vLLM Fuyu
Worked on a bugfix PR with discrepency between get_multimodal_embedding and PlaceholderRange.
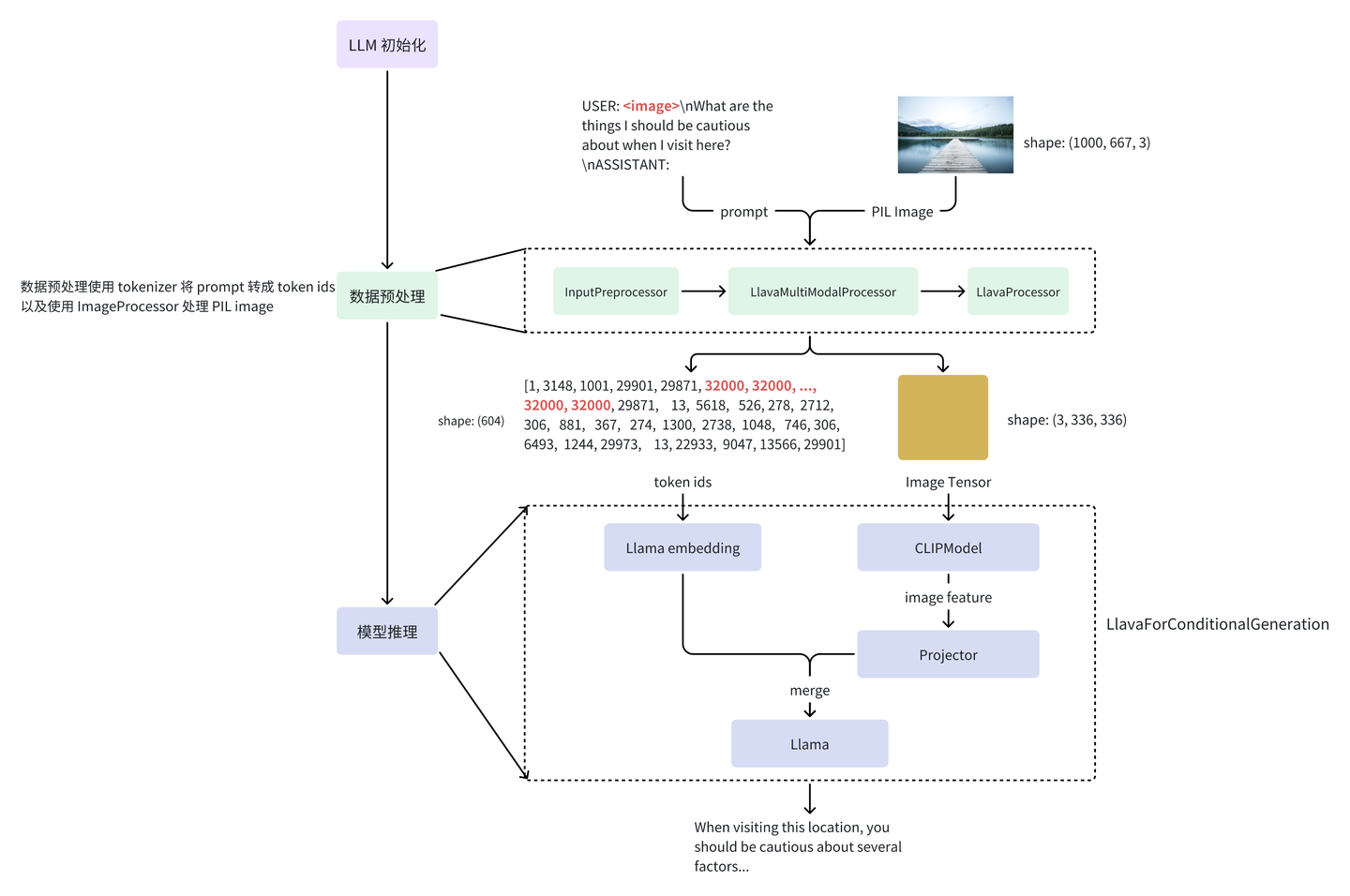
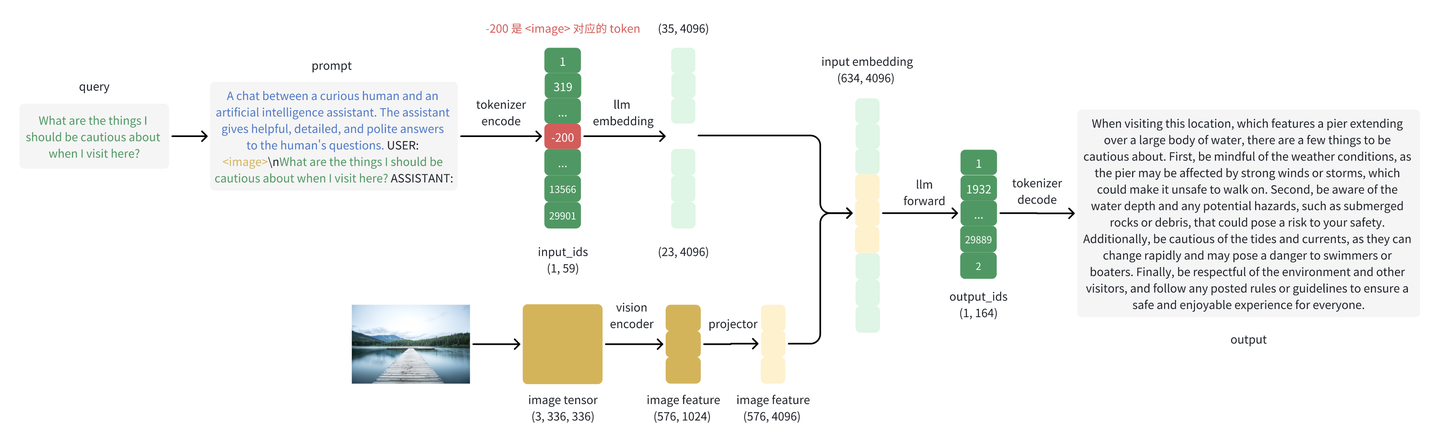
0 vLLM MultiModal preprocessing
This blog briefly explains how vLLM handels text and image tokens.
Other blog from this author also explain more details of LLAVA
1 Bug and Fix
The bug is mismatch during merging of multimodel embeddings
raise ValueError(
ERROR 03-27 07:39:33 [core.py:344] ValueError: Attempted to assign 2016 = 2016 multimodal tokens to 2013 placeholders
ERROR 03-27 07:39:33 [core.py:344] `
and the fix is to create a mask showing which token placeholders are for image embeddings.
# NEWLINE is marked as False in the mask
#image_tokens = ([_IMAGE_TOKEN_ID] * ncols +
# [_NEWLINE_TOKEN_ID]) * nrows
mask = torch.tensor(([True] * ncols + [False]) * nrows)
embed_is_patch.append(mask)
and use two util functions to scatter the embeddings and select them out later
scatter_patch_features(*args) for args in zip(
vision_embeddings,
image_input["embed_is_patch"]
)
select_patch_features(multimodal_embeddings)