Engram - The history
EZ encoder gives a review of Engram
0 Overview
- Transformer 的 FFN 层本质是一个 Key-Value Memory
- Sparsity 是打破「不可能三角」的关键(Performance / Compute / Model Size)
- 通过 Hash 查表实现 O(1) 复杂度的 N-gram 检索
- Engram 让模型不用「计算」就能「记住」常识知识
- DeepSeek 的工作是前人研究的集大成者
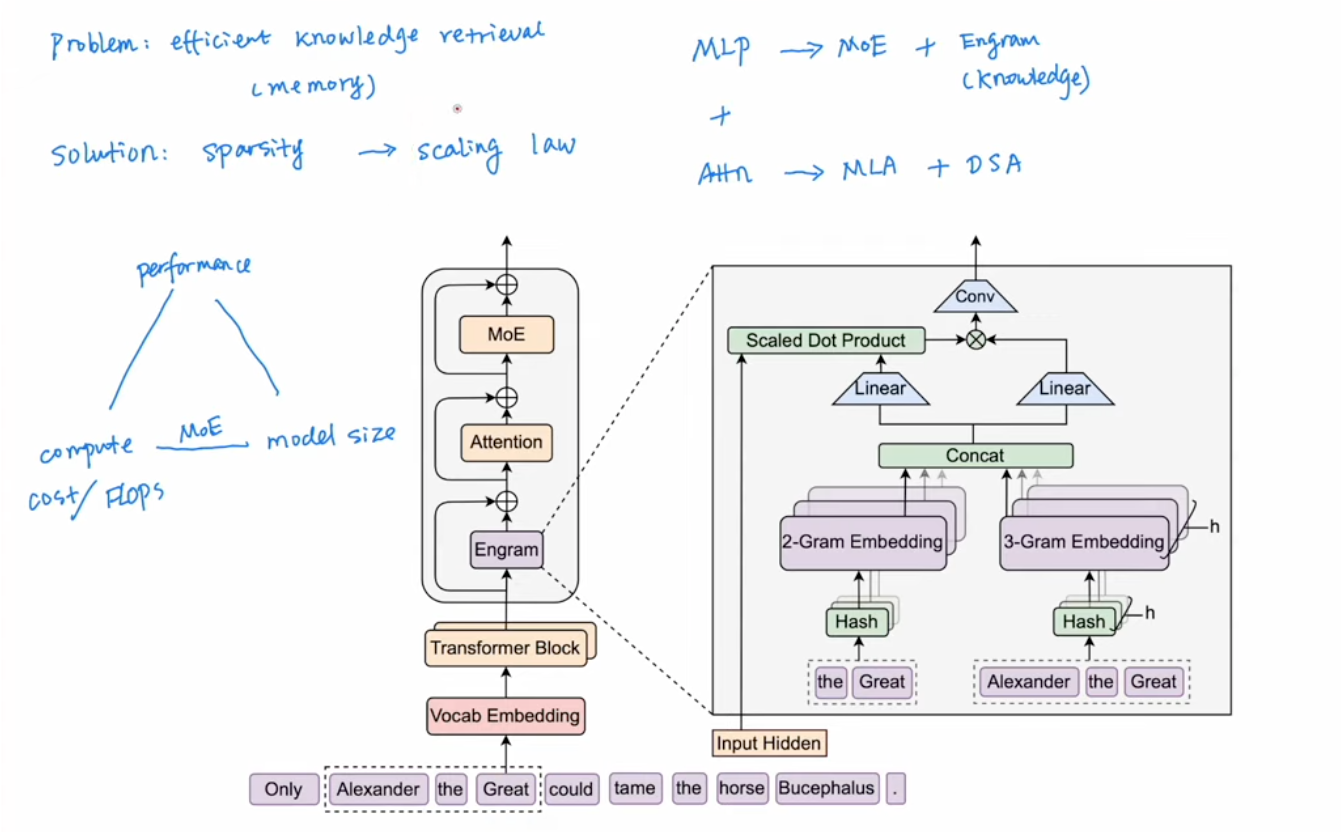
1 Memory branch
Engram is actually a word invited by Ricard Semon, who created engram(记忆痕迹) and ecphory.
 and you can actually view the engram cells from this Science paper
and you can actually view the engram cells from this Science paper
 Let’s take a look at papers on LLM memories
Let’s take a look at papers on LLM memories
- Facebook 2019 - Language Models as Knowledge Bases
- KNN was used as KB in the traditional ML and LM is actually KB
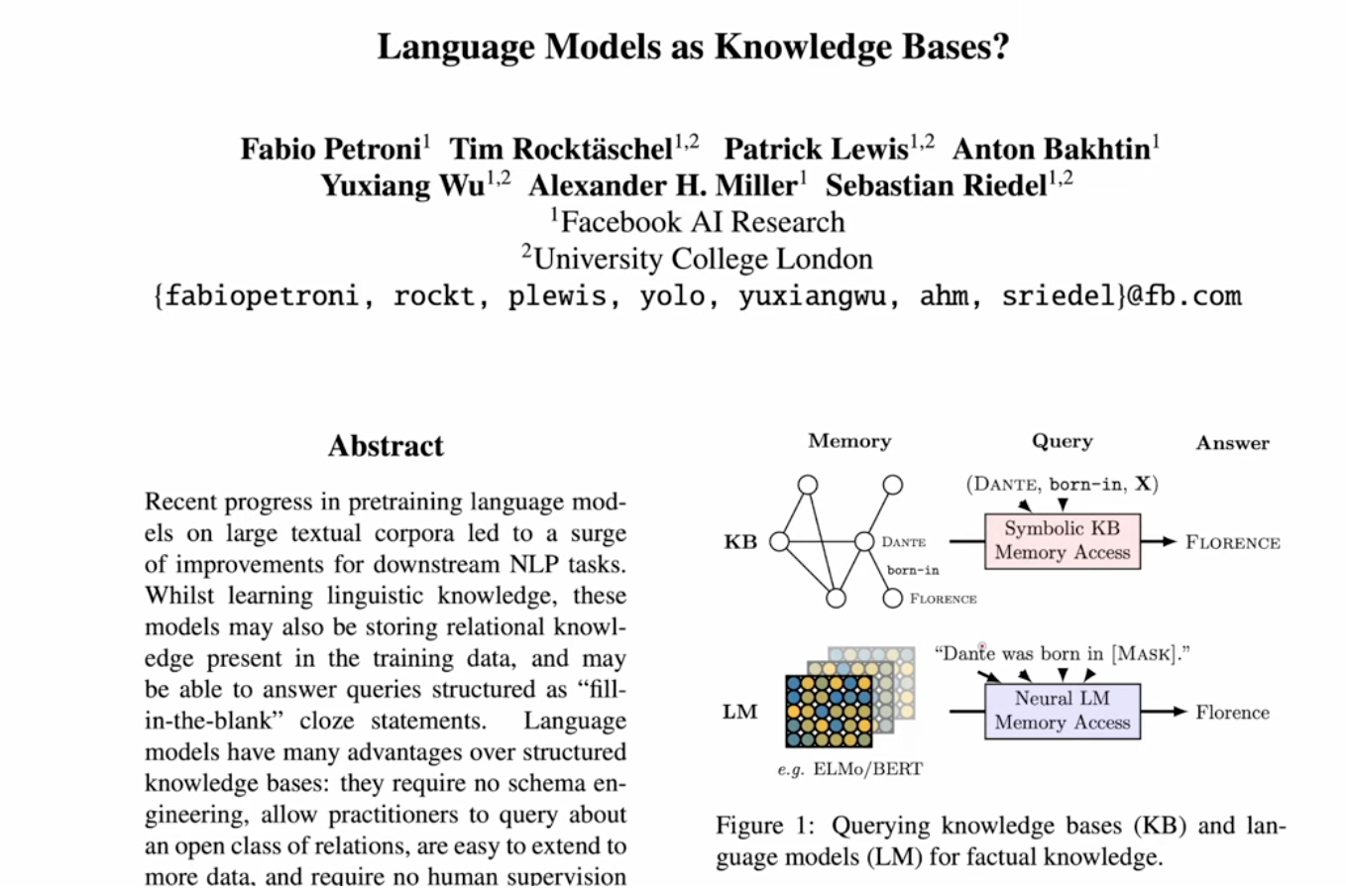
- KNN was used as KB in the traditional ML and LM is actually KB
- Google 2020 - T5 作为 Knowledge Base
- Model can “look up information” stored in the parameters

- Model can “look up information” stored in the parameters
- 2021 - Transformer FFN 层是 Key-Value Memory
- Critical paper starting FFN as KV memory.
- $FFN(x) = f(x * K^T)*V$ is a confusing formula here, isn’t it self-atten?
- Key multiplication get memory coefficient

- Microsoft 2022 - Knowledge Neurons
- Active neurons store knowlege and are referred as KN
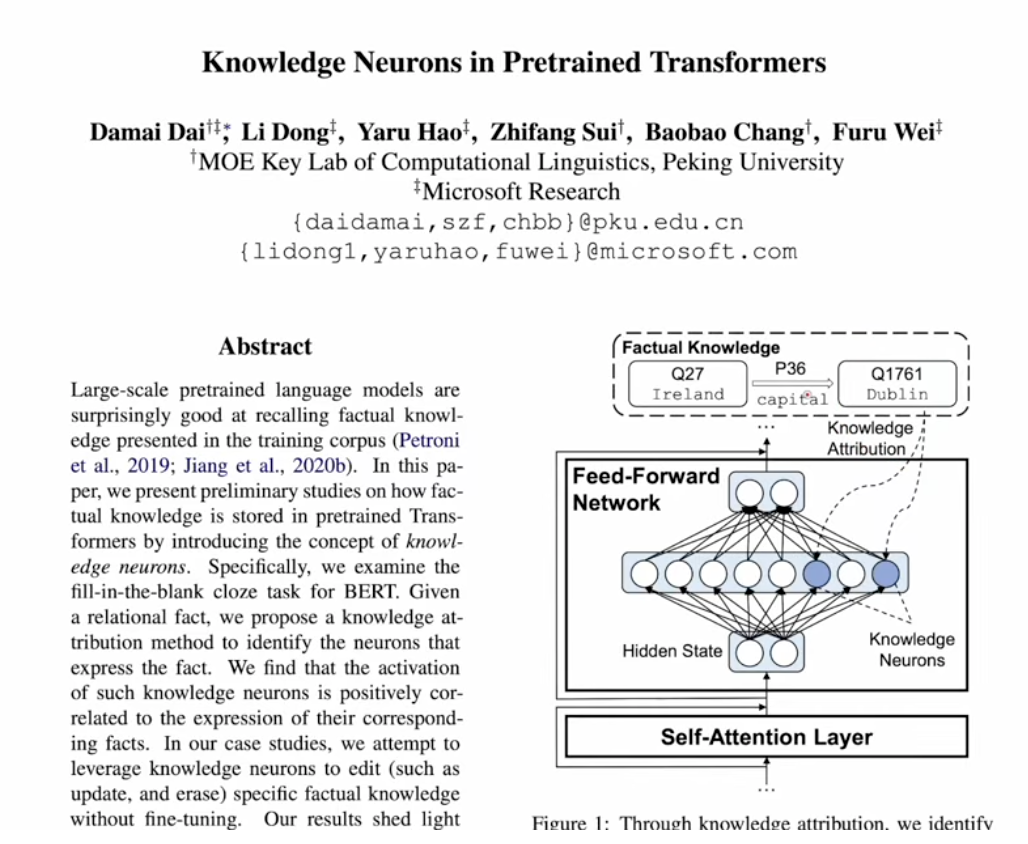
- $FFN(H)=Gelu(HW_1)W_2$, here Hidden H is the concatentation of all attention heads
- $Self_Atten(x)=softmax(Q*K^T)V$, this makes more sense
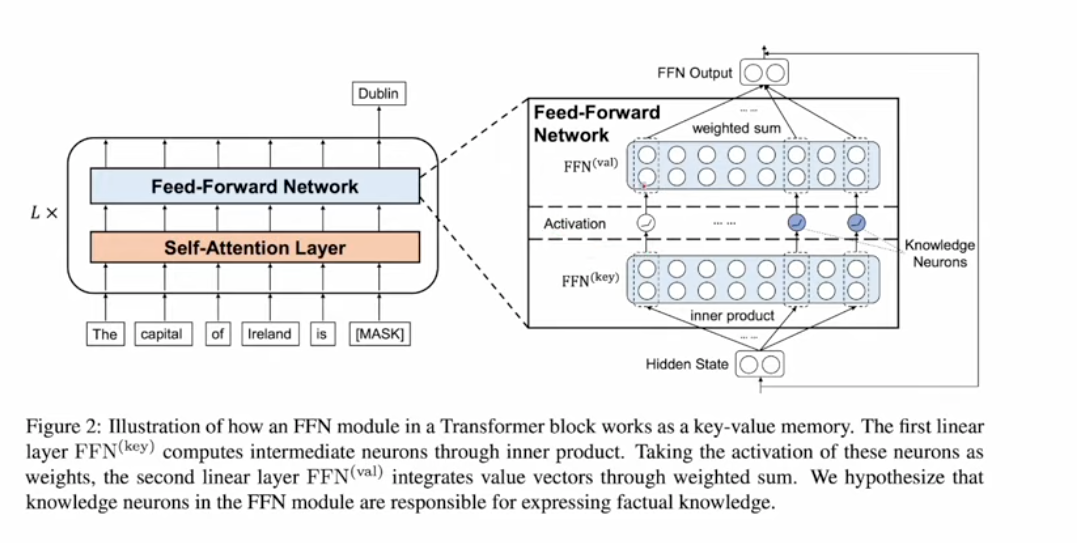
- Active neurons store knowlege and are referred as KN
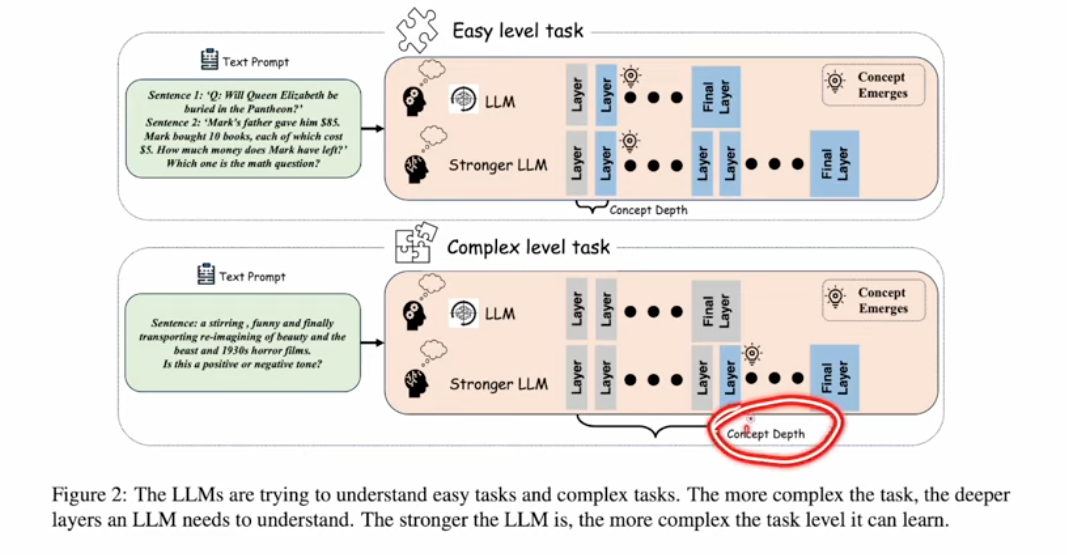
- Concept depth concept introduced in the following paper

- Facebook 2019 - Product Key Memory (PKM)
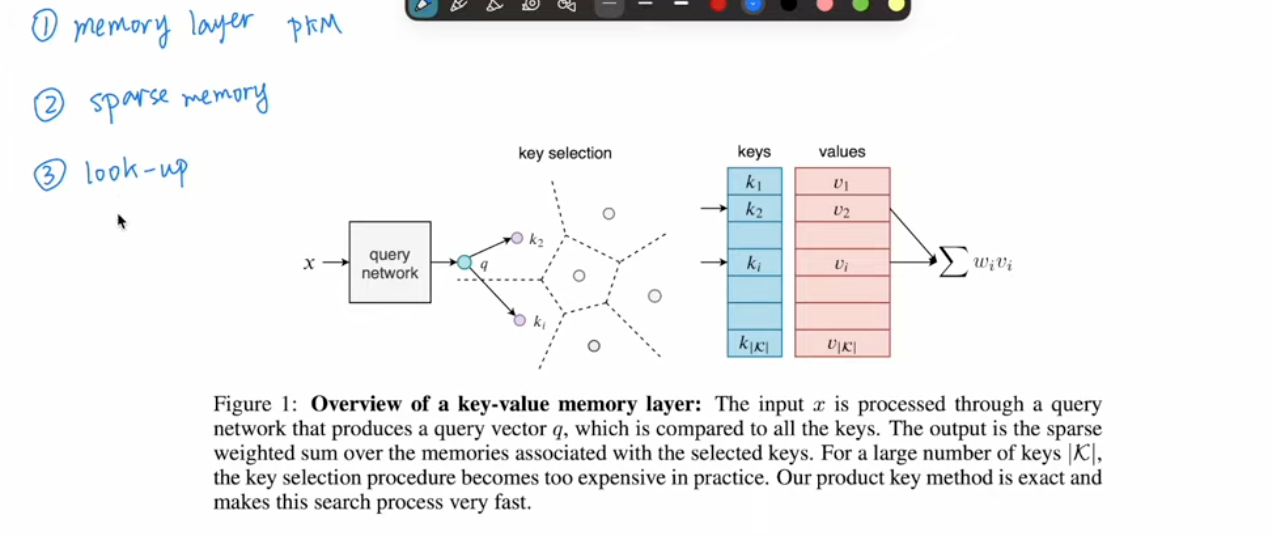
- K nearest neightboards used to find keys for each query
- product key method is split keys due to large key size
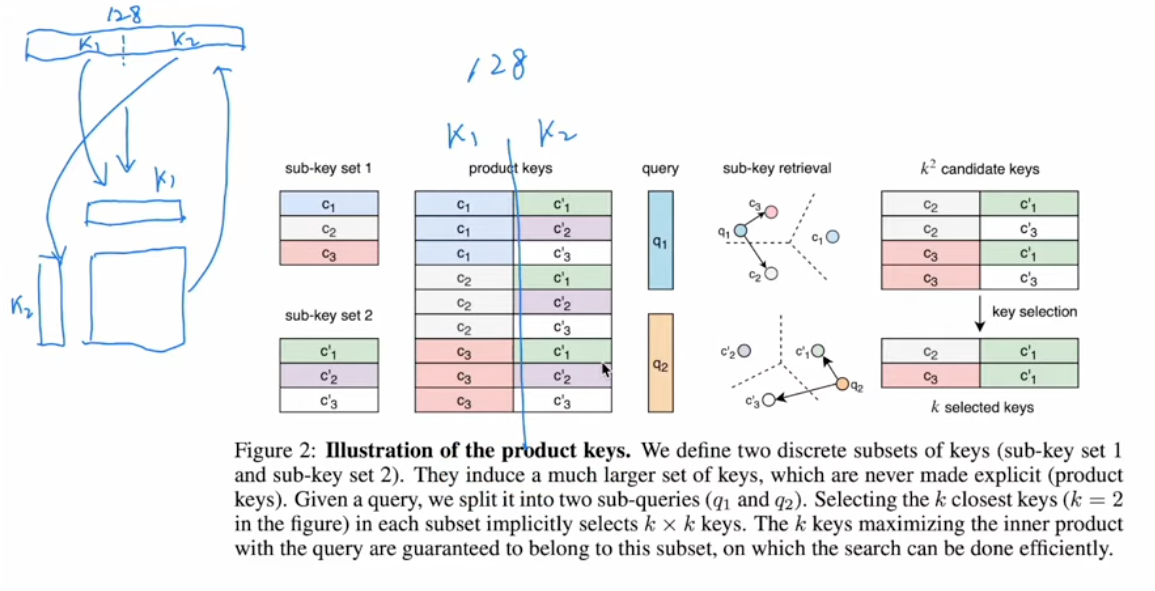
- K nearest neightboards used to find keys for each query
- Meta - Memory Layer 扩展到 128B 参数
- ML is scalable

- Adding gating for control on tops of PKM
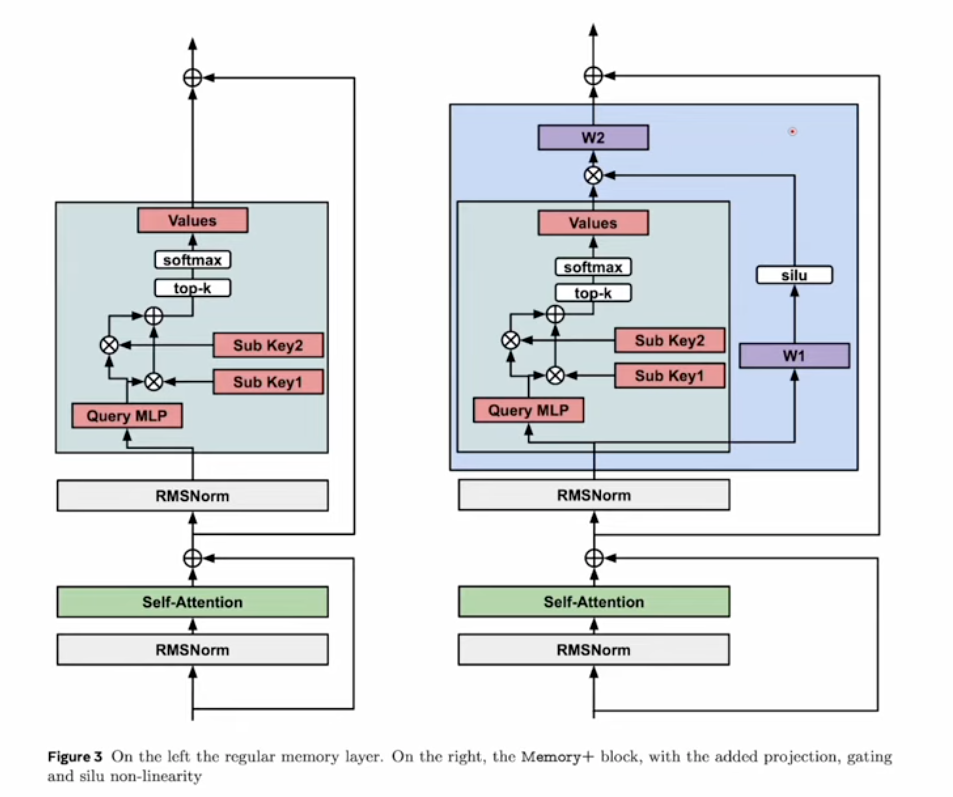
- ML is scalable
- DeepMind 2022 - Retrieval-Enhanced Transformer (RETRO)
- Instead of using parameters as KN, external docs can be used as KN, smiliar to RAG

- CCA(Chunked Cross Attention) was introdued here. similar to N-gram in Engram
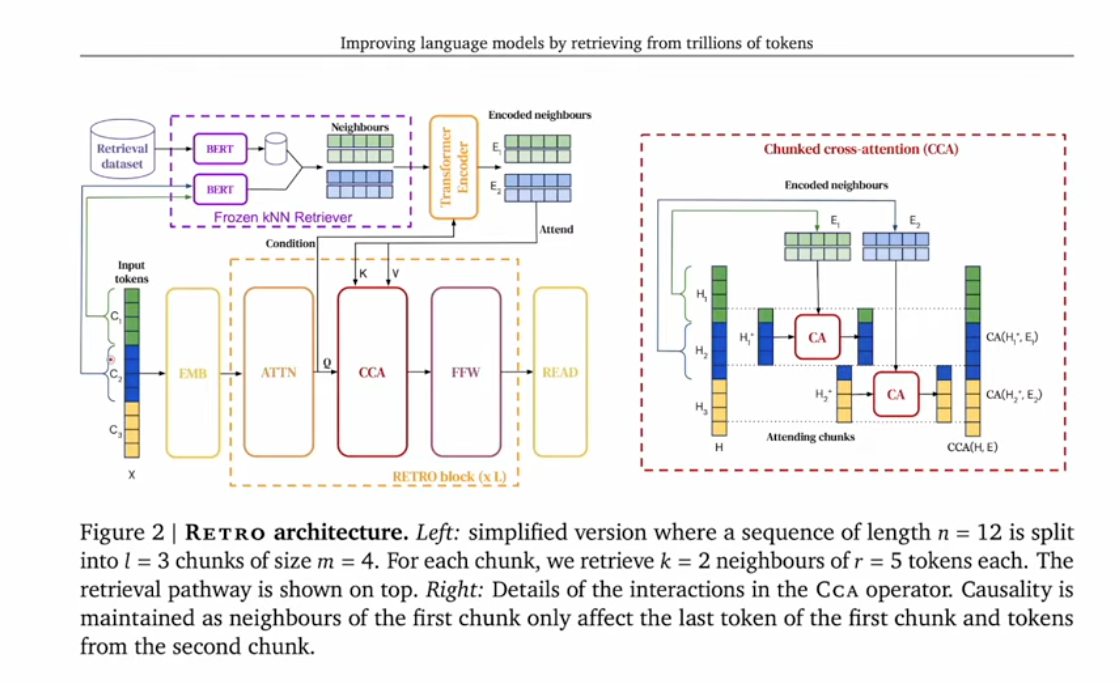
- Instead of using parameters as KN, external docs can be used as KN, smiliar to RAG
- Google 2023 - External Memory 提升模型能力

- additional parameters for input representation (Ngram)
- expert function (MoE)

2 N-Gram branch
Original bag of words is lacking words orders, and N-gram can be used to improve that
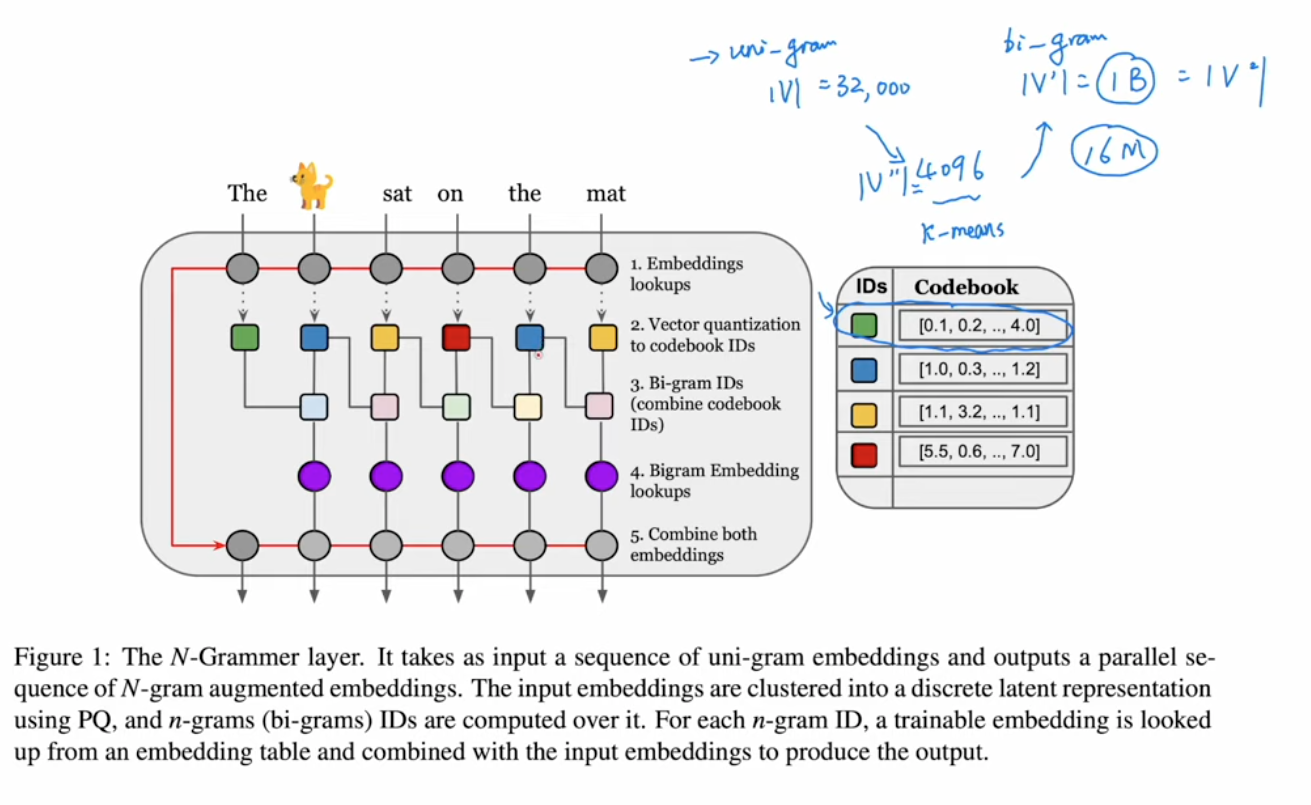
- Google 2022 - N-Grammer:用 N-gram Embedding 增强 Transformer

- Codebook ID is used to reduce vacab size, which is V^2 in case of 2-gram.
- k-means cluster is uesd to reduce dim.
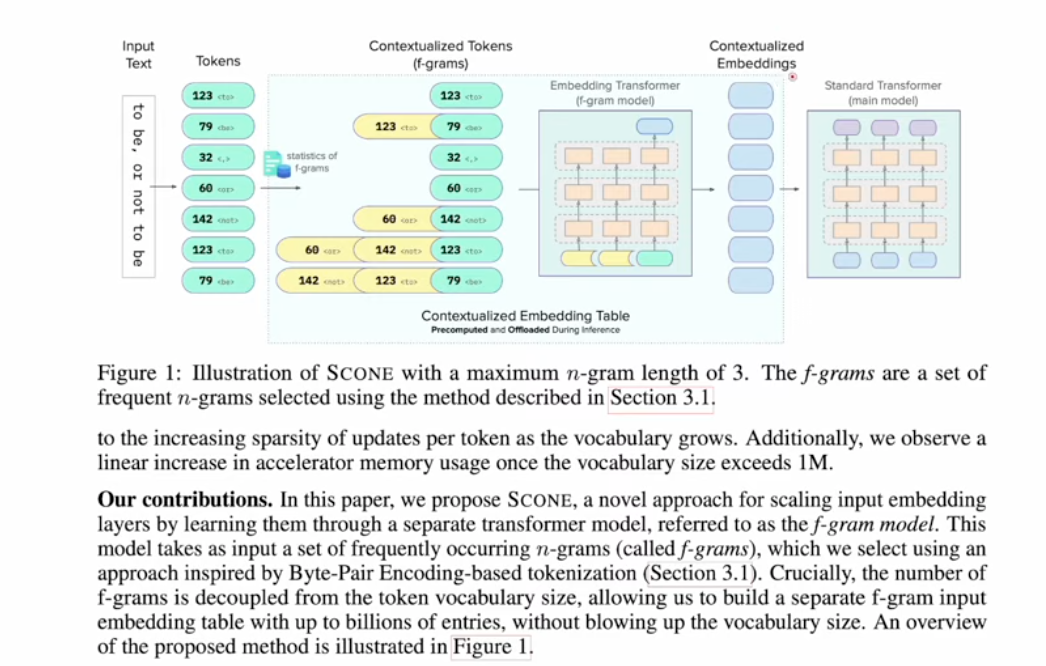
- Google 2025 - Scaling Embedding Layer
- Introduced f-gram, frequently occuring n-grams

- The embedding table can be precomputed and offload to disk!
4 Engram paper
The Engram paper is easy to understand now with all previous information
- A lookup hash table for 2 or 3 gram
- Multi Hash were used to avoid colision
- A gating mechanisium is similiart to Q/K/V memory mathcing and weighted sum
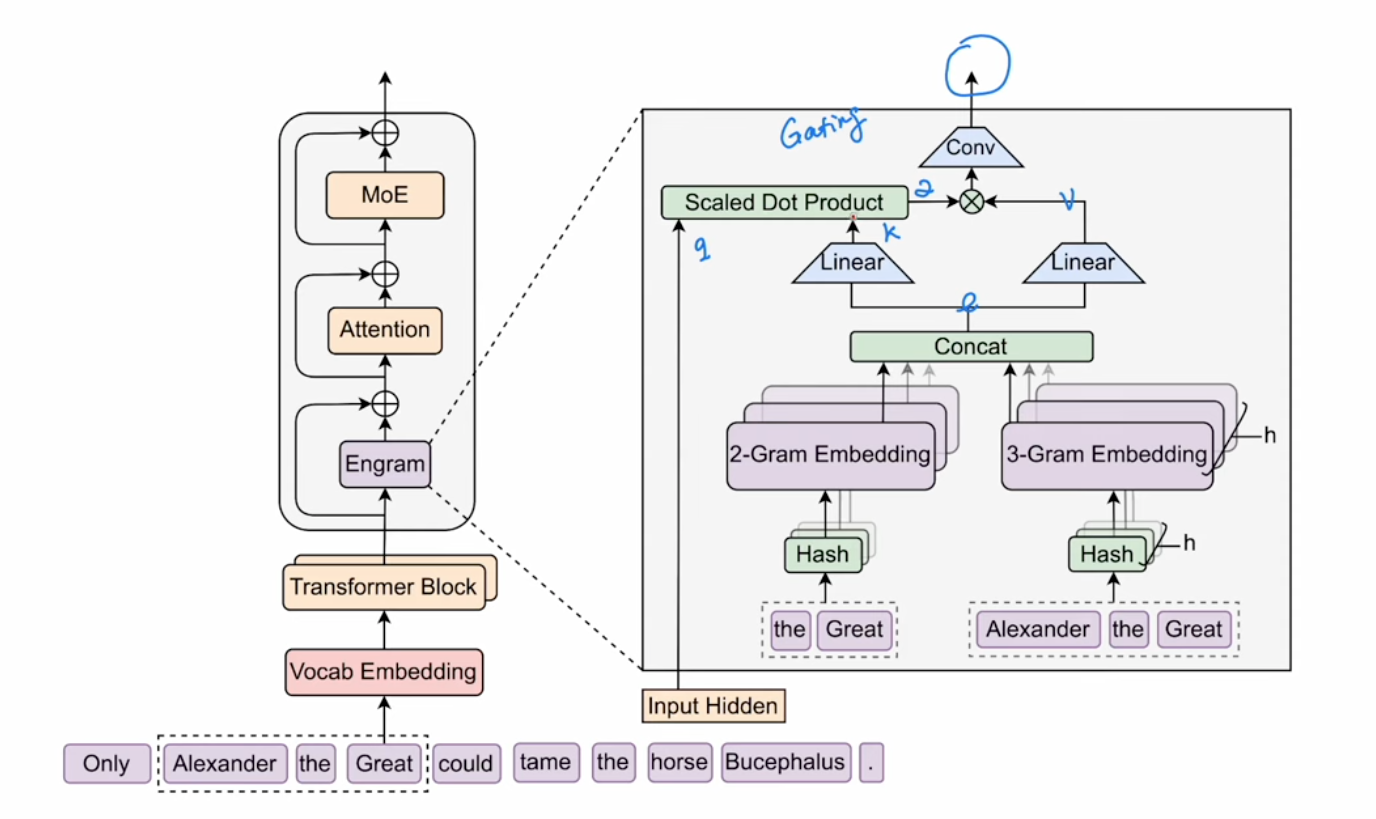
- Tokenizer compression was used (like combining upper/lower cases)

- Introduced f-gram, frequently occuring n-grams