DeepSeek OCR
Continue to dive into the OCR paper, which reaches silimar leve to SOTA dots.ocr
0 Fox and OmniBench Benchmark
Fox is short for Focus Anywhere for Fine-grained doc understanding. And the team also published benchmark data and evaluation tools here
and Omnidoc Bench is another popular benchmark for OCR from China
1 DS OCR
The performance is measure by compression rate(how many image token were used vs accuracy).
The paper put current VLM into 3 categories, based on how they process images at different ratio and resolutions.
- Multiple encoder are used for Vary/DeepSeek VL ( 2~4 encoders)
- Tiling method (InternVL and DS VL2)
- Google’s work NatViT (Qwen)
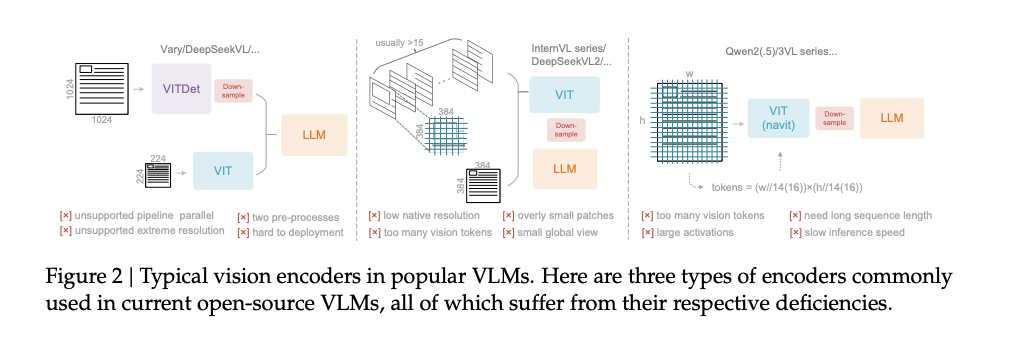
The proposal from this paper is as following, the innovation is mainly from the image encoder.
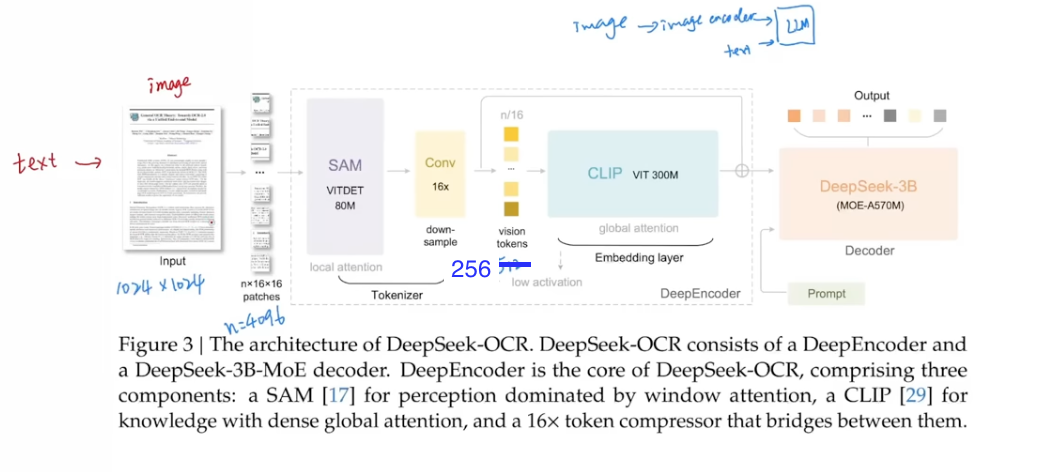 Use SAM for local attention and CLIP for global attention.
Use SAM for local attention and CLIP for global attention.
2 Details in the image encoder
- For a 1024x1024 image, divided into 16x16 patches, and will get (1024/16)^2=64^2=4096 patch tokens. and compress by 16 to get 4096/16=256 tokens, which is huge comperssion from the original text in the image
- The structure is inspired from Vary paper by Haoran.
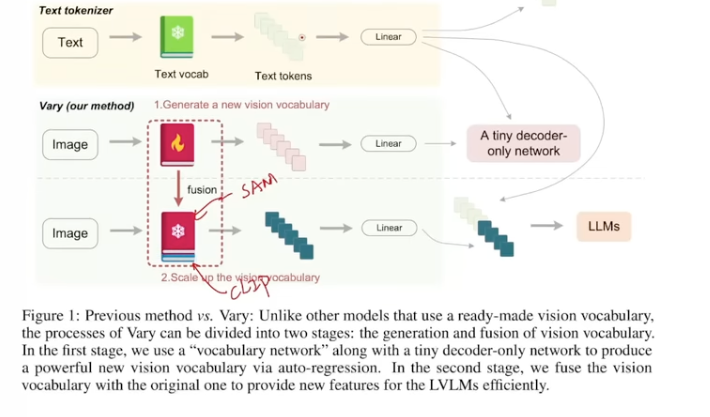 The new vision vocabulary network is essencially the SAM encoder, which is trained first, and then fuse with the CLIP. (The conv is used to change SAM dim to match with CLIP)
The new vision vocabulary network is essencially the SAM encoder, which is trained first, and then fuse with the CLIP. (The conv is used to change SAM dim to match with CLIP)
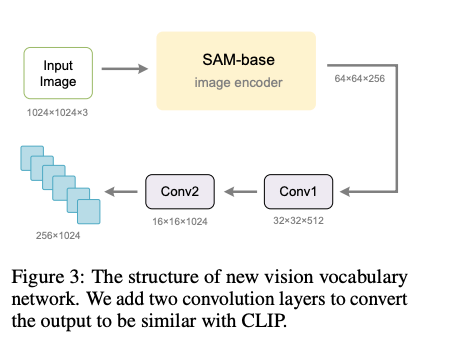
- Change this parallel structure of SAM and CLIP into series strcuture, to reduce token numbers, which is DeepSeek-OCR encoder
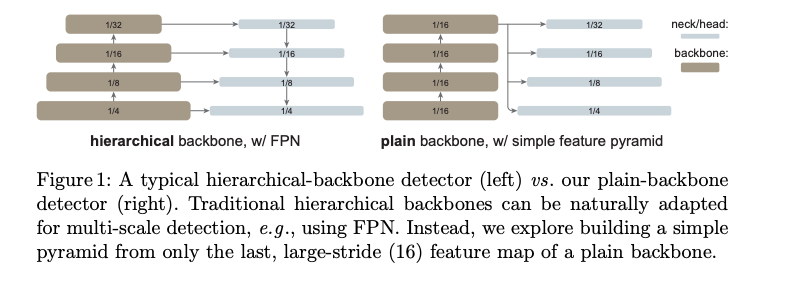
- ViTDET is a modified ViT by Kaiming He, and it’s similar to Swin to do local attention (super simplied version of Swin). The plain backbone Paper link here
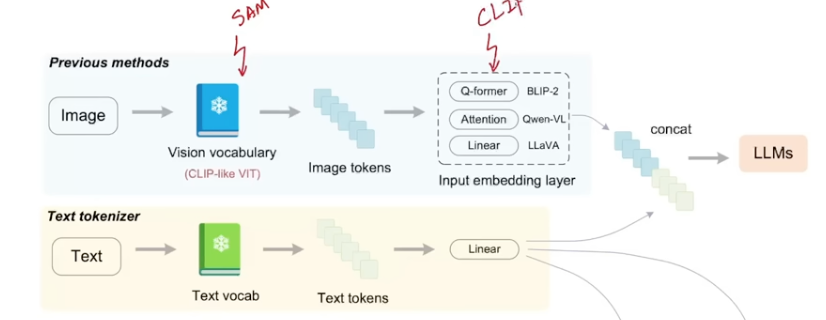
- The embedding layers in the proposal is actually the traditionall adapter, and here DS uses CLIP as the adapter
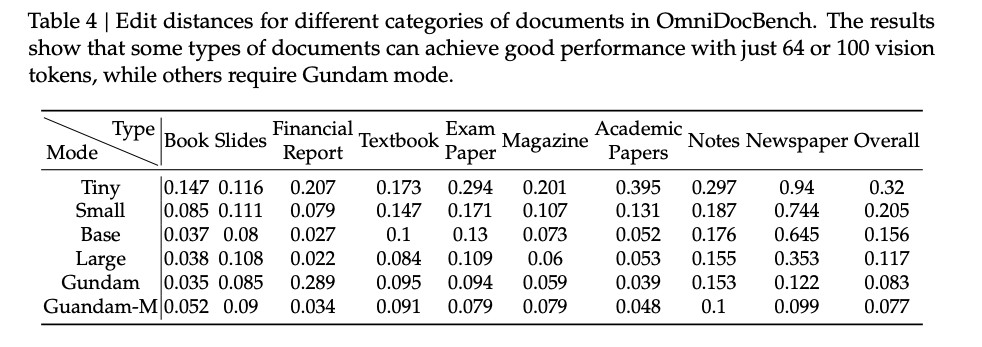
- Different mode, tiny/small, base/large and Gundam, for different resolutions. Tiny/small is not good on newspaper, could be due to large number of text in newspaper
- 3B model and activation at 570M for MoE
- Context compression can use different resolutions from different time, like human memory has different impression for things happening long time ago
