Boltzmann Machine
I started learning ML with Andrew Ng’s course, and at the same time, I also took Neuron Network from Hinton. The second one is actually very hard for me and I never really understand the Boltamann Machine concept, until this video. It follows Hopefiled introduction and clearly explained how we add stochasticity and hidden units to achive generativity fron MM.
O The beginning
All the generative idea can be tracked back to Boltzmann Machine. Other than Hopfield which can perfectly restore memoery, which, however, is limited by number of neuron, Boltzmann focuses on generate patterns never seen before.

1 Ludwig Boltzmann
In 1870, Boltzmann got his PhD from University of Vienna. His contriution to thermodynamics is to find the probability of a particular’s status with energy E.
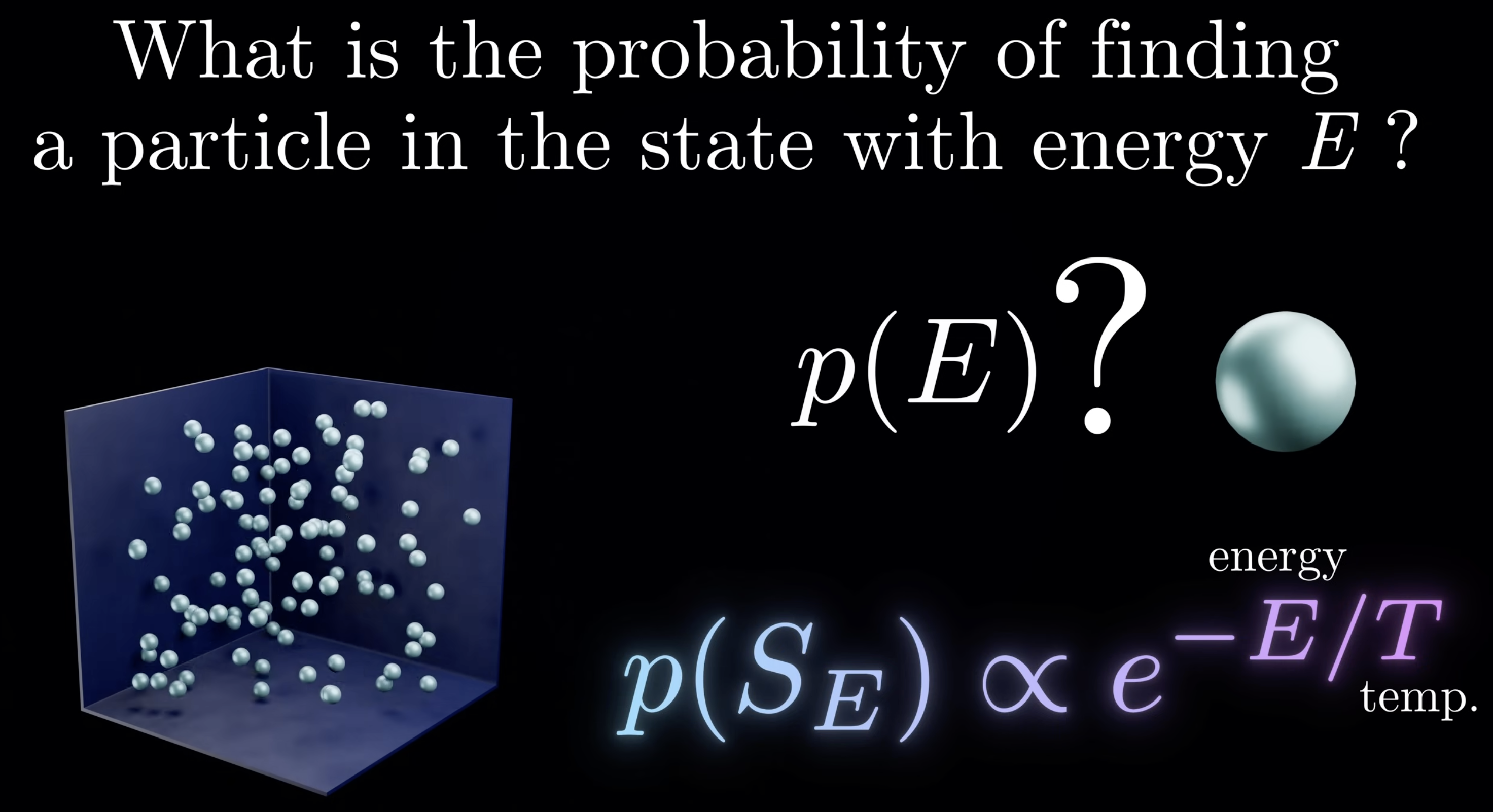 The deduction is straighforward
The deduction is straighforward
 Given the condition that all prob add to be 1, we can notice that the absolute energy is proportional to the relative energy. So we can use the same formular with partition function as the scalar and get the full Boltzmann Distribution
Given the condition that all prob add to be 1, we can notice that the absolute energy is proportional to the relative energy. So we can use the same formular with partition function as the scalar and get the full Boltzmann Distribution
 To summary here
To summary here

2 Inferences.
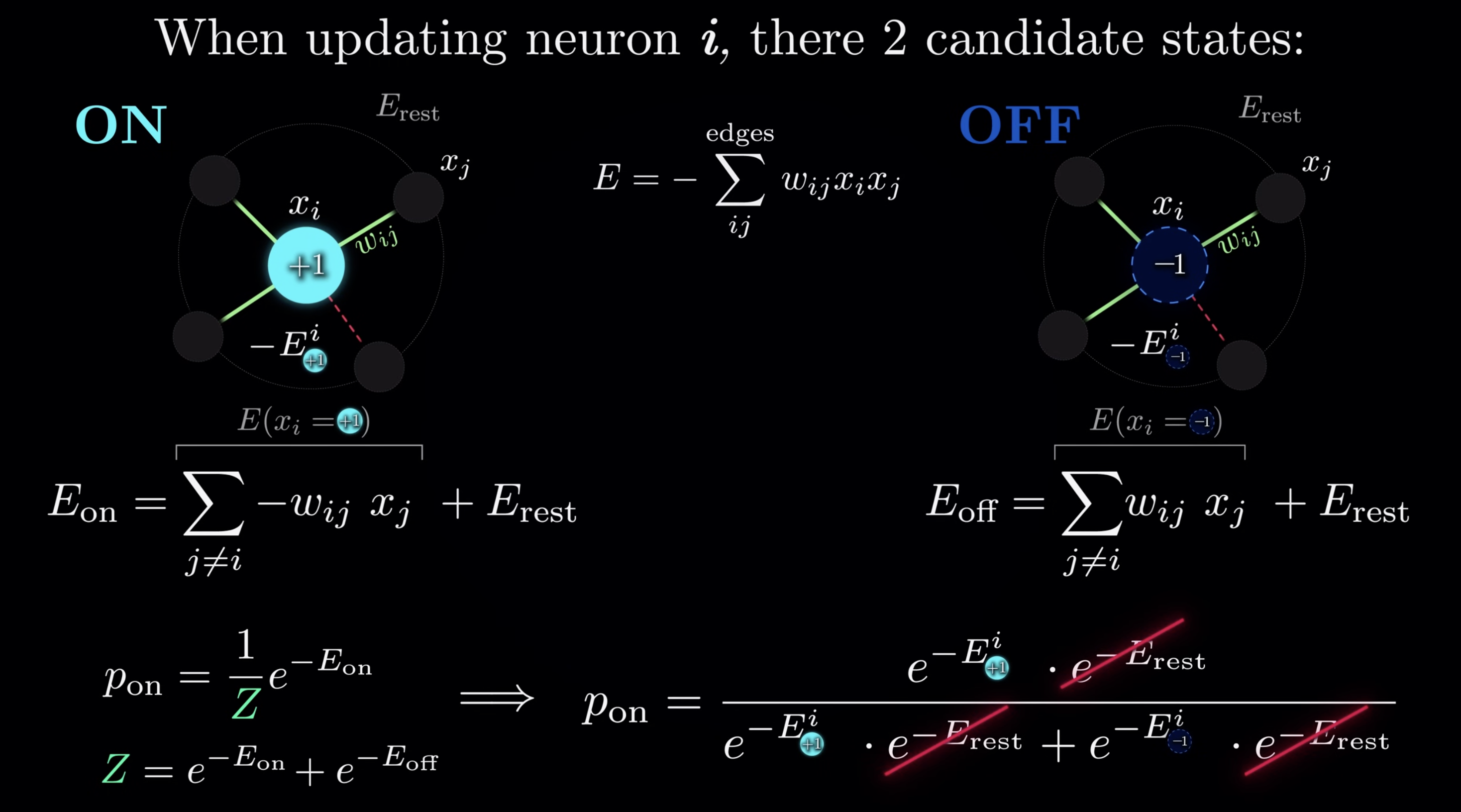
Let’s recall how Hopfield update the status for inference.
 and Boltzmann introduce non-deterministric update
and Boltzmann introduce non-deterministric update
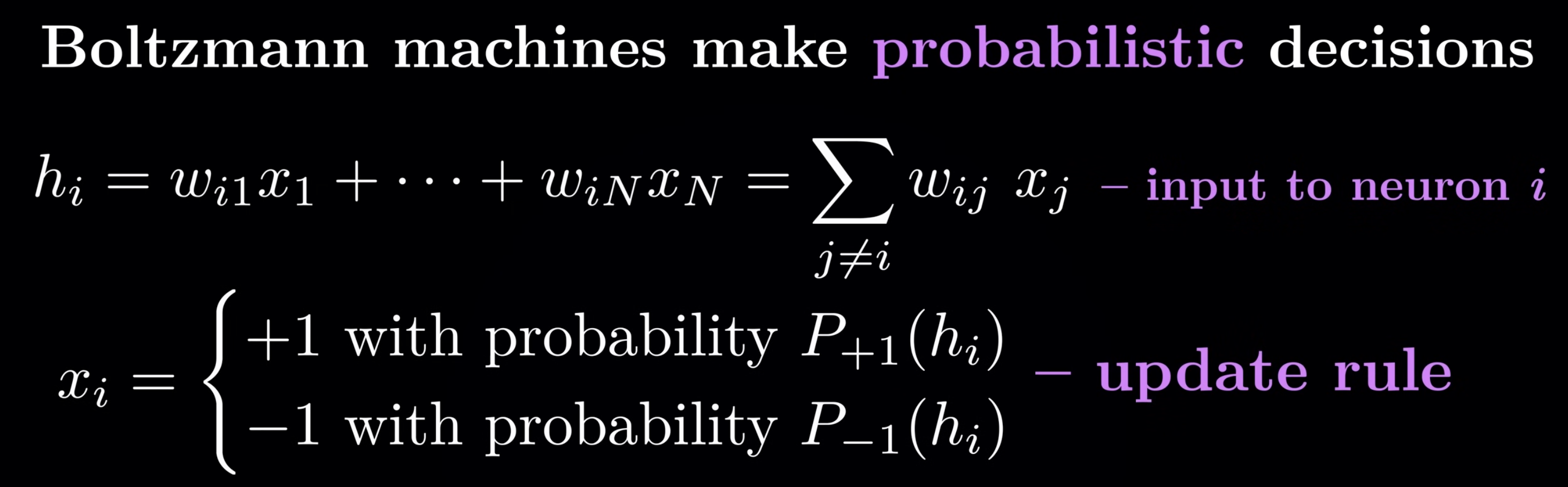
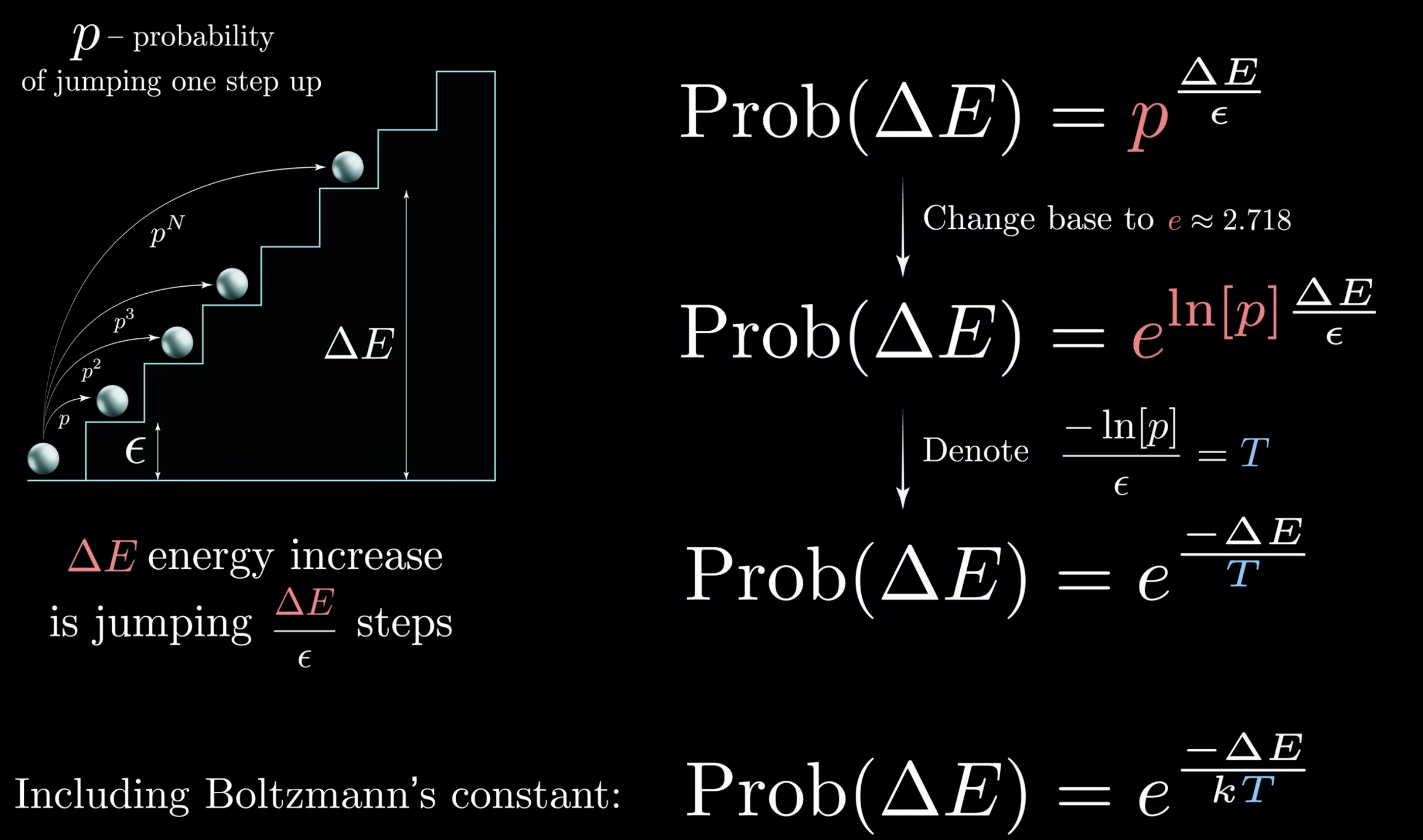
Here are the details of updating deduction
 Replace $\Delta_E$ , you will get the Sigmoid function naturally
Replace $\Delta_E$ , you will get the Sigmoid function naturally
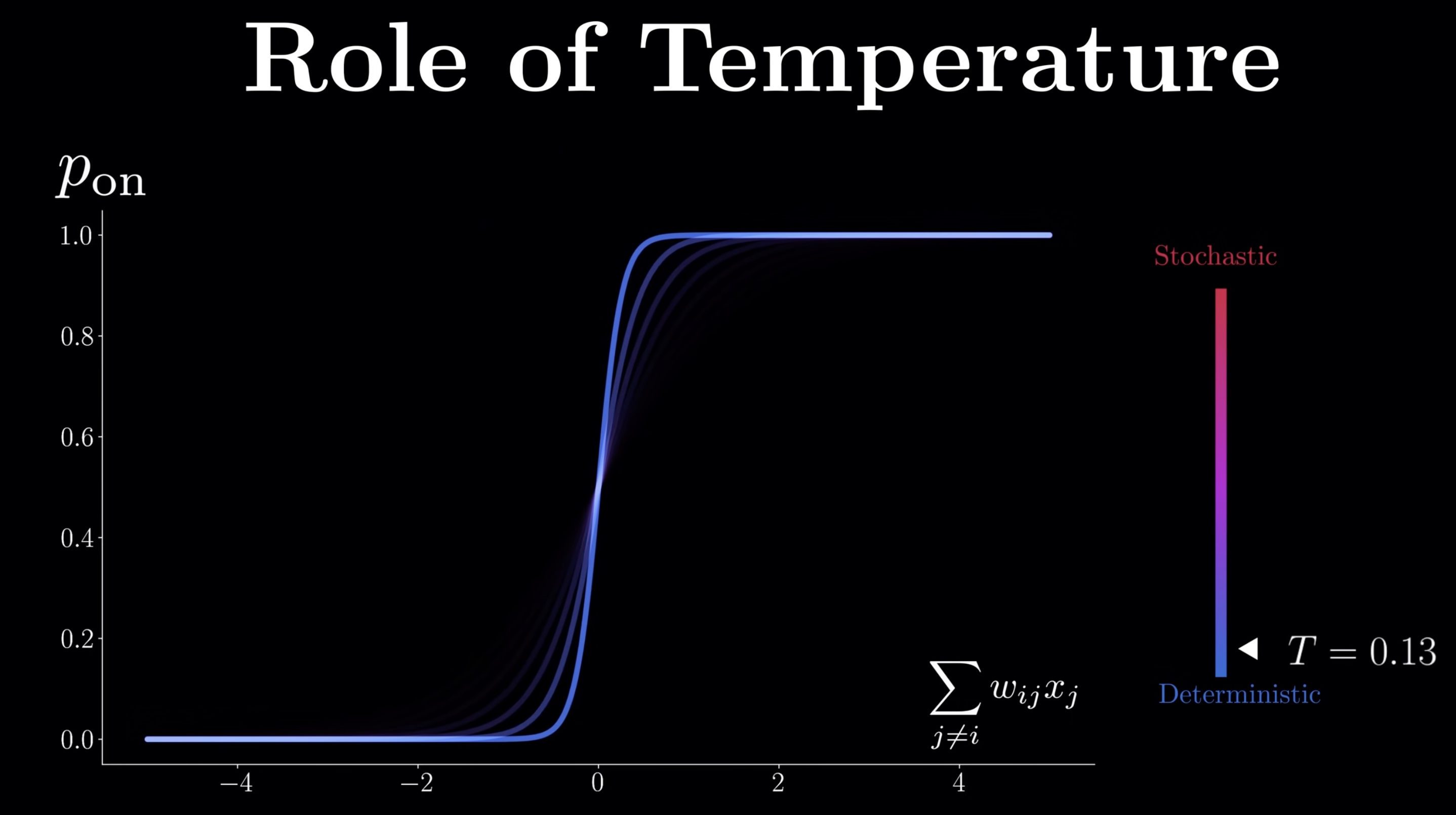
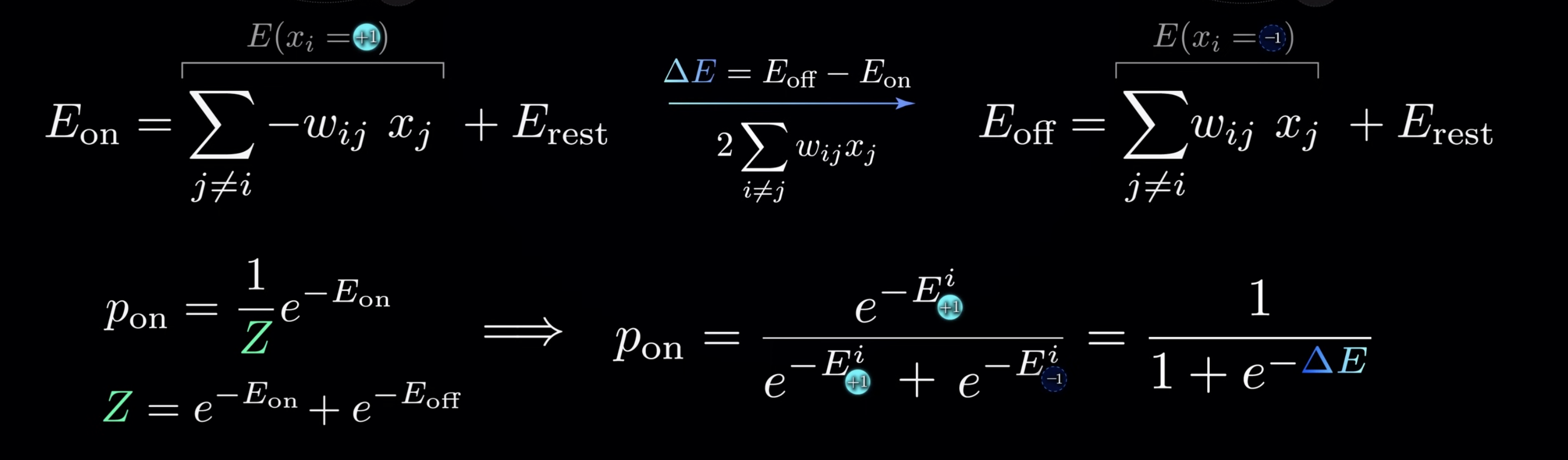 This is also explains the role of temperature, which is widely used in LLM, and low temp means more deterministric results, sigmoid degraded into a step function.
This is also explains the role of temperature, which is widely used in LLM, and low temp means more deterministric results, sigmoid degraded into a step function.
 So here is the summary of inerence steps.
So here is the summary of inerence steps.

3 Training
Boltzmann needs to learn the underlying distribution of the training data, istead of just memorizing the specific examples. This is the previous energy based learning object not pactical here
 The new objetive is all the general goal of all generative ML methods
The new objetive is all the general goal of all generative ML methods
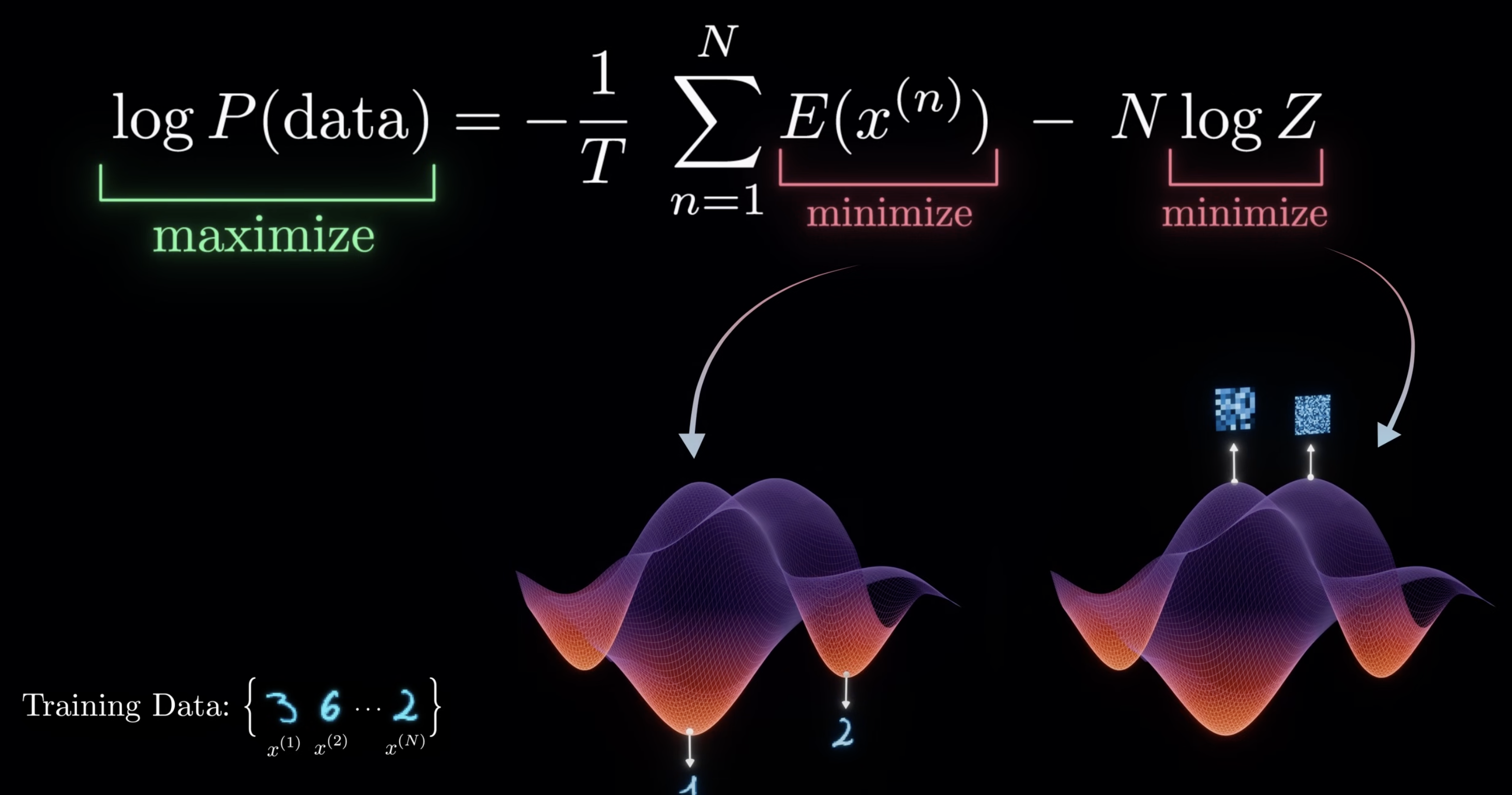
 Through some math deductions, you will get following formula. The minimize data part is easy to interpreate, which is to low the energy of training data, same as Hopefield machine.
Through some math deductions, you will get following formula. The minimize data part is easy to interpreate, which is to low the energy of training data, same as Hopefield machine.
 But the second part is very interesting. Since majority of the status are jiberish, so minimize the partition function, is to maximize the energy of jibberish status (due to the nagative sign).
But the second part is very interesting. Since majority of the status are jiberish, so minimize the partition function, is to maximize the energy of jibberish status (due to the nagative sign).
 This leads to the contrastive learning rule due to the contrastive terms. I see contrastive a lot in the Diffusion learnings, and here is the origin!
This leads to the contrastive learning rule due to the contrastive terms. I see contrastive a lot in the Diffusion learnings, and here is the origin!

4 Hidden Neurons
Adding hidden neurons, which are not connected to inputs. This is crucial for network to learn latent features instead of directly memorizing the examples. The question is how to train them if they are not connected to the training data. The contrastive learning method also adapts here.

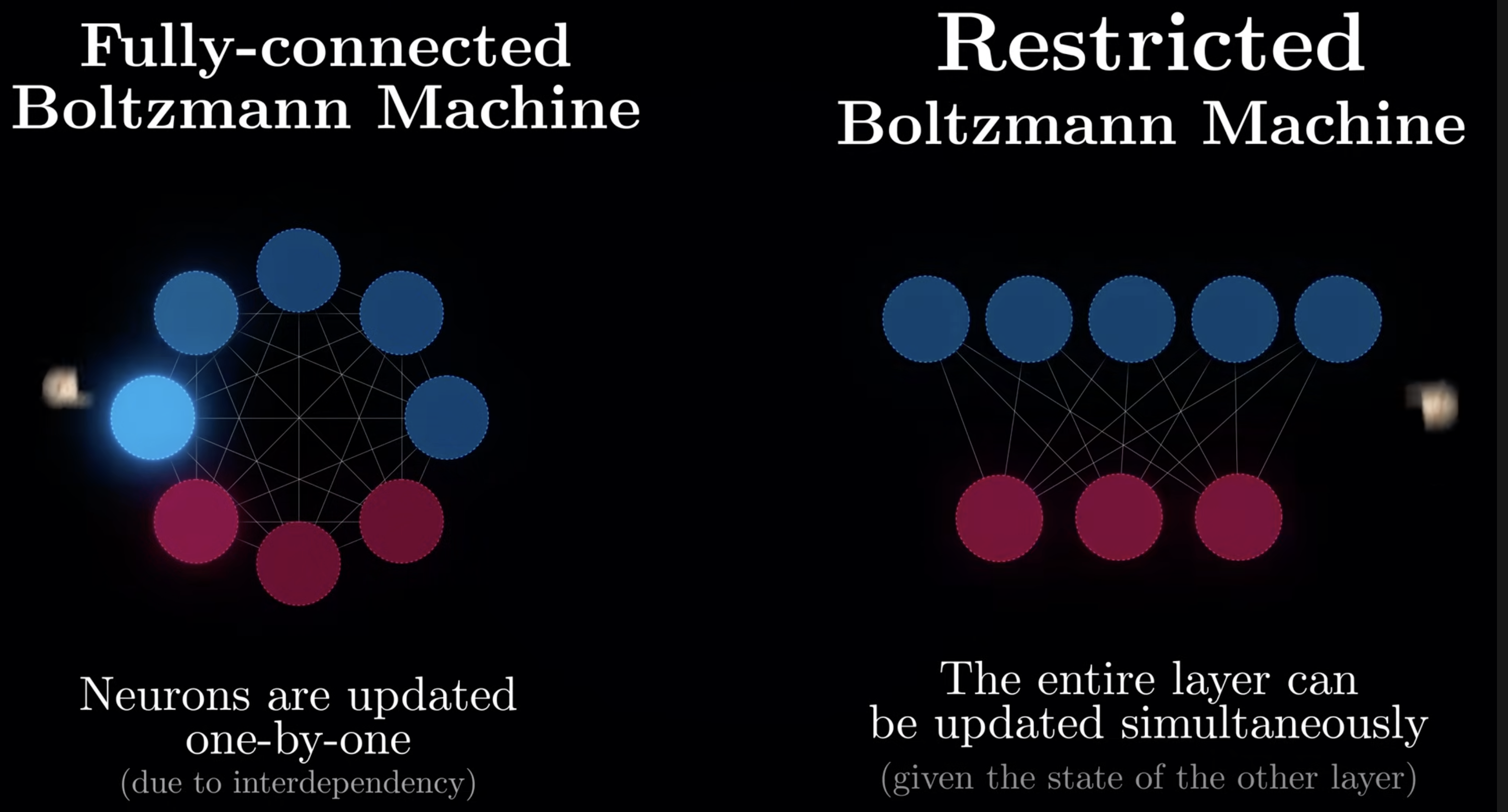
RBM
The restriction, is to restrict the connection between visible, or hidden neurons. Only visible to hidden connections are allowed
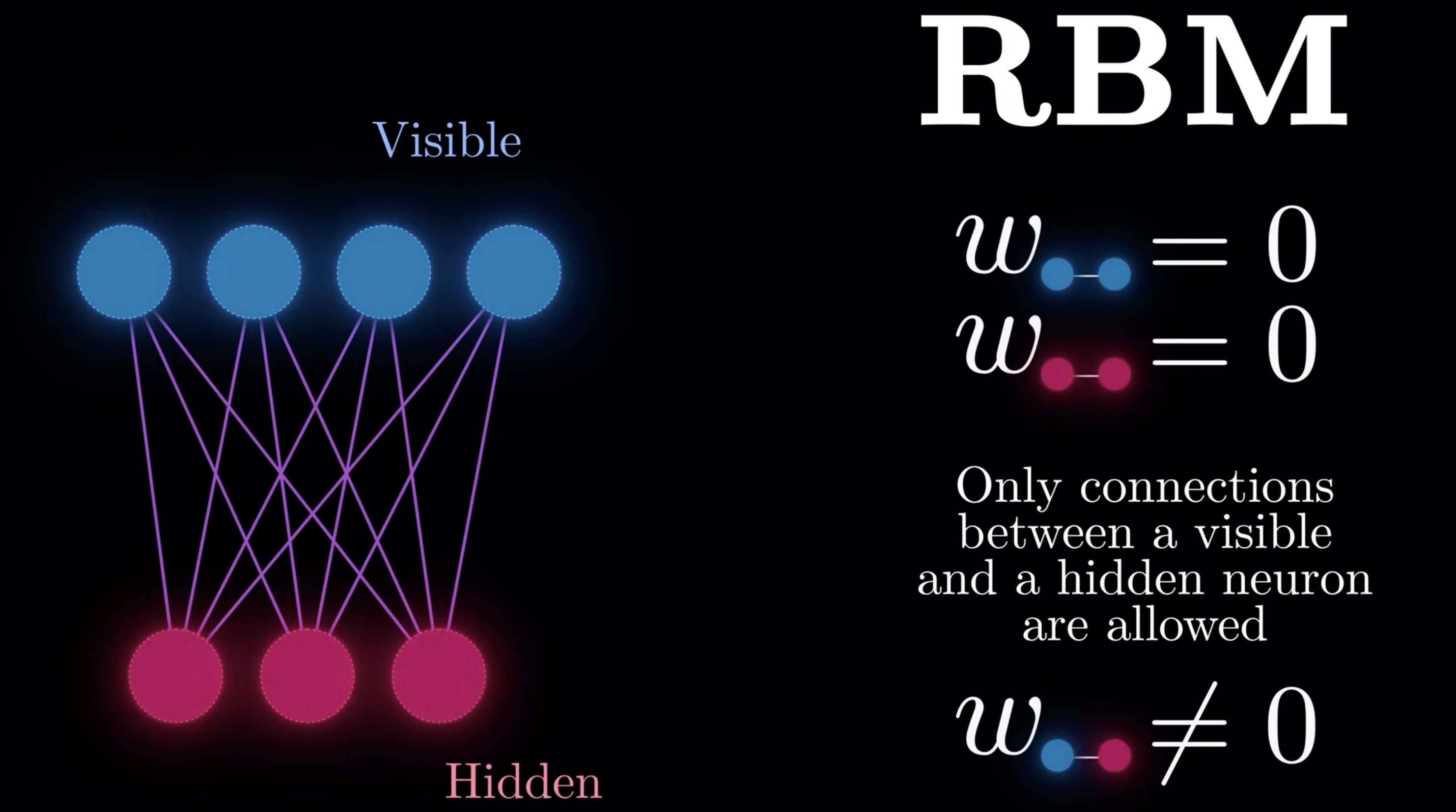 The benefit of doing so is that we can update neurons layer by layer
The benefit of doing so is that we can update neurons layer by layer