4Bit Quantization GPTQ and GGUF and 1Bit LLM
Maarten gives another greate visual guide on quantization. It’s pretty basic but have couple of interesting points
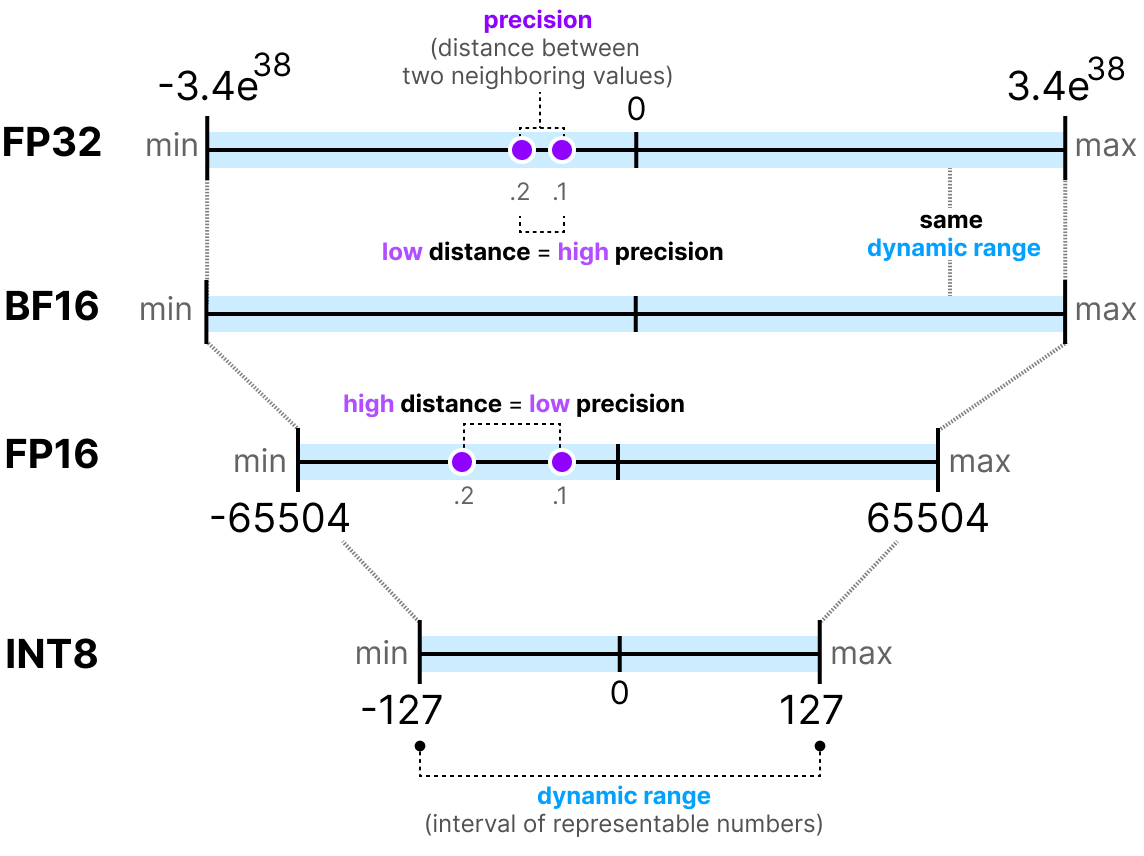
1 BF16
BF16 actually has the same dynamic range as FP32, due to using same 8 bits for Exponent. (Leaving 7 for significand/mantissa, vs 23 for FP32)
FP16 is 5bit and 10 bits.
2 Calibration
Quantization of the weights is performed using either symmetric or asymmetric quantization.
There are two forms of quantization of the activations:
- Dynamic Quantization
After data passes a hidden layer, its activations are collected. This distribution of activations is then used to calculate the zeropoint ( _z ) and _scale factor ( s ) values needed to quantize the output: - Static Quantization
static quantization does not calculate the zeropoint ( _z ) and scale factor ( _s ) during inference but beforehand. To find those values, a calibration dataset is used and given to the model to collect these potential distributions.
3 GPTQ
- GPTQ is arguably one of the most well-known methods used in practice for quantization to 4-bits on GPU
- GPTQ is based on OBQ(Optimal Brain Quantization), which is based on OBS (Optimal Brain Surgeon), which is based on OBD(Optimal Brain Damage) proposed by LeCun in 1990
- It’s asymmetric quantization and does so layer by layer such that each layer is processed independently before continuing to the next
- converts the layer’s weights into the inverse-Hessian. It is a second-order derivative of the model’s loss function and tells us how sensitive the model’s output is to changes in each weight.
- we quantize and then dequantize the weight of the first row in our weight matrix.This process allows us to calculate the quantization error (_q)
- we redistribute this weighted quantization error over the other weights in the row. This allows for maintaining the overall function and output of the network.
Here are the pseudo-code from youtube
 Pay attention that we are leaving emergent features out for quantization!
Pay attention that we are leaving emergent features out for quantization!

4 GGUF
- GGUF(GPT-Generated Unified Format) a file format specifically designed for storing and deploying LLMs, especially those that are quantized.
- Huggingface supports all file formats, but has built-in features for GGUF format, a binary format that is optimized for quick loading and saving of models, making it highly efficient for inference purposes.
- allows users to use the CPU to run an LLM but also offload some of its layers to the GPU for a speed up.
- There are different implementations of the GGUF but the principle is divide weights of a layer into super blocks containing sub blocks.
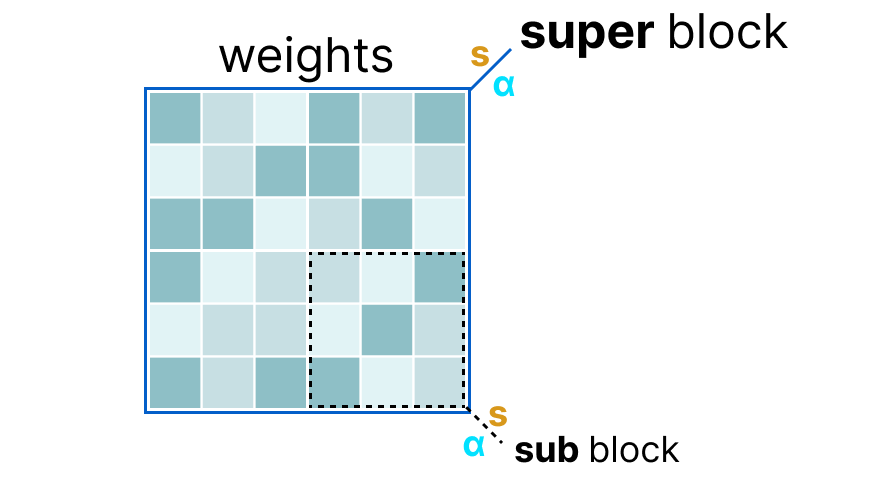
- The scale factor is calculate using the information from sub block it’s quantized using information from the super block

5 1 Bit LLM
No joking, it’s just 1 and -1 for the weight as 1 Bit LLM. It applies to all linear layers, namely BitLinear, and apply to INT8 activations.
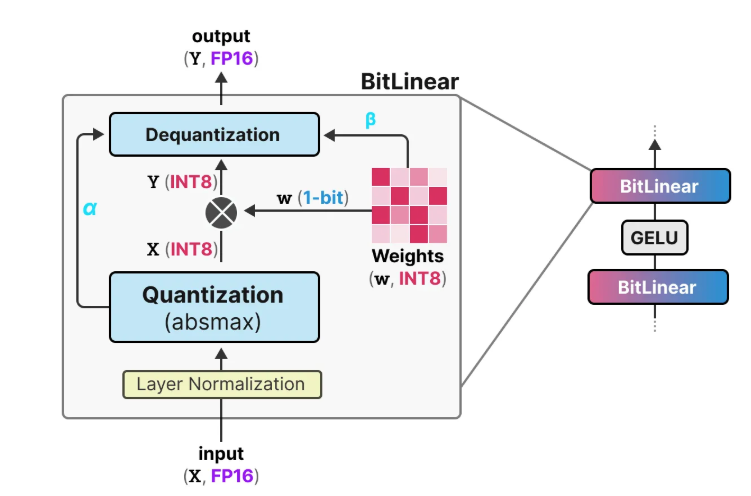 The weights are actually stored in INT8, and changed to 1 or -1 using signum function
The weights are actually stored in INT8, and changed to 1 or -1 using signum function
 and activations are quantize to INT8 with traditional absmax quantization
and activations are quantize to INT8 with traditional absmax quantization
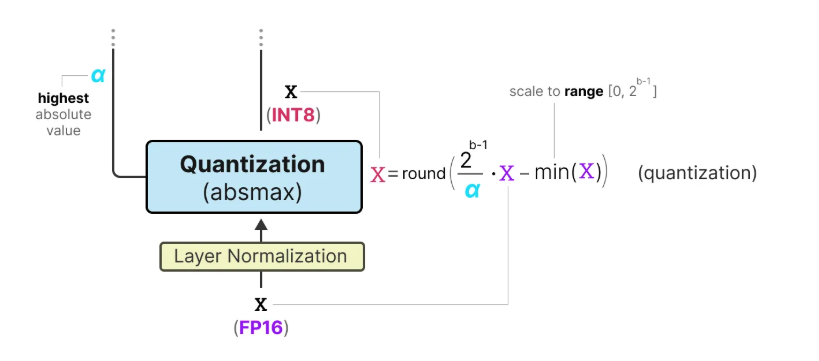 The tracked $\alpha$ nad $\beta$ are used to dequantize results back to FP16
The tracked $\alpha$ nad $\beta$ are used to dequantize results back to FP16

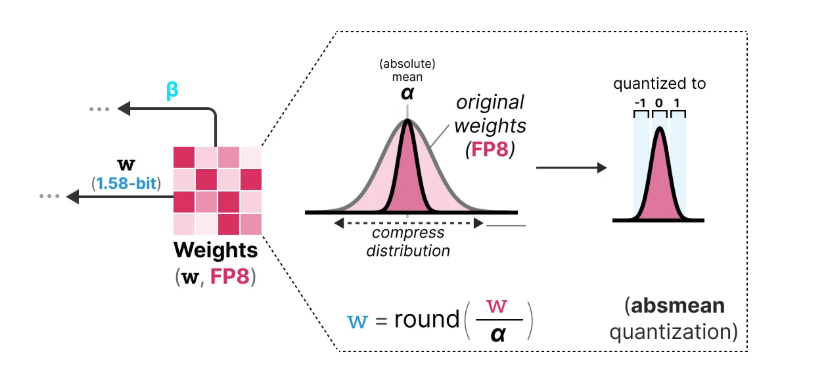
6 All LLM are 1.58 Bits
BitNet 1.58 Bit is adding status 0, making it ternary. The quantization is called absmean function