Mixture of Recursions
EZ’s talk about Mixture of Recursions
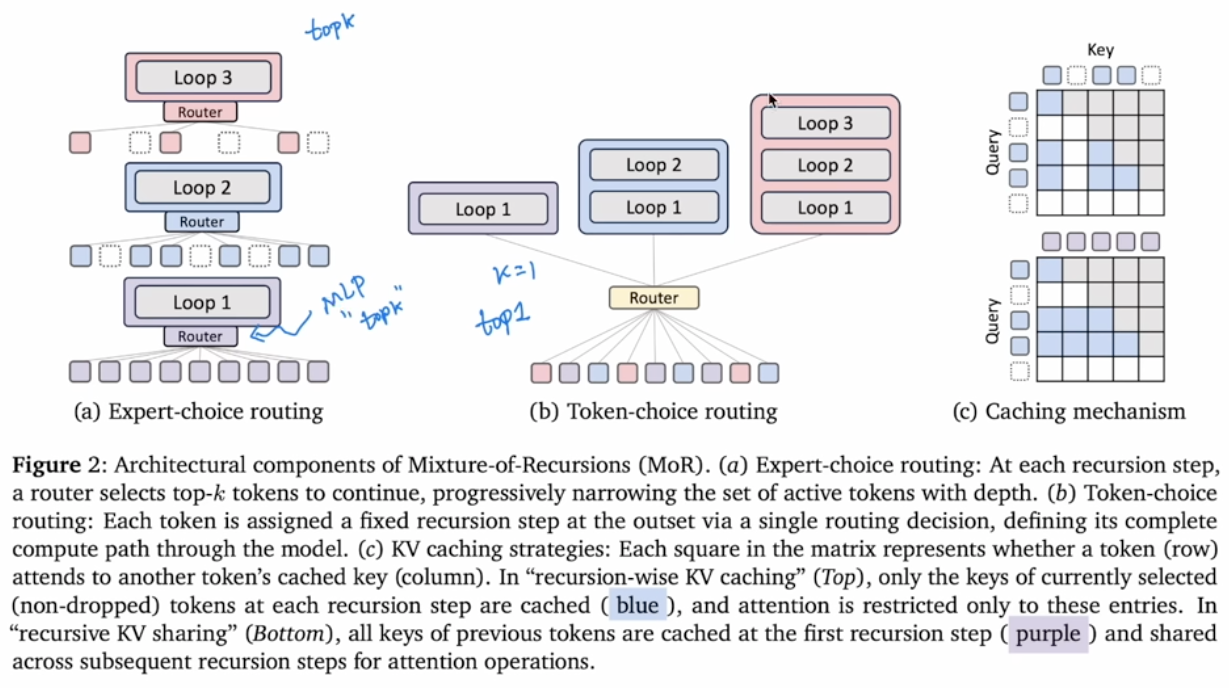
1 MoR = RNN + Transformers
Deepmind’s latest paper on MoR, which evolves from Recursive Transformer and MoD

The paper is having similar idea as MoE, which has a route to decide which layers to go through. So some tokens are go through more layers than some other tokens

Here are list of paper has relative techs around MoR
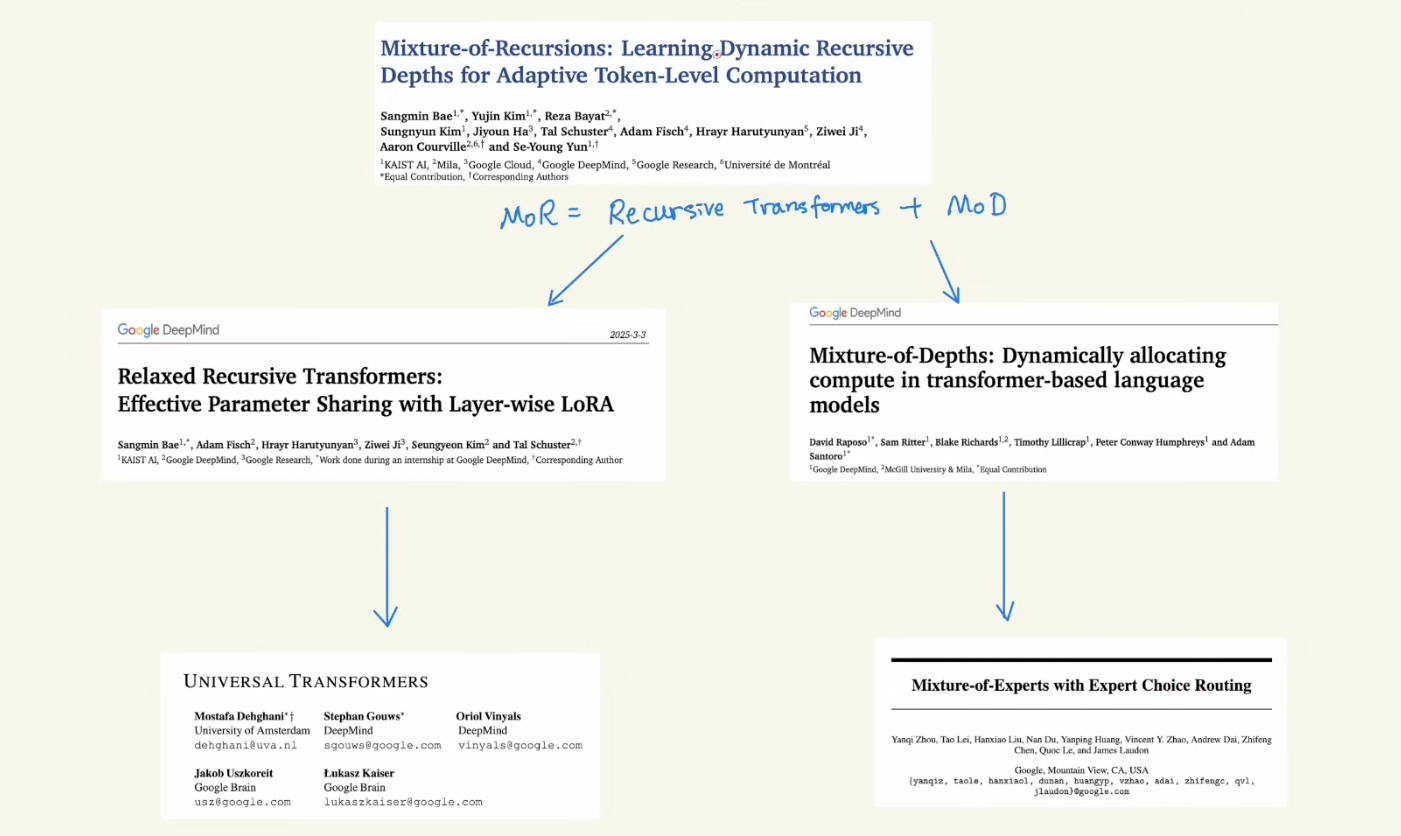
2 Recursive Transformers
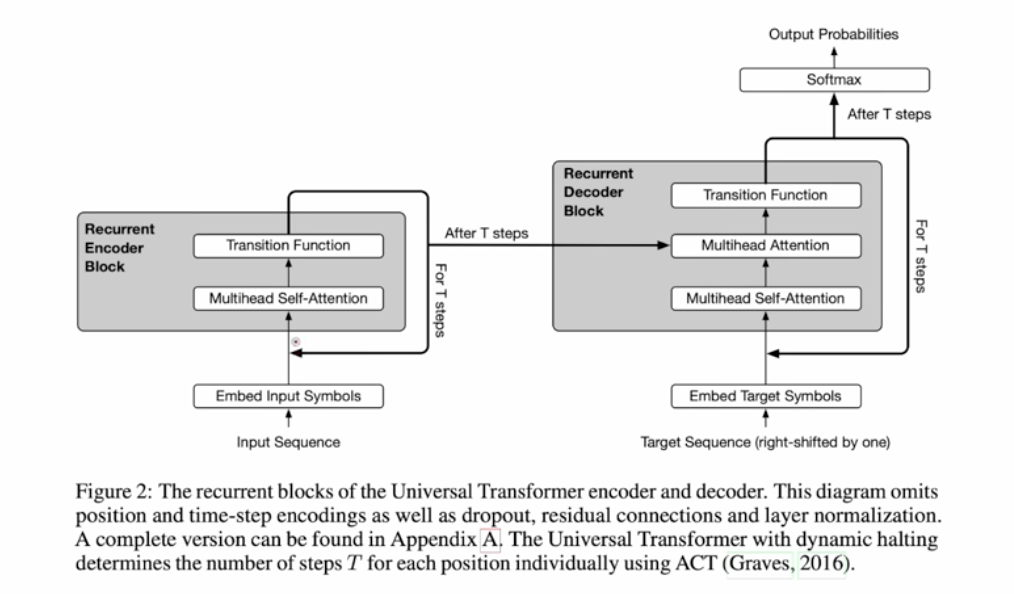
It starts from Universal Transformers, which is combine RNN into Transformers
 One latest development on this tech is also from Google. THe resursive is adding loops on some layers.
And the Relaxed Recursive Transformers is adding LoRA idea into it
One latest development on this tech is also from Google. THe resursive is adding loops on some layers.
And the Relaxed Recursive Transformers is adding LoRA idea into it
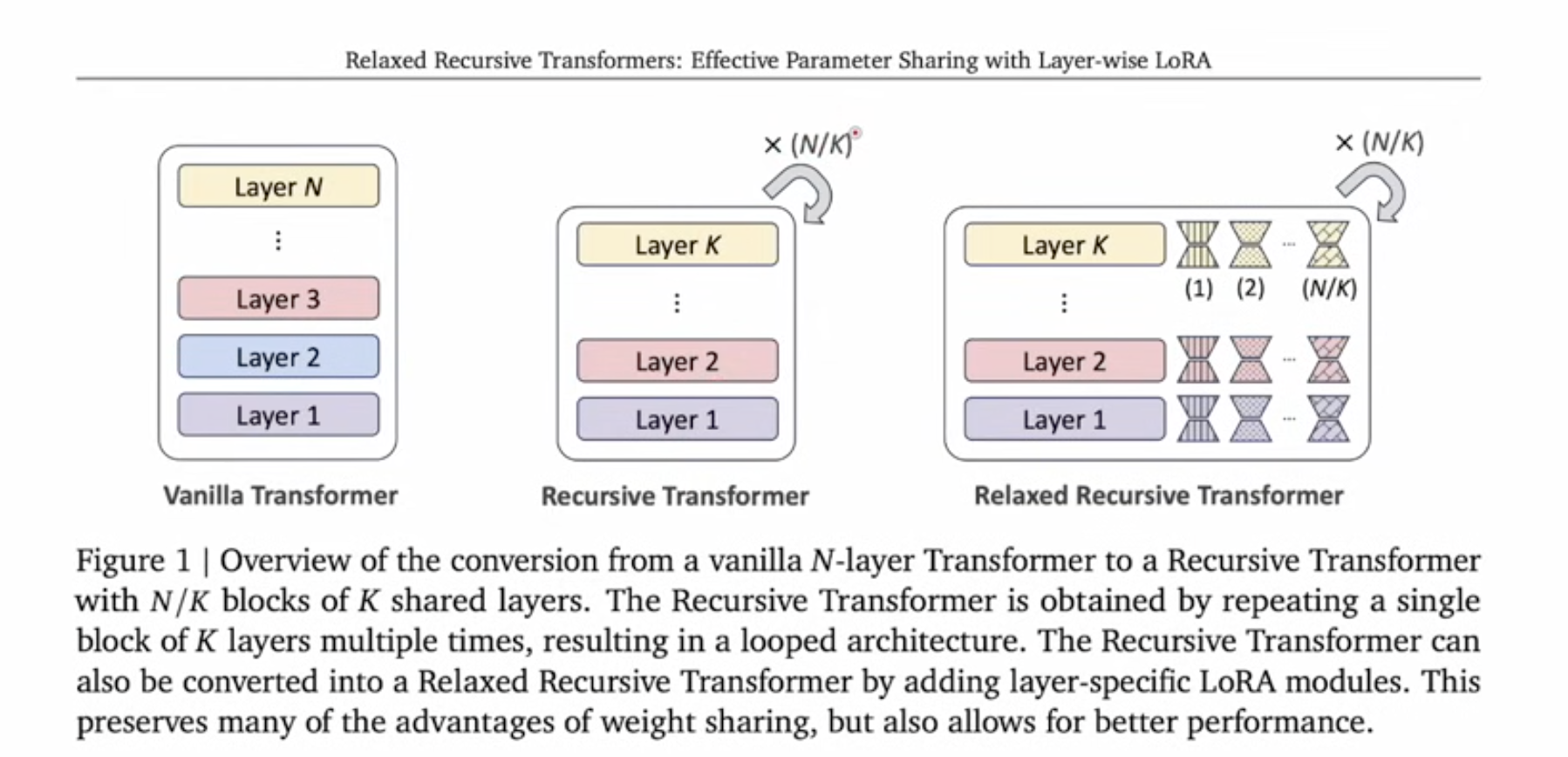 DIFFERENT LoRA were added so that parameters will be slightly different between recursive blocks
DIFFERENT LoRA were added so that parameters will be slightly different between recursive blocks
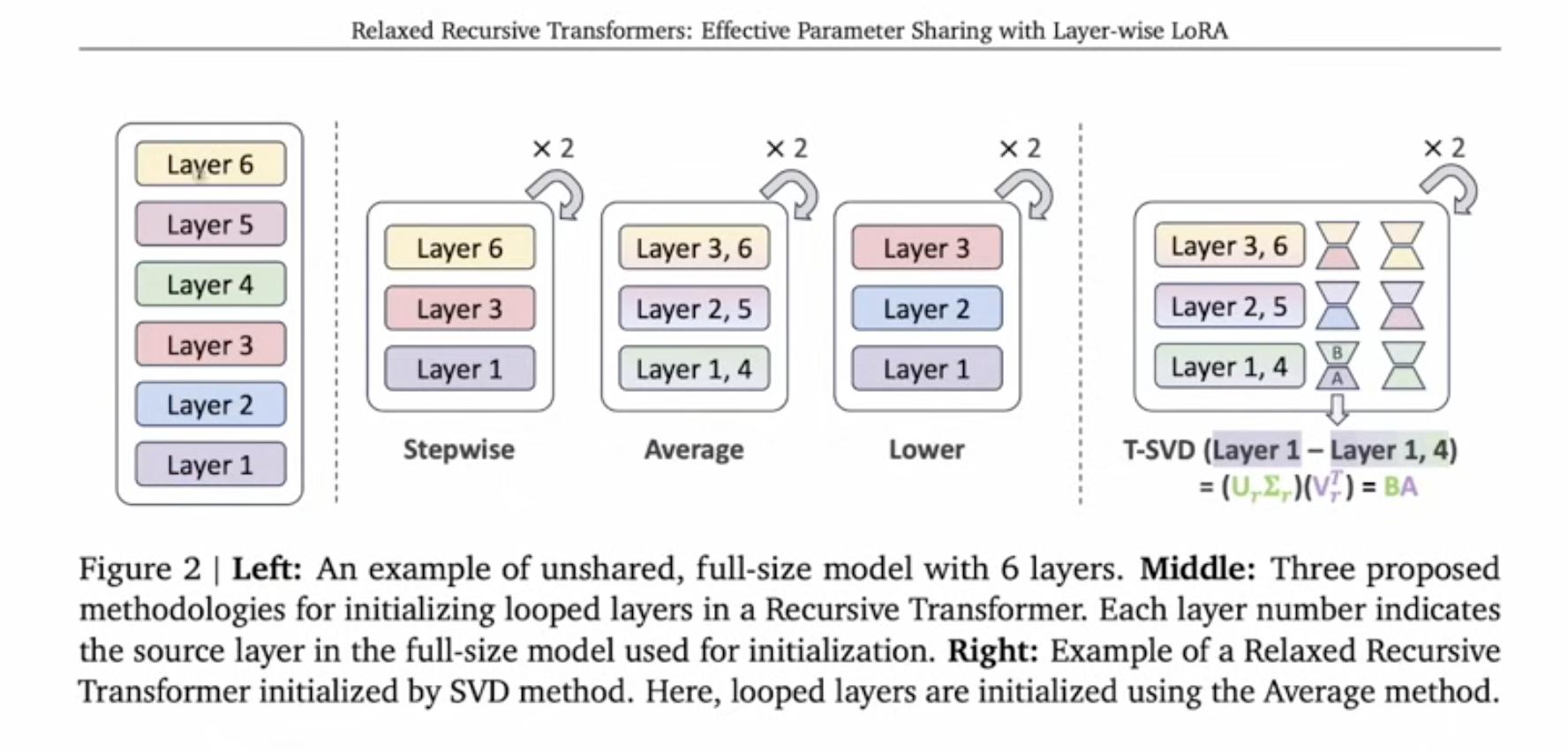
How to convert a Transfomer into a RT? Different ways to select layers are discussed in the paper
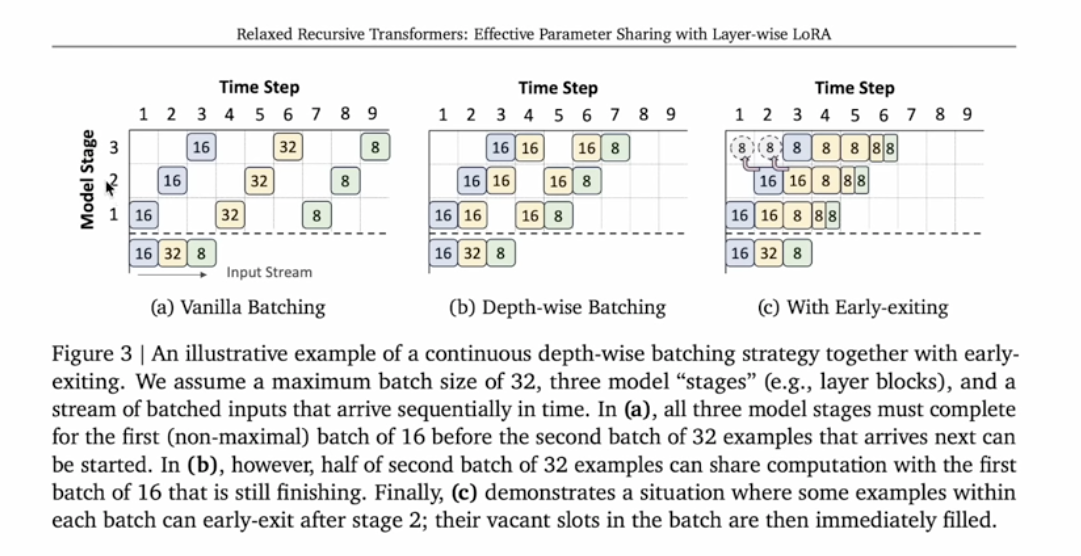
Continuous depth-wise batching is also introduced here, which is developed from Continuous sequence batching from Anyscale. Yes, Cade’s blog is shown up here again.
- Model stage: means model layers here
- Reduce GPU bubbles by depth-wise batching and early-exiting
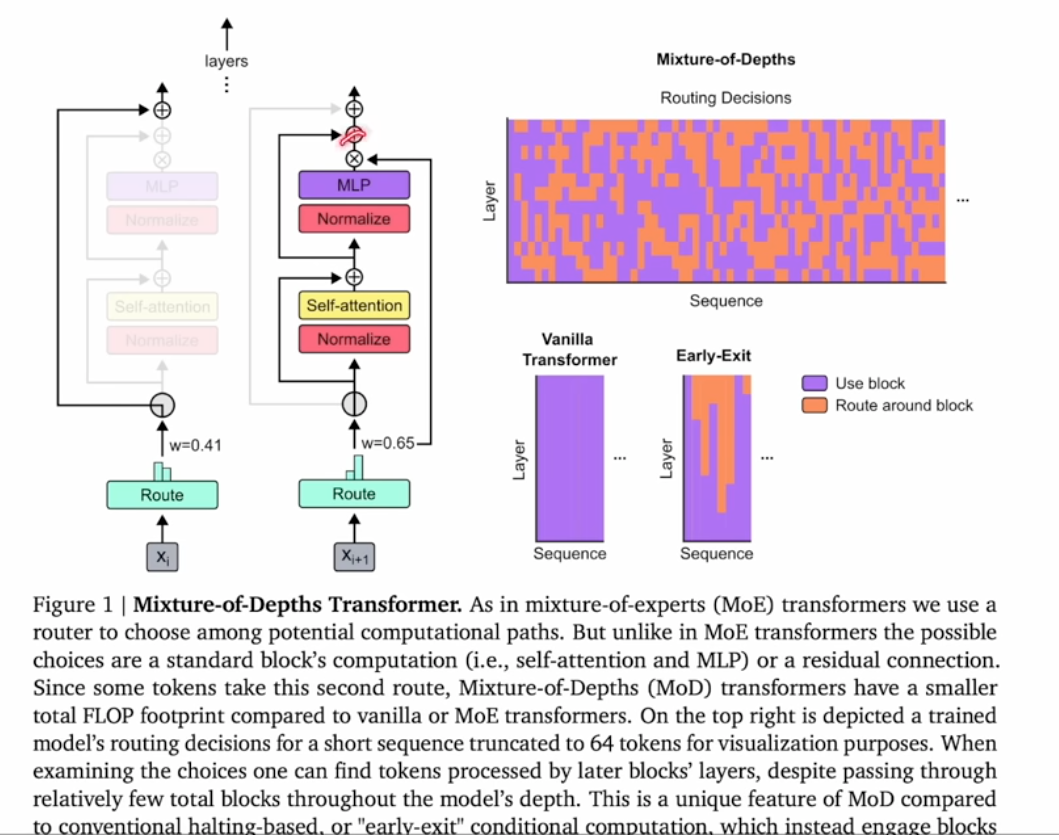
3 Mixture of Depth
A route, similar to MoE is used to decide by-pass or calculate a block
Early-Exit can skip some layer calculation, but limited to the end of layers
MoD can skip layers at any position
Two routing schemas are used here
- Token-choice-routing: Let token choose which expert to choose, which is easy to have bad load balance
- Expert-choice-routing: Let expert choose token, which is balance aware.
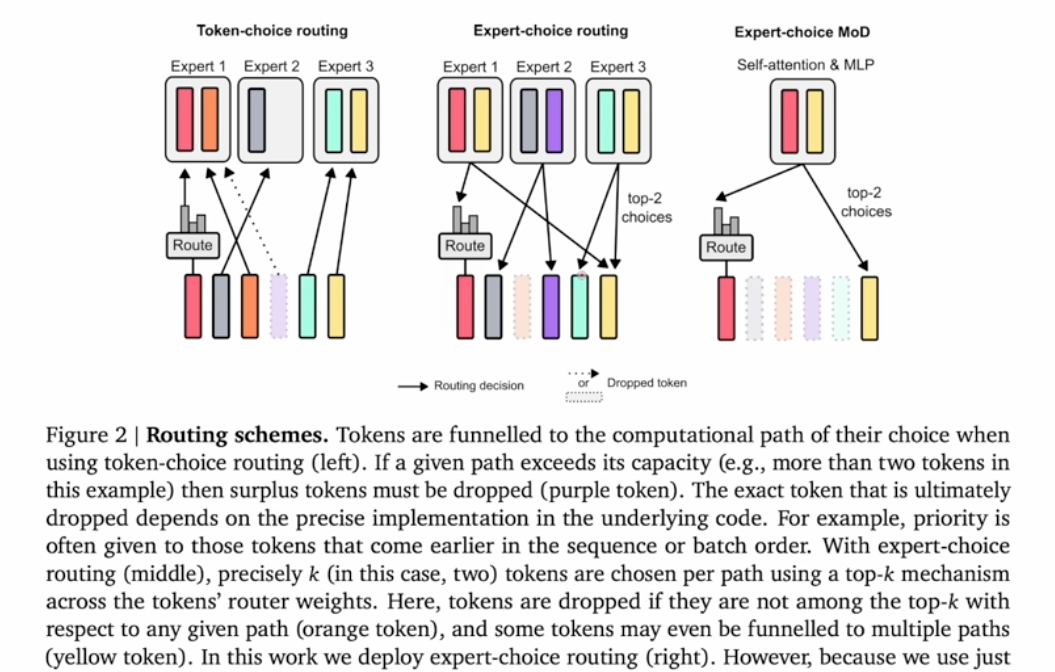
This method is actually introduced by Google as Expert Choice MoE
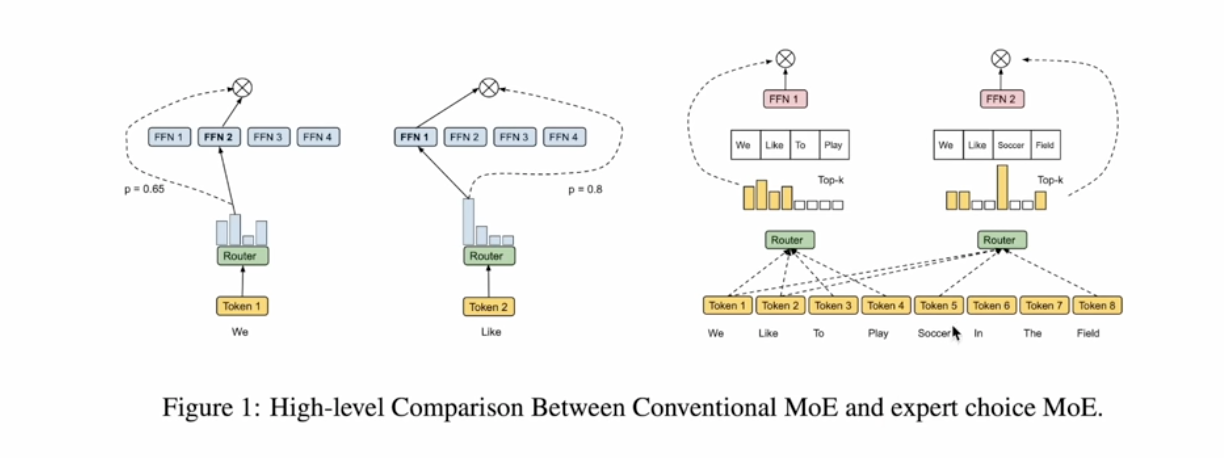
The cons for token-choice is load-imbalanced, and expert-choice is leakage (causality violation):
During training, you can always choice tokens based on expert, but during inferences, you only have limited tokens (already-generated-tokens) to choose from.
 The solution is adding a simple MLP to predict if a token is belongs to top-K
The solution is adding a simple MLP to predict if a token is belongs to top-K
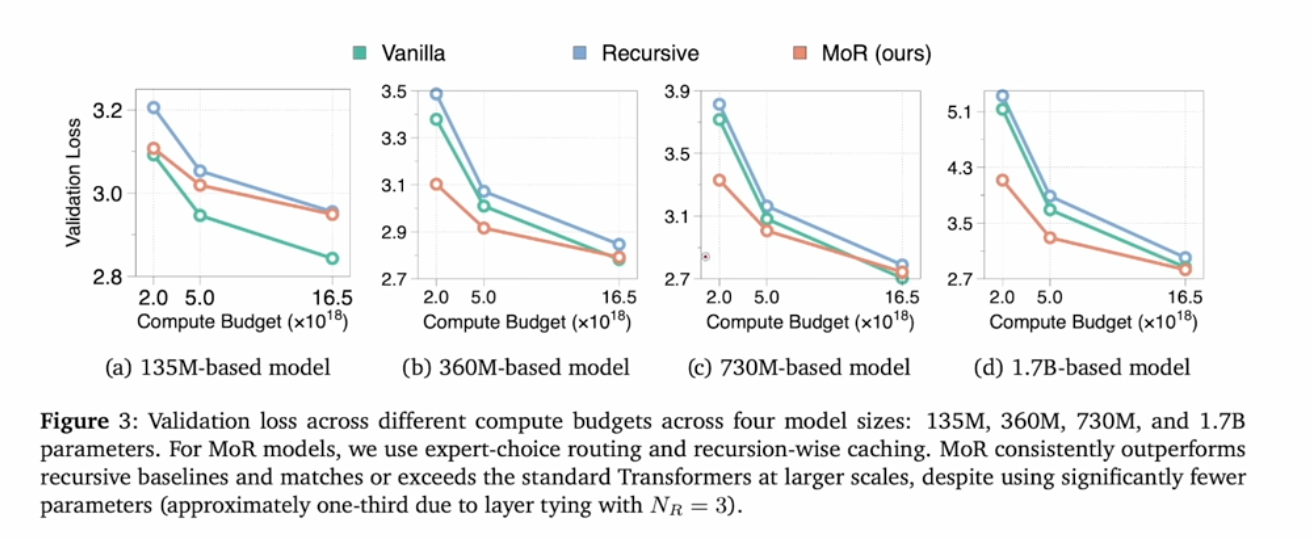
4 Result
Only shows benefit at large models with limited compute budget