Diffusion Transformers
Diffusion Transformers is different from dLLM and it’s widely used in omni models
This is the note from video and this blog
0 ViT Review
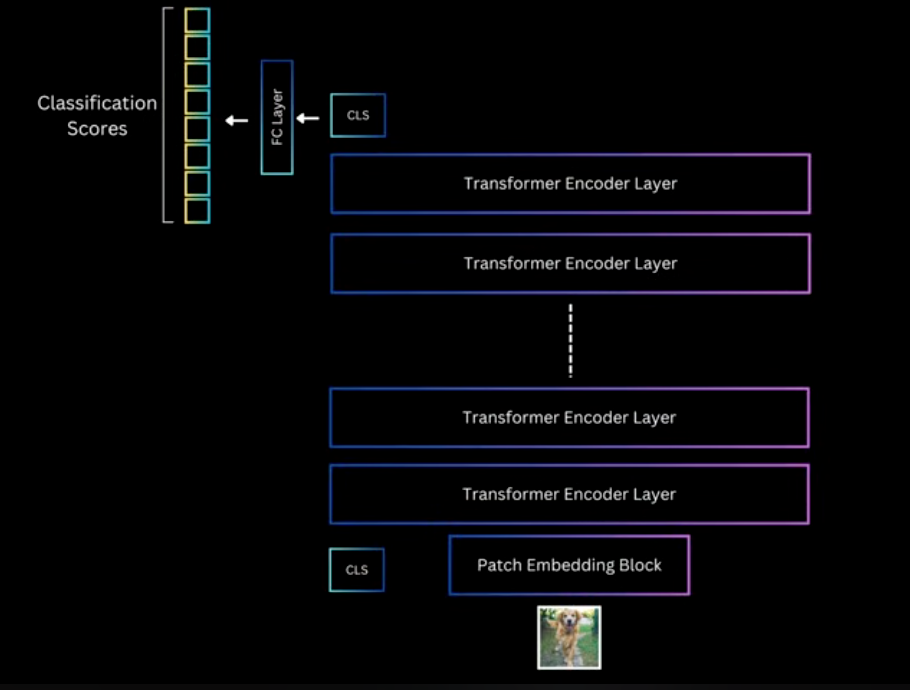
There are quite some similarity between ViT and DiT
The review here is the to show that patch embedding block get D-dimen embeddings
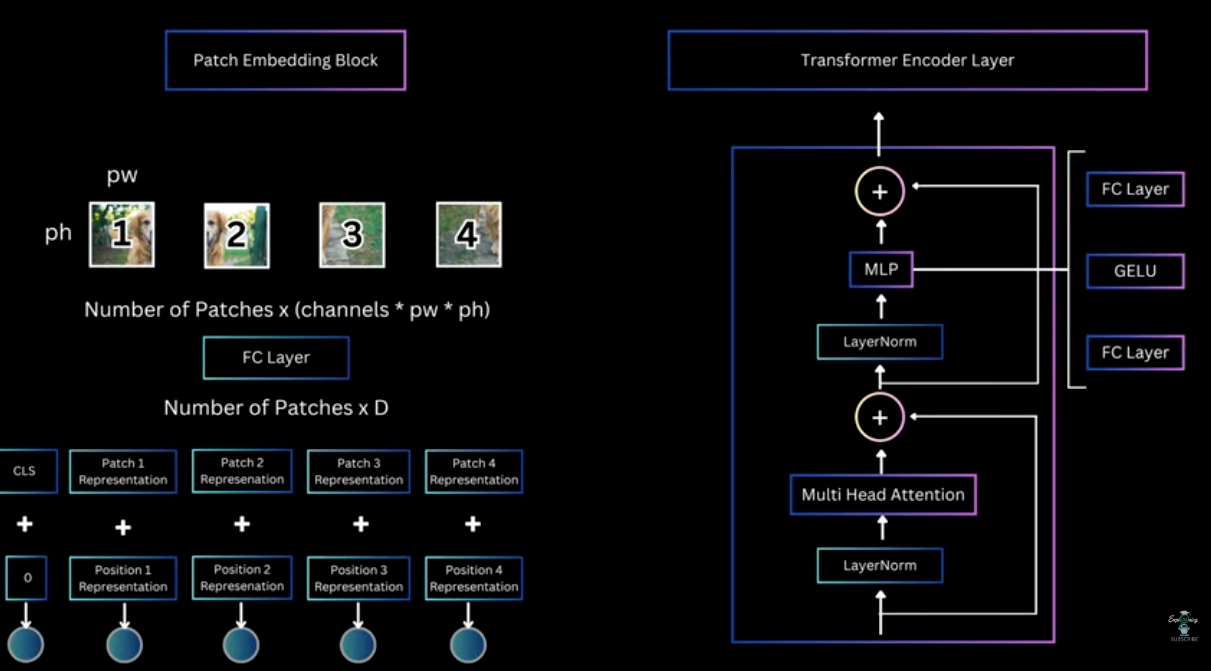 and then pass in the transformer layers, with an additional CLS information
and then pass in the transformer layers, with an additional CLS information
1 DiT Review
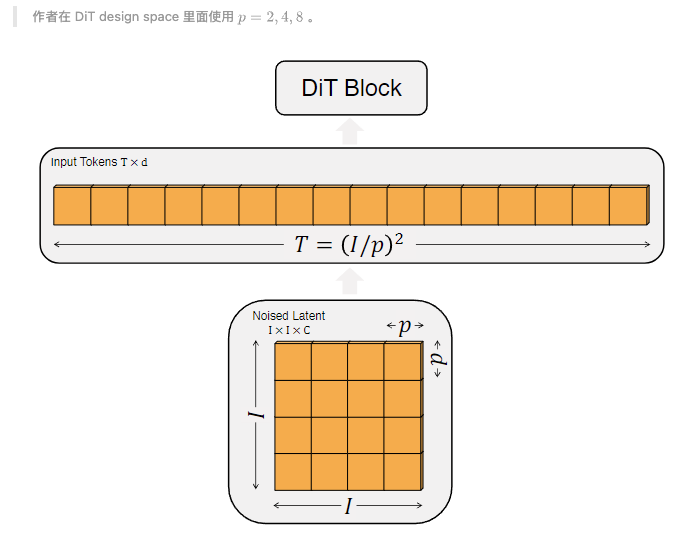
- DiT would remove the CLS information
- Working on latent space instead of pixel
- 2D position embedding is used
- The patchify process
2 Architecture design
The block design is all about how to add time and text embedding into the image embeddings
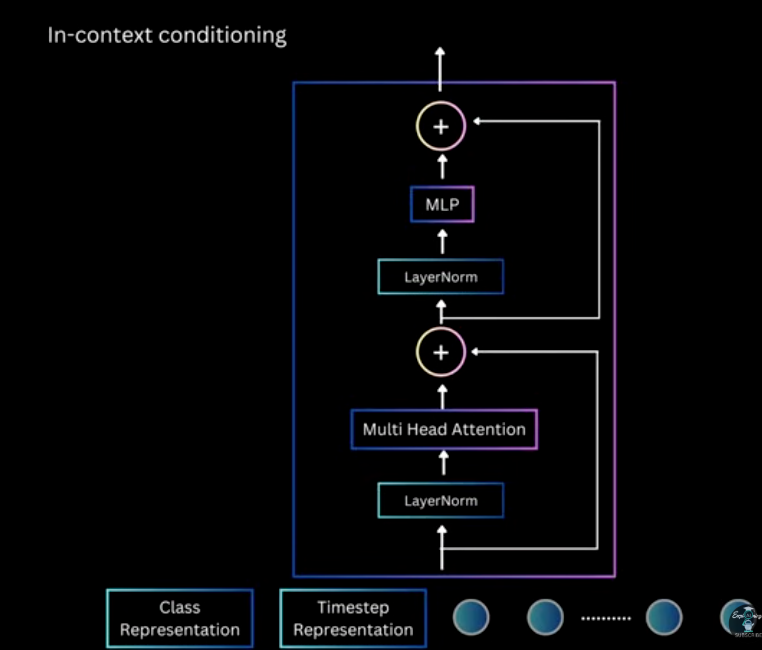
- In-context conditioning
Simply concatenate time and text with image embedding, like CLS in ViT
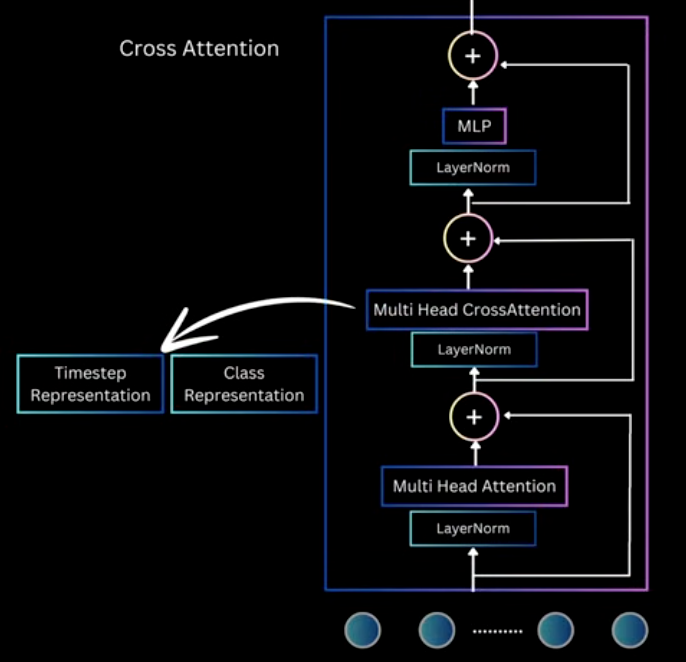
- Cross-Atten Block
Concatenate tim and text, and add cross-atten block, which is 15% more FLOPS
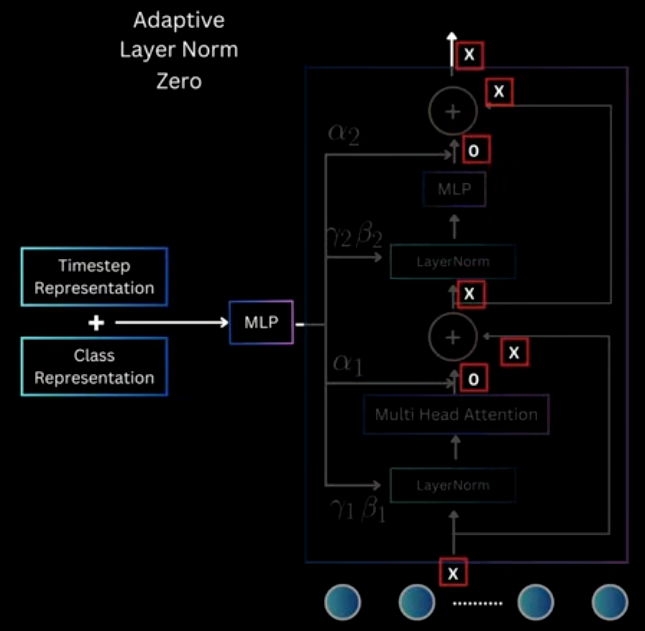
- Adaptive Layer Norm
LayerNorm is about normalize over
feature_dimand learn $\gamma$ and $\beta$ to scale the inputclass LayerNorm: def __init__(self, feature_dim, epsilon=1e-6): self.epsilon = epsilon self.gamma = np.random.rand(feature_dim) # scale parameters self.beta = np.random.rand(feature_dim) # shift parametrs def __call__(self, x: np.ndarray) -> np.ndarray: """ Args: x (np.ndarray): shape: (batch_size, sequence_length, feature_dim) return: x_layer_norm (np.ndarray): shape: (batch_size, sequence_length, feature_dim) """ _mean = np.mean(x, axis=-1, keepdims=True) _std = np.var(x, axis=-1, keepdims=True) x_layer_norm = self.gamma * (x - _mean / (_std + self.epsilon)) + self.beta return x_layer_normand Adaptive Layernorm is use time and text embedding as scale and shift parameters
class DiTAdaLayerNorm: def __init__(self,feature_dim, epsilon=1e-6): self.epsilon = epsilon self.weight = np.random.rand(feature_dim, feature_dim * 2) def __call__(self, x, condition): """ Args: x (np.ndarray): shape: (batch_size, sequence_length, feature_dim) condition (np.ndarray): shape: (batch_size, 1, feature_dim) Ps: condition = time_cond_embedding + class_cond_embedding return: x_layer_norm (np.ndarray): shape: (batch_size, sequence_length, feature_dim) """ affine = condition @ self.weight # shape: (batch_size, 1, feature_dim * 2) gamma, beta = np.split(affine, 2, axis=-1) # (batch_size, 1, feature_dim) _mean = np.mean(x, axis=-1, keepdims=True) _std = np.var(x, axis=-1, keepdims=True) x_layer_norm = gamma * (x - _mean / (_std + self.epsilon)) + beta return x_layer_norm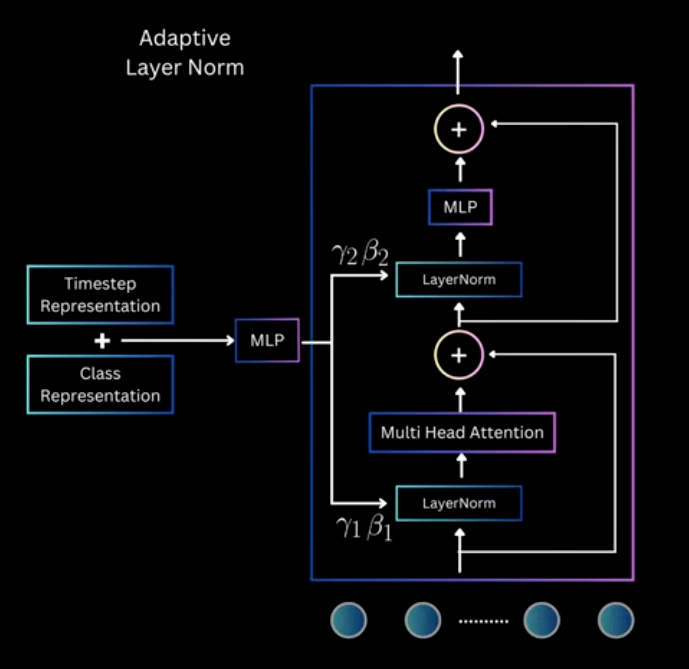
- adaLN-Zero Block
What actually used is the Zero-Initialized version.
class DiTBlock: def __init__(self, feature_dim): self.MultiHeadSelfAttention = lambda x: x # mock multi-head self-attention self.layer_norm = LayerNorm() self.MLP = lambda x: x # mock multi-layer perceptron self.weight = np.random.rand(feature_dim, feature_dim * 6) def __call__(self, x: np.ndarray, time_embedding: np.ndarray, class_emnedding: np.ndarray) -> np.ndarray: """ Args: x (np.ndarray): shape: (batch_size, sequence_length, feature_dim) time_embedding (np.ndarray): shape: (batch_size, 1, feature_dim) class_emnedding (np.ndarray): shape: (batch_size, 1, feature_dim) return: x (np.ndarray): shape: (batch_size, sequence_length, feature_dim) """ condition_embedding = time_embedding + class_emnedding affine_params = condition_embedding @ self.weight # shape: (batch_size, 1, feature_dim * 6) gamma_1, beta_1, alpha_1, gamma_2, beta_2, alpha_2 = np.split(affine_params, 6, axis=-1) x = x + alpha_1 * self.MultiHeadSelfAttention(self.layer_norm(x, gamma_1, beta_1)) x = x + alpha_2 * self.MLP(self.layer_norm(x, gamma_2, beta_2)) return x