TensorRT-LLM Backend
Watched Faradawn Yang’s sharing about TRTLLM in EZ channel, which is really well articulated. I furthur watched his vLLM and SGLang sharing, also inspiring
0 Overall view of these three backend
These three engines are actually optimizing inference from different perspective
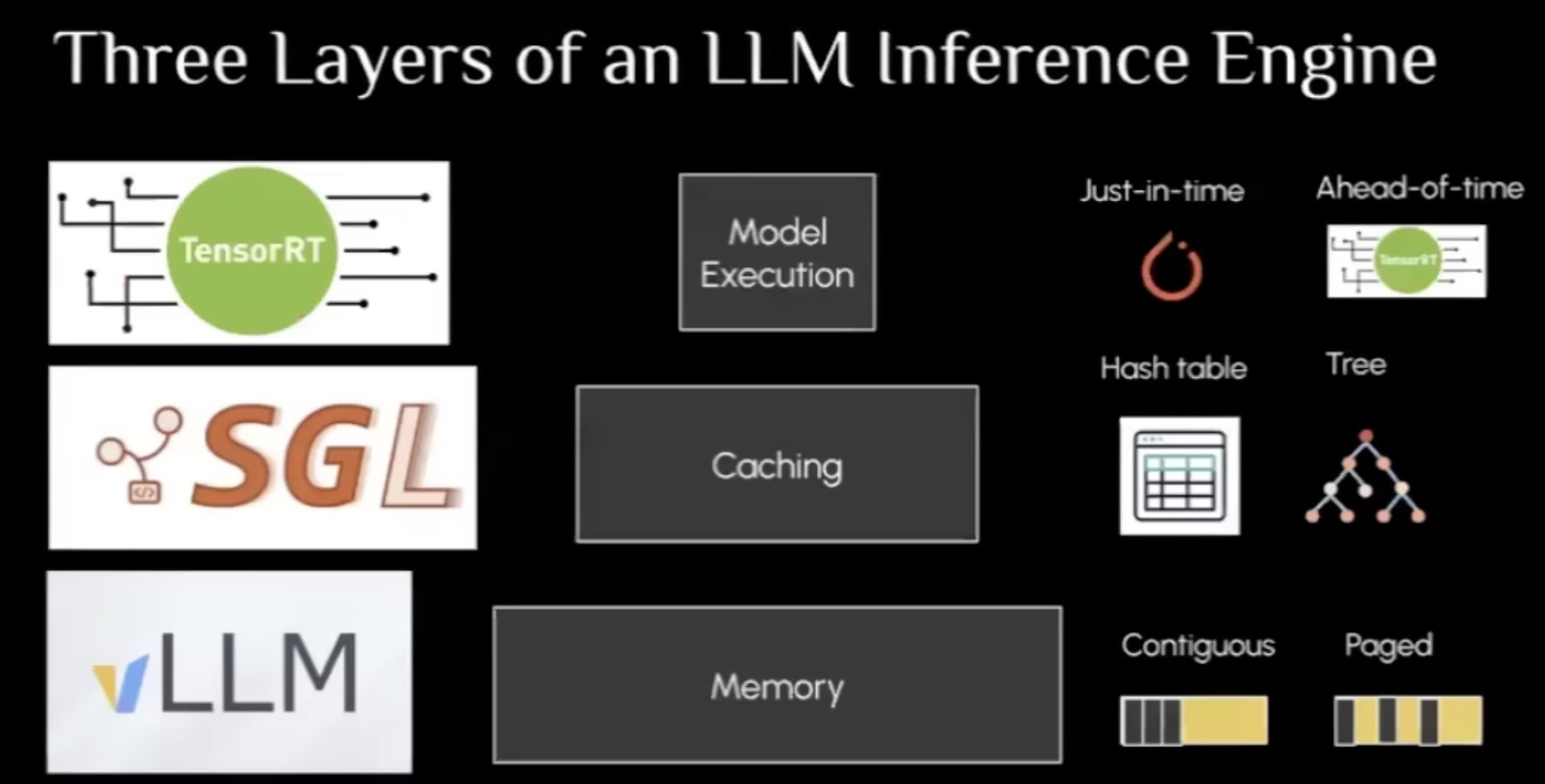
1 How TRTLLM stands out
- Using vLLM load HF weight is like Python interpreator
 While TRTLLM compiles, like g++, the engine based on hardware type and execute later
While TRTLLM compiles, like g++, the engine based on hardware type and execute later

- TRTLLM is using Kernal Auto Tuning, which can search over difference matrix size for multiplication.
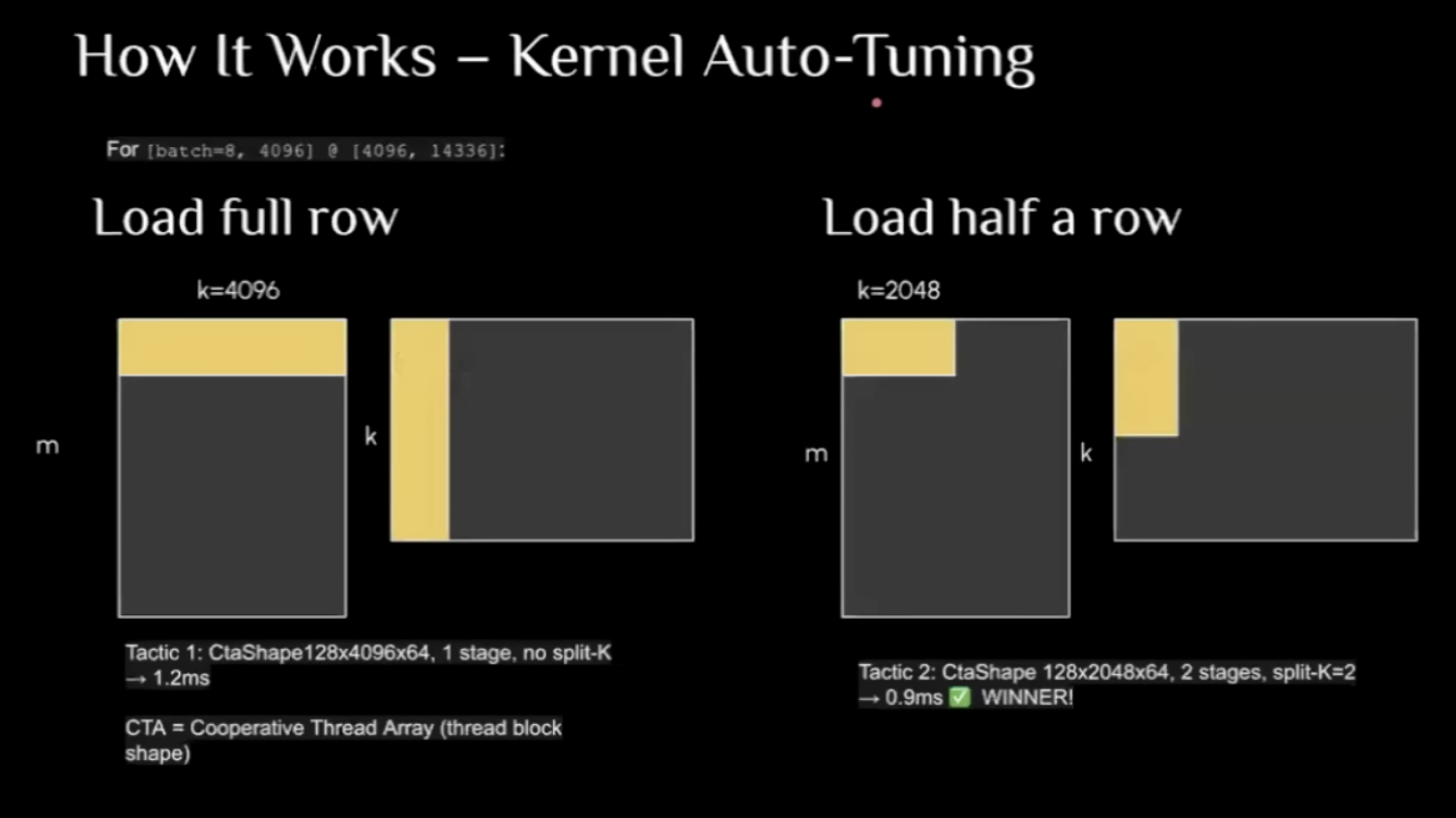 The chanllege could be huge search space
The chanllege could be huge search space
 but can be mitigated by limiting batchsize
but can be mitigated by limiting batchsize

- When not knowing the exactly batchsize
 The queue is the solution
The queue is the solution

- It also comes with multiple other compiling options

2 CUDA Grapha Capture
I heard this term mentinoed multiple and still not sure what’s the exactly meaning
Here is a simple comparsion and will dive into later
