DeepSeek OCR - Background
A deepseek paper about more Contexts Optical Compression than OCR, which could be the next big break through in VLM field. Great read from EZ encoder video
0 VLM Background
NLP and Vision work in the past decades has been merged into VLM work.
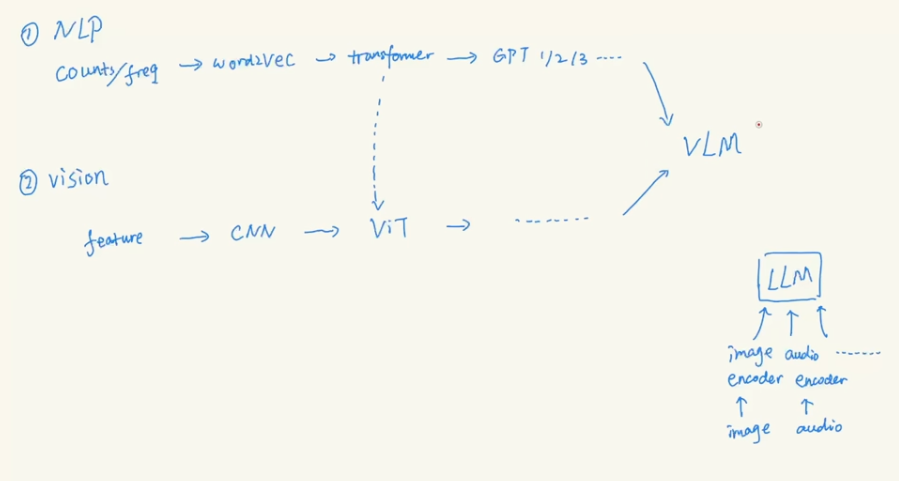 Here are couple of image encoders:
Vision Transformer is split picture into patches, and how to deal with picture with different resolution is the problem from ViT to all the following works
Here are couple of image encoders:
Vision Transformer is split picture into patches, and how to deal with picture with different resolution is the problem from ViT to all the following works
 Swin Transformer is doing CNN with Transformers at different scale, and swin is short for “Shifted Windows”
Swin Transformer is doing CNN with Transformers at different scale, and swin is short for “Shifted Windows”

1 Combine Tokens
To combine text and image tokens, CLIP is a key work from OpenAI
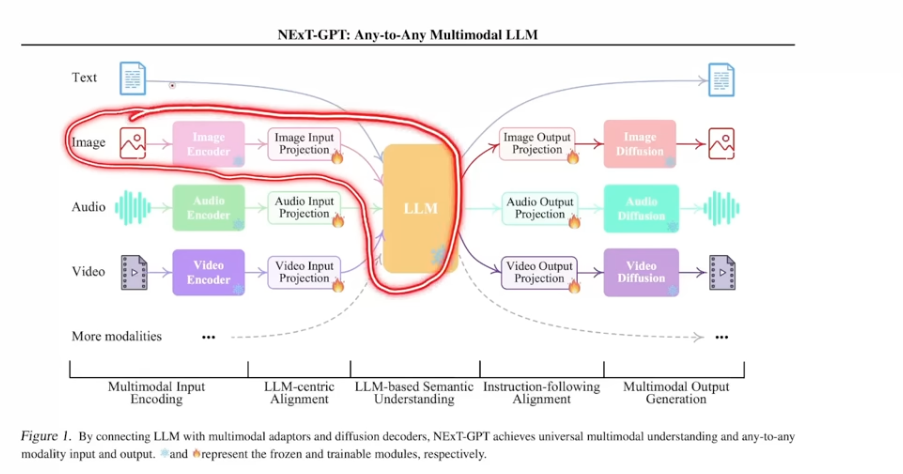
 and this lays fundation of multimodal of working w any other modalities. Here is NExT-GPT paper about it
and this lays fundation of multimodal of working w any other modalities. Here is NExT-GPT paper about it
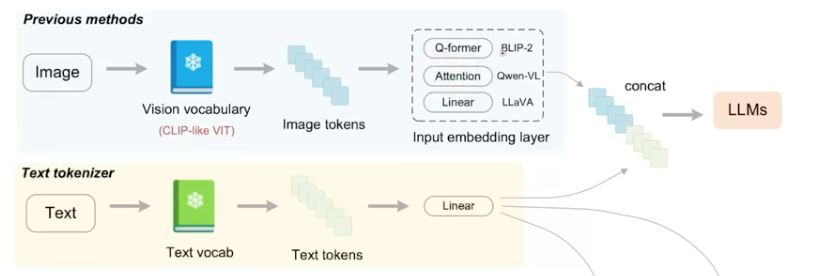
 and there are multiple ways to combine text and image/video tokens, like linear(LLava), attention(Qwen-VL) and cross-attention(Q-former, BLIP-2) (From Haoran’s previous Vary paper)
and there are multiple ways to combine text and image/video tokens, like linear(LLava), attention(Qwen-VL) and cross-attention(Q-former, BLIP-2) (From Haoran’s previous Vary paper)
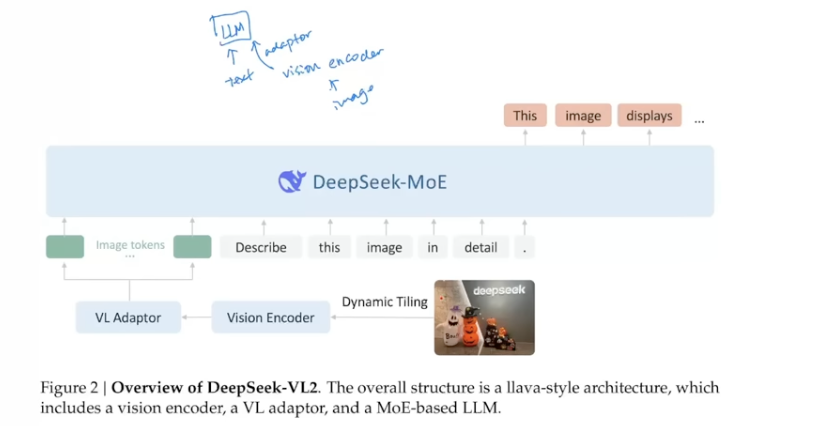
 Another example from DeepSeek-VL2, which uses Dynamic Tiling.
Another example from DeepSeek-VL2, which uses Dynamic Tiling.
 This tiling idea is coming from InternVL 1.5 paper
This tiling idea is coming from InternVL 1.5 paper
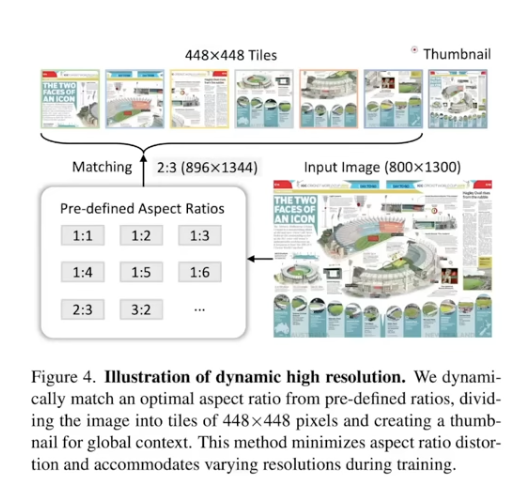
2 Multiple Image Encoders
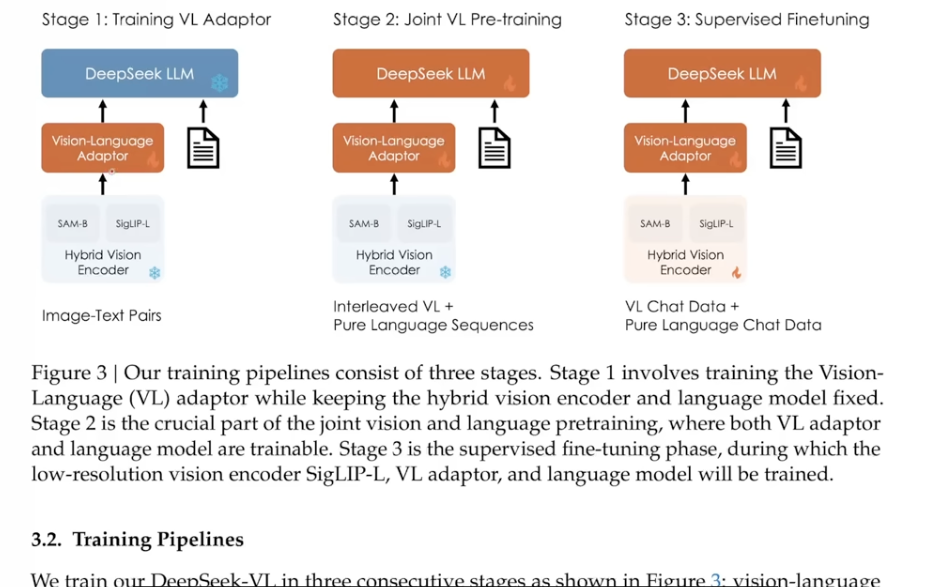
Due to the complicated situation of various images due to size, ratio and resolutions, we may employee multiple image encoders, like DeepSeek-VL paper uses 2 SAM-B and SigLIP-L.
 and Cambrian-1 from LeCun’s team in NYU even push to 4 encoders, SigLIP+DINOv2+ConvNext+CLIP
and Cambrian-1 from LeCun’s team in NYU even push to 4 encoders, SigLIP+DINOv2+ConvNext+CLIP
 Patch-Pack NaViT from Google proposed a way to use encoder for any ratio and resolution – Multiple patches from different images are packed in a single sequence—termed Patch n’ Pack—which enables variable resolution while preserving the aspect ratio. The downside of this method is generating too many tokens
Patch-Pack NaViT from Google proposed a way to use encoder for any ratio and resolution – Multiple patches from different images are packed in a single sequence—termed Patch n’ Pack—which enables variable resolution while preserving the aspect ratio. The downside of this method is generating too many tokens
