Deepseek R1 - GPT history
Continue with Deepseek R1 from EZ Encoder Link
0 Kimi K1.5
Flood Sung answered how K1.5 was trained on Zhihu, explained how they learned from OAI o1 to get Long Chain of Thoughts.
Both Noam and Richard emphasis on search, instead of any structured methods like MCTS. Don’t be limited by reward model in RL due to reward hacking limitatinos. So

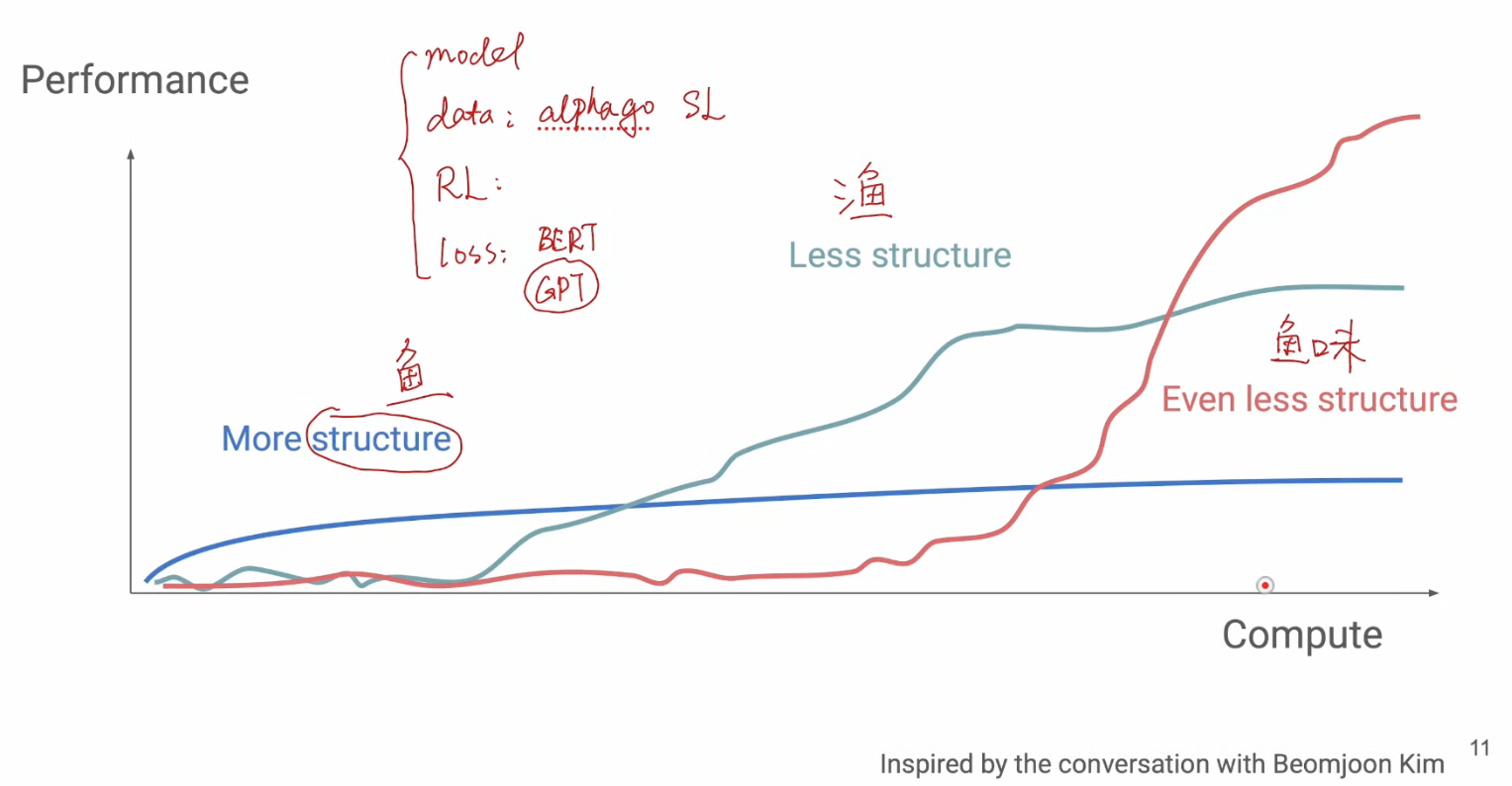
1 Inductive Bias
Both RNN and CNN has structured bias built in while Transformers doesn’t have it, using only attention and MLP
2 The Bitter Lesson
Richard Sutton proposed use general method, which is easy to scale up, to improve performance
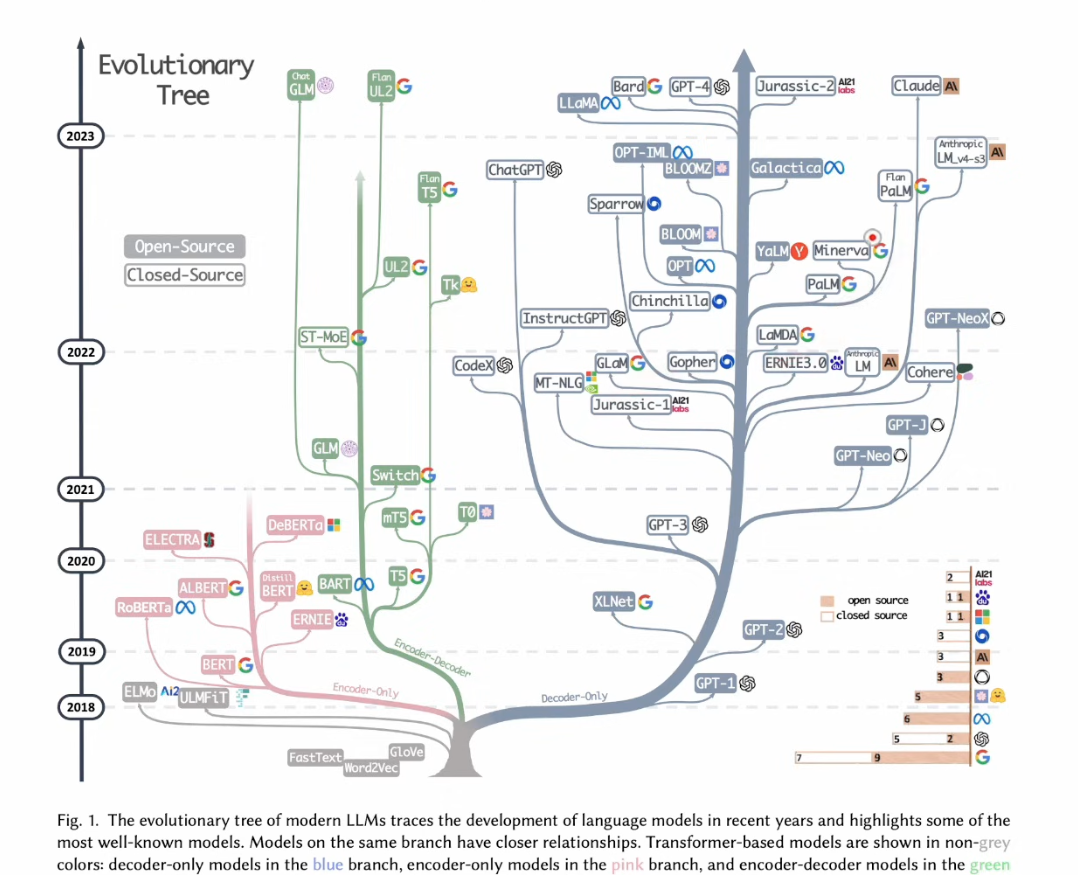
3 History
 Bert goes for traditional Encoder-Decoder pattern
Bert goes for traditional Encoder-Decoder pattern
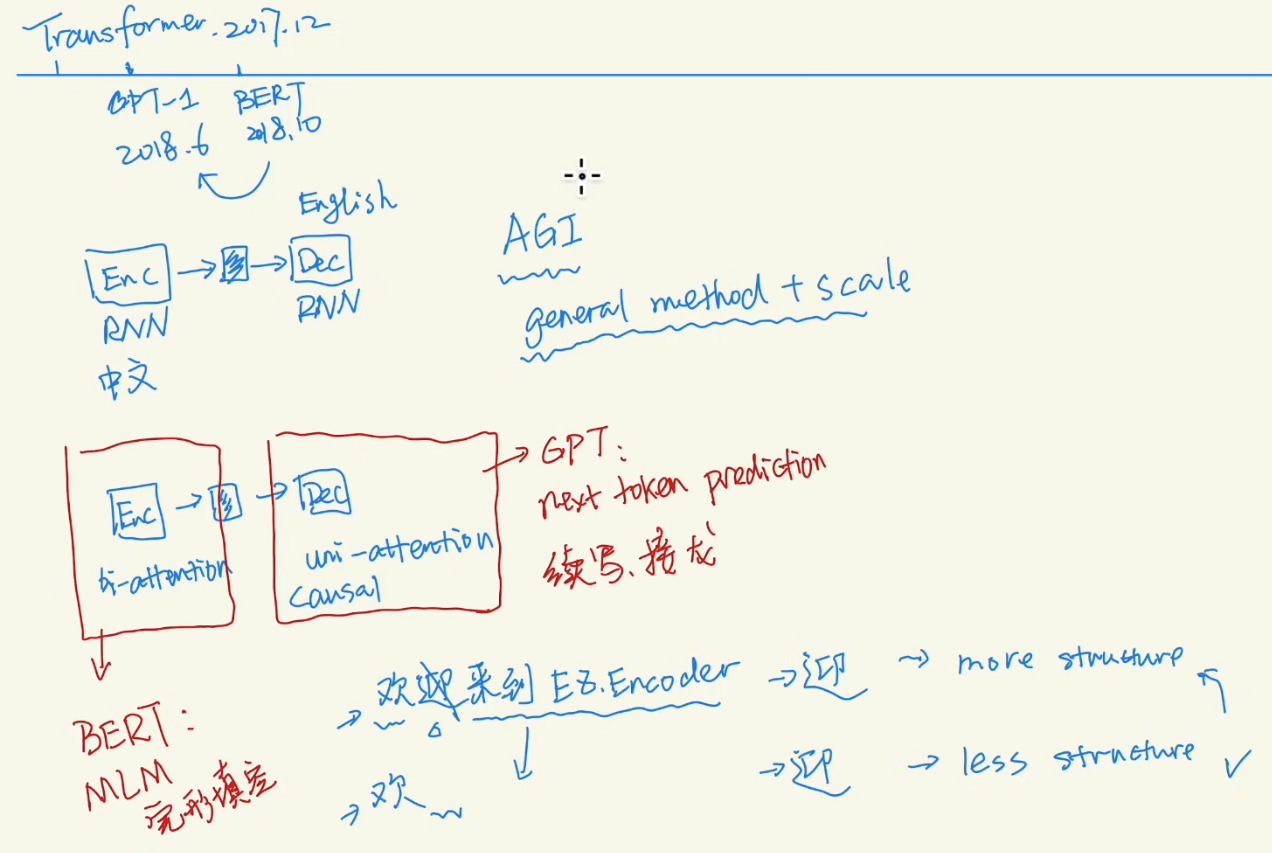
GPT-1 paper, Improving Language Understanding by GPT. Alec made historical move of applying transformer’s decoder.
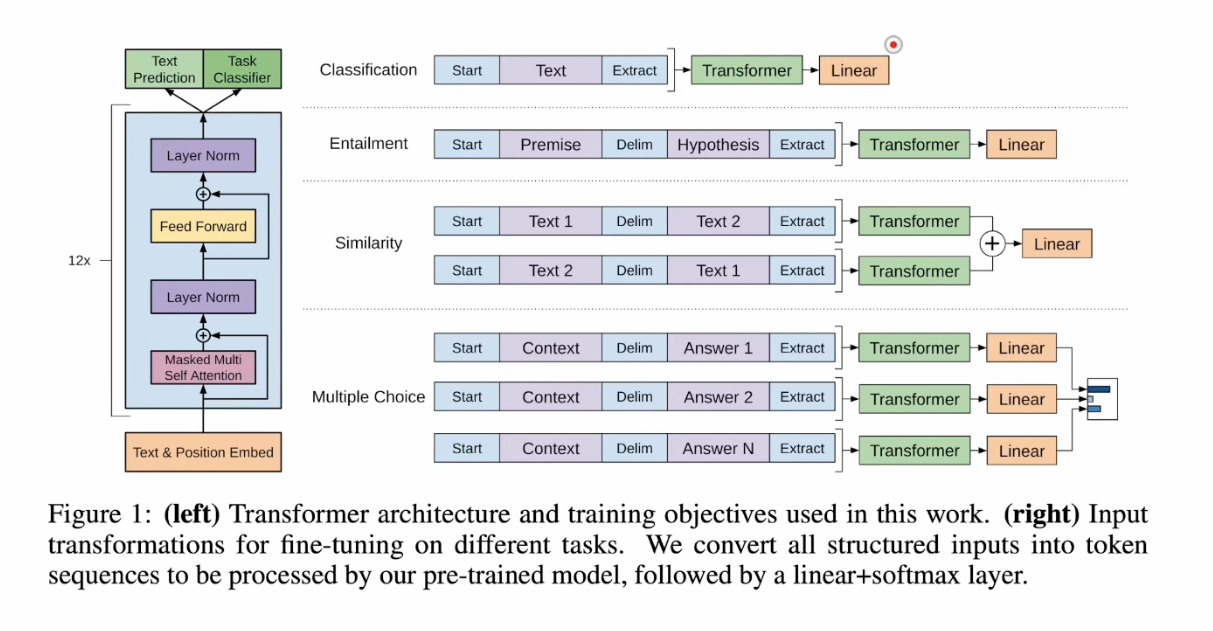 GPT-2 paper, Language Models are Unsupervised Multitask Learners. Use QA mode for all tasks, and see scaling law showing up.
GPT-2 paper, Language Models are Unsupervised Multitask Learners. Use QA mode for all tasks, and see scaling law showing up.
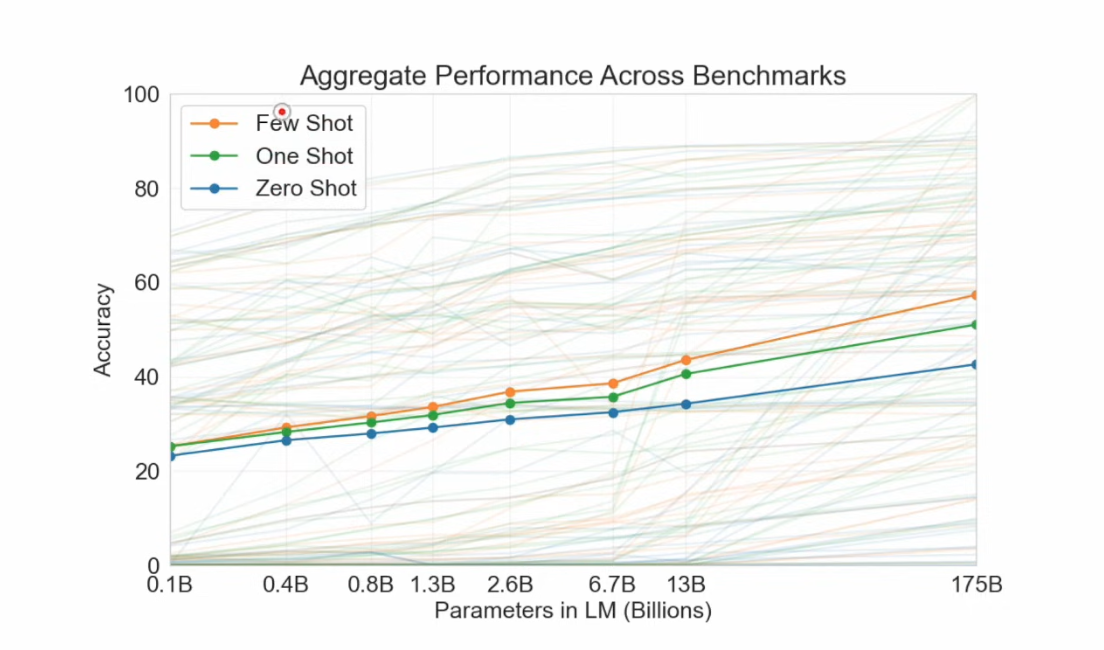
 GPT-3 paper, Language Models are Few-Shot Learners, even zero shot can see improvement from scaling law.
GPT-3 paper, Language Models are Few-Shot Learners, even zero shot can see improvement from scaling law.
 Google released their decoder only model, PaLM, with larger size. Similiar, Deepseek also incresae model sizes. Meta’s OPT-175B has many failes.
Google released their decoder only model, PaLM, with larger size. Similiar, Deepseek also incresae model sizes. Meta’s OPT-175B has many failes.

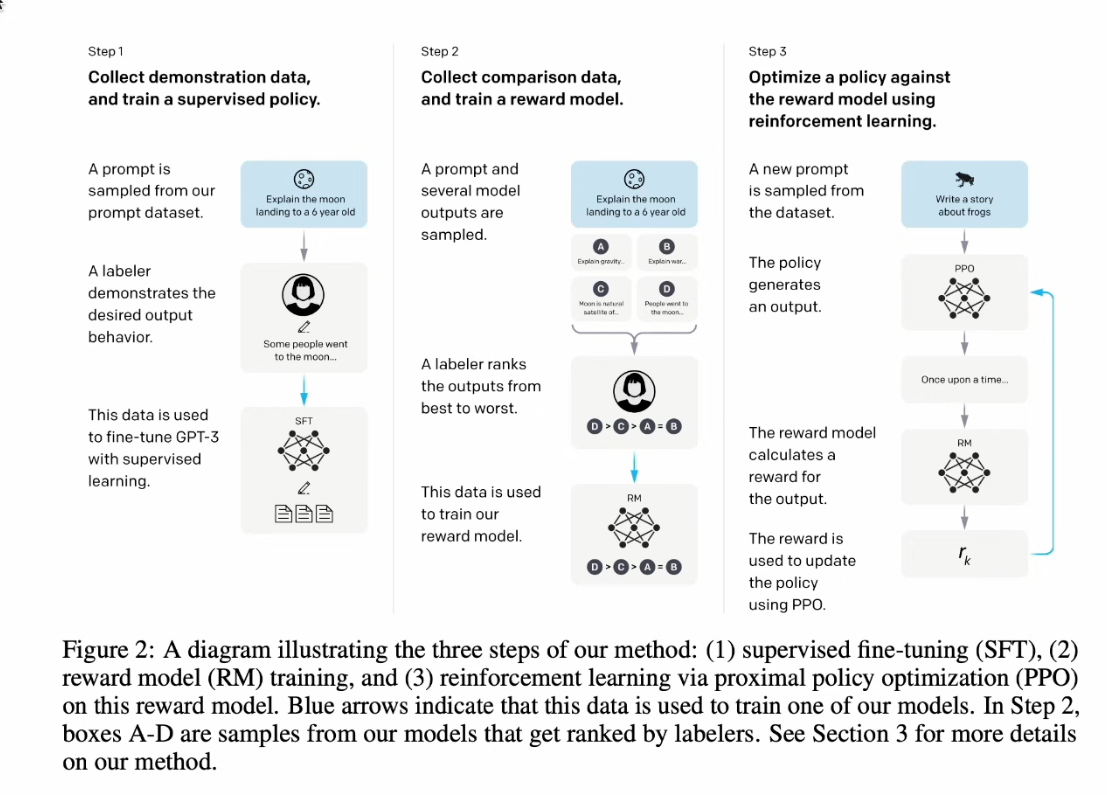
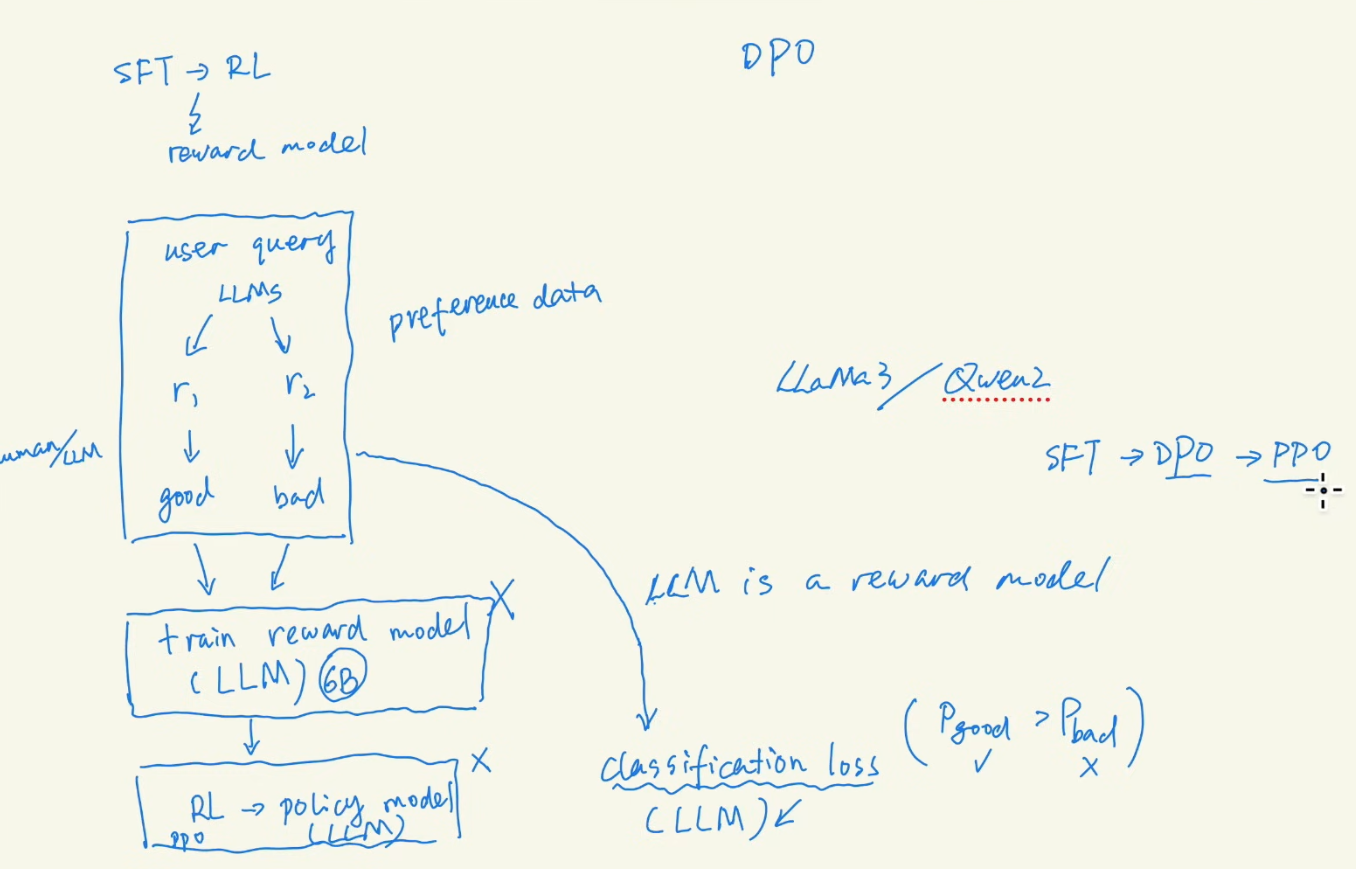
Instruct GPT paper, Training Language models to follow instructions with human feedback, critial RL during training: first SFT, then train a reward model, and RL through PPO.
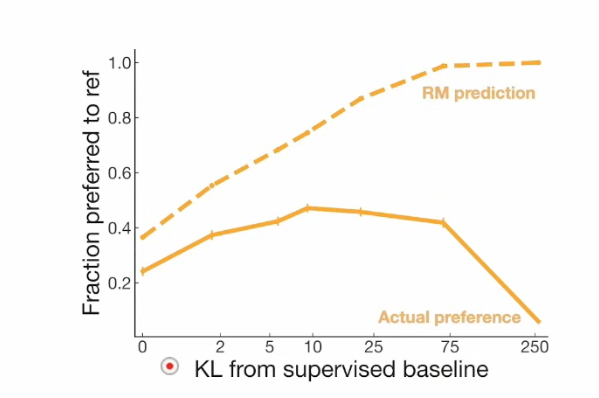
Reward hacking shows up when overoptimized. It’s summarized in OAI paper, Leraning to summarize from human feedback.
This is the overall paradim of LLM training from OAI

4 DPO
DPO, Direct Preference Optimization, your language model is Secretly a Reward Model, was using by Llama 3, so can skip the reward model training, and out of RL schema.
5 Emergency
Google published Emergent Abilities of LLM in 2022