Continuous Batching from first principles
Anyscale’s continuous batching blog was highly regarded in many places, but I actually not really understand the implementation details. But this new blog from HF, really explained things clearly from first principles
1. Review of KV Cache
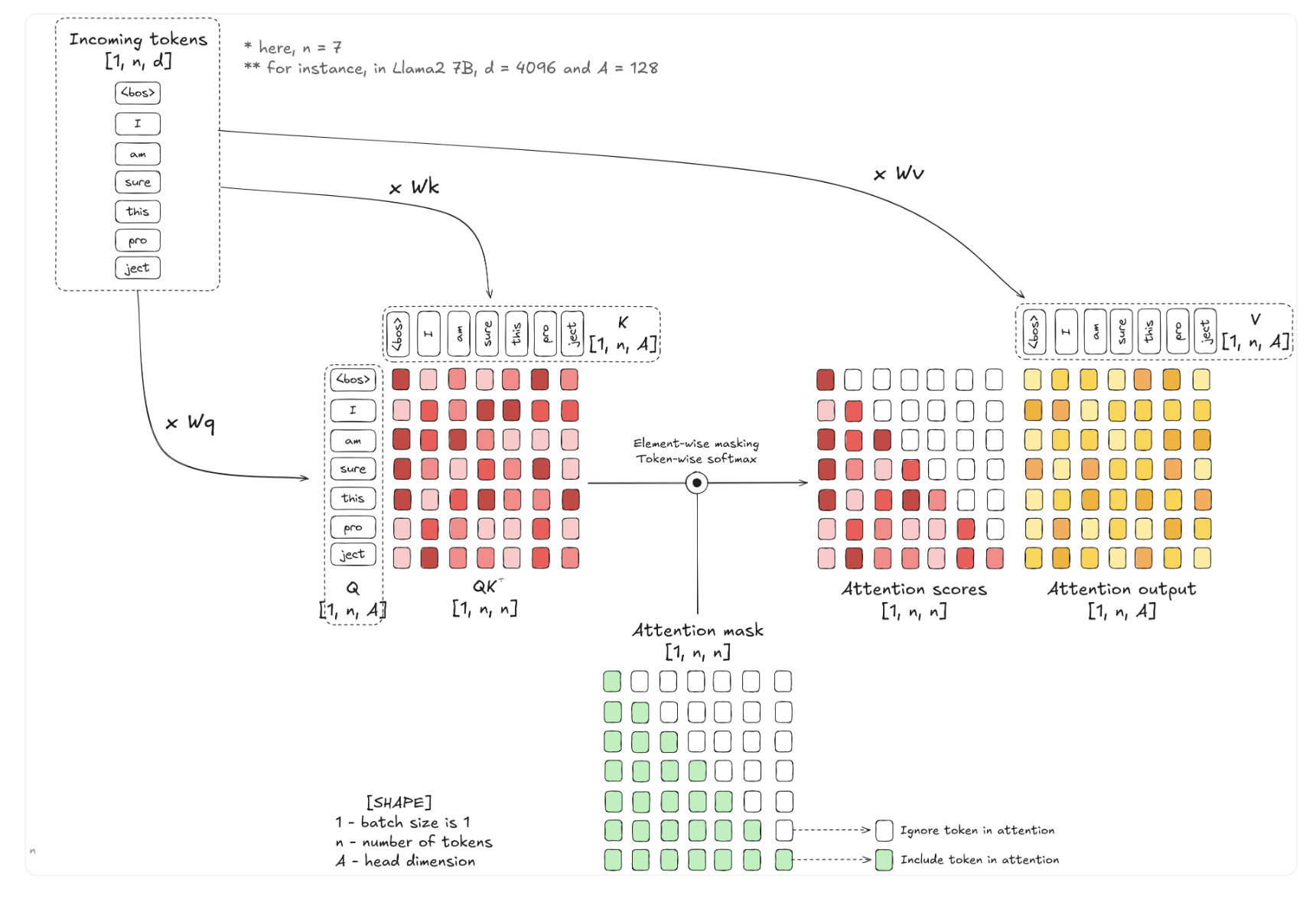
Let’s look at attention calculation
- Q/K/V can have different size $(1, n_{q/k/v, A})$
- K/V must share same size due to matrix application
- Read the attention table Row by Row, so Q only need to be one row
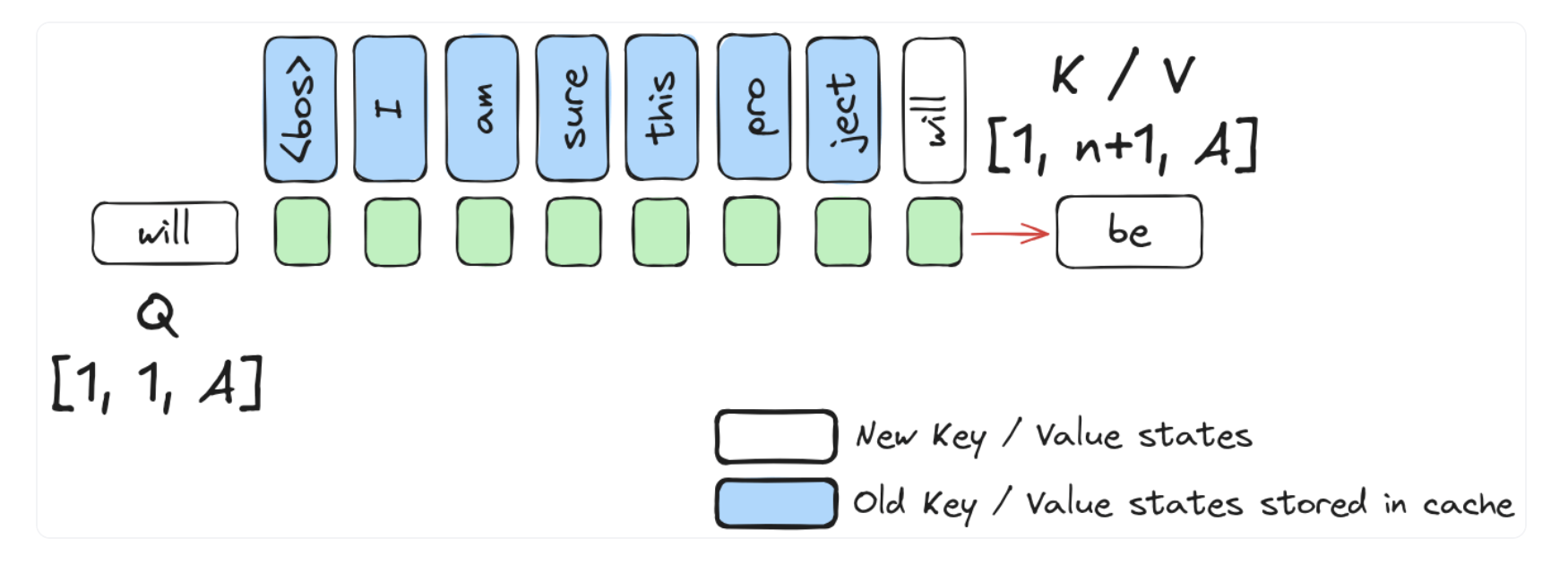
Last generated token is mapped into Q matrix, and calculated one more row to be appended to previous KV Cache
 The size of KV cache is 2 * L * HA per token
The size of KV cache is 2 * L * HA per token
- L: attention layers
- HA: H attention Heads with Dimention A in total (each head is A/H)
- 2: K and V
So it’s 2 × 32(L) × 128(HA) = 8192, which fp16 maps to 16k in mem
2. Chunked Prefill
Never thought of Chunked prefill is a pre-requisit for Continous attention. and you will know why in a bit.
!!!wait!!! My bad…I confused this with prefix caching, which is essencially KV cache reuse inNIM, controlled by NIM_ENABLE_KV_CACHE_REUSE env var.
So chunked prefill was introduced by piggyback decoding.
See more detail at vllm doc
- Smaller values (e.g., 2048) achieve better ITL because there are fewer prefills slowing down decodes.
- Higher values achieve better TTFT as you can process more prefill tokens in a batch.
- For optimal throughput, we recommend setting
max_num_batched_tokens> 8192 especially for smaller models on large GPUs. - If
max_num_batched_tokensis the same asmax_model_len, that’s almost the equivalent to the V0 default scheduling policy (except that it still prioritizes decodes).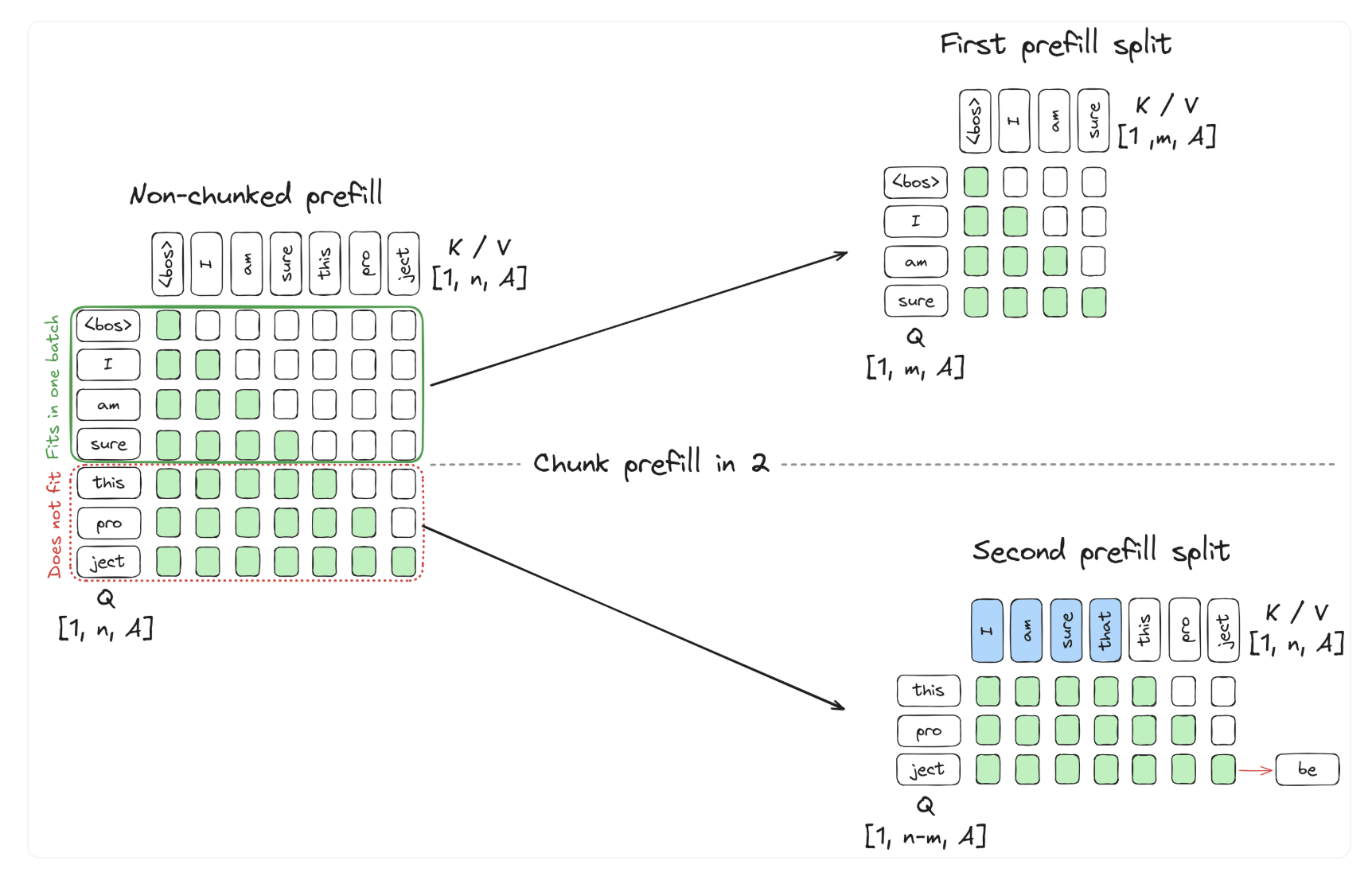
3. Dynamic Batching
To batch multiple prompts together, we need to pad shorter prompts with padding to the left
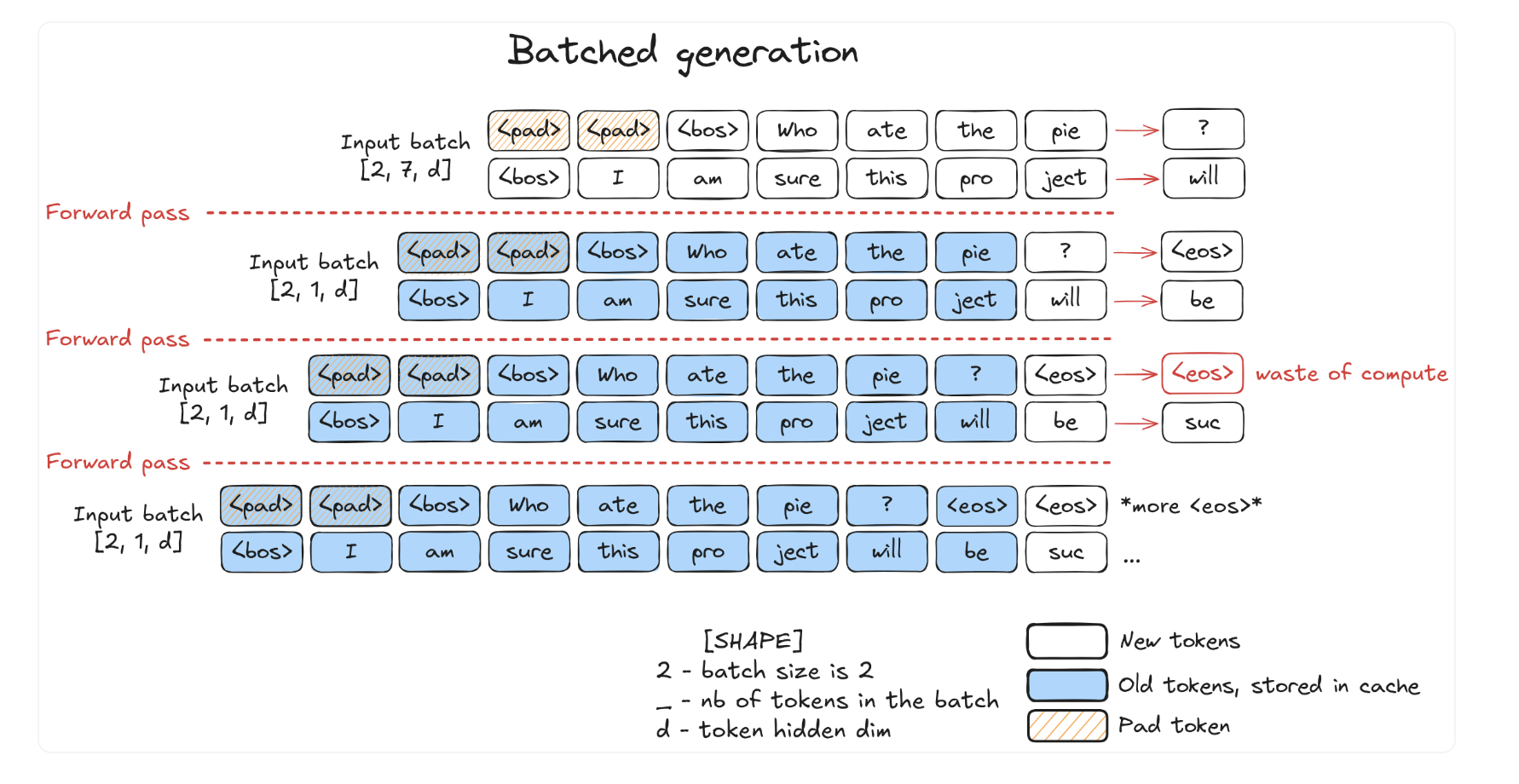
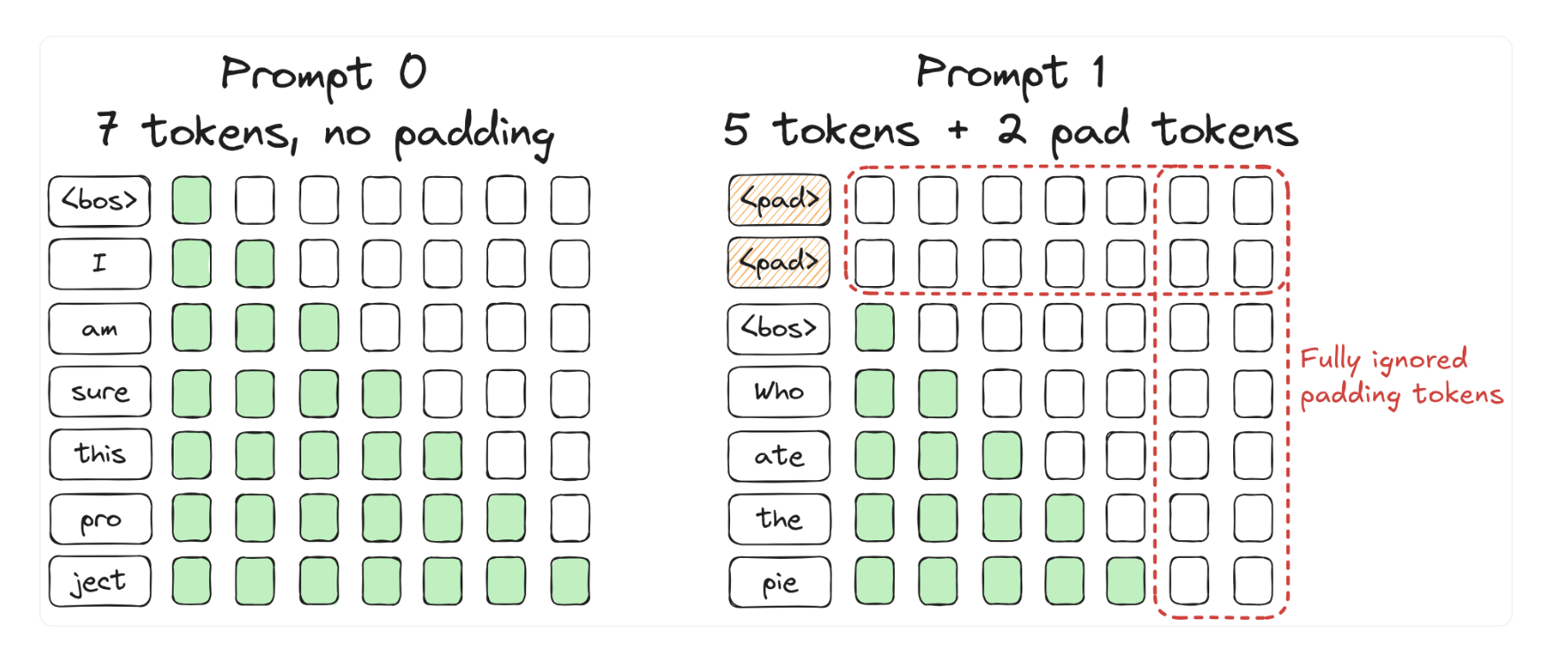 Then we can have batched generation, but waste not only the paddings, but also caluclation after EOS
Then we can have batched generation, but waste not only the paddings, but also caluclation after EOS
 Dynamic Batching is designed to solve this issue, by dynamically adding in new prompt after one is finihsed
Dynamic Batching is designed to solve this issue, by dynamically adding in new prompt after one is finihsed
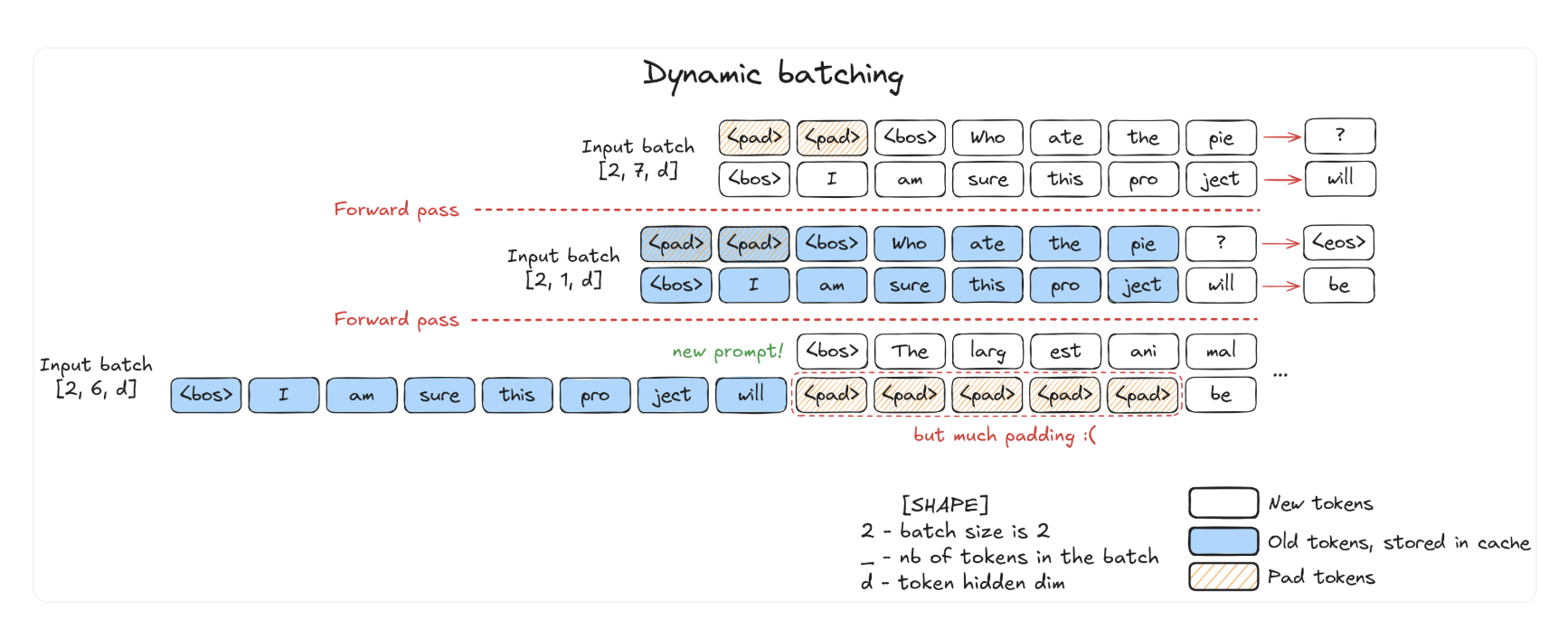 The main drawback is that (n-1)(B-1) padding needed
The main drawback is that (n-1)(B-1) padding needed
- n: Newly added prompt with n initial tokens
- B: batch size, number of prompts.
We need to pad all the decoding prompts, which has only 1 input token, versus the newly added prompt at prefill has n tokens.
4. Ragged Batching
A radical rethinking of fix the issue above, instead of using a new axis for new prompt, but we can concatenate prompts together.
And use casual mask smartly as following
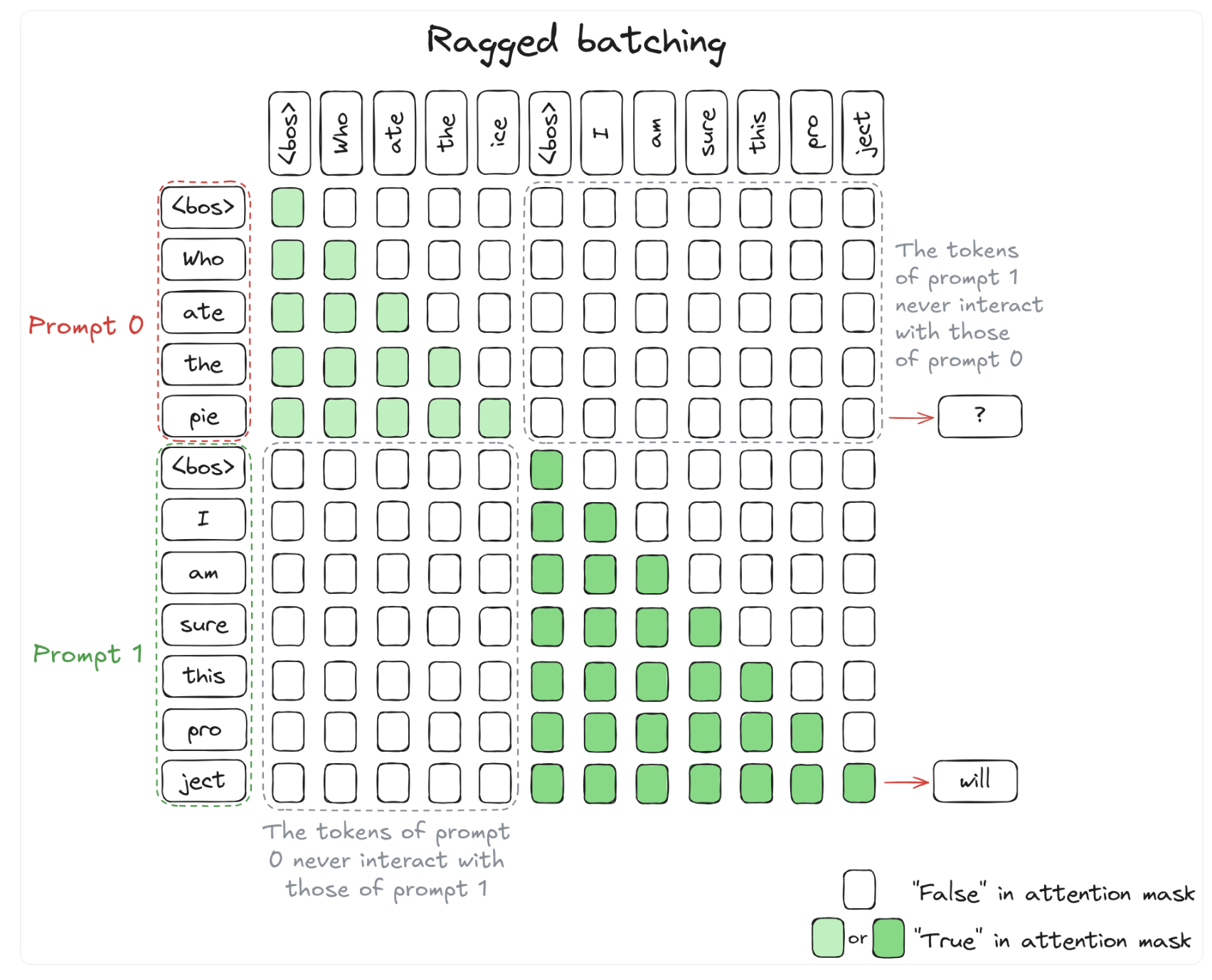
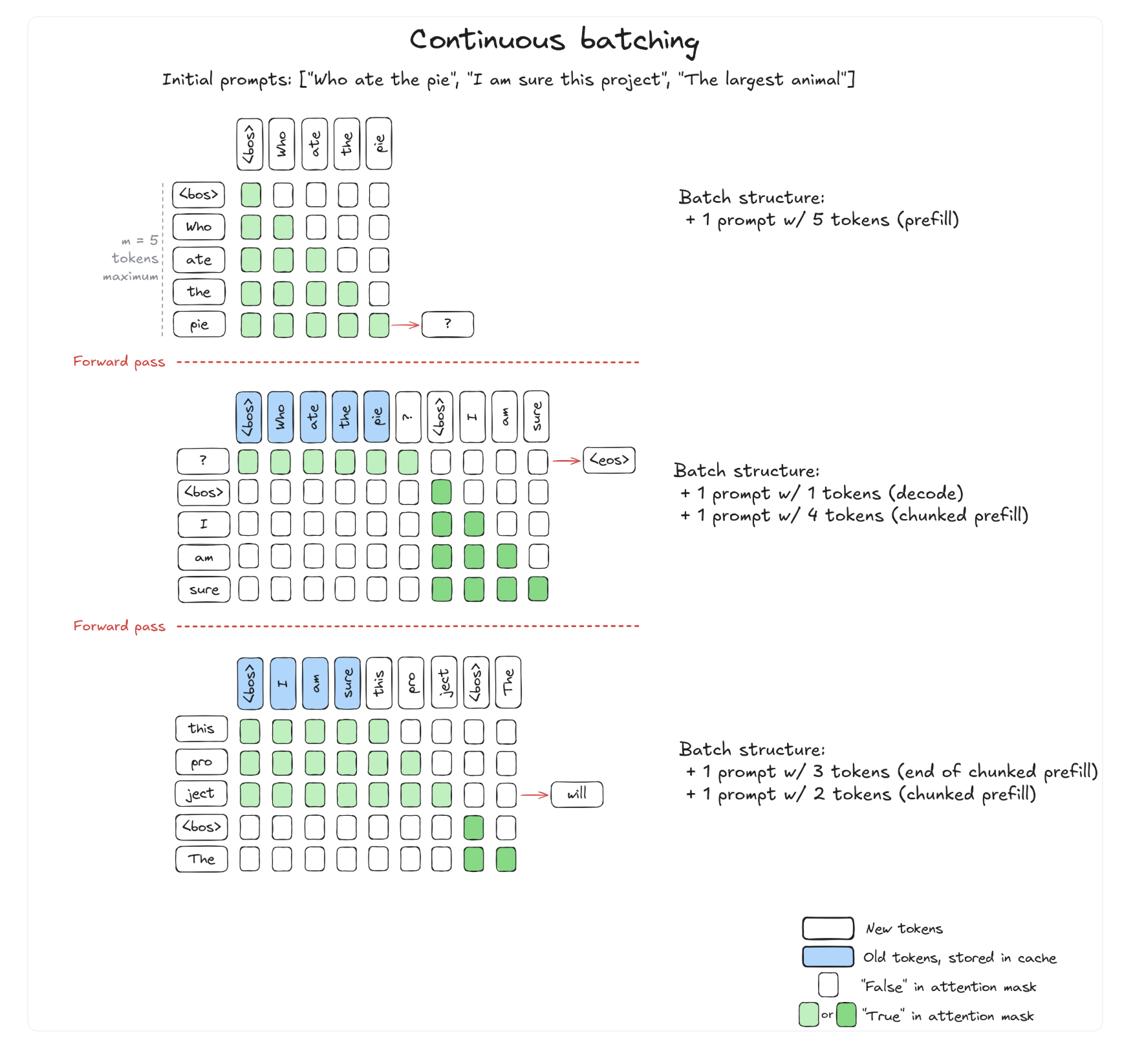
5. Continuous Batching
Now you have all the technologies needed for continuous batching. Prompts are batches in single axis by concantenation, and chunked attention can make sure a fixed size mem is used