Deepseek R1 - GRPO
EZ encoder’s new video on DeepSeekMath
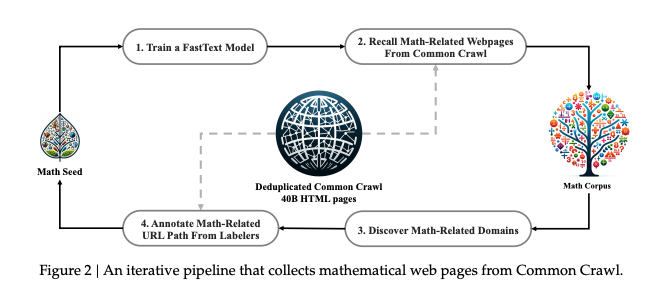
1 Data collection
Collect 120B tokens, and train 1.3B model first before traning the 7B model.
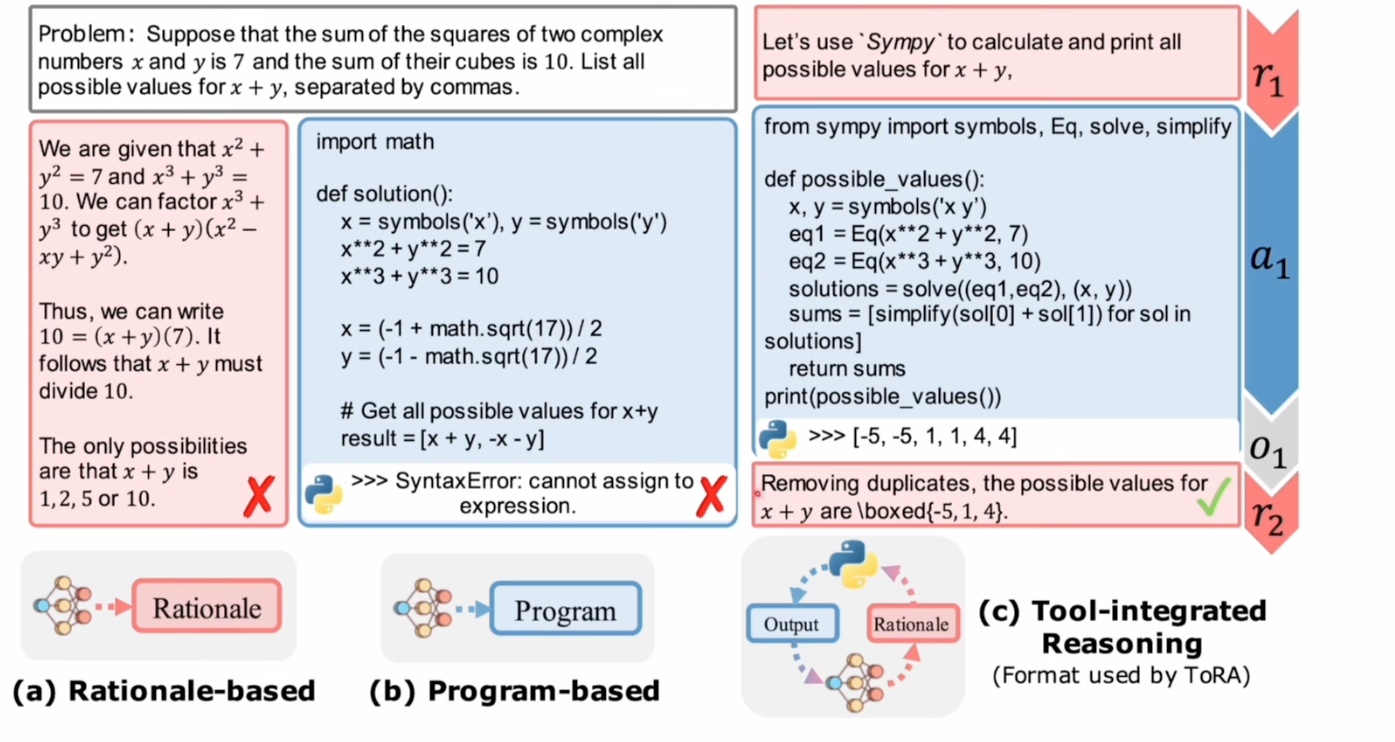
2 PoT
Program-Of-Thought, use program as thinking progress.
Tool-integrated Reasoning is combining of CoT and PoT
3 RL and GRPO
The top down of RL.
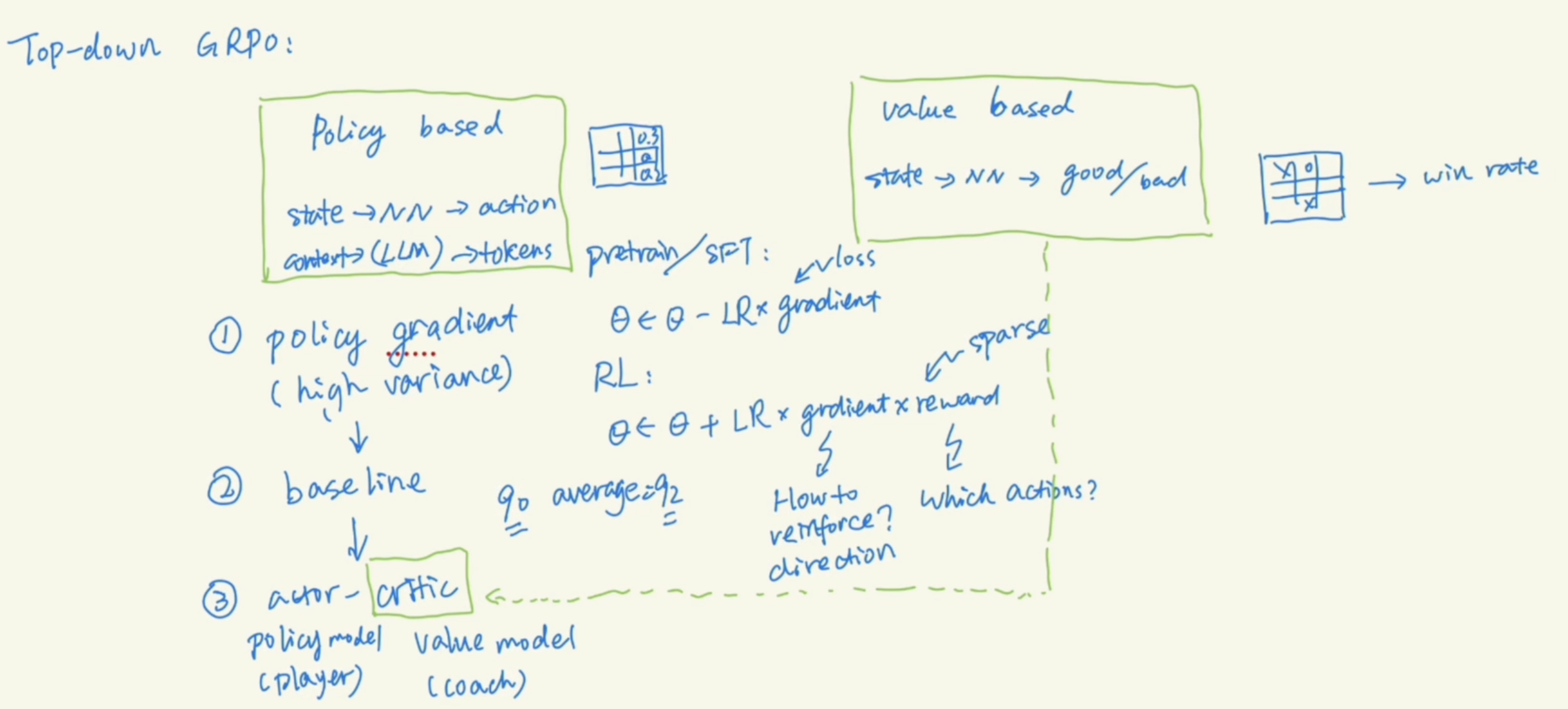 TRPO is adding a constrain between old and new policy, let KL divergence limited.
TRPO is adding a constrain between old and new policy, let KL divergence limited.
PPO is a simplied TRPO by removing the KL div but use a clipping method.
GRPO is further simplifying PPO by removing value model and compute the average of rewards for multiple CoTs. And use each reward minus this average as the advtange.

The lower bound, clipping, and KL div are used to limit the model from changing too much
