BERT
I think I need to review BERT more closely to undertstand the encoder structure for dLLM. So I checked out this video
0 Encoder
It’s called encoder structure, b/c it outputs an embedding code, CAE
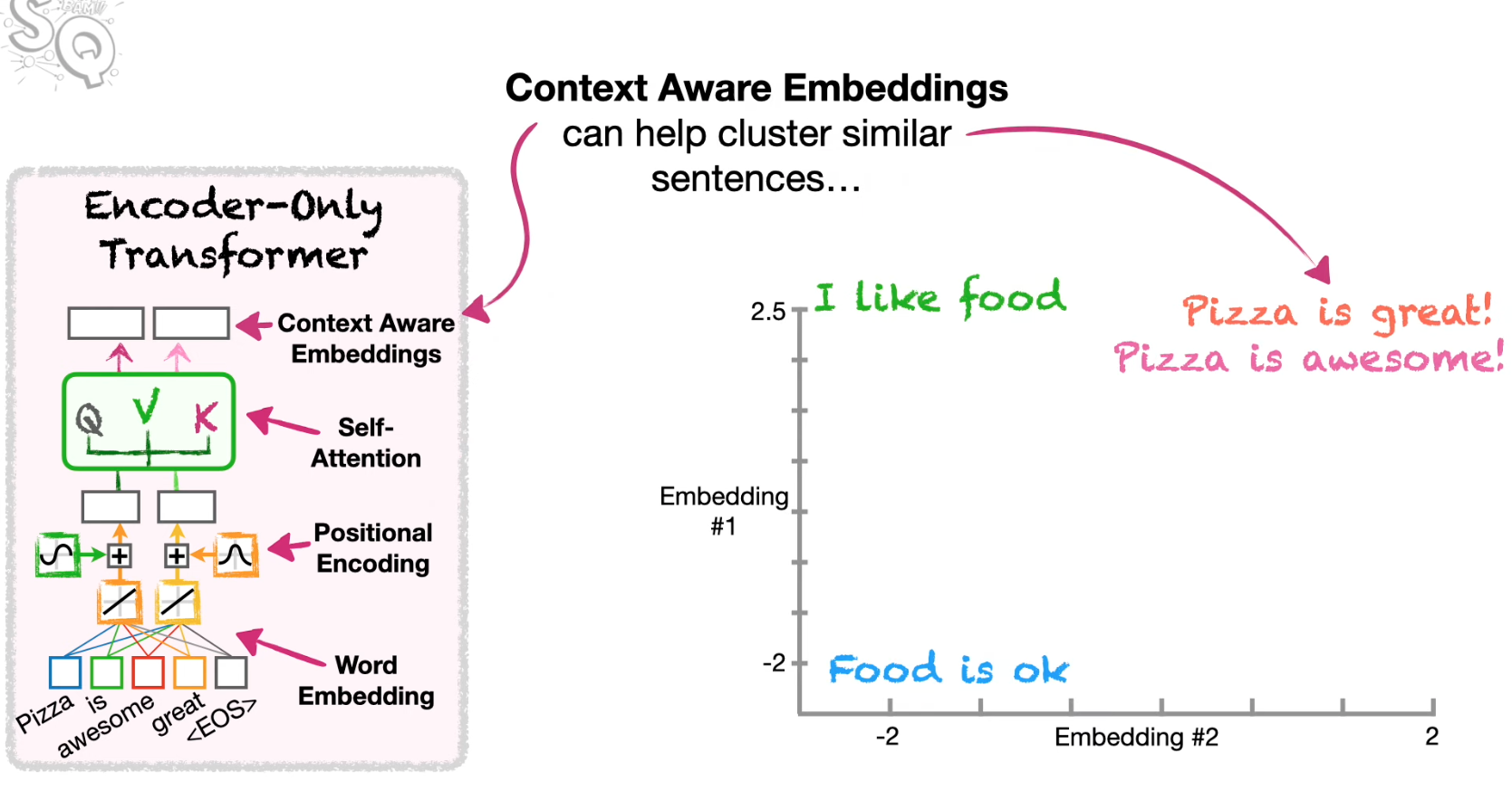
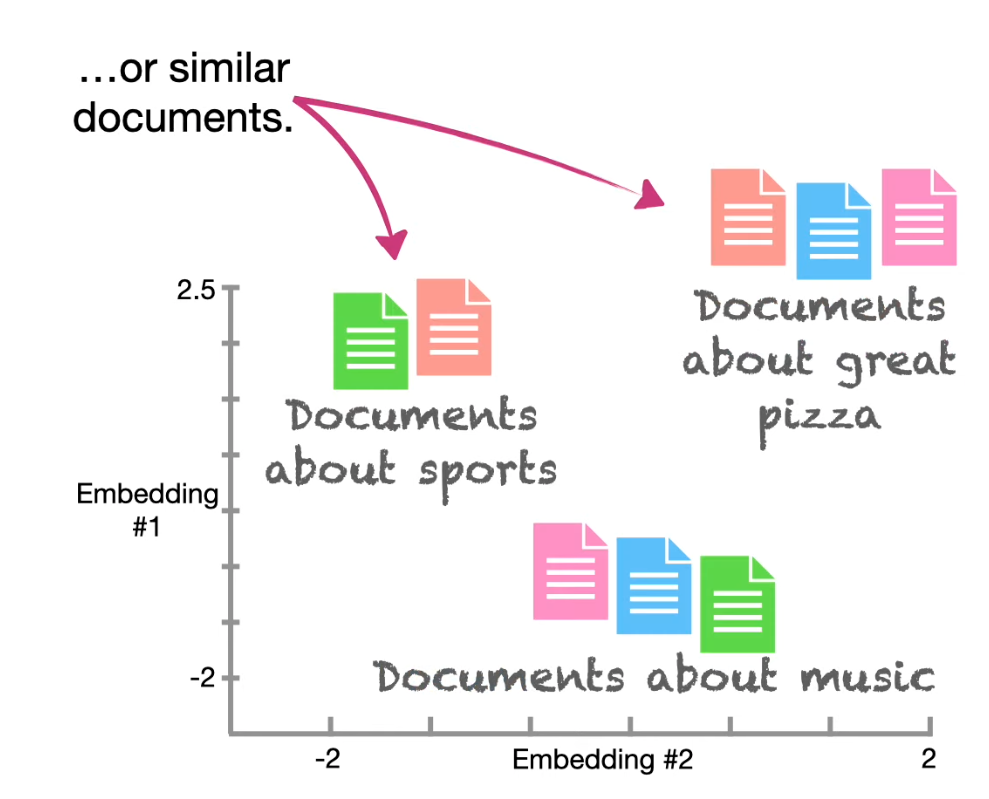
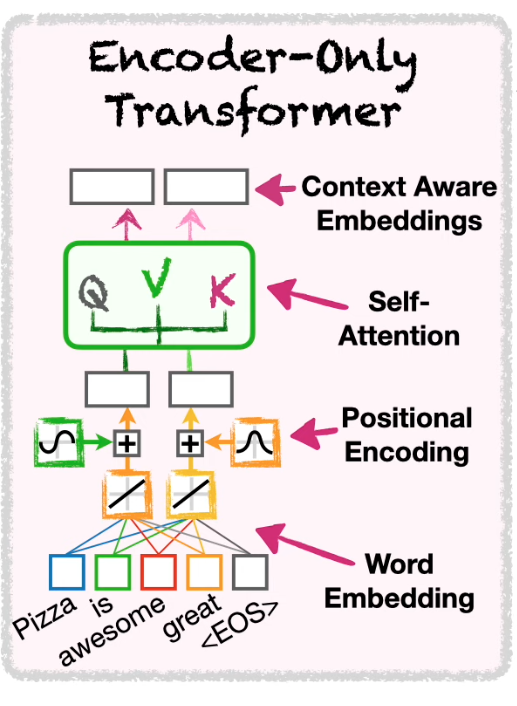 It helps cluster not just words, sentences but documents
It helps cluster not just words, sentences but documents
Now let’s take a closer look at Encoder architecture for Transformers for BERT (video)
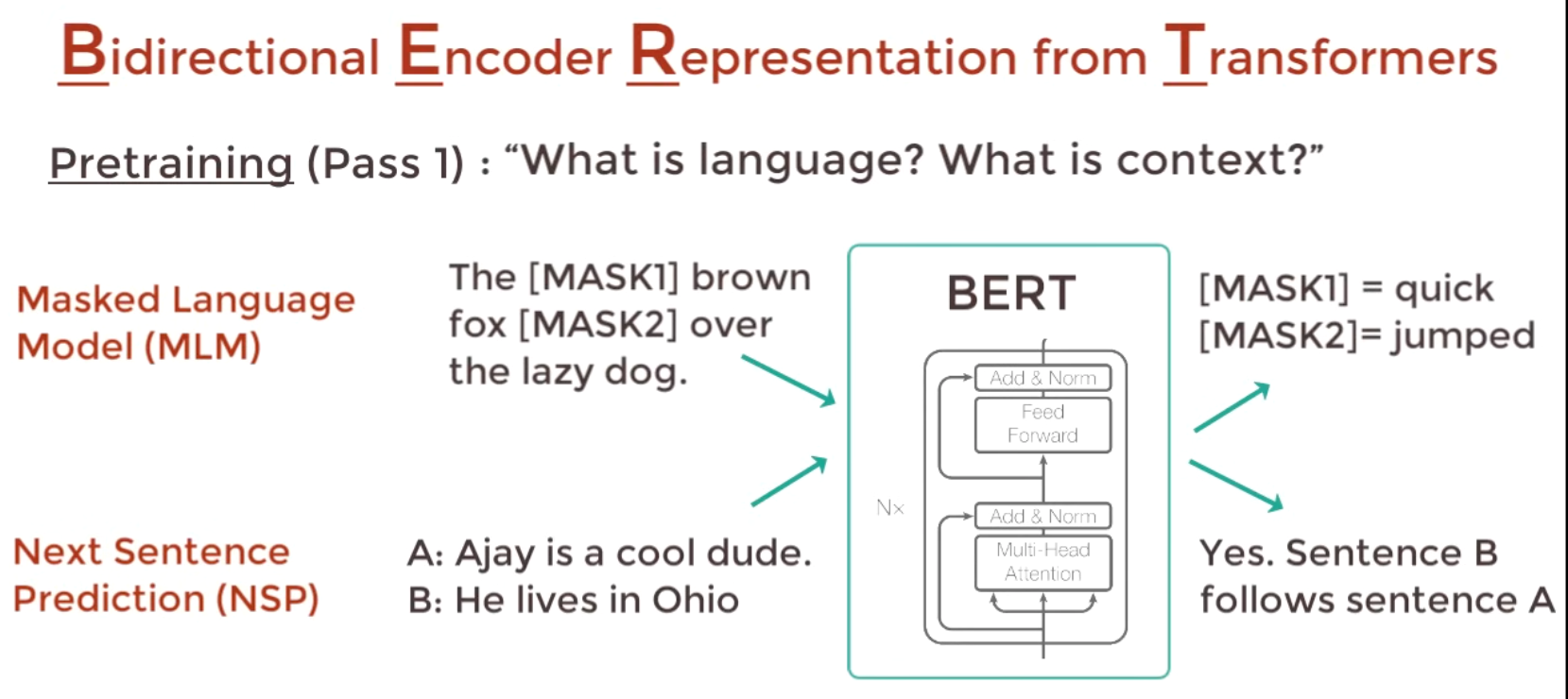
1 BERT Pre-Training
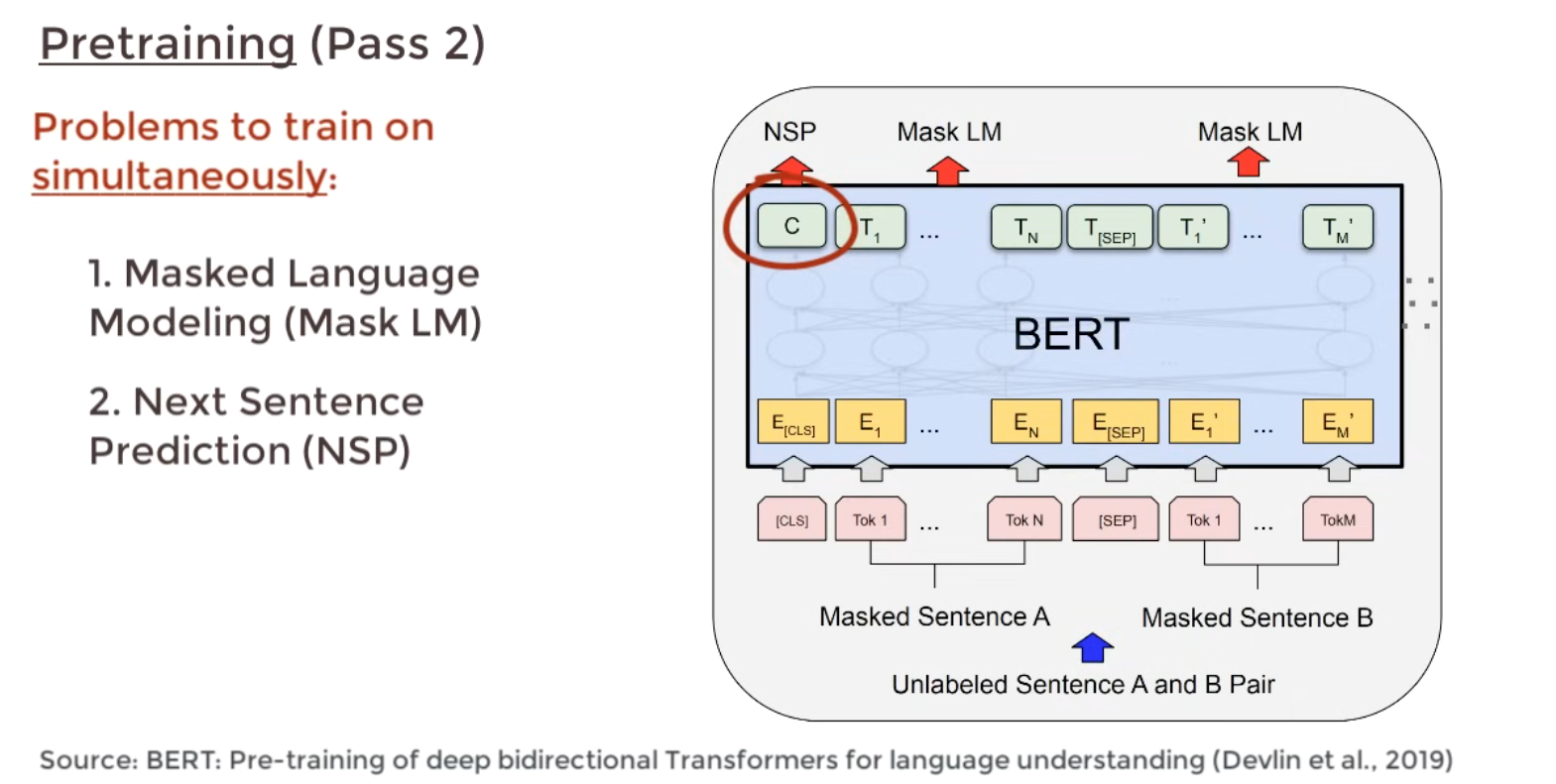
Two phases for the Pretraining phase.
- Masked LM: Fill in the blanks
- Next Setence Prediction: If two sentences are related
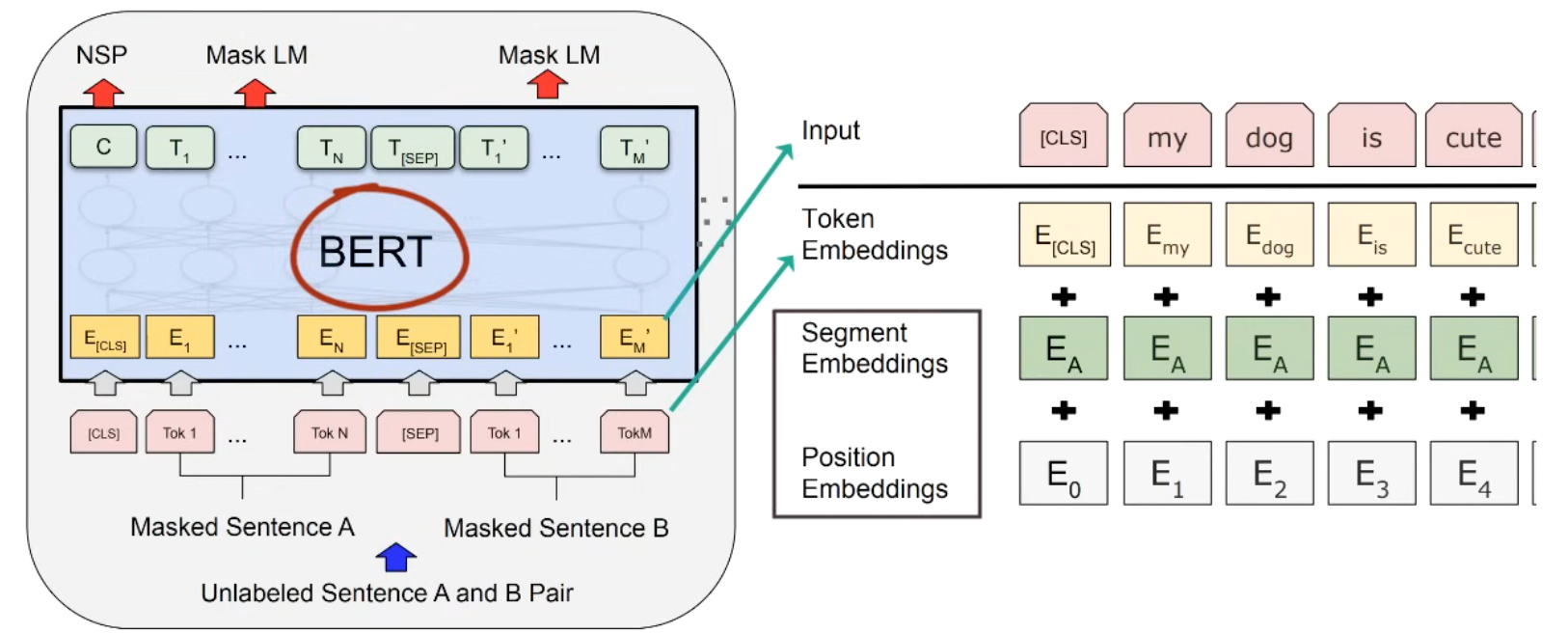
 The input is sum of 3 embeddings
The input is sum of 3 embeddings - Token embedding is from wordpiece w 30k tokens
- Segement embedding is A or B
- Position embedding
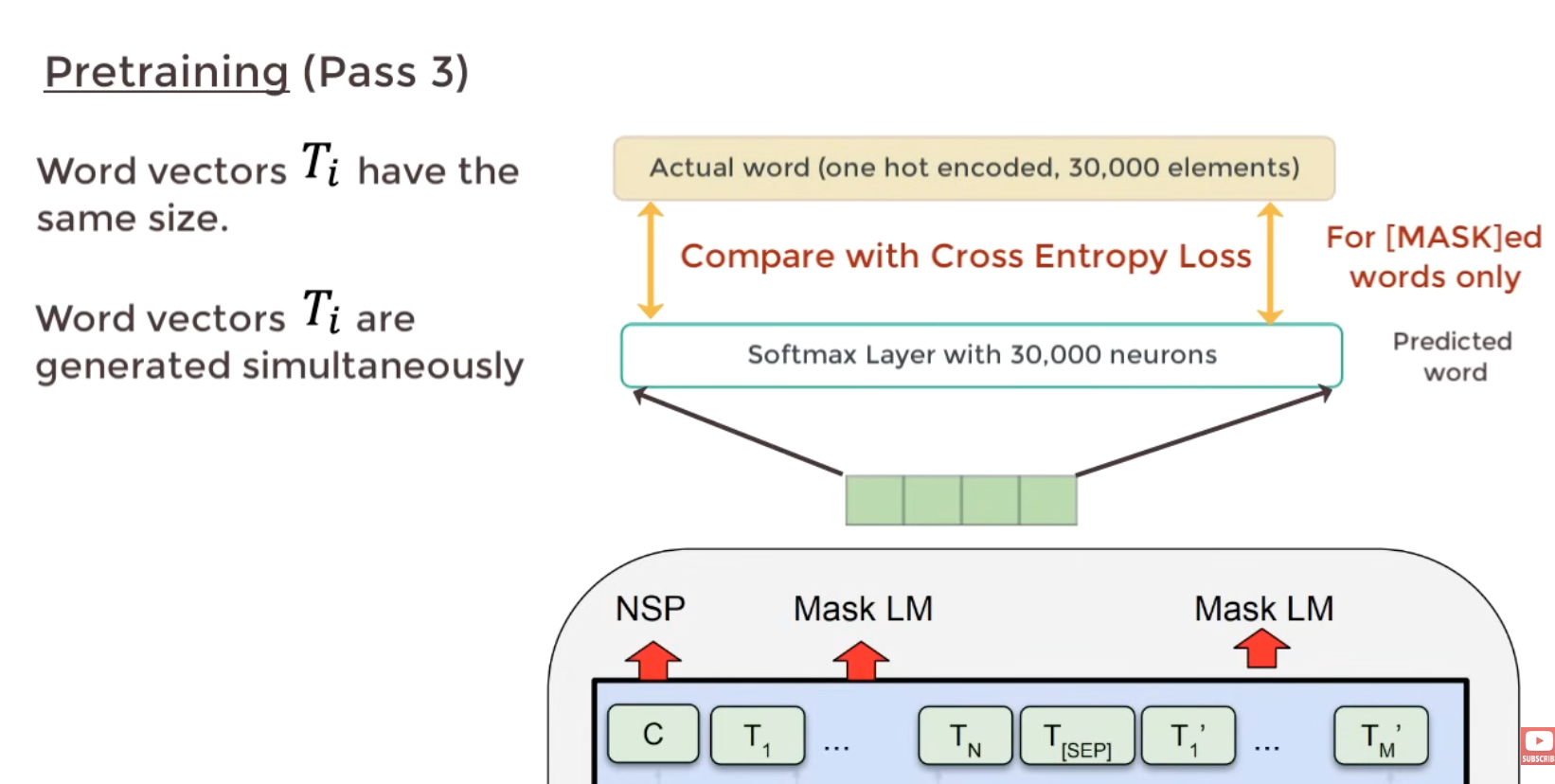
 The output of each word is mapped to 30k neurons (token vocab size) and compaire w one hot encoding for a loss calculation.
The output of each word is mapped to 30k neurons (token vocab size) and compaire w one hot encoding for a loss calculation.
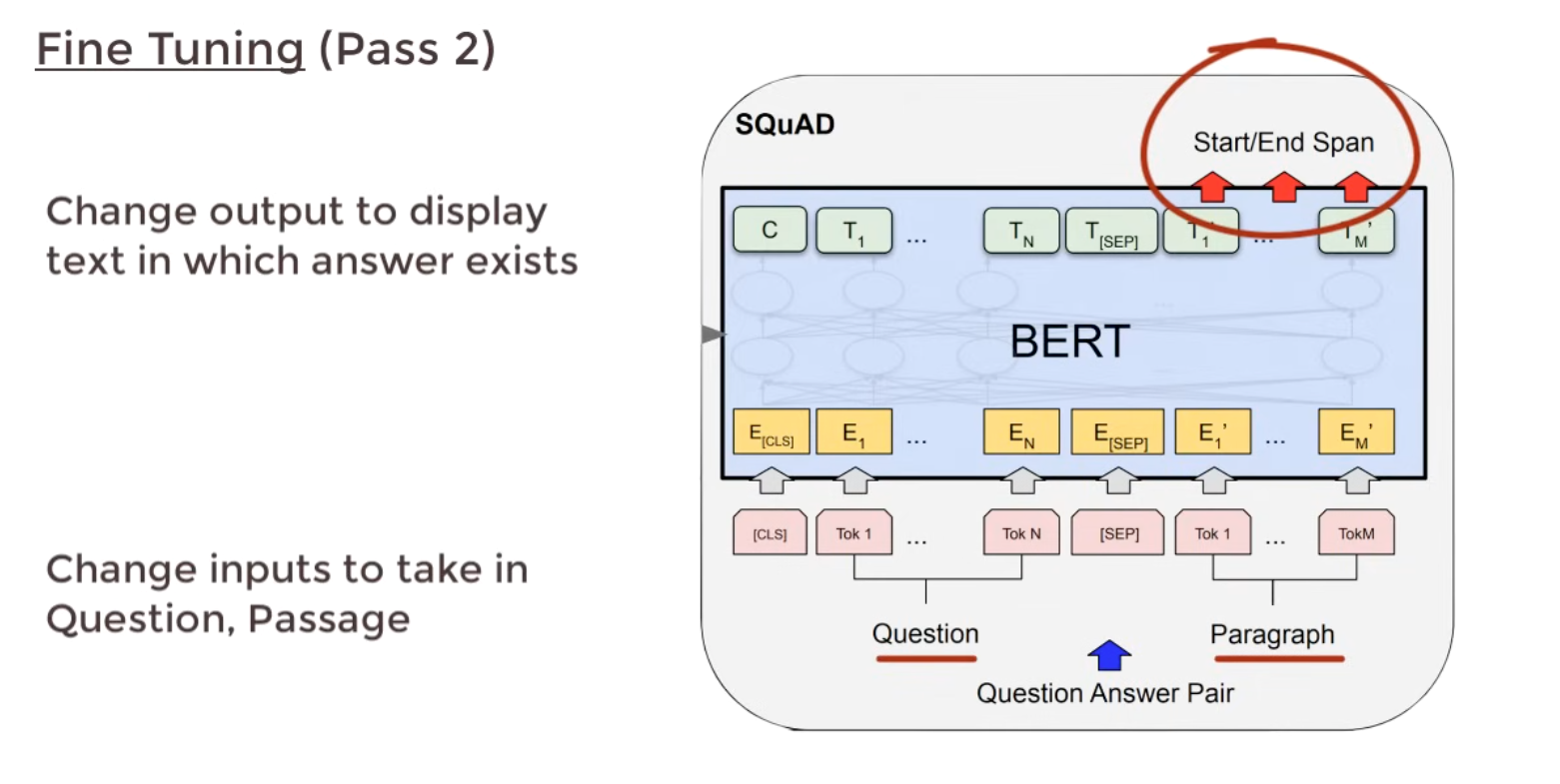
3 BERT Fine Tuning
- The Finetuning is for a Q/A pair
- Only output layer is FTed, so the process is fast
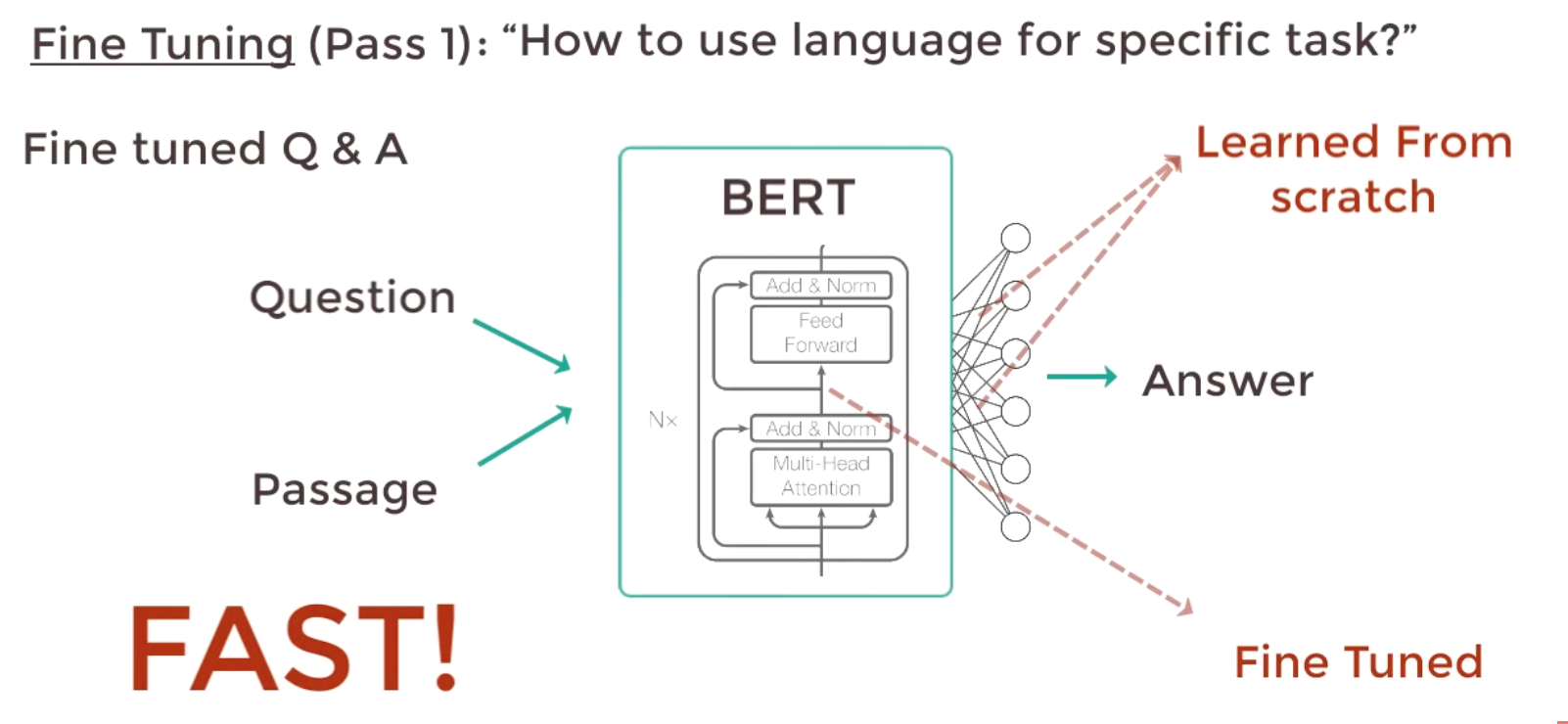
- The input is Question, and a Passage contains the answer
- The output is the start/end words for the answer