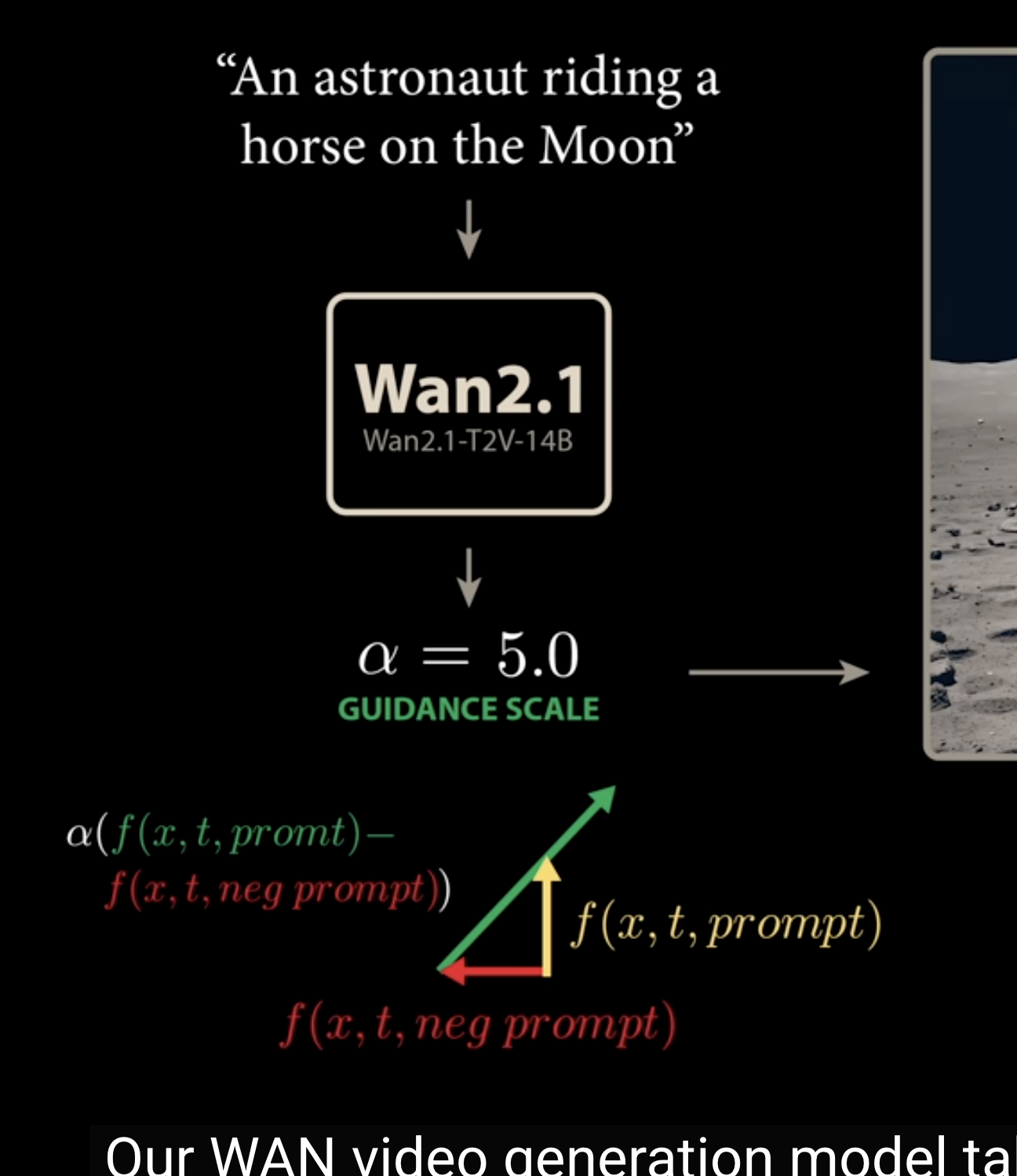
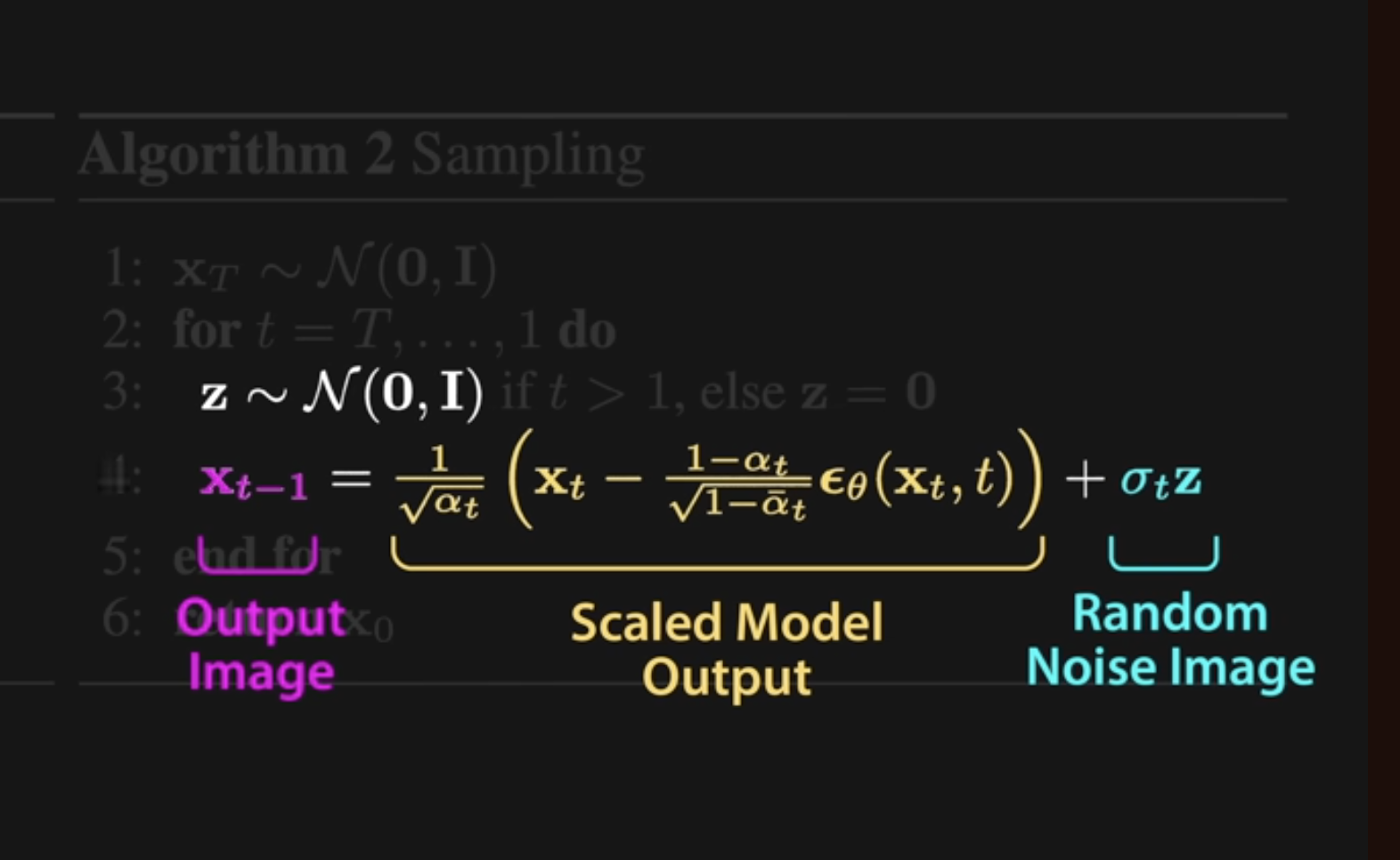
DDIM and Classifer-free Guidance
I looked up in my blog, and there is no record of VAE, ELBO, or flow models. These are the contents I spent quite some time on, but it’s right before I started blogging my learnings. So I would review all these contents again.
and gladly I found this video from WesLab, which gives a great overview of DDPM and DDIM, and make me understand classifier-free guidance for the first time.
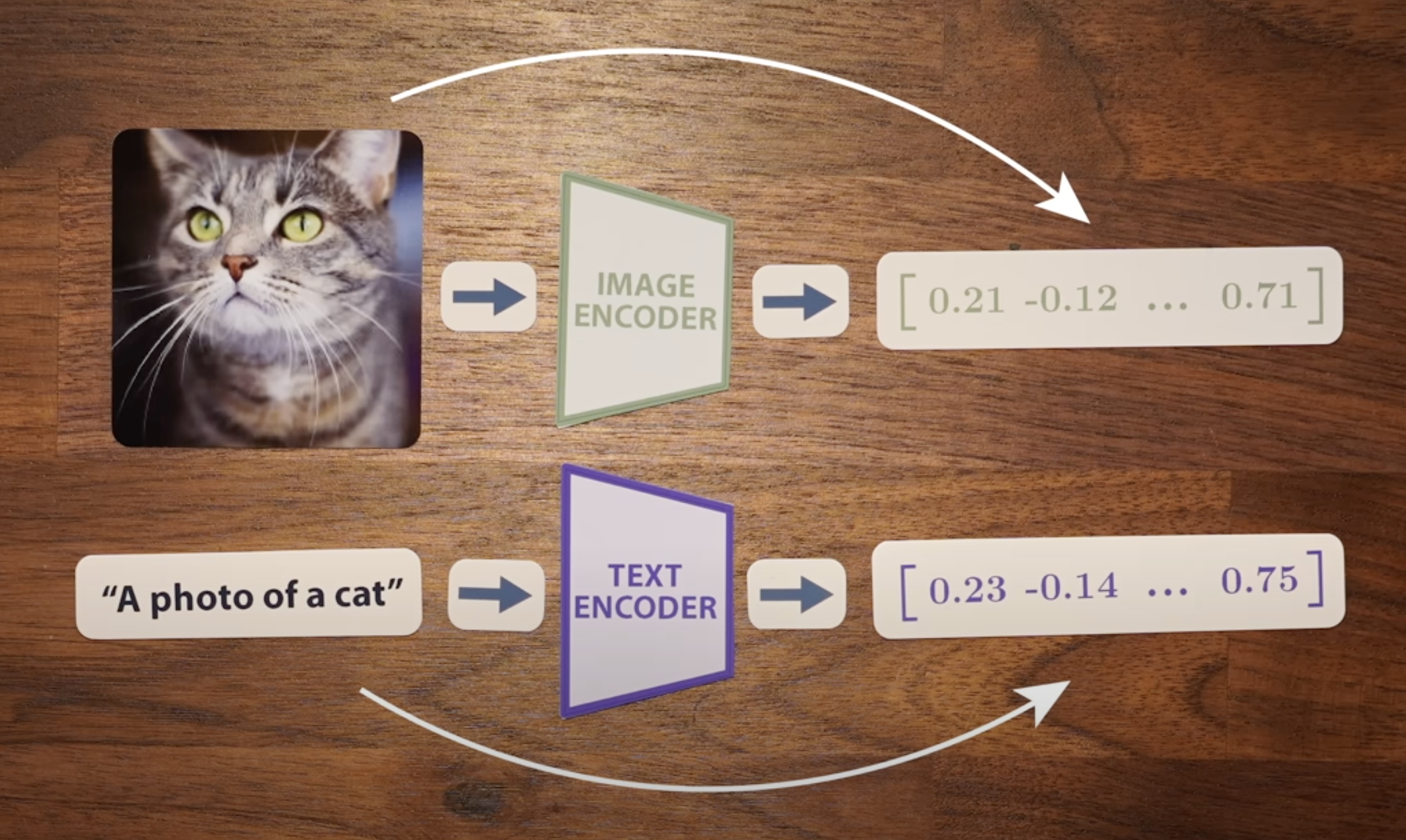
1 CLIP(Contrast Language Image Pretrain)
CLIP from OAI is learning by minimizing the cosine distance between an image embedding and text embedding. The question of image generation becomes how we can generate an image from the emebding vector
2 DDPM (Denoising Diffusion Probablistic Model)
Here come the DDPM paper, firstly using diffusion model for model generation
 This video asked a question I didn’t pay attention before
This video asked a question I didn’t pay attention before
- How the training for noise at random step work so well?
 So the key learnng from diffusion model is call time variance vector field, which is also the basic of flow based model
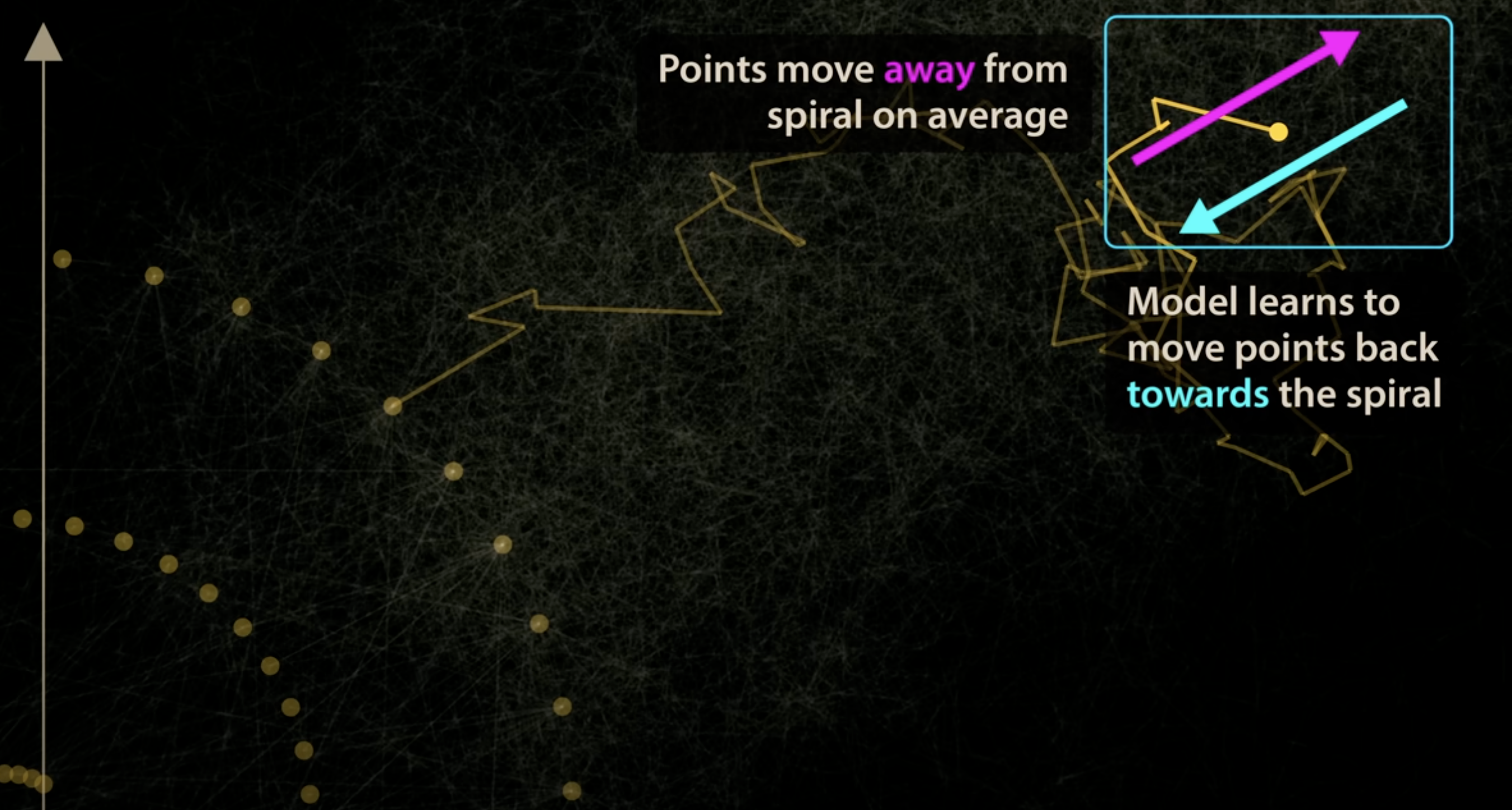
Here we have a 2D image pixels as an example, and all the training are placed on a spiral.
The learning is always trying to move the data back to its original spiral locations
So the key learnng from diffusion model is call time variance vector field, which is also the basic of flow based model
Here we have a 2D image pixels as an example, and all the training are placed on a spiral.
The learning is always trying to move the data back to its original spiral locations
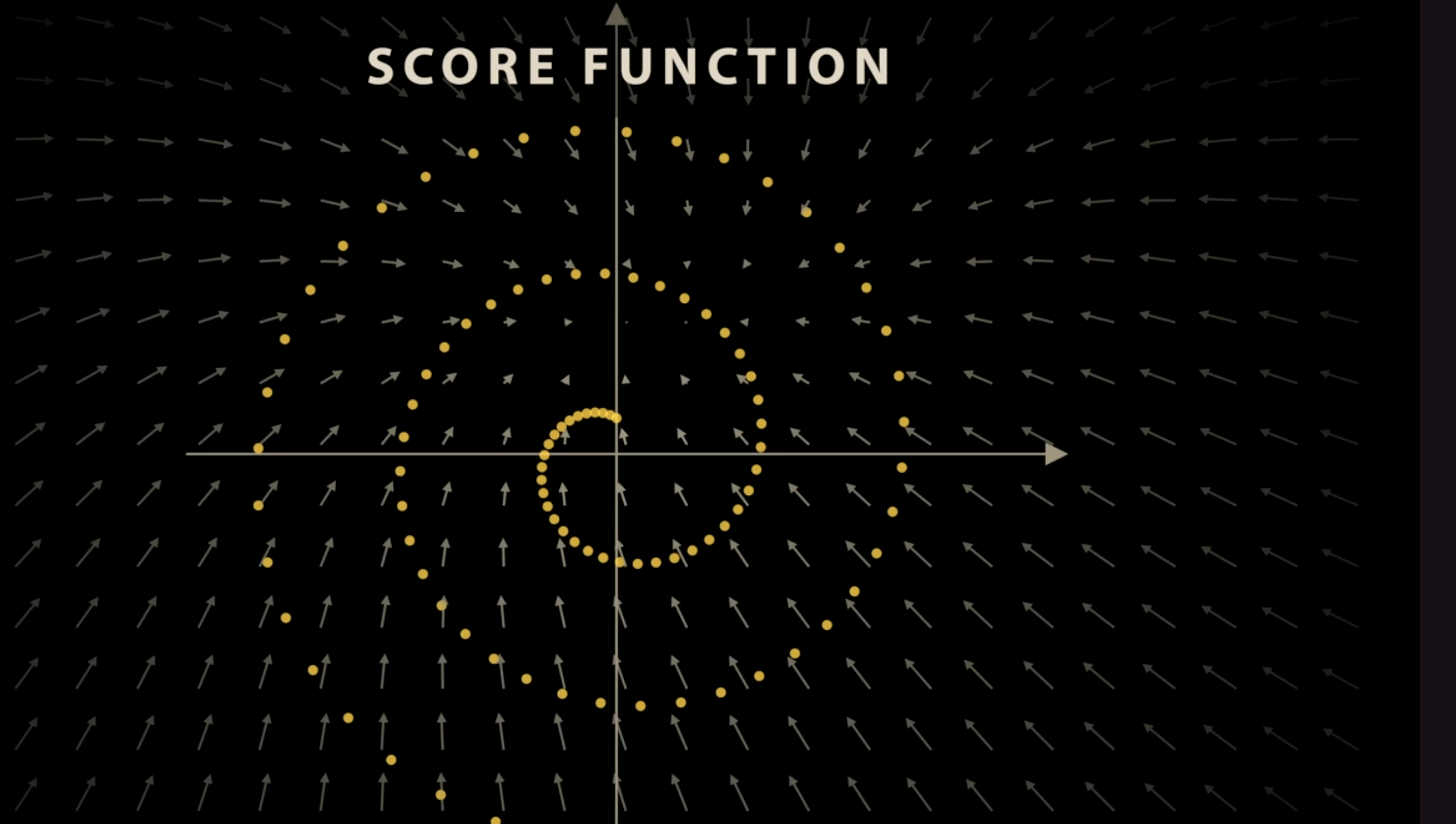
 The learning of direction pointing back to the orignal position, is also known as score function
The learning of direction pointing back to the orignal position, is also known as score function
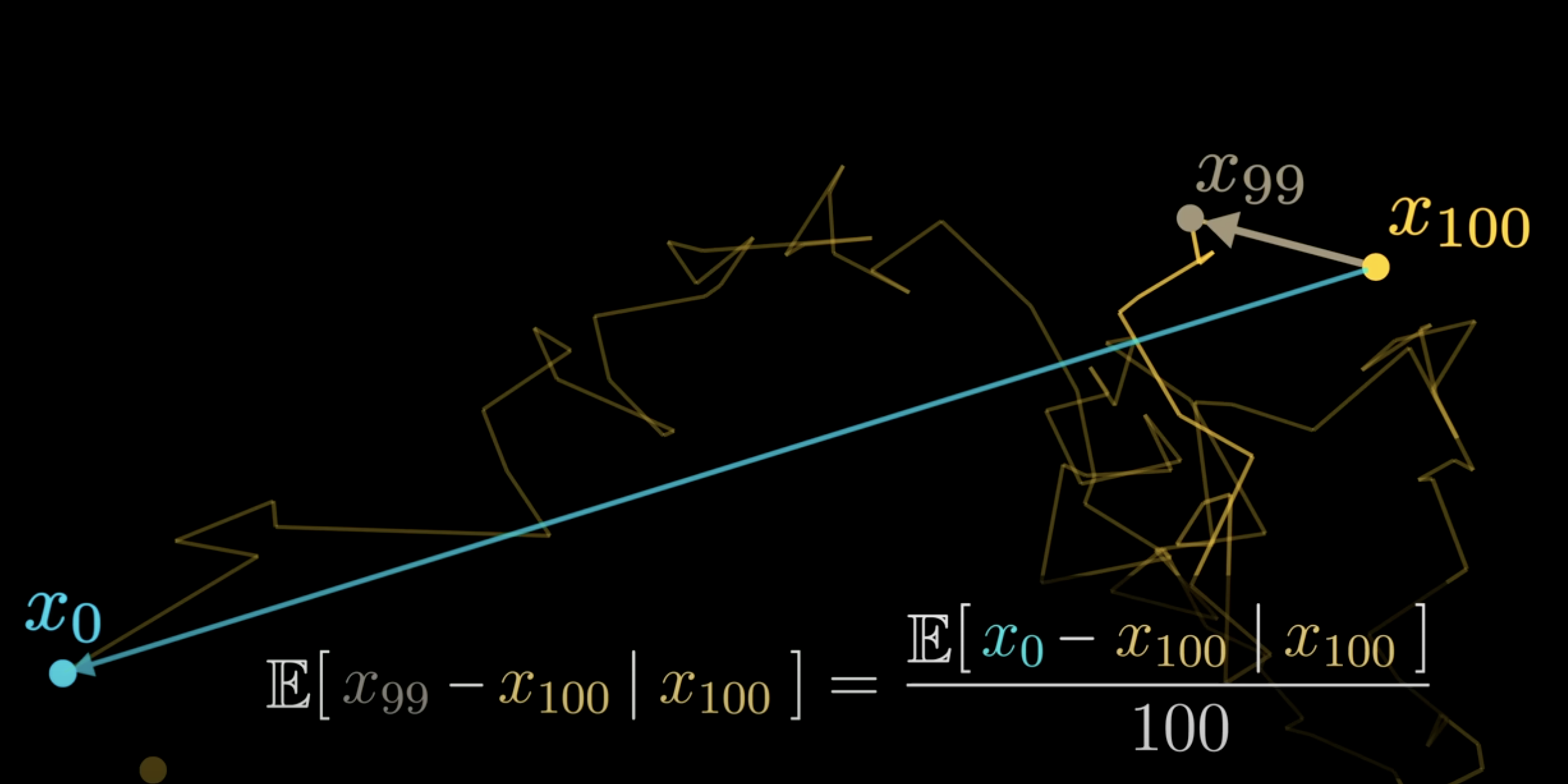
 So the noise added at 100th step, is the average of final noises for all 100 steps
So the noise added at 100th step, is the average of final noises for all 100 steps
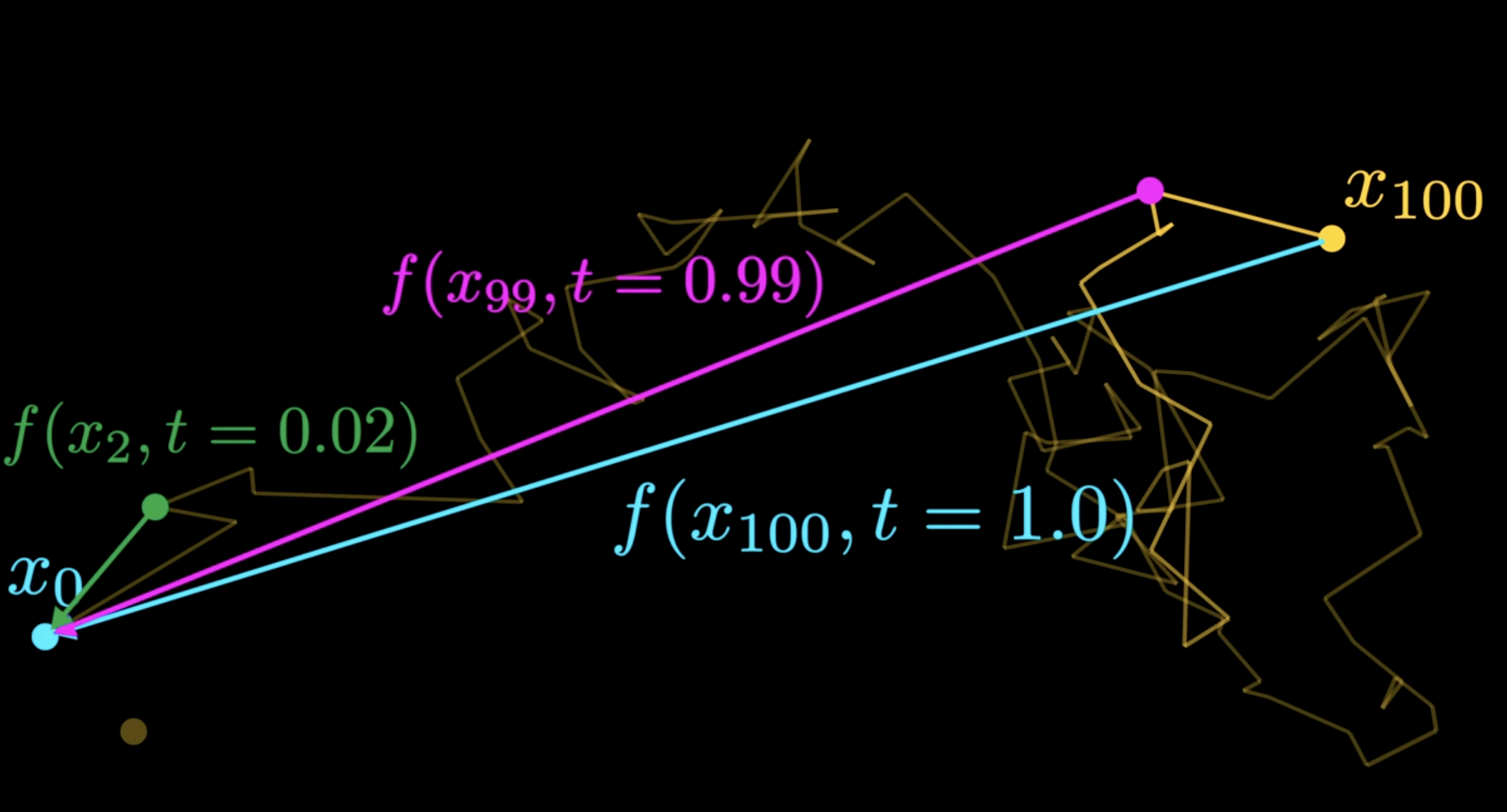
 We can also condition all the noise with time t, so we will learn corse vector field at large time value, and learn very refine structure when t approches zero
We can also condition all the noise with time t, so we will learn corse vector field at large time value, and learn very refine structure when t approches zero
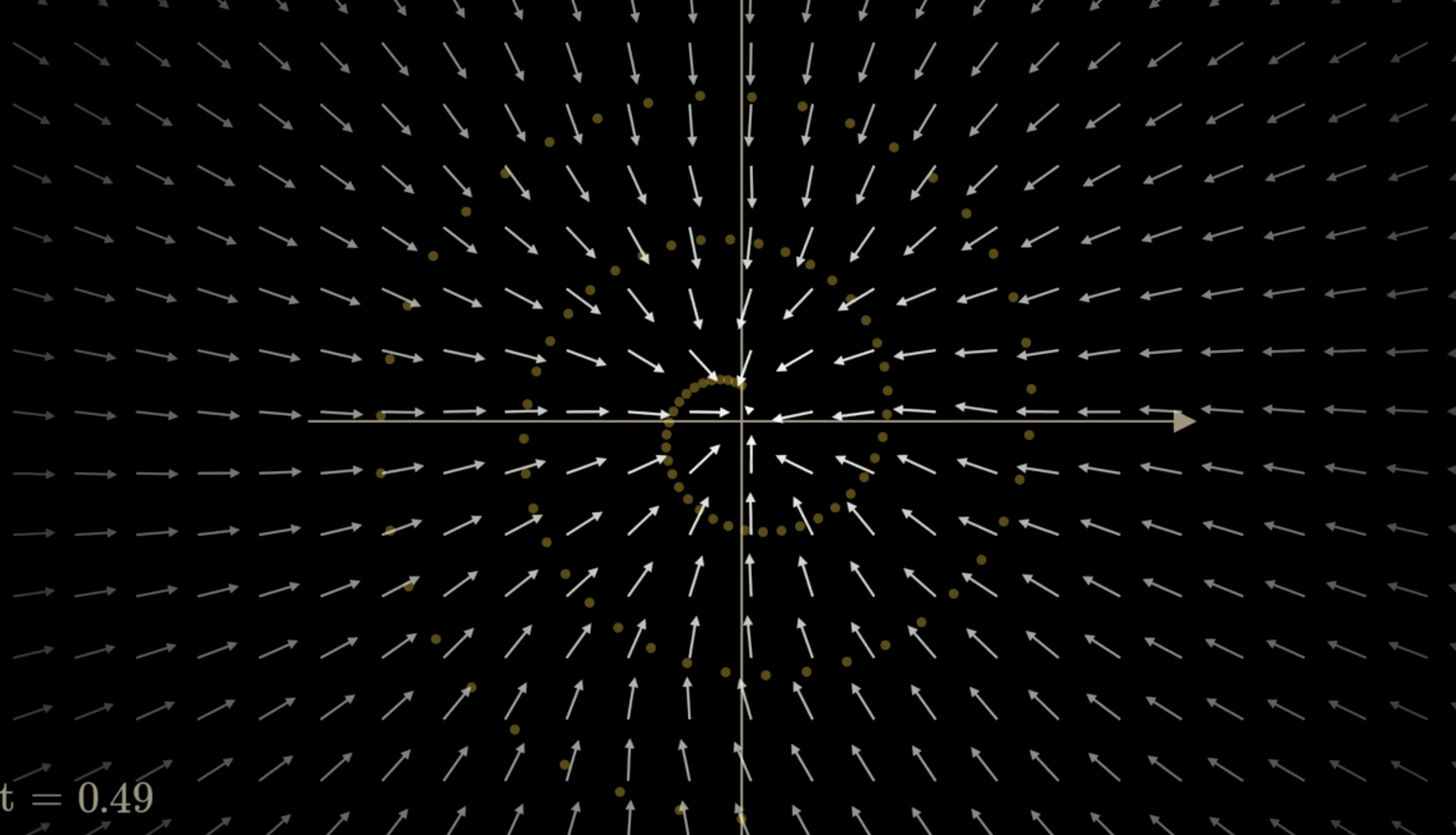
 You can see the direction are pointing to the center of spiral when t>0.4
You can see the direction are pointing to the center of spiral when t>0.4
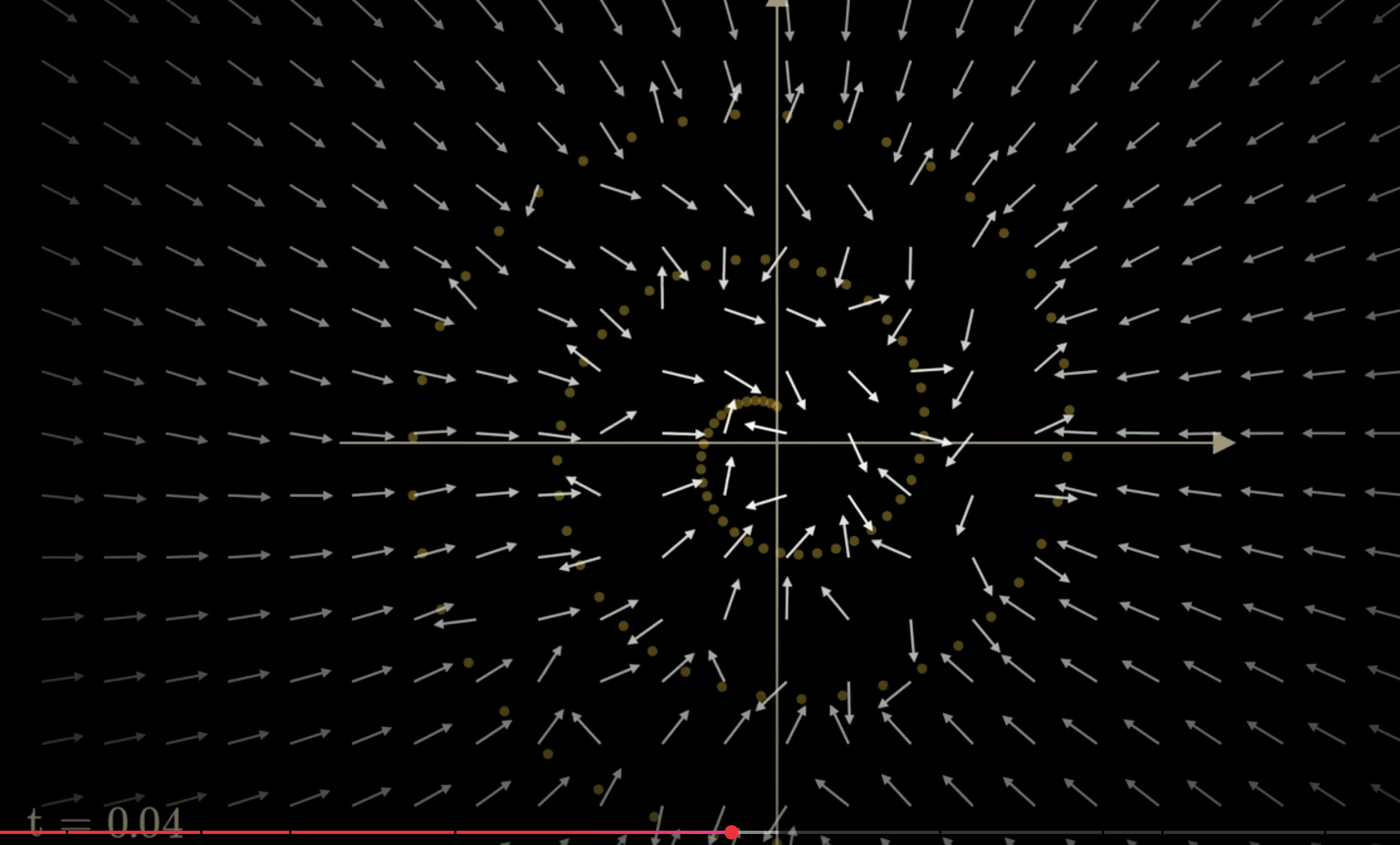
 but point to the spiral itself when t<0.4
but point to the spiral itself when t<0.4
- Now let’s take a look at the why do we need to add random noise at the generation step?
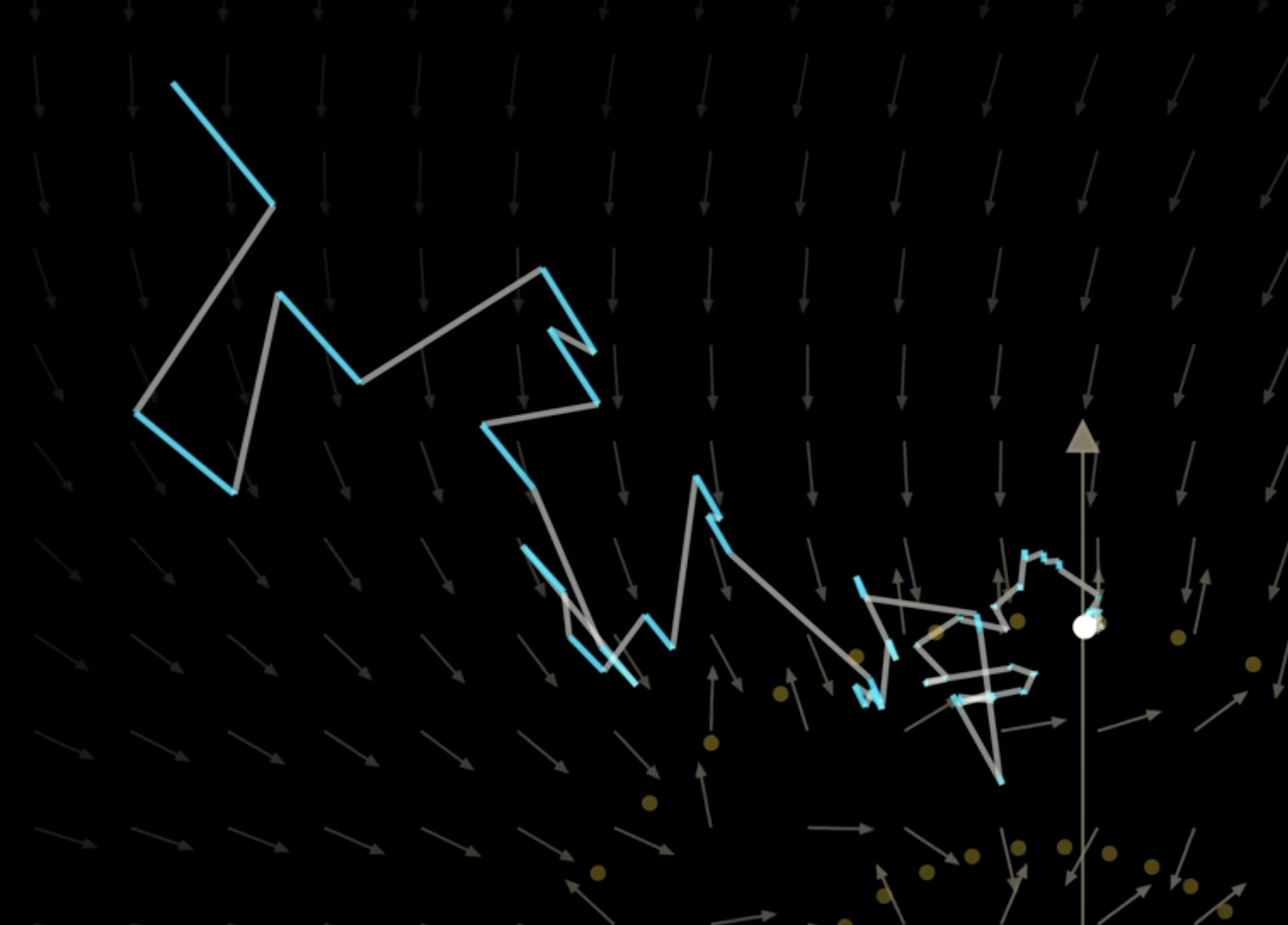
 Here is an illustration of moving points back at each step, blue part is the predicted noise, and grey part is the random noise added. (You can see predicted noise is poinint to the center of spiral)
Here is an illustration of moving points back at each step, blue part is the predicted noise, and grey part is the random noise added. (You can see predicted noise is poinint to the center of spiral)
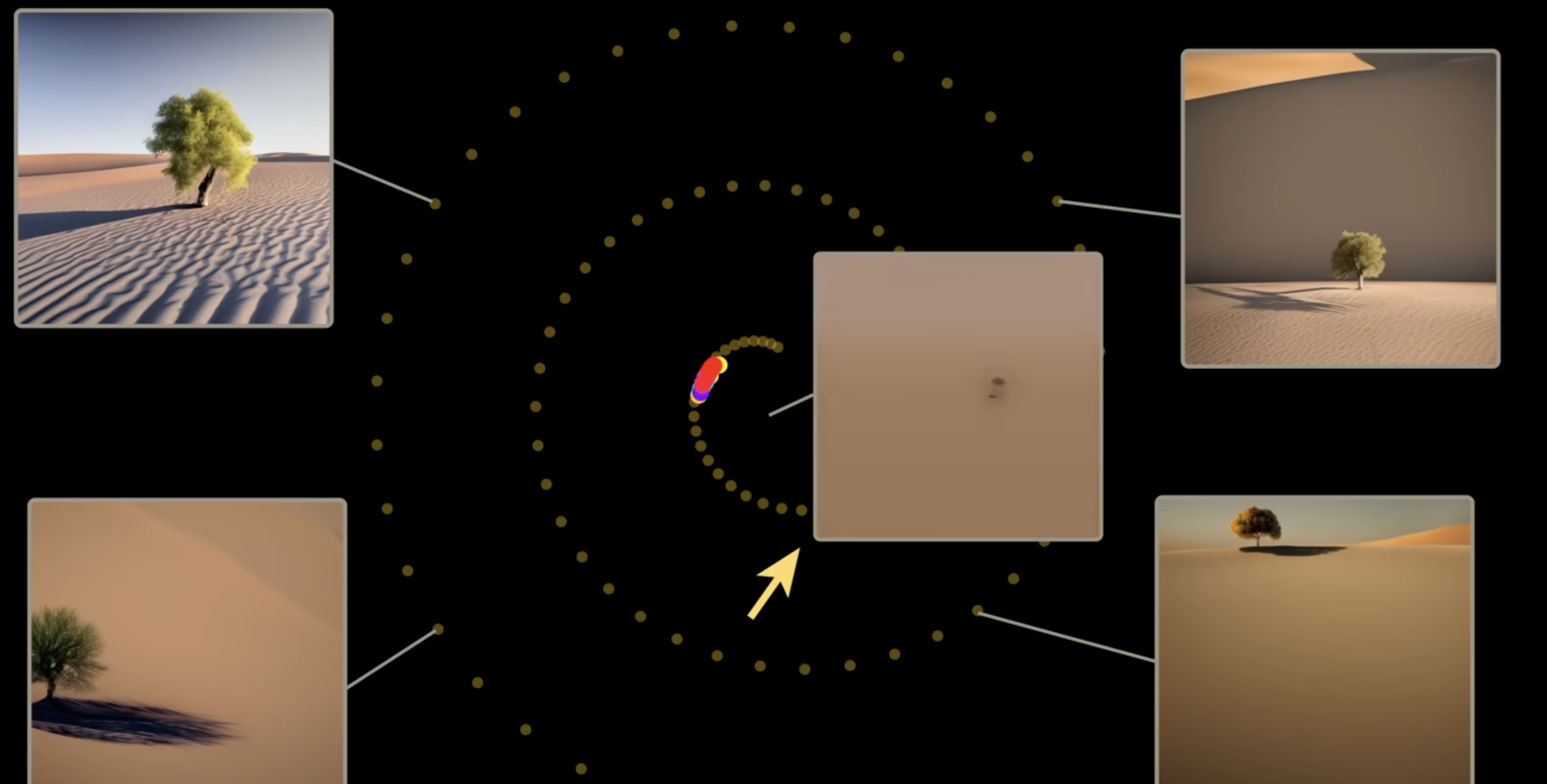
 If we remove this random noise part, all points will be moved to the center of the spiral and left a blurred image. (Here each point is a picture w clear tree)
If we remove this random noise part, all points will be moved to the center of the spiral and left a blurred image. (Here each point is a picture w clear tree)
 Without math work, we can see that the model learns the mean of our noise distribution, but in order to sample from the noise distribution, we should add the zero mean Gaussian.
Without math work, we can see that the model learns the mean of our noise distribution, but in order to sample from the noise distribution, we should add the zero mean Gaussian.

3 DDIM (Denoising Diffusion Implict Model)
To improve the speed of DDPM, DDIM and score base SDE(Stachastic Differential Equation)paper were published.
 The idea is to use a SDE to simulate the random noise steps, and this problem is well studies in statiscal mechanics known as Fokkel-Planck equation.
The idea is to use a SDE to simulate the random noise steps, and this problem is well studies in statiscal mechanics known as Fokkel-Planck equation.
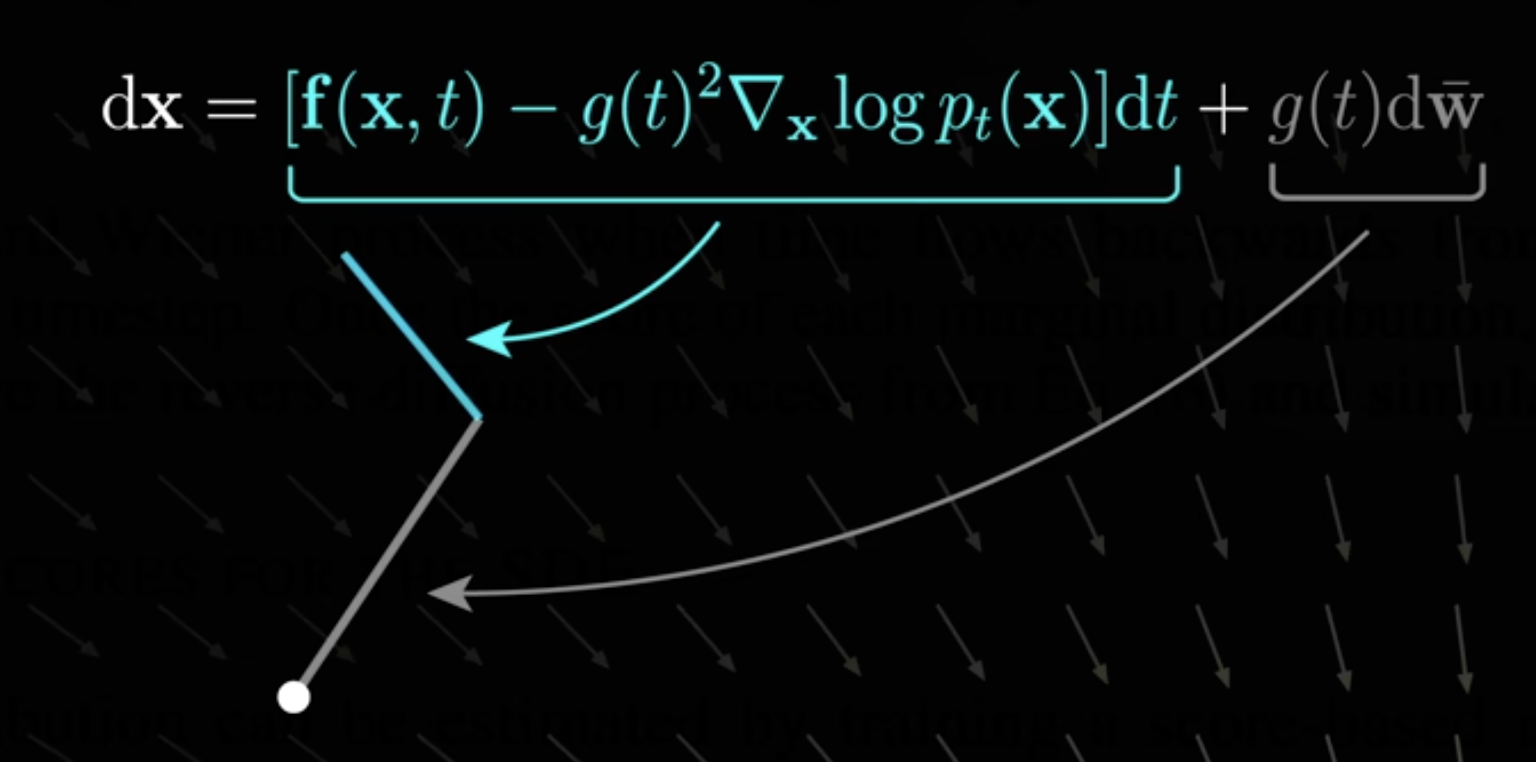 And Google Brain team also showed that a ordinary/deterministic DE can be used here, which leads to DDIM
And Google Brain team also showed that a ordinary/deterministic DE can be used here, which leads to DDIM

4 Conditioning
DALI2 from OAI, is basically an unCLIP approach, use a diffusion model to decode the text embedding back to
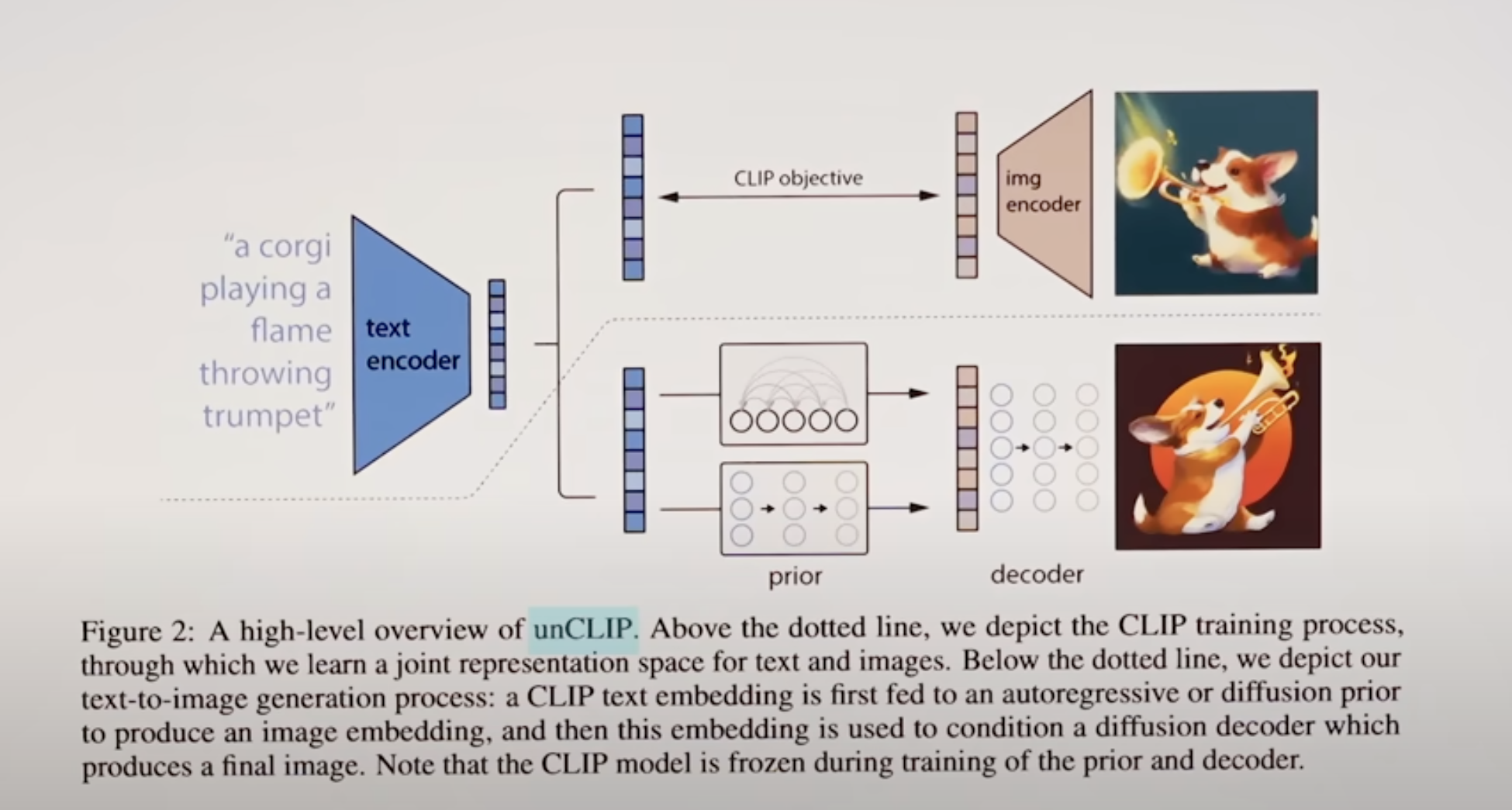 Conditioning text embedding can be directly add to the diffusion model, can be cross-attentioning, add, or even appending.
Conditioning text embedding can be directly add to the diffusion model, can be cross-attentioning, add, or even appending.
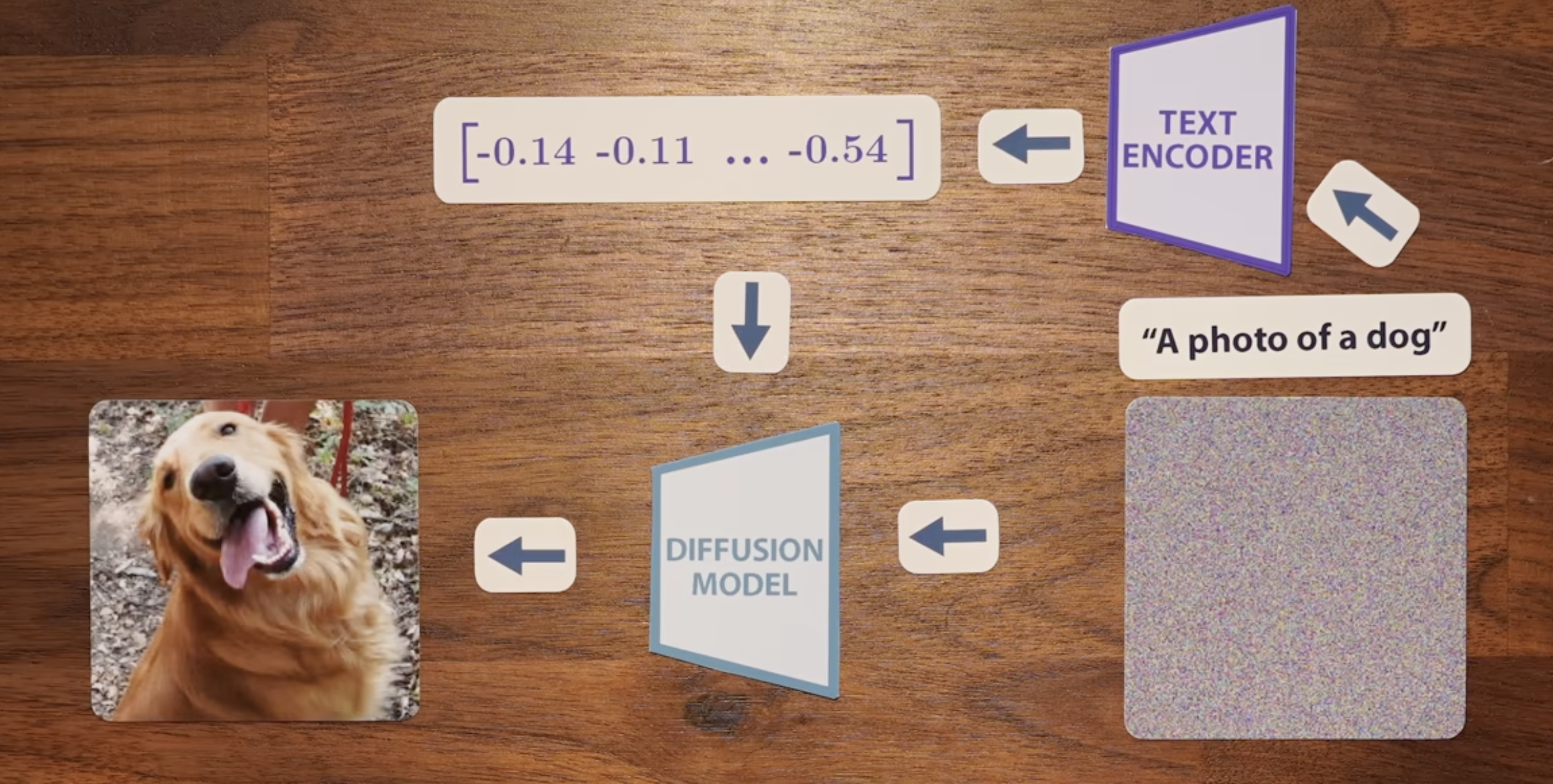
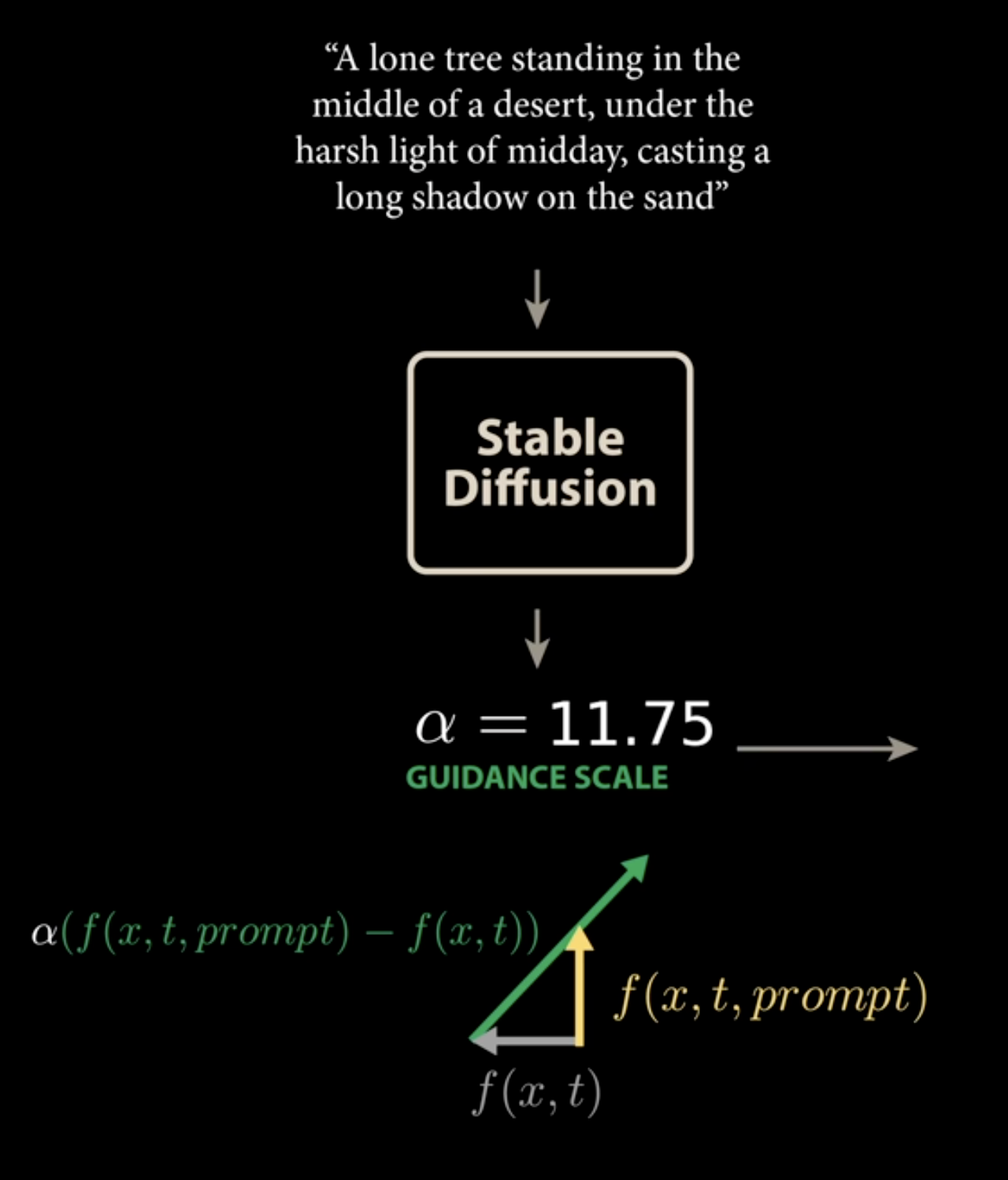
5 Class-Free Guidance
But just adding conditioning is NOT enough for imaging generation. The reasoning being there are two forces of pulling the points back to spiral. The unconditional model is pulling to the center of the spiral, and conditioned vector field guided to the specific part of the spiral. So de-coupling these two vector fields is a key to generate text guided image
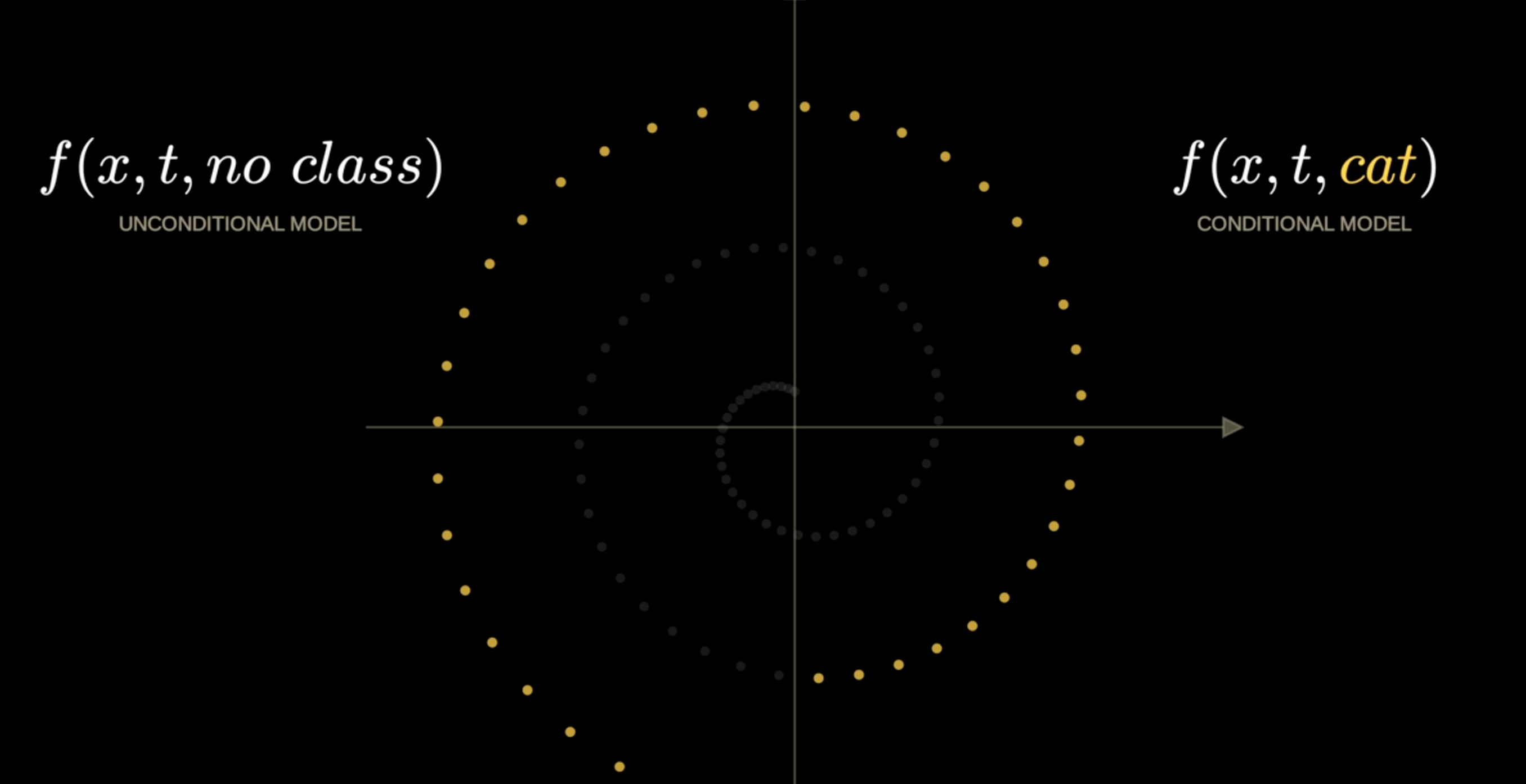 The difference of these two vector, is the class-free guidance
The difference of these two vector, is the class-free guidance
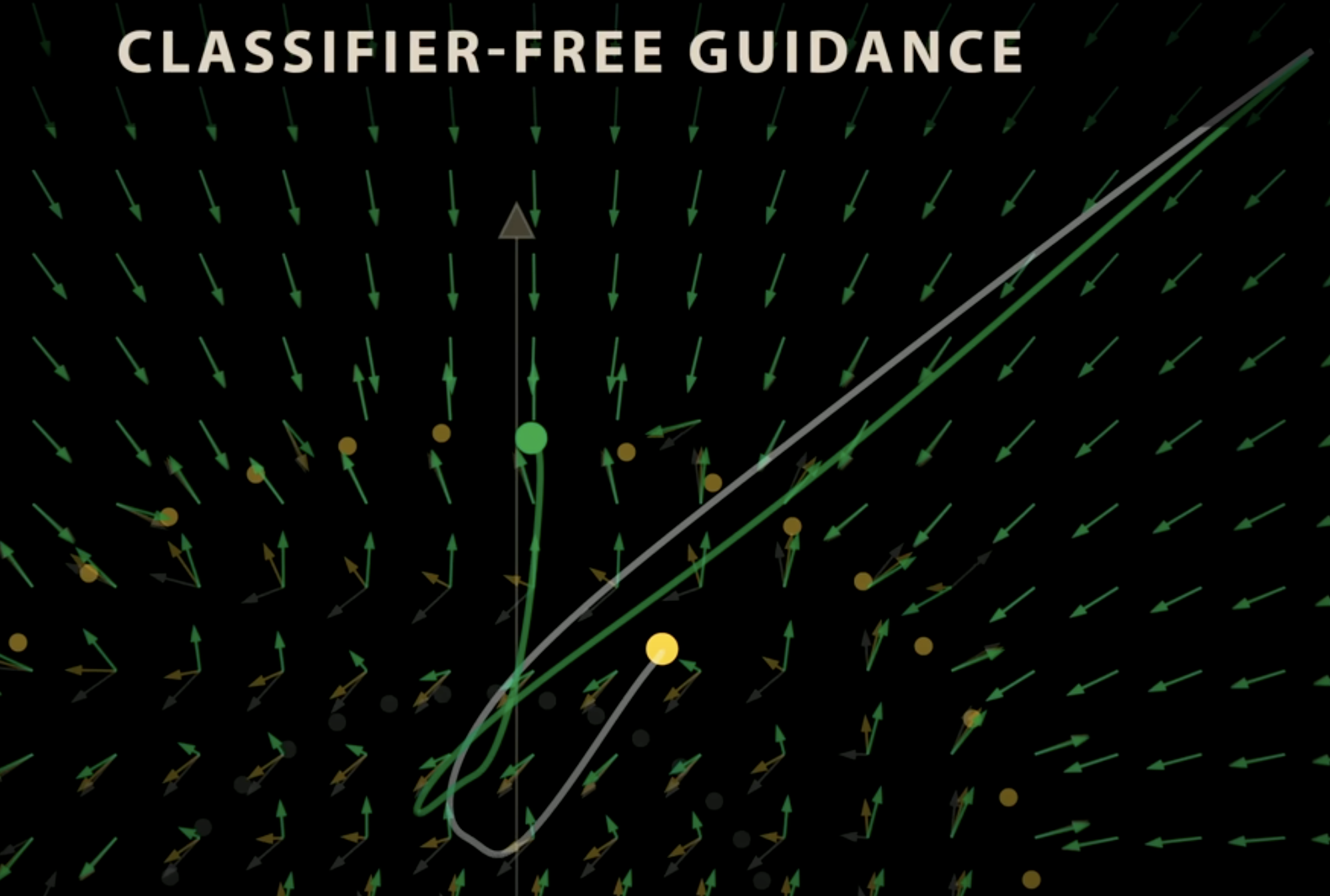 Now we can scale this guidance to generate what we need
Now we can scale this guidance to generate what we need
 and WAN 2.1 also used negative prompting to better shape the guidance
and WAN 2.1 also used negative prompting to better shape the guidance