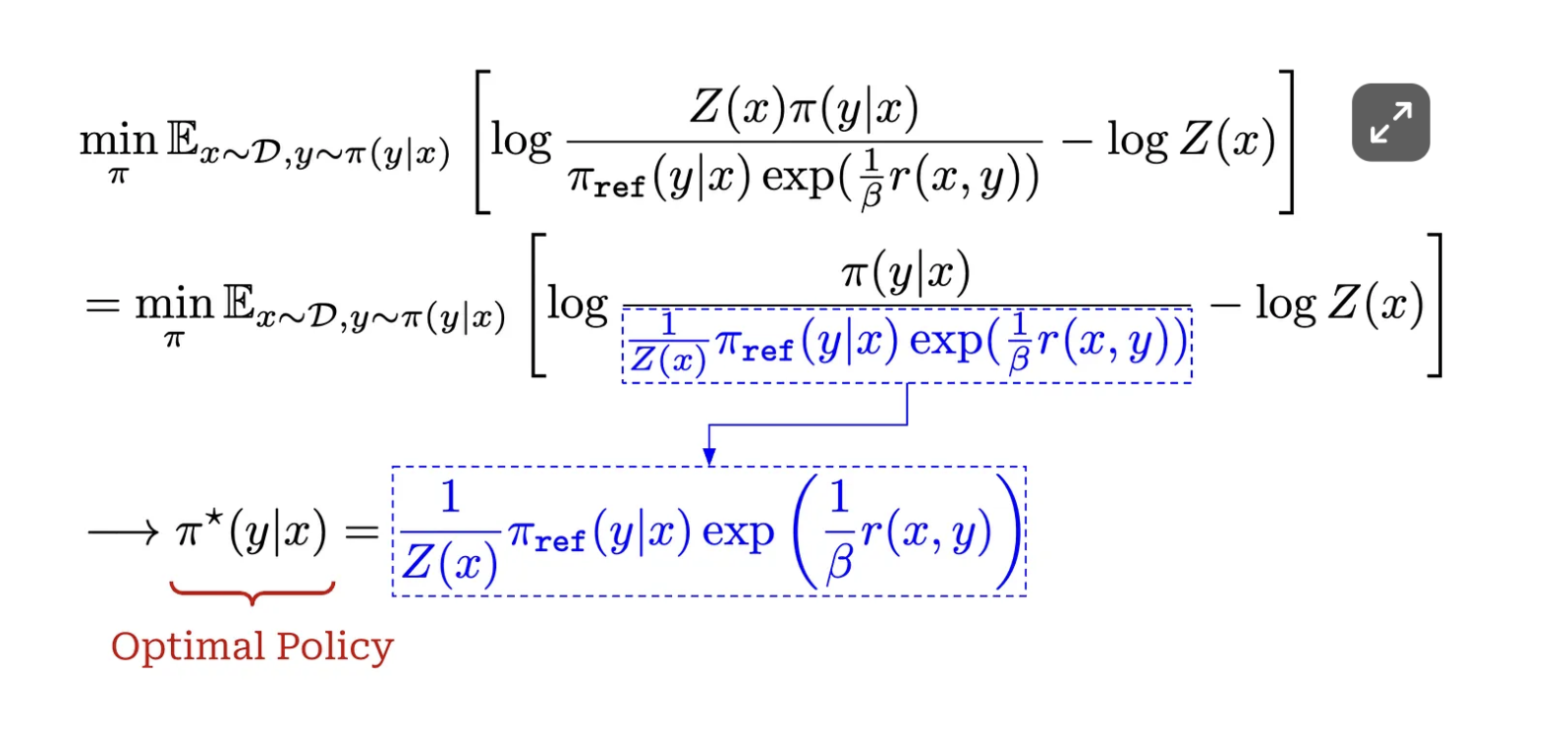 you can see that
you can see that
- The value of the optimal policy is ≥ 0 for all possible completions y.
- The sum of the optimal policy across all completions y is equal to 1.
Further derivation shows that the policy being optimal policy can minimized the RLHF objective

- Deriving an implicit reward. Re-arrange the defination of optimal policy, we can get the implicti reward function
- Plug into Bradley-Terry modal
- Training an LLM to match this implicit preference model—this is what we are doing in the DPO training process.