Context Extension by YaRN
LLM context length can be extended in the post training process. They are all RoPE based algorithem, like YaRN(Yet Another RoPE extensioN)
Summary in this zhihu post
0 RoPE Review
Found another good video on RoPE and shows the key idea of rotate original embedding vector based on the absolute position in the sentence( ONly based on preceeding words)
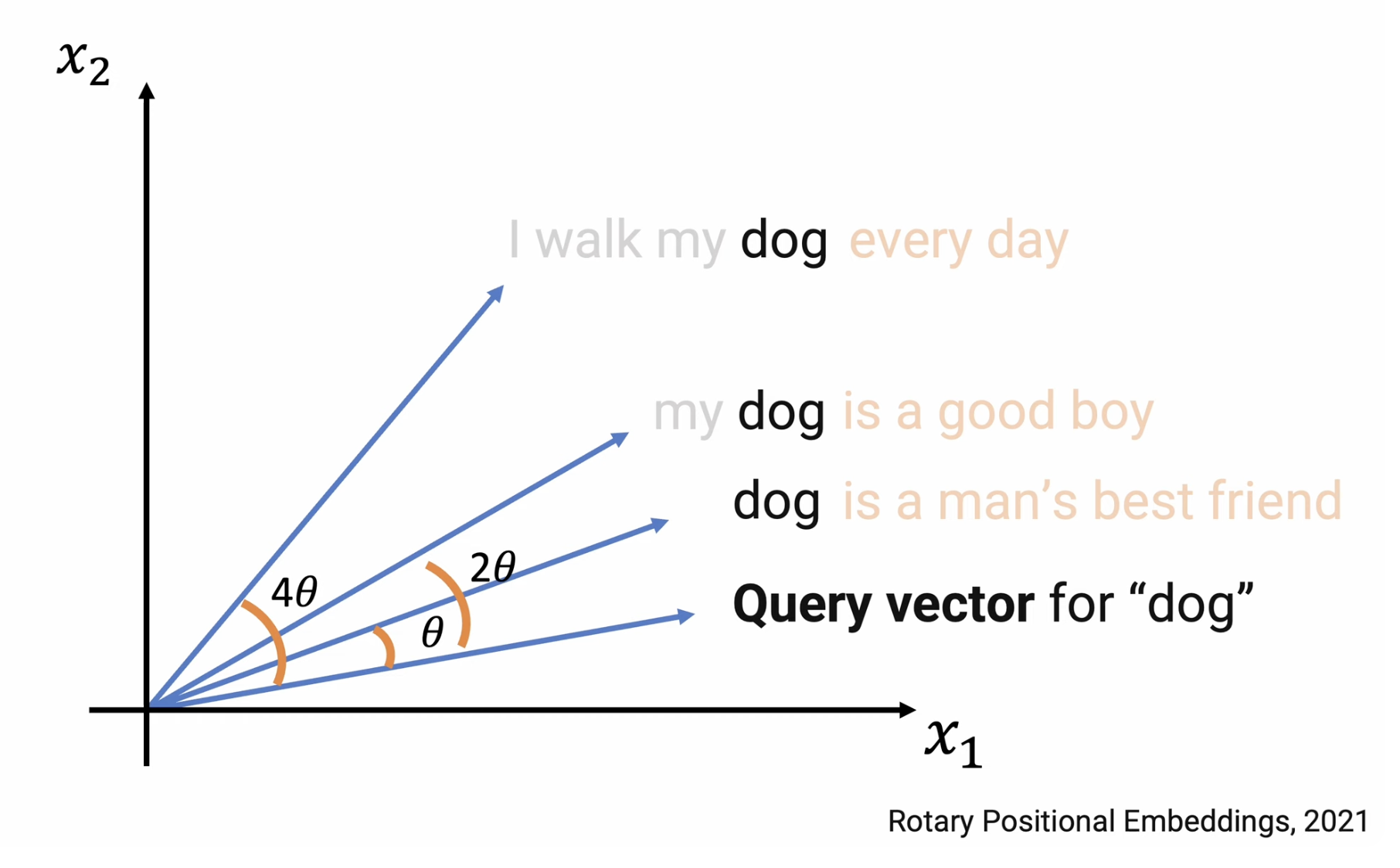 The advantage is that the relative position of the words are preserved no matter other context. For instance, “I walk my dog”, adding prefix or suffix to this sentence, won’t change the relative position of “I” and “dog”, always will be $3\theta$
The advantage is that the relative position of the words are preserved no matter other context. For instance, “I walk my dog”, adding prefix or suffix to this sentence, won’t change the relative position of “I” and “dog”, always will be $3\theta$
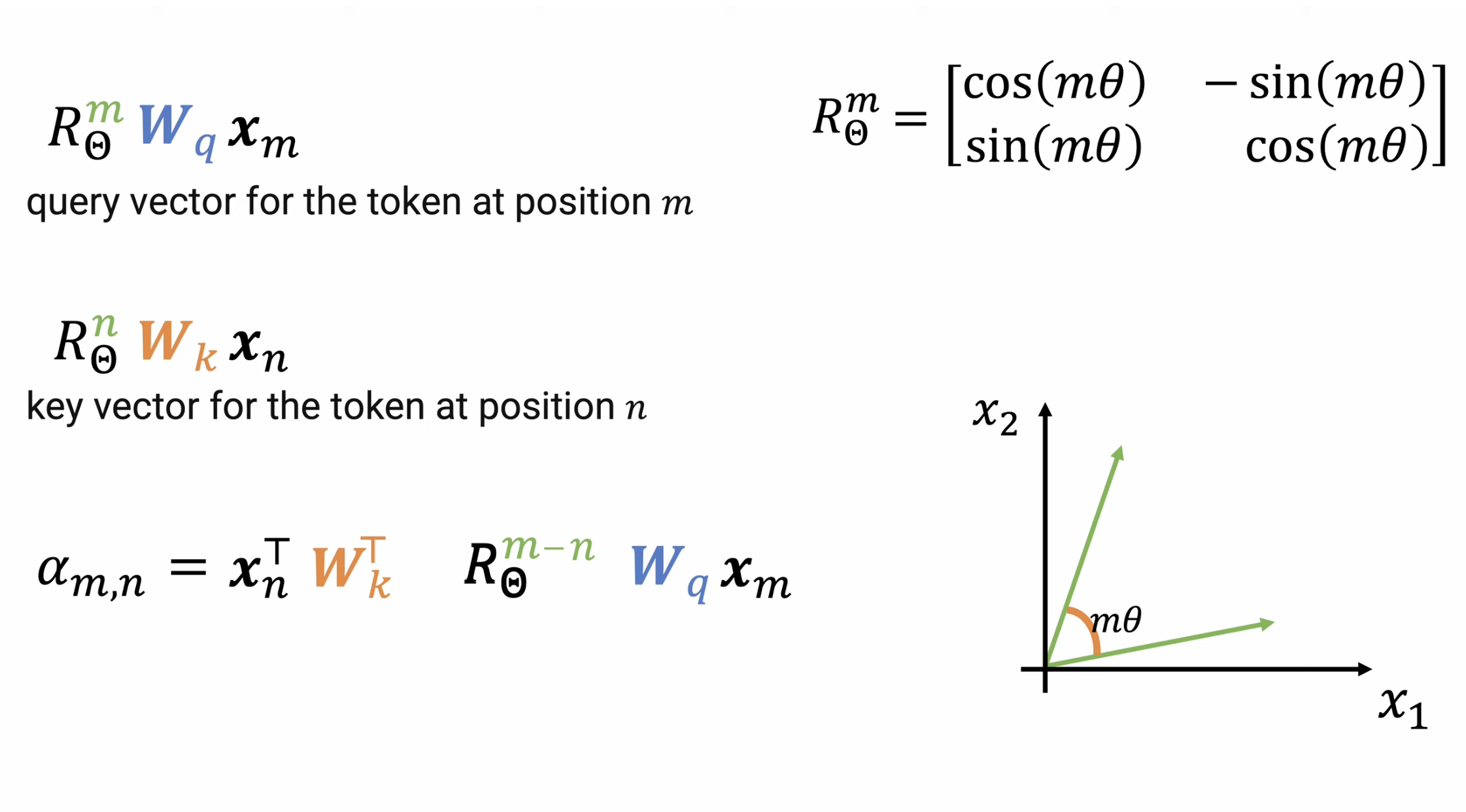 For higher dimentions, we break it down to 2-dim pairs and define different $\theta$ to capture high and low frequence features
For higher dimentions, we break it down to 2-dim pairs and define different $\theta$ to capture high and low frequence features



1 Position Interpolation
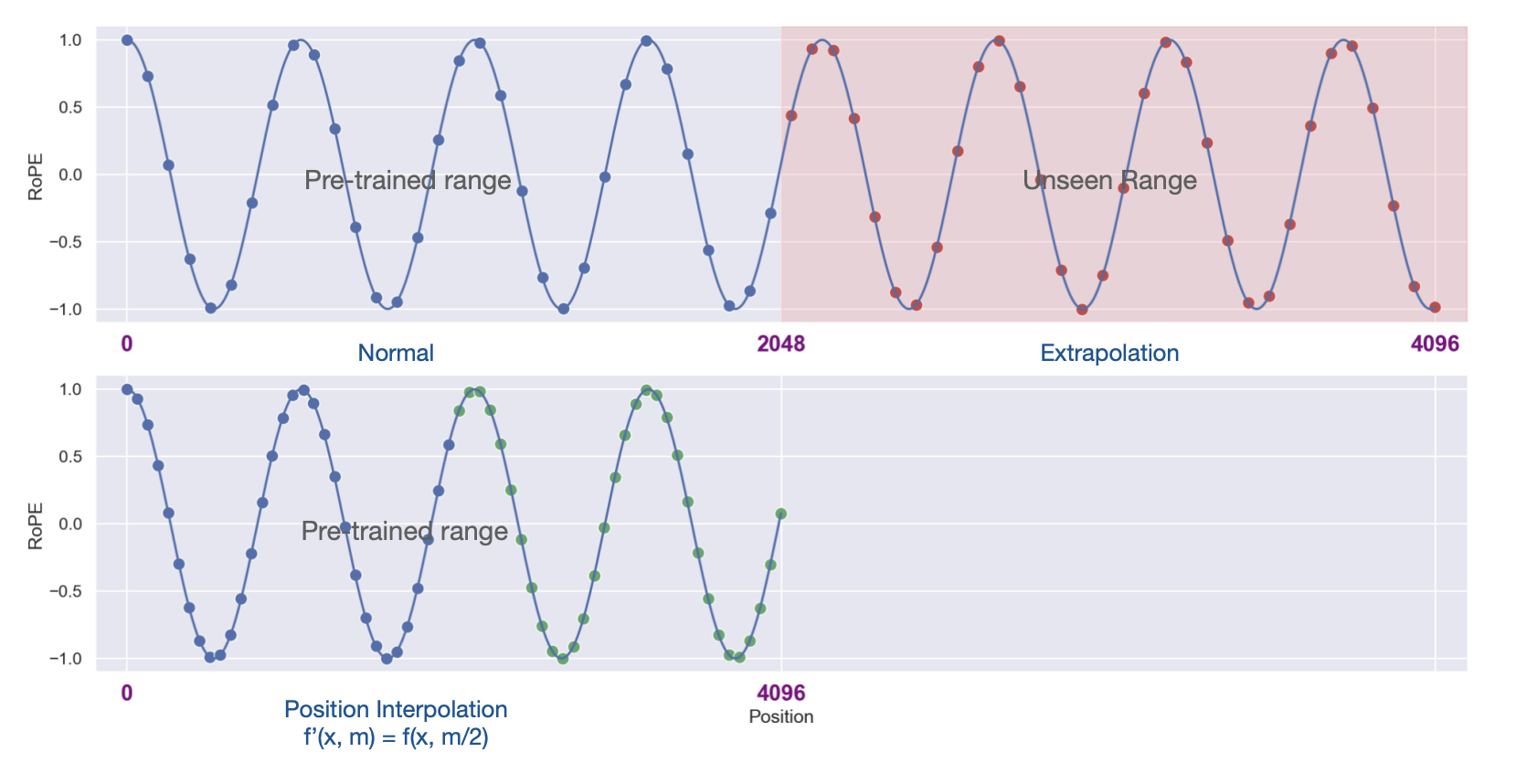
Meta published PI to extent the context window length beyond training. The key idea is to interpolate RoPE directly.It’s simple but insufficient at high freq.
 Let’s rewrite RoPE in complex number form
Let’s rewrite RoPE in complex number form
 and the PI is formulated as following by changing position.
and the PI is formulated as following by changing position.

2 YaRN
Yet Another RoPE extensioN was based on NTK(Neuron Tagent Kernel) and this video shows an early paper to explain this idea.
Following notes are mainly from zhihu and medium
- NTK-aware method to deal with High-freq lost issue in PI. So instead of uniform interpolation, we spread out the interpolation pressure across multiple dimensions by scaling high frequencies less and low frequencies more. Mathematcially it changes $\theta$ to achieve this.

- NKT-by-parts proposes a solution by not interpolating higher frequency dimensions at all and always interpolating lower frequency dimensions.
- If λ is much smaller than L, no interpolation.
- If λ is equal to or bigger than L, only interpolate (avoid extrapolation).
- Dimensions in-between can have a bit of both, similar to “NTK-aware” interpolation.

- NKT-Dynamic is based on Dynamic Scaling which changes scaling factor at every forward-pass. In PI/NKT-aware/NKT-by-part, s = L’/L, where L’ is the fixed number of extended context size. In each forward-pass, the position embedding updates the scale factor s = max(1, l’/L), where l’ is the sequence length of the current sequence.

- YaRN = KNT-by-parts + logit temperator
