Deepseek R1 - RL review
Taking notes from EZ Encoder Academy’s video series about R1.
1 What’s is AGI
Part 1 of the video is explain difference of R1 Zero, using RL only for post-training, and R1, using bootstrapping with cold start. I will skip most of it, and one interesting topic is about security is deepseek, which is 100% vunlerable against attackss
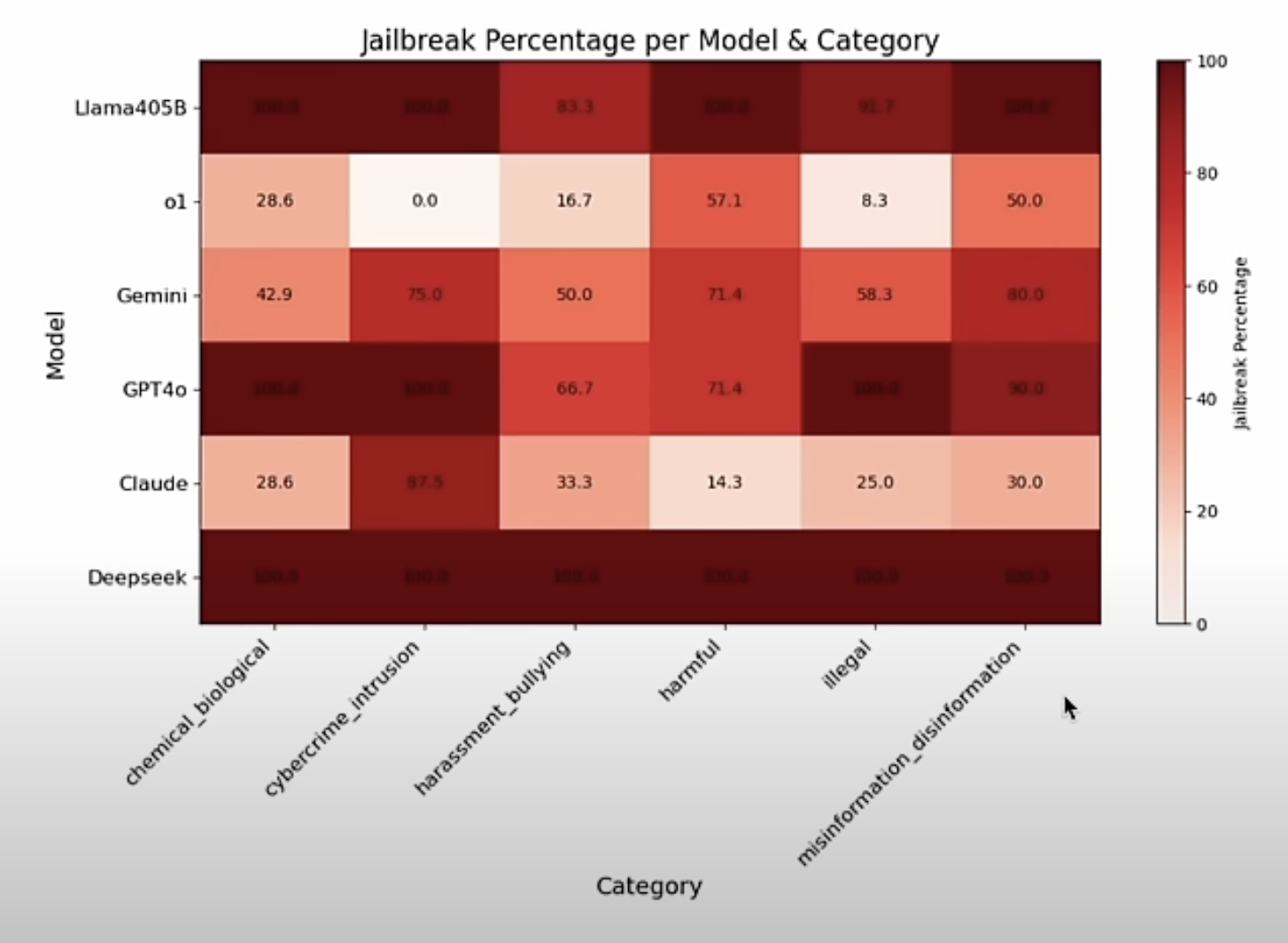
A google paper gives the defination of different levels of AGI
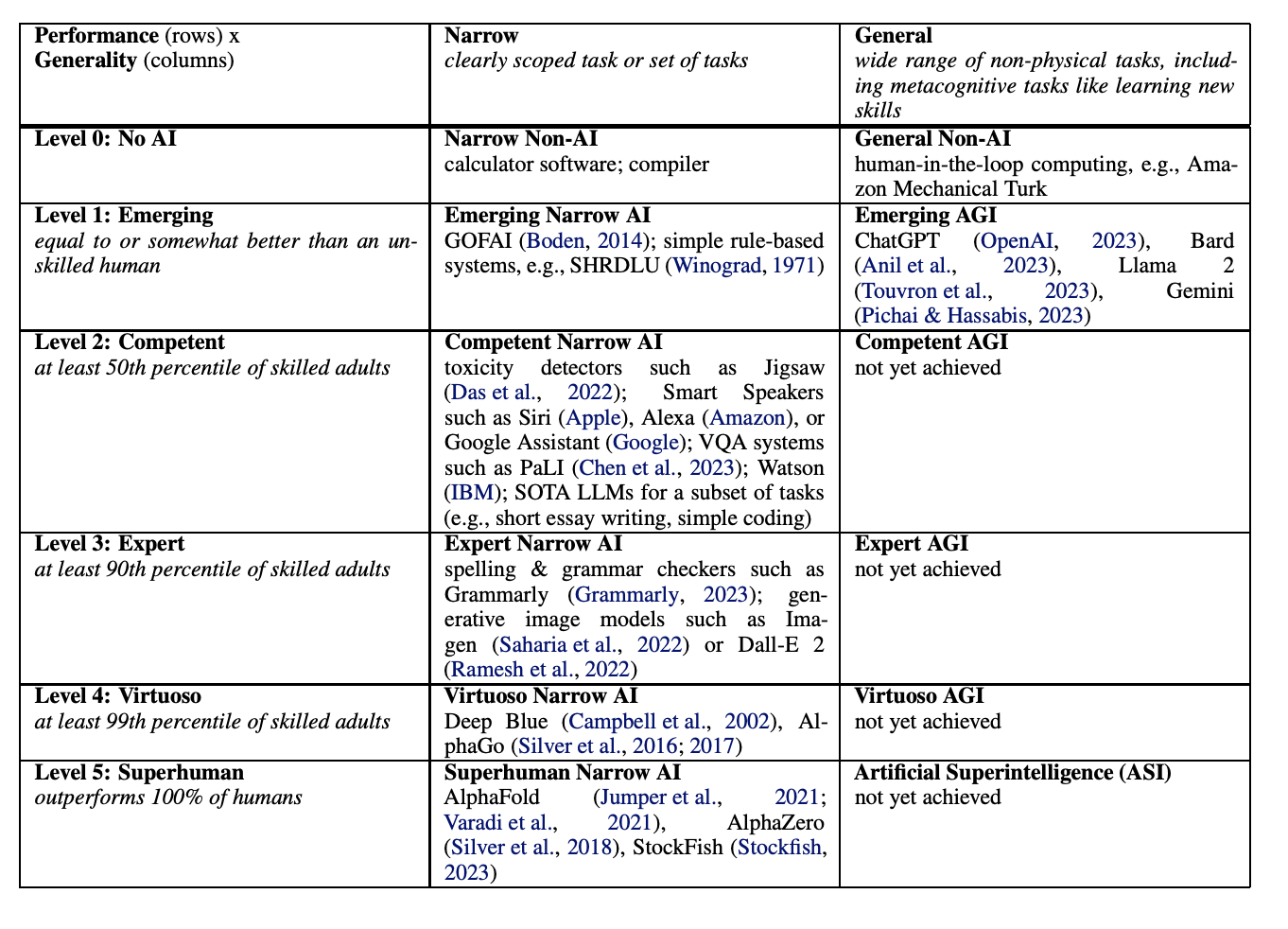
Deepmind, OAI uses RL to achieve RL, and OAI is more focus on LLM approach since ChatGPT. LLM can be considered as RL, as context is environment, LLM is the agent, and next token is the action. LeCun is thinking JEPA(Joint Embedding Predictive Architecture) is the way to achieve world model. See details here
2 RL in Review
Comparing Supervised Learning with RL, the GT for SL is very dense, have GT for each data point, while GT for SL is sparse, providing rewards after several steps.
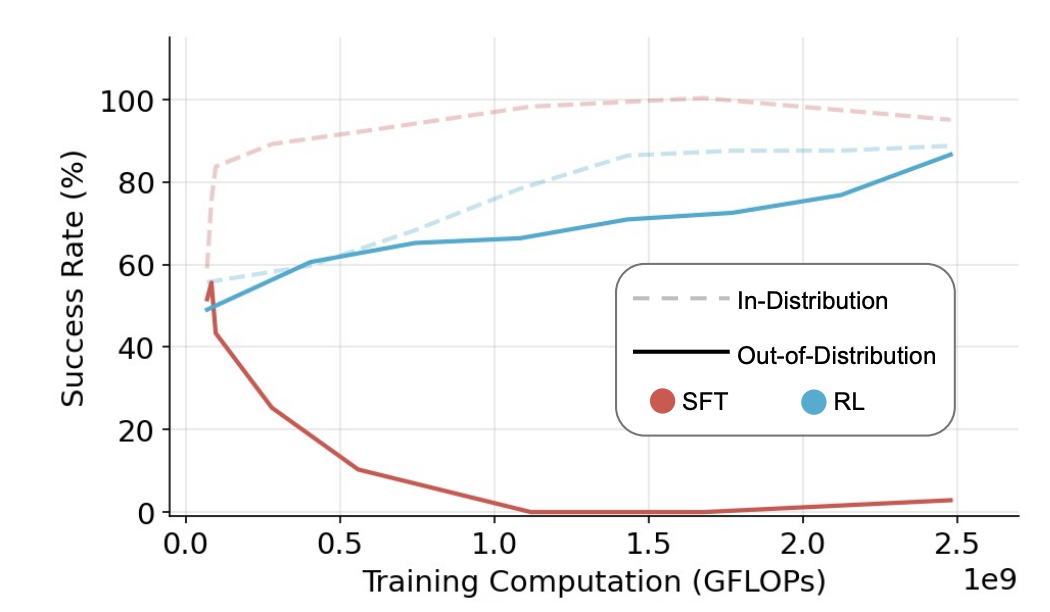
A paper summarized it as “SFT Memorizes, RL Generalizes”
Policy based method is to train the agent to take action, like agent being player(actor). Value based method is to get a value for agent actions, like a coach to the agent(critic). These two can be combined as in Actor-Critic method

3 How RL is different from SL
-
Reward is sparse, so most of the training and optimization tricks in RL is to get sparse reward properly handel to training the policy network. Like both PPO and GRPO.
-
Reward defination can be in verifiable domain, like coding/math/game, or unverifiable domain, based on human perference. This could leads to reward hacking, like Terminators want to terminate human, which is easy way to achieve best rewards for protecting the earth.
-
RL dynamically interacted with the environment, so we can simulate the states between two RL agents, like playing go games.
-
Explore vs Exploit.
4 AlphaGo and AlphaZero
Essencially, it’s just search algorithm behind the scene, with RL used to help trim search pathes
- For simple game like tic-tac-toe, $10^4$, brutal force search can solve the problem, which is Monte-Carlo simulation.
- For Chess, $10^{47}$, DeepBlue uses rule-based search algo.
- For Go, $10^{170}$, AlphaGo uses Policy and Value network to help the search, thus RL based searching.
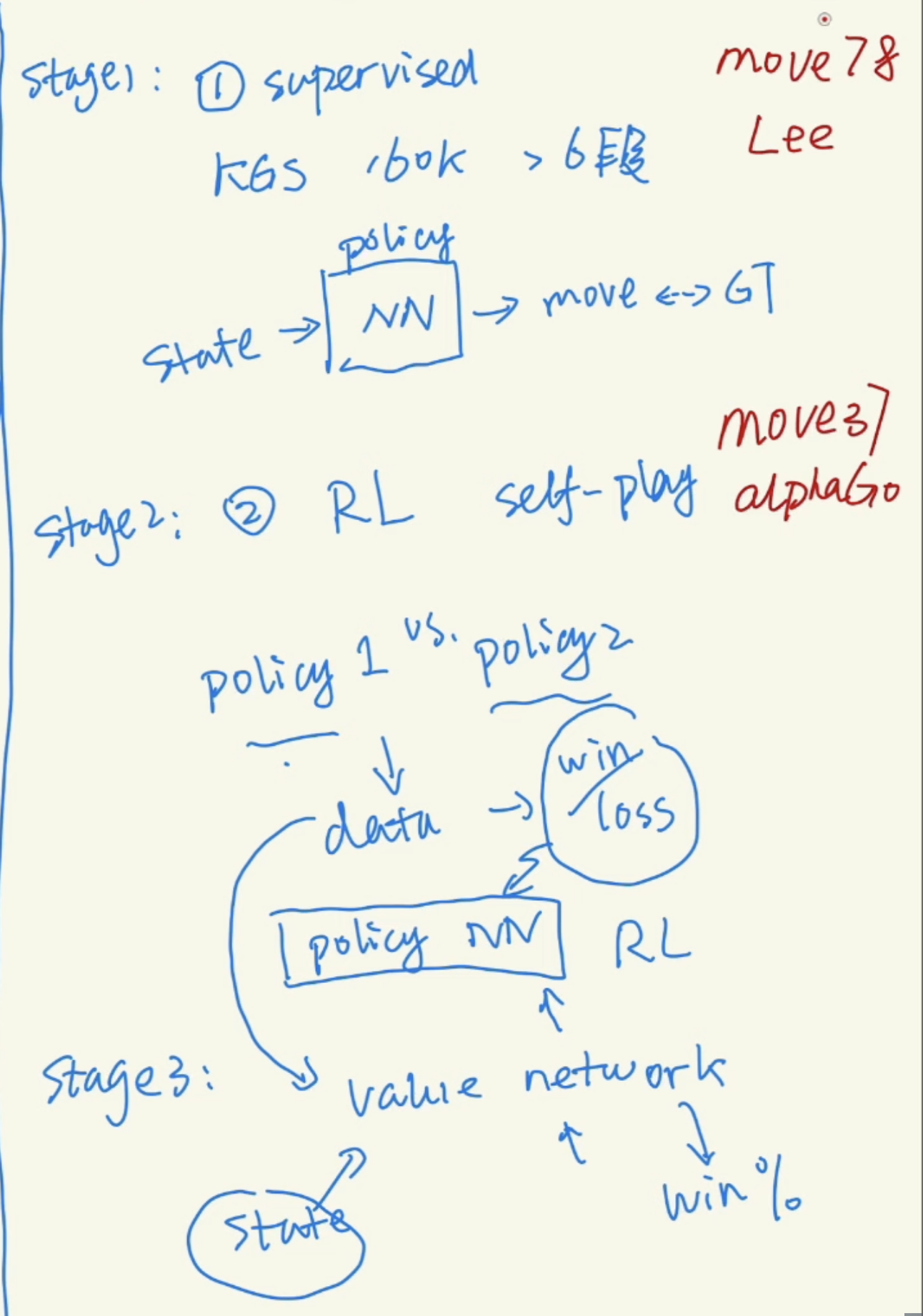
The training of AlphaGo has three steps
- SL with human datasets
- Train the policy network with self-play to learn how to play
- Train the value network from self-play data to evaluate states
So Move 37 from AlphaGo was considered bad move, but eventually is a great move
Move 78 from Lee was un-common move, which helped Lee to beat AlphaGo.
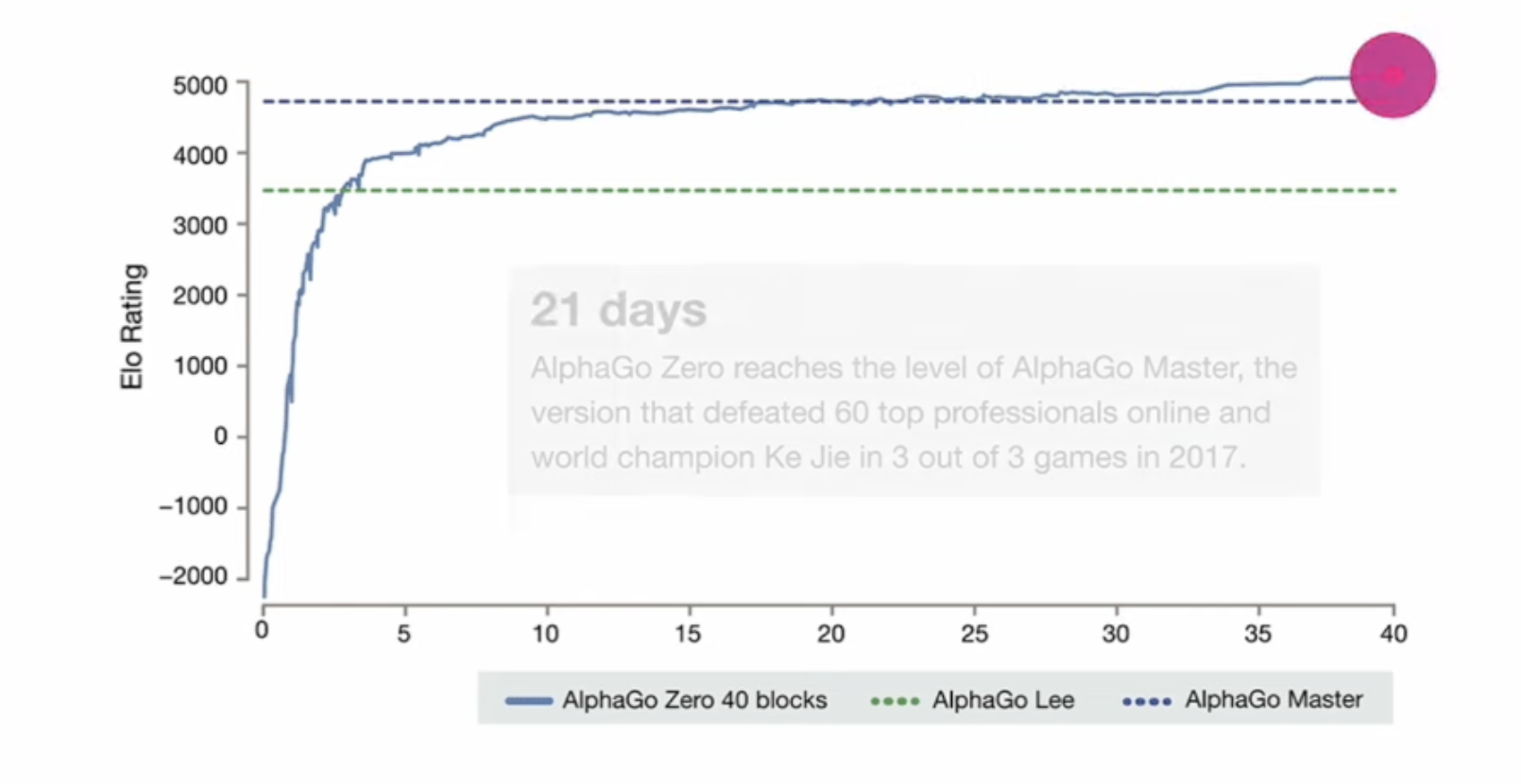
After removing the SL from step 1, DeepMind trained AlphaZero.
5 Book Recommend
What life should mean to you. On my to-do list now
