CLIP
Dr Vlog gave a talk on CLIP to Math PhDs and summarized in a 50mins video.
0 Paper
OpenAI’s early works for early multimodality model training

1 How it works
The fundamention idea is contrastive learning between image and text contents, thus it gets the name CLIP( Contrastive Language-Image Pretraining)
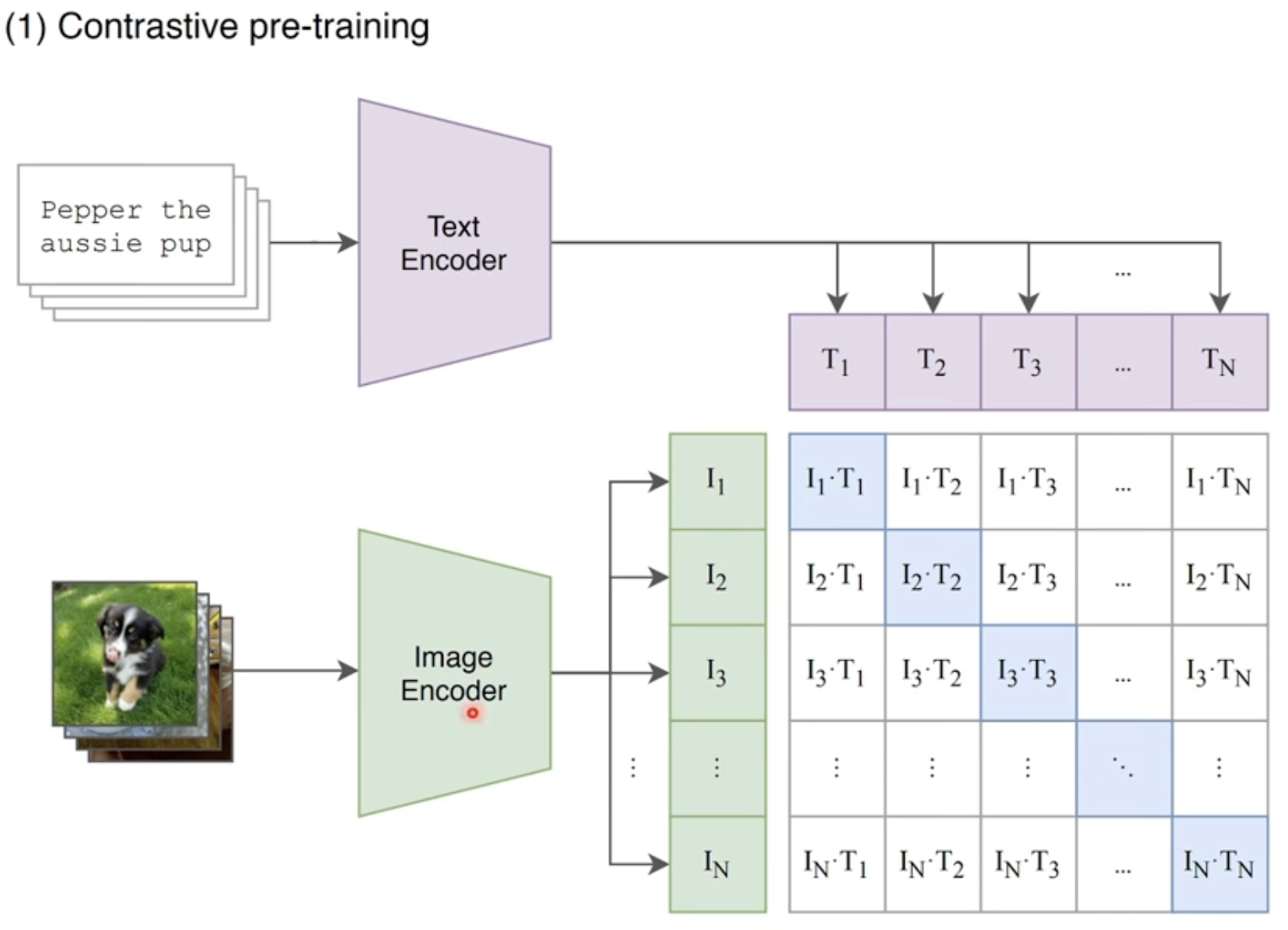 Can be used for zero-shot inferences, which is the main advantage.
Can be used for zero-shot inferences, which is the main advantage.
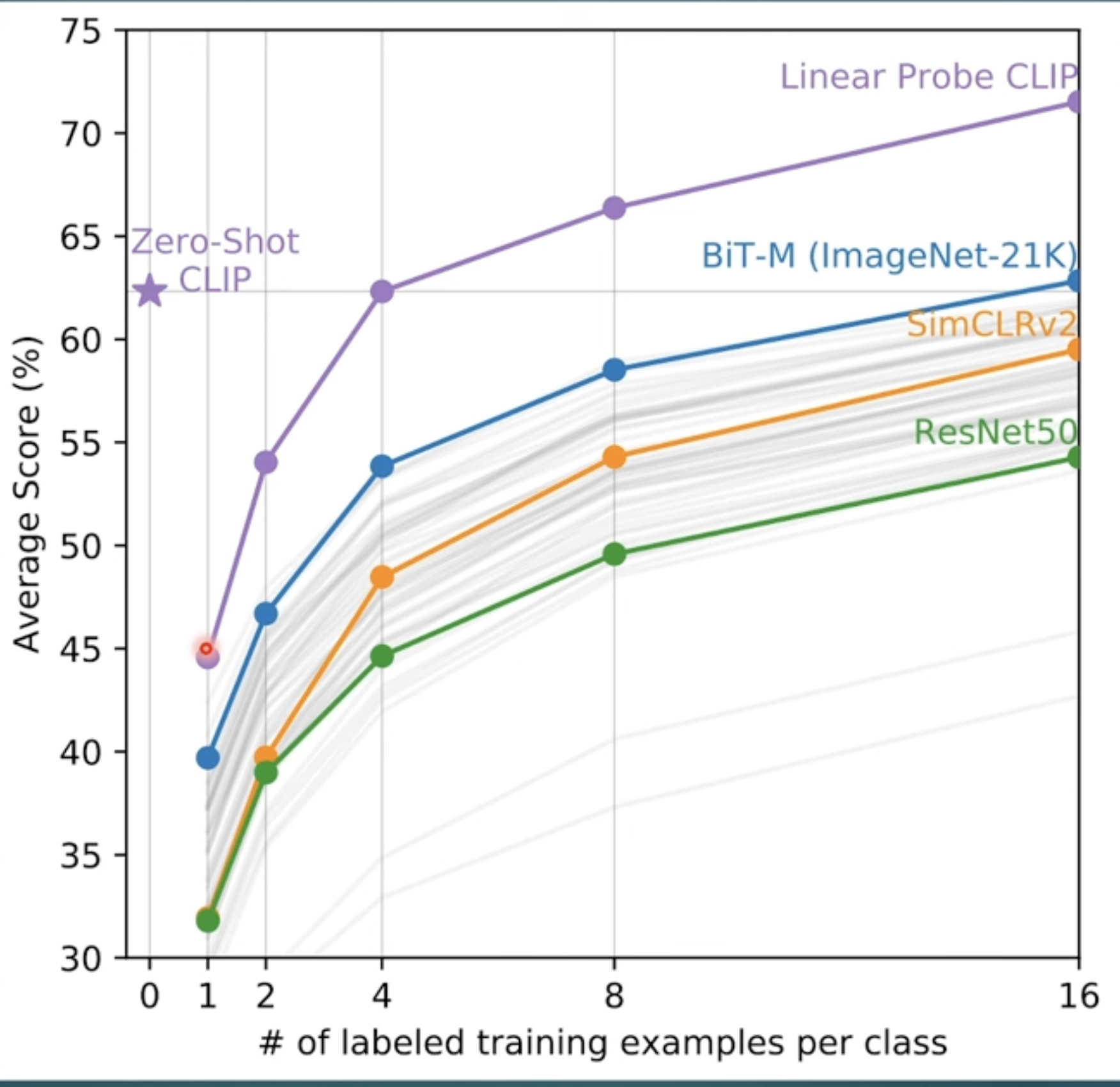
 and it’s zero shot result is even higher than 1 shot, which is totally contract to human behavior. So this is telling us the real “learning” capability of human is still way stronger than current models.
and it’s zero shot result is even higher than 1 shot, which is totally contract to human behavior. So this is telling us the real “learning” capability of human is still way stronger than current models.
Here is the dummy training code for CLIP
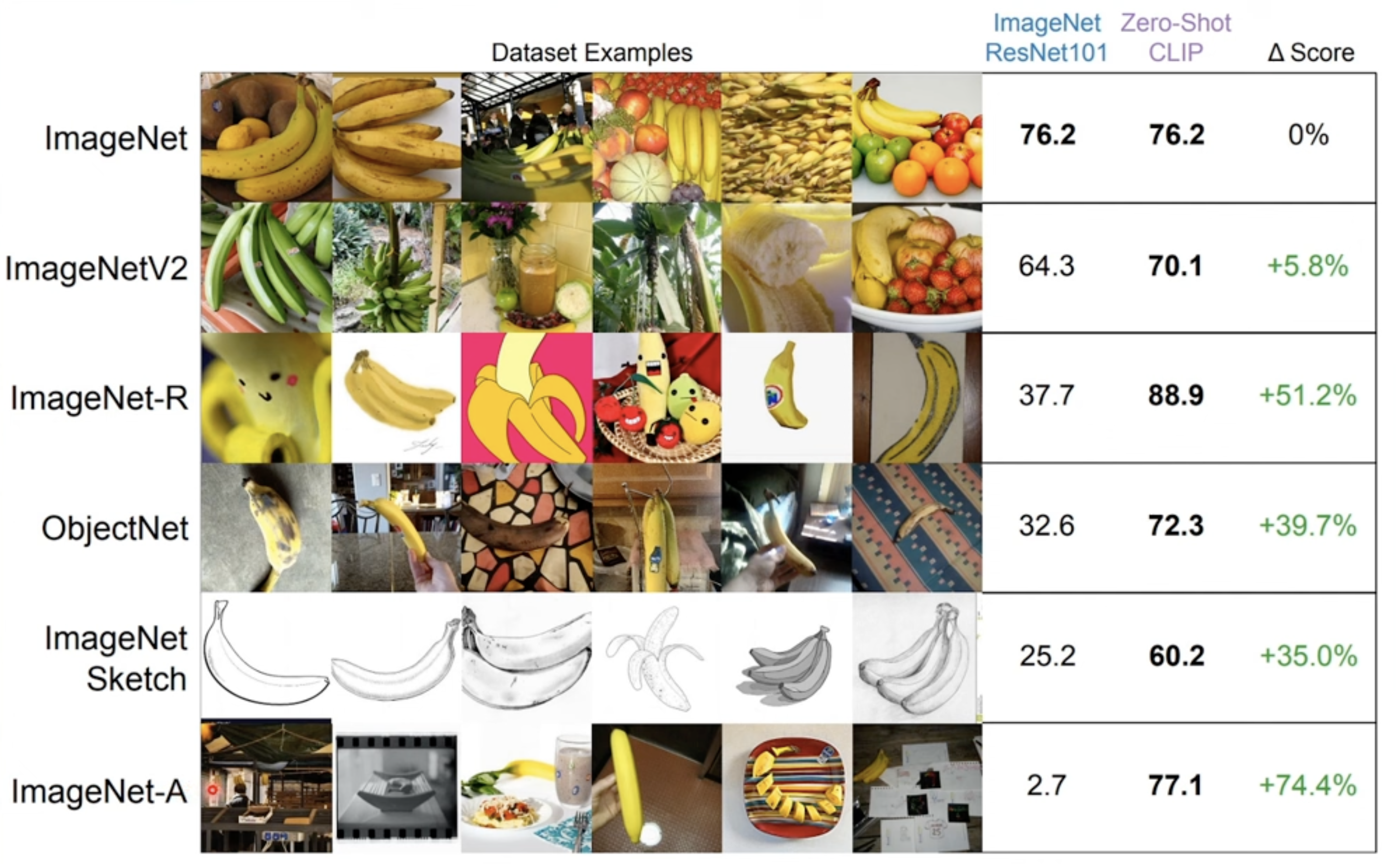
 It adapts well to images sets which is dramatically different from the original one
It adapts well to images sets which is dramatically different from the original one
3 Applications
Apple’s MM1 model is based on CLIP
 and it also shows amazing few-shots learing capability
and it also shows amazing few-shots learing capability
