Diffusion LLM for real
Video source for dLLM
1 The progress of dLLM
-
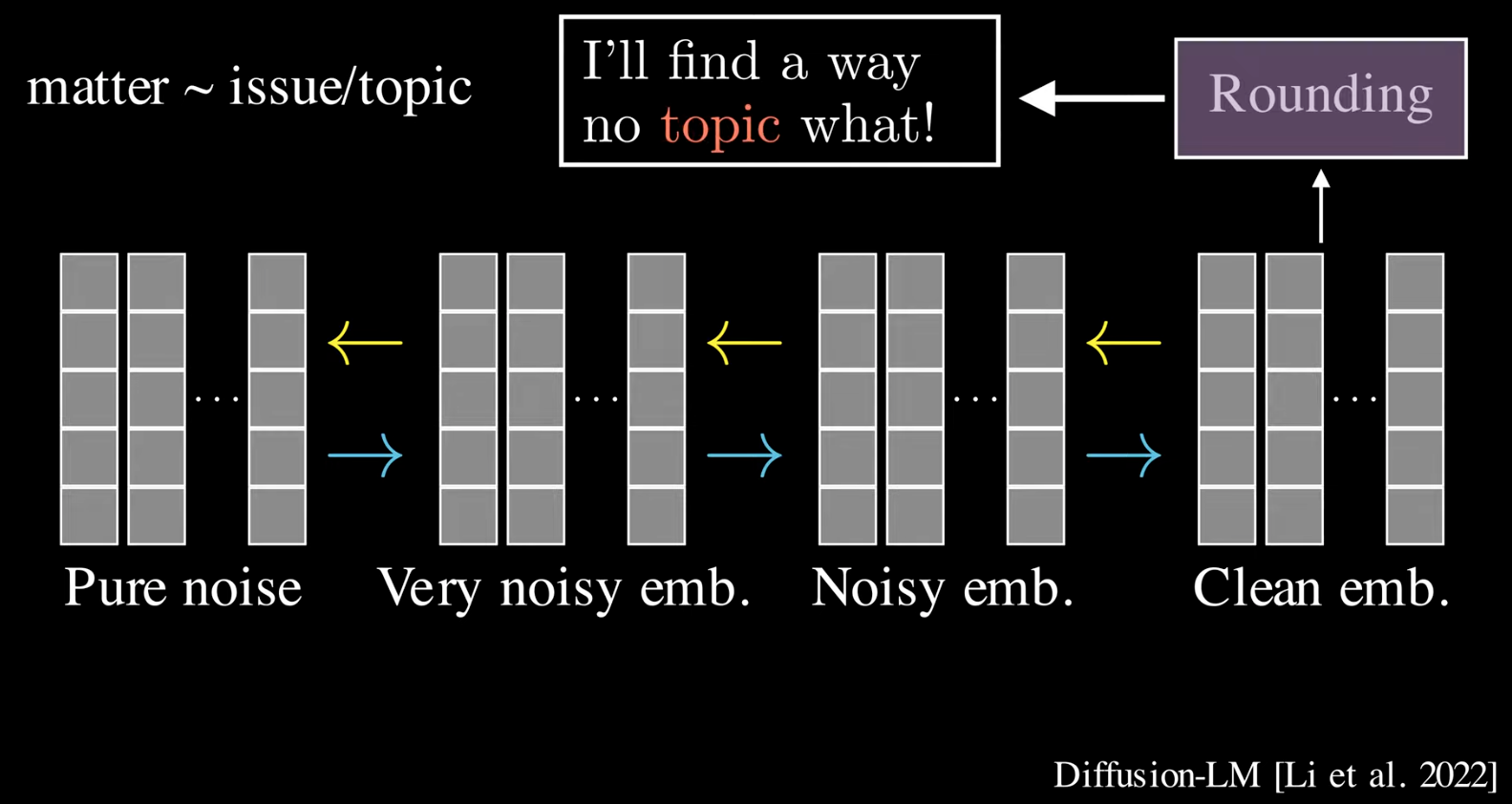
Token level of dLLM By adding noise to token embeddings. The drawbacks is that small numerical error can lead to wrong decoding. Like this example, it meant to be “no matter”, but “matter” is similar to “topic” in token space, and get the a translation with totally different words combination as “no topic”
-
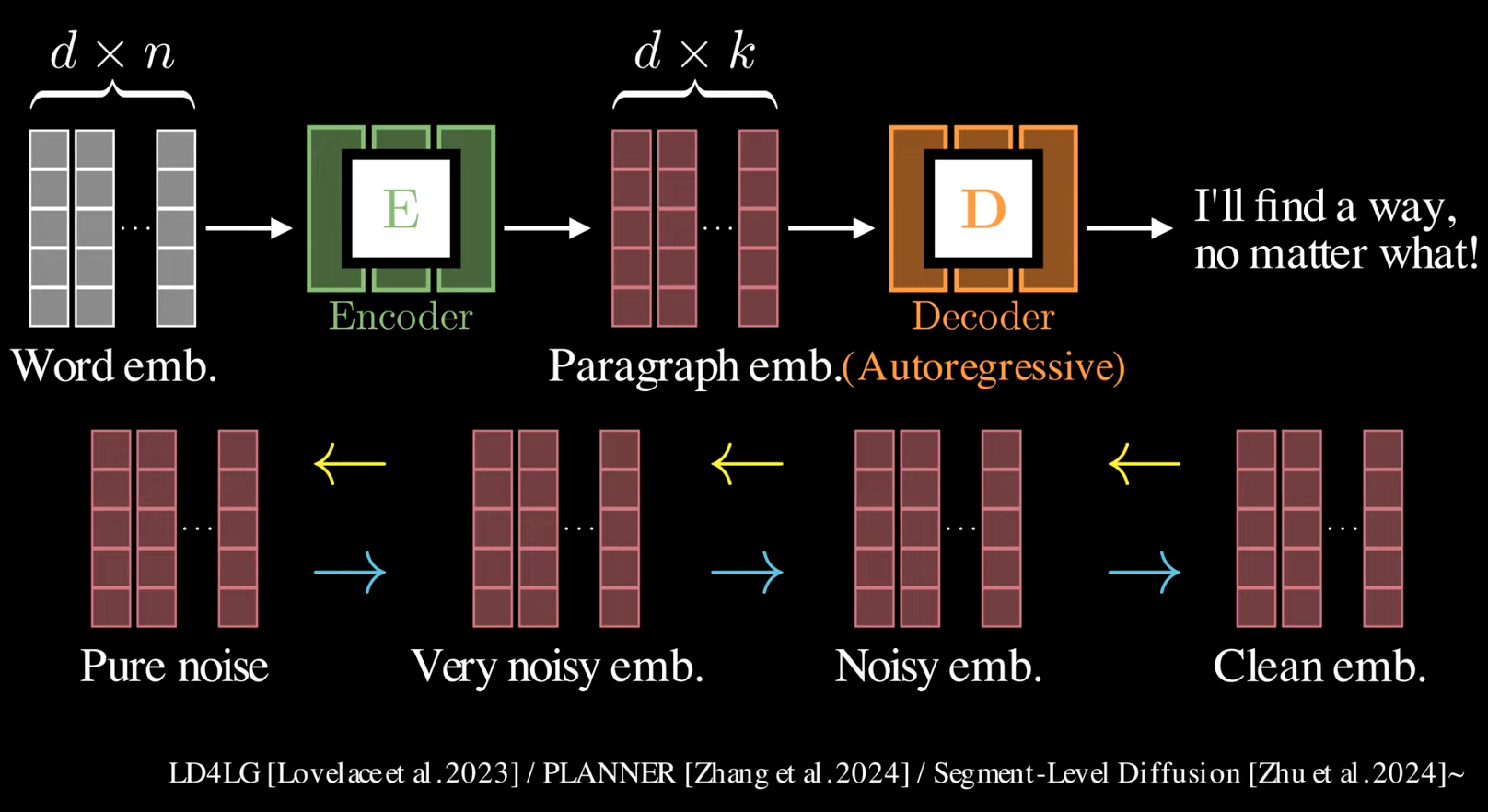
Seg level of dLLM It uses an encoder to convert n tokens into a fixed length k vector. and apply adding noise to the embedding. An AR decoded was used to decode
-
Masked words of dLLM To make it more like image diffusion, a masked version of dLLM is here. Each word is a one-hot encoding, so use a special position for the mask
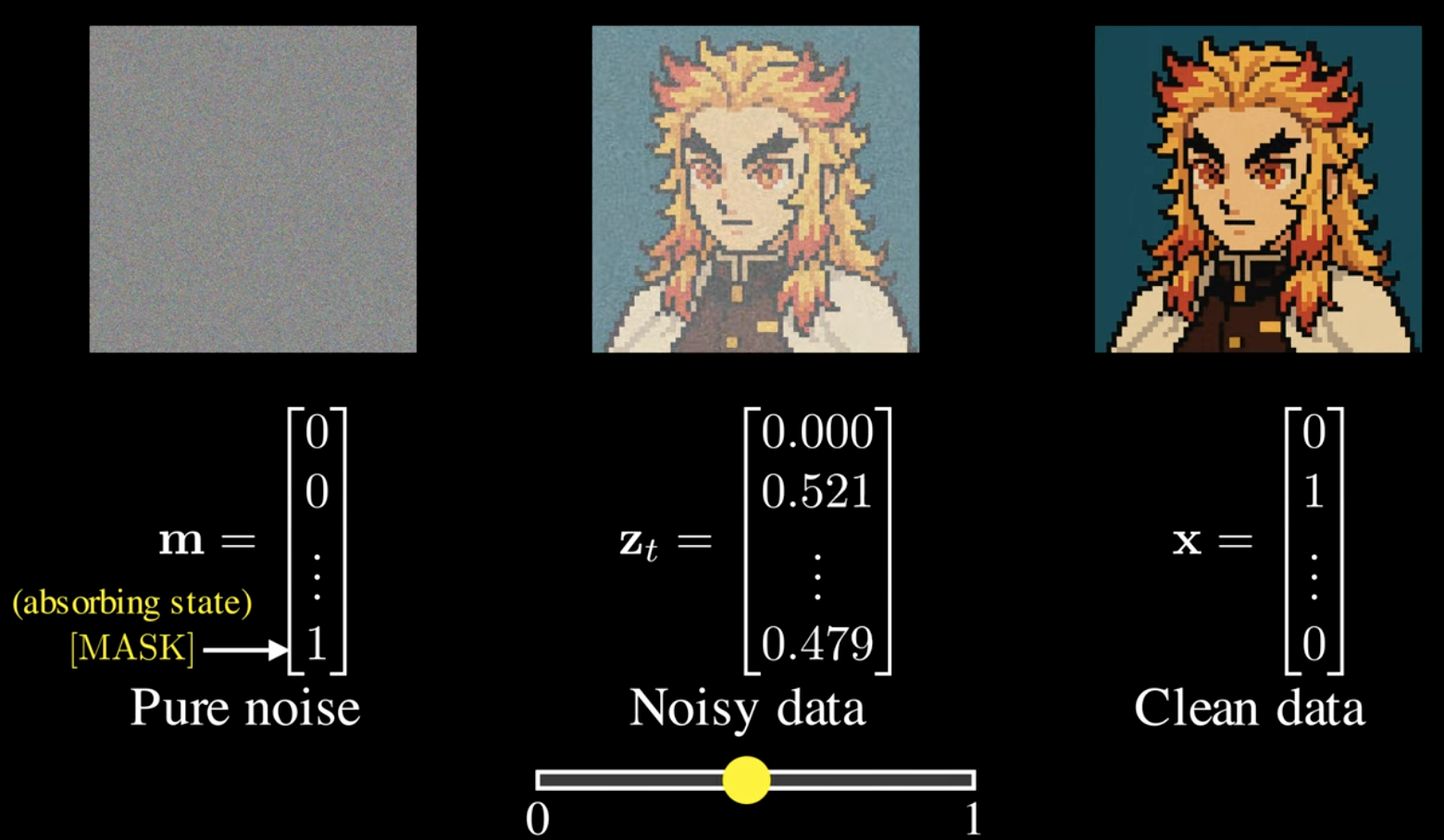 So words are generated at each step with certain masked words get de-masked
So words are generated at each step with certain masked words get de-masked
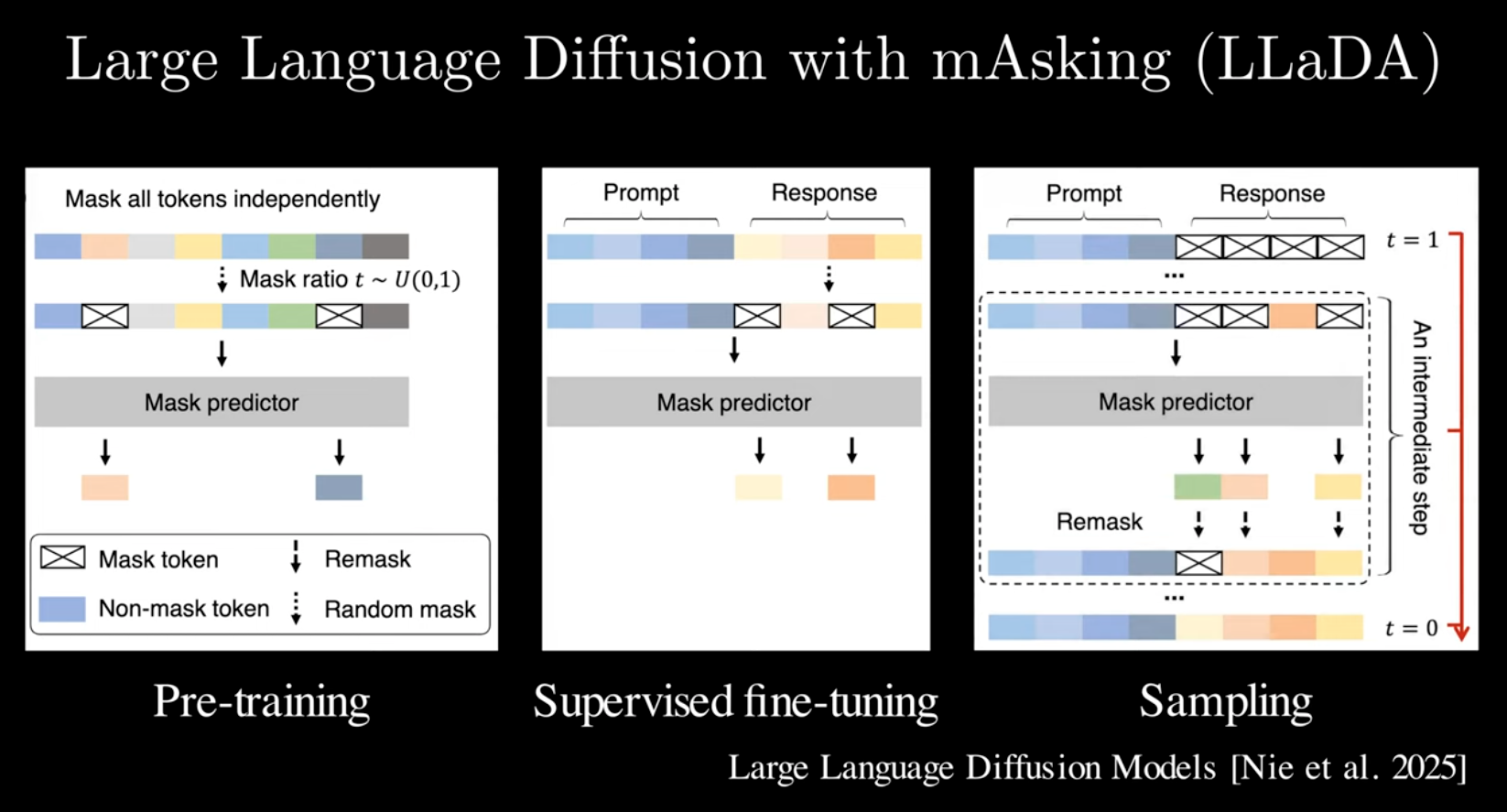
 An issue is that unmasked words can NOT be fixed once unmasked. So new methods are used to remask words if needed.
An issue is that unmasked words can NOT be fixed once unmasked. So new methods are used to remask words if needed.
 This is highlevel of LlaDa works
This is highlevel of LlaDa works
-
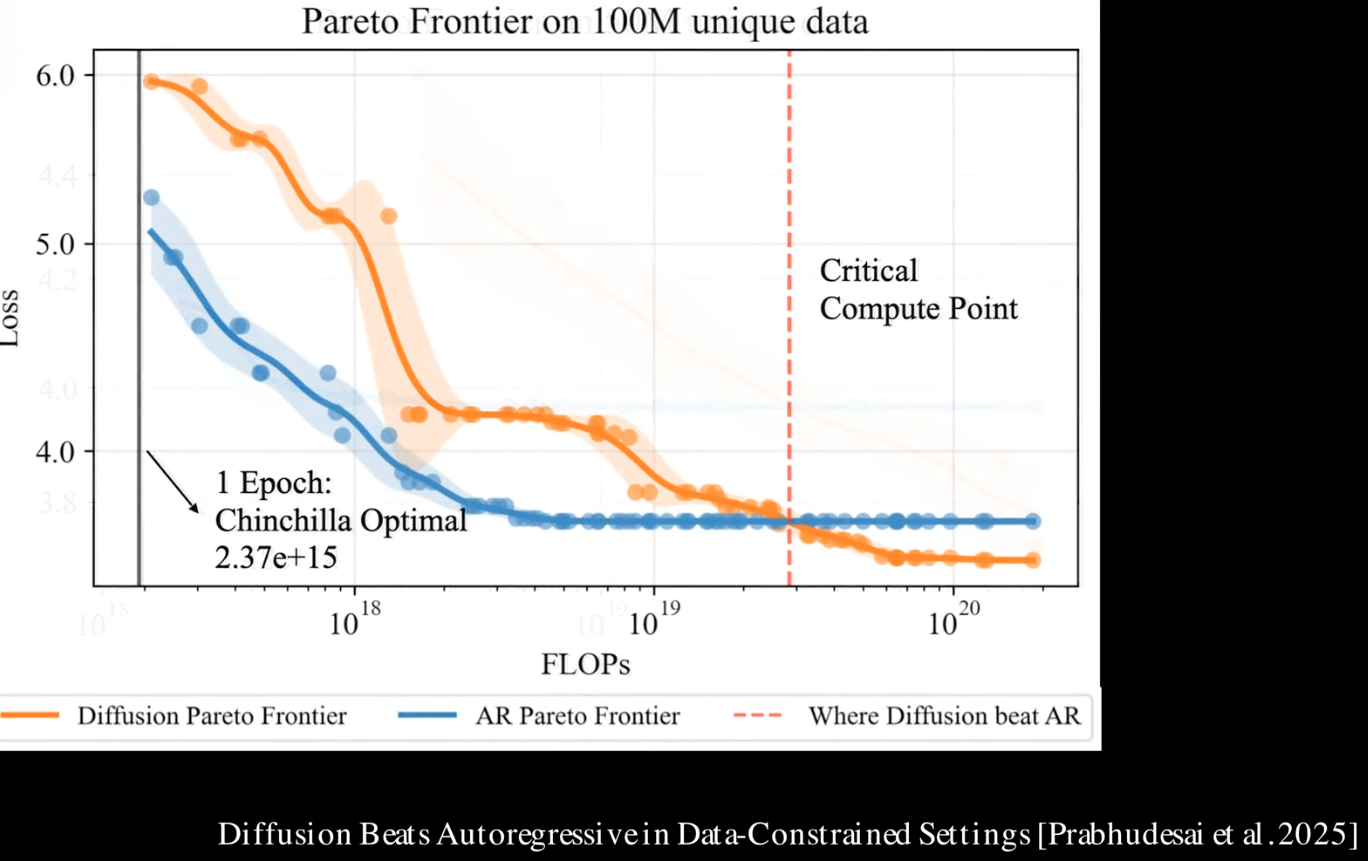
The overall training efficient of dLLM is better than AR, because the training data can be masked in various of ways, instead of just next token prediction in AR