Deepseek R1 - CoT
Continue with Deepseek R1 from EZ Encoder. Link
0 System 1 vs System 2
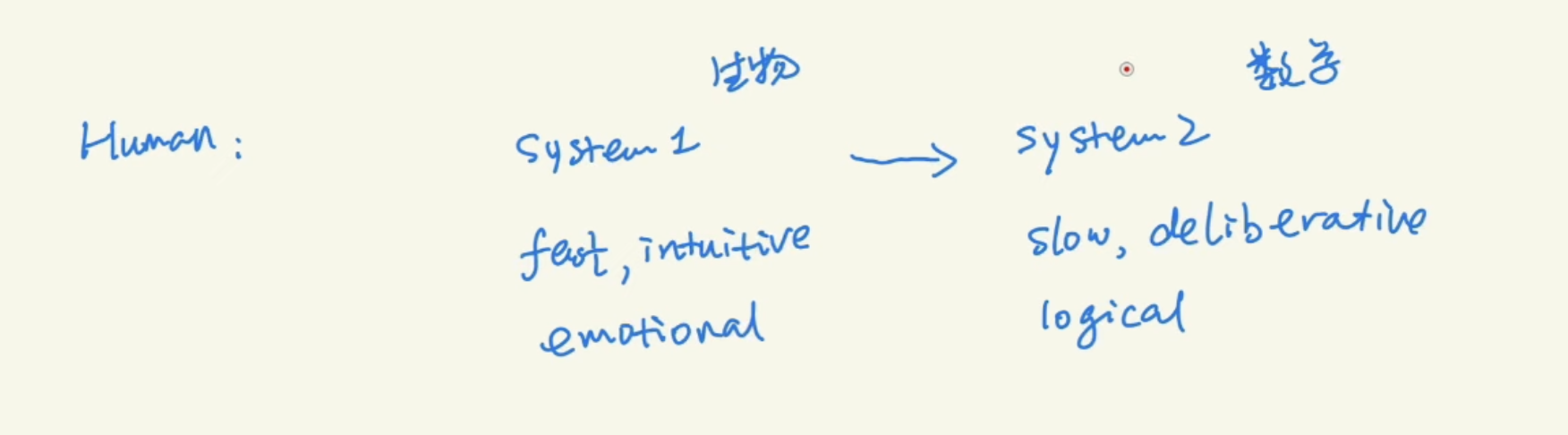 A 2025 paper uses this concept in LLM
A 2025 paper uses this concept in LLM
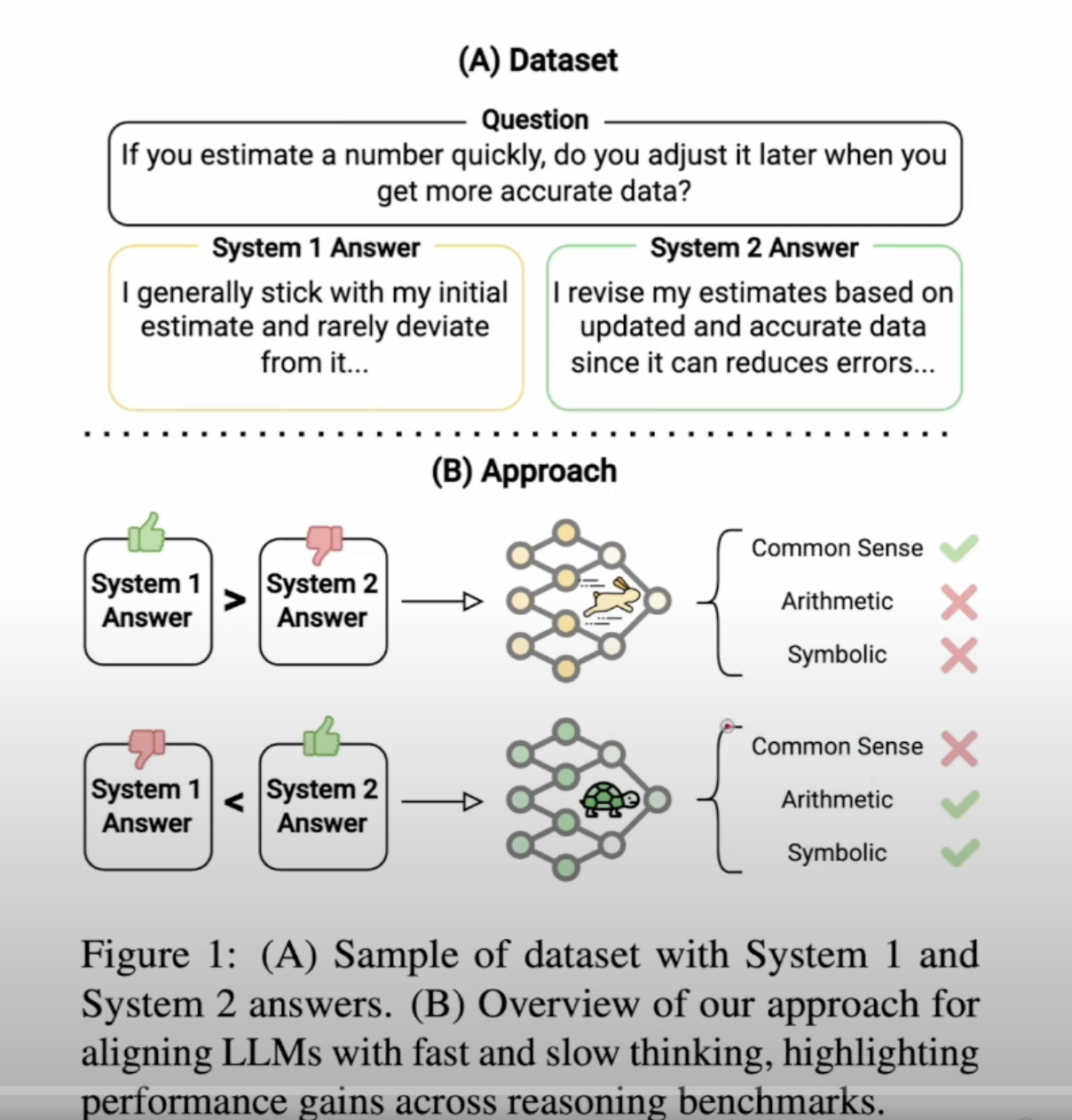
1 Chain of Thoughts
“CoT Prompting Elicits Reasoning
in Large Language Models” paper was published by Jason Wei from Google in 2022. Initial method is adding in context prompting.
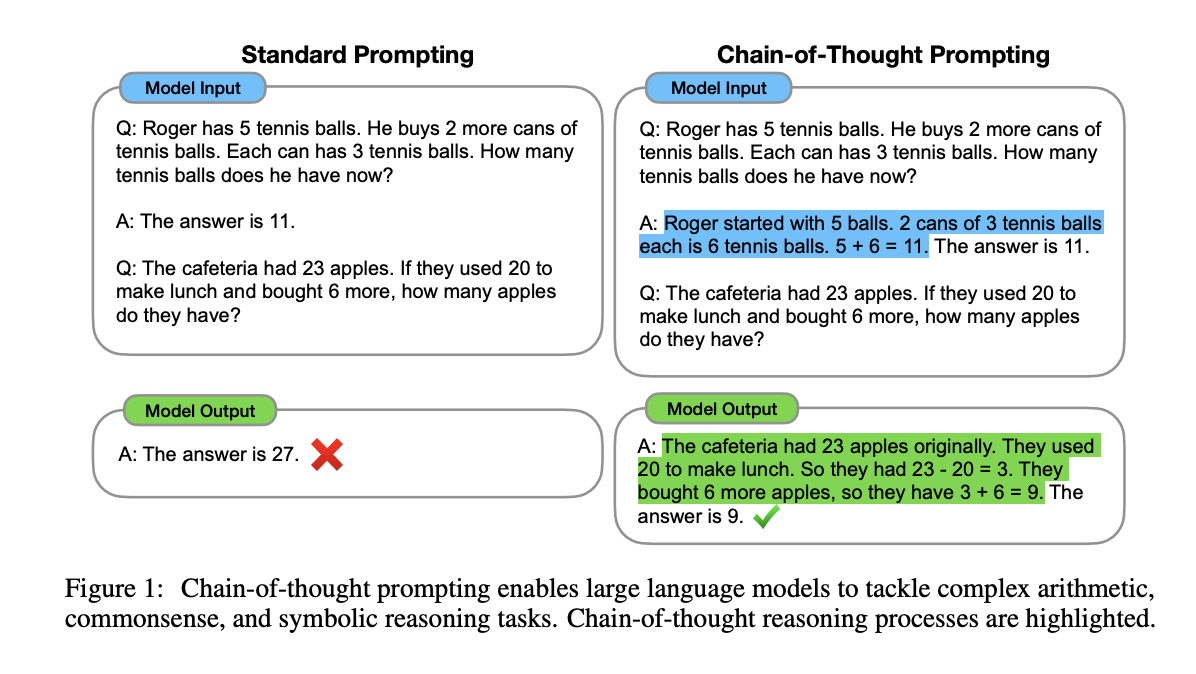
and “Large Language Models are Zero-Shot Reasoners” paper firstly introduced Let’s think step by step prompt.

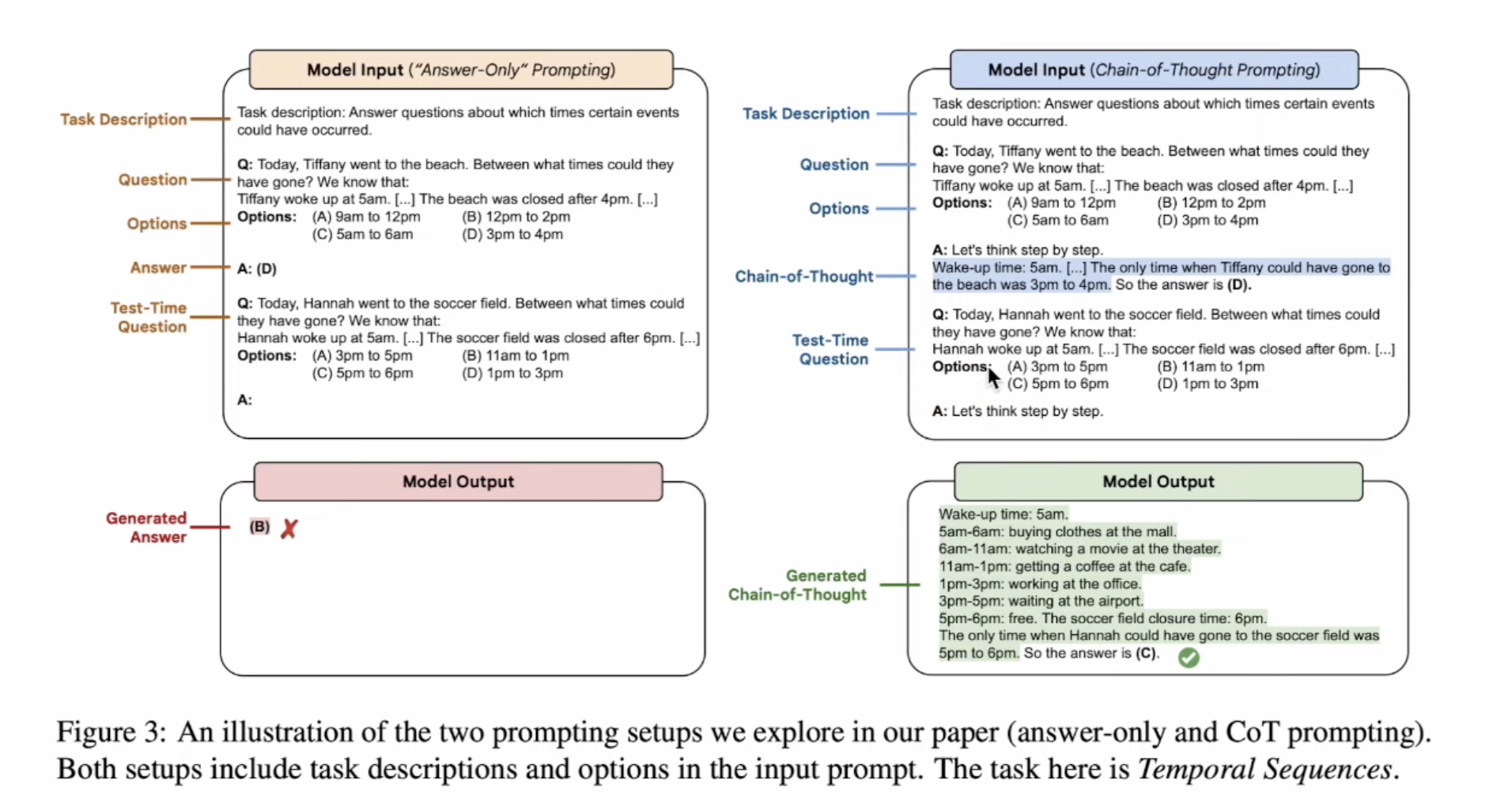
Combining these two methods,”Challenging BIG-Bench tasks and
whether chain-of-thought can solve them”paper tested on Big Bench-Challenage dataset.
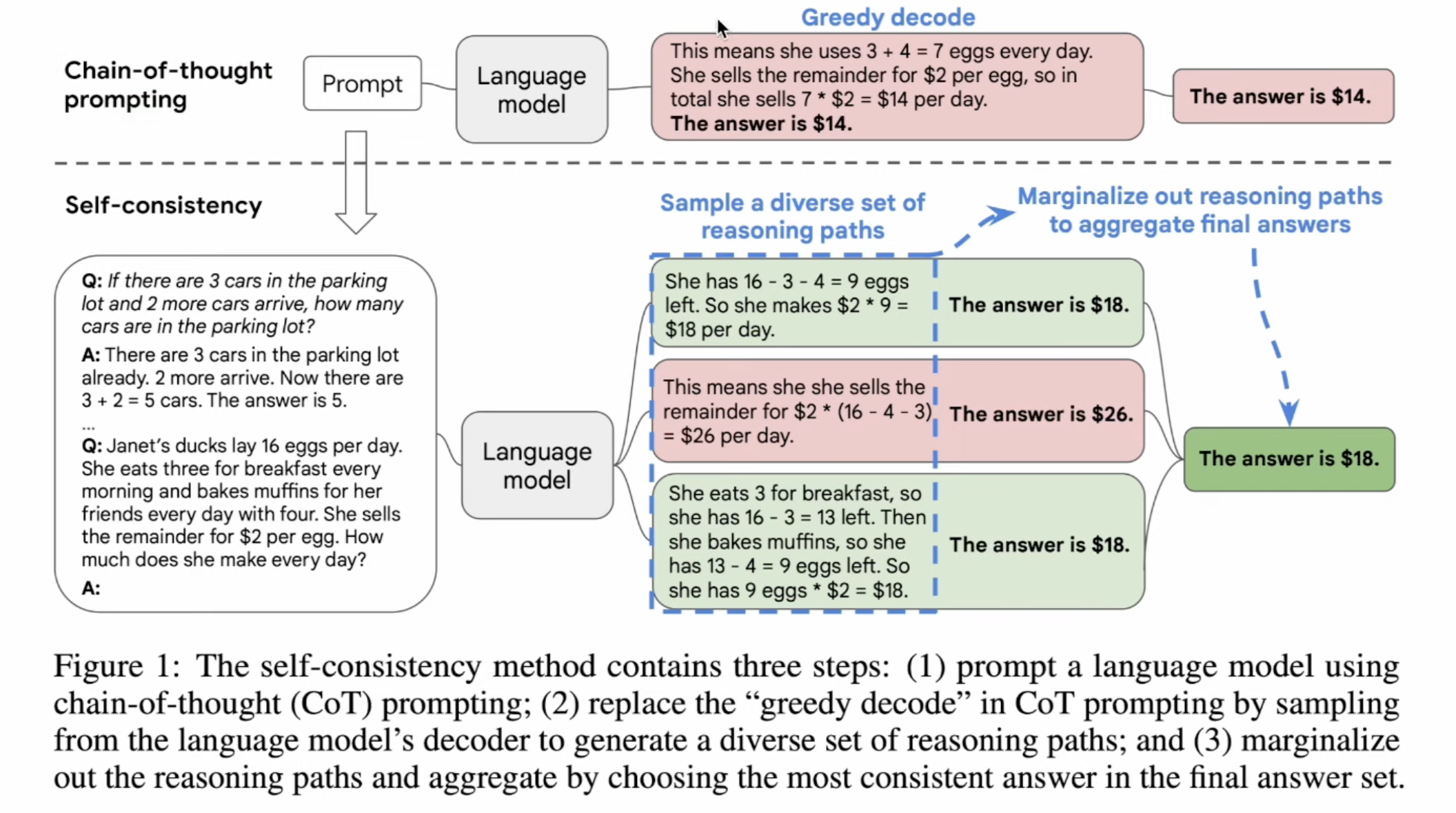
“SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT
REASONING IN LANGUAGE MODELS” paper uses LLM generate multiple answers, and use majority voting to get the correct answer.
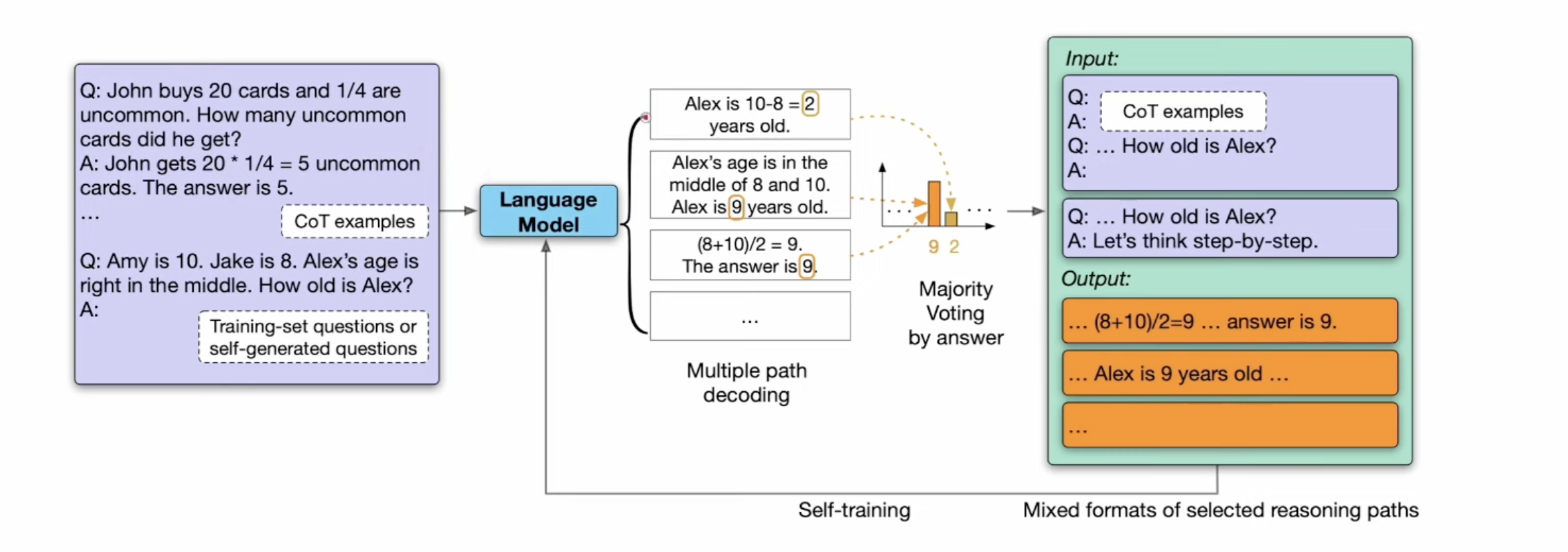
“LARGE LANGUAGE MODELS CAN SELF-IMPROVE” paper introduces training model in SFT step to get better CoT results. and model distillation for reasoning model can get good results as well.
Next step, is training in RL step from paper
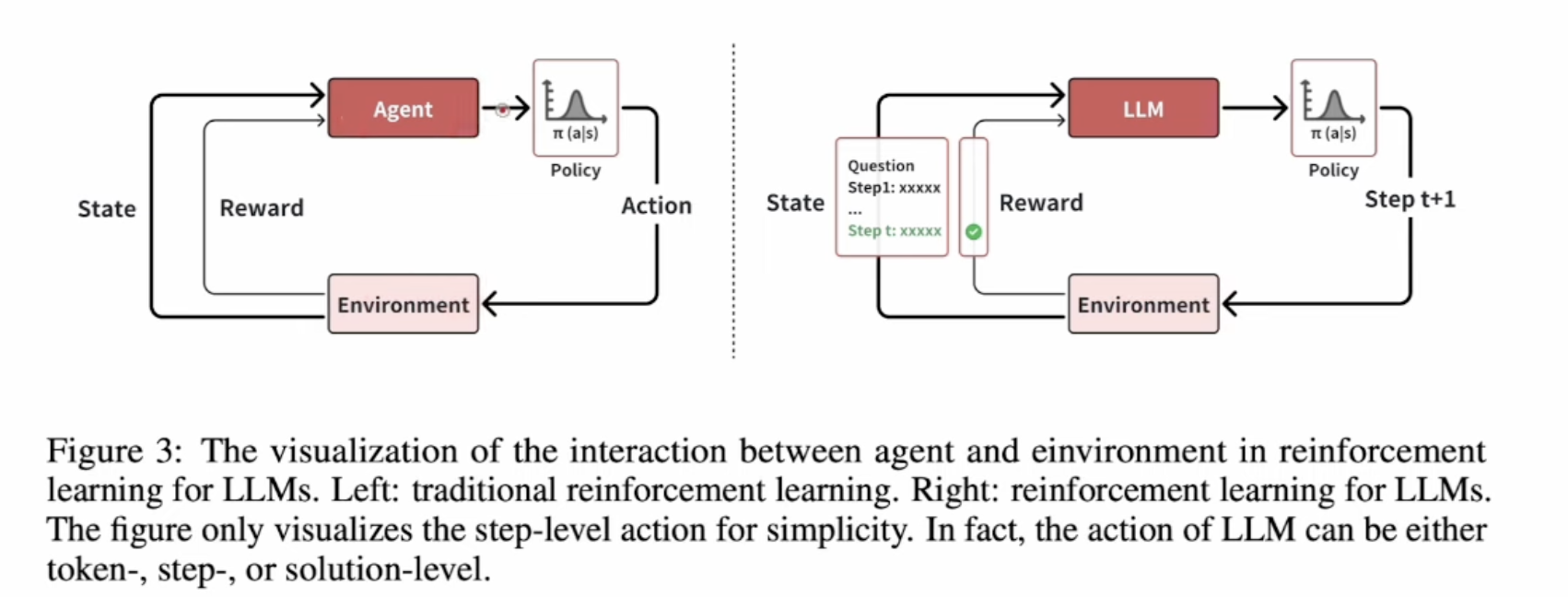
2 Outcome Reward Model vs Process Reward Model
ORM was outcome driven and PRM would check the reasoning step by step.
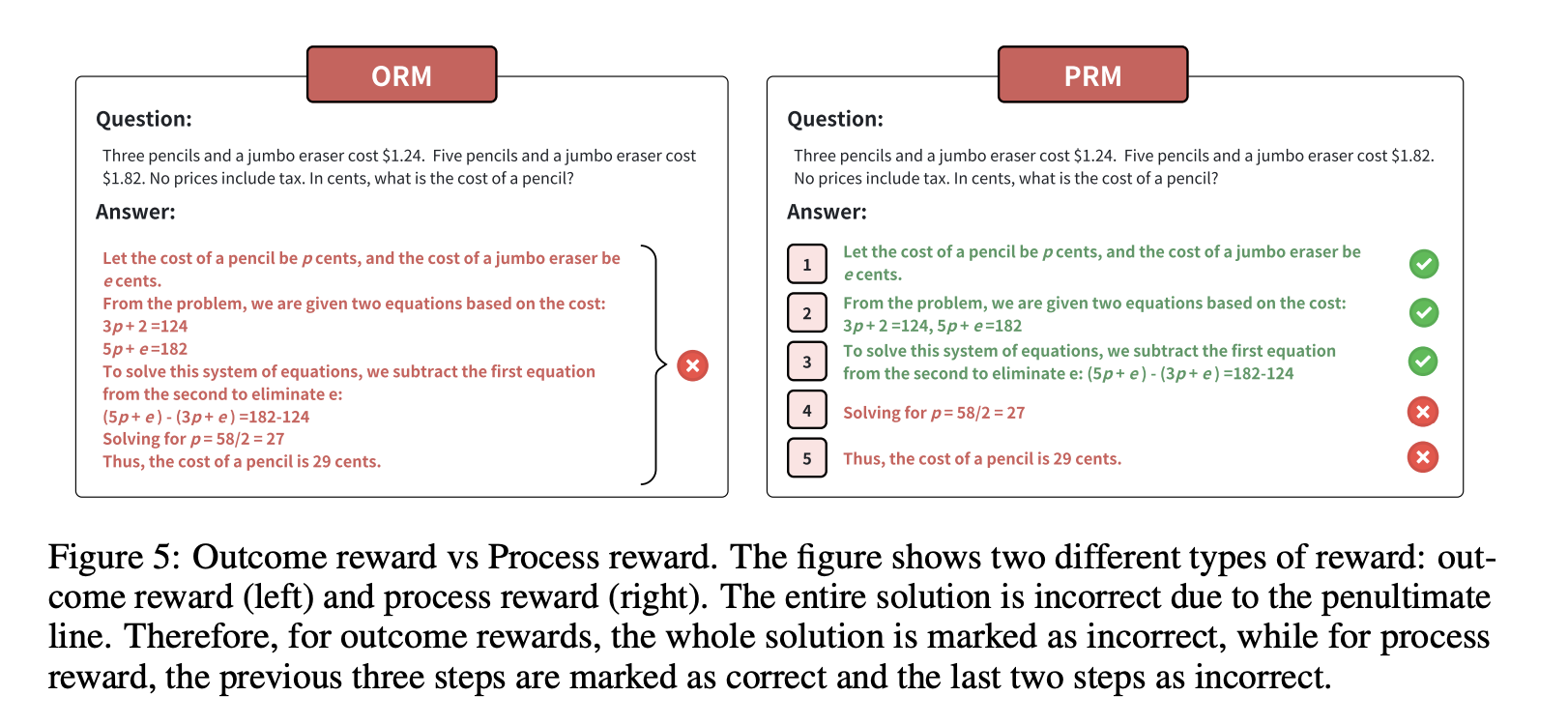
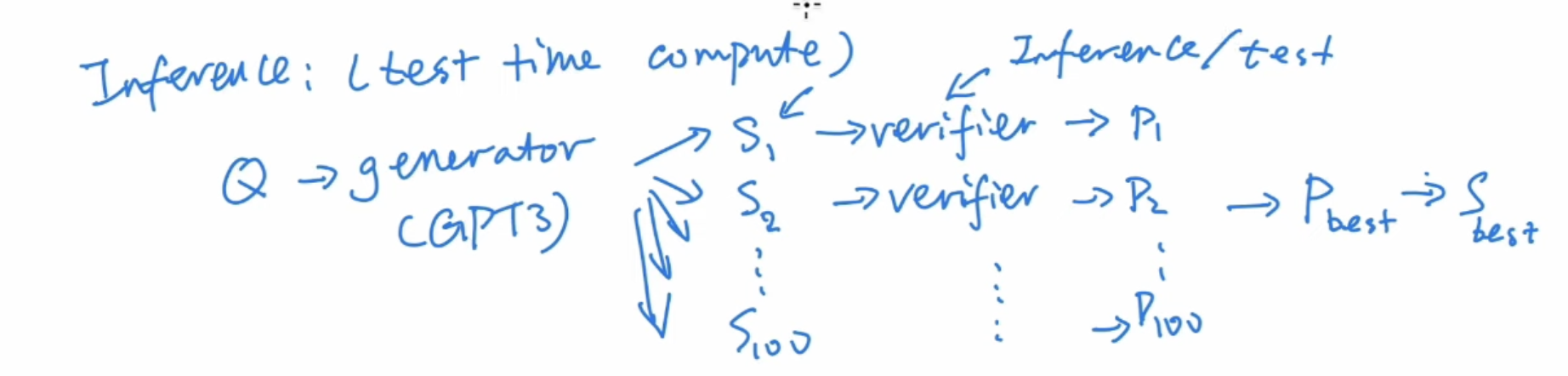
Reward model used in RL, can also be call verifier in the post-training. There are multiple methods to get results from verifier
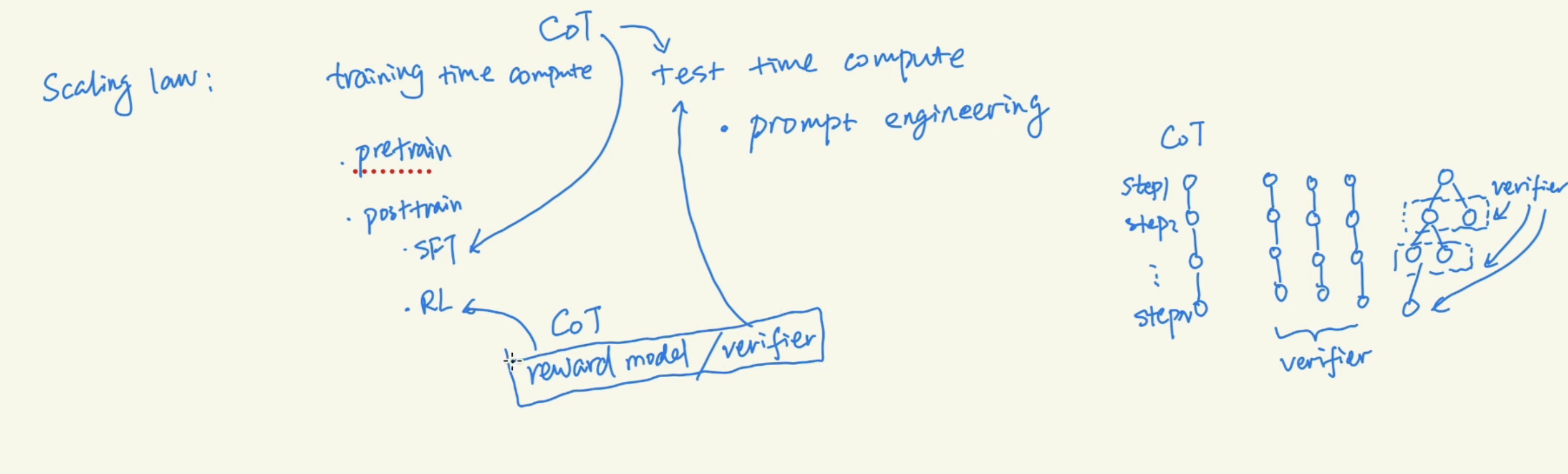
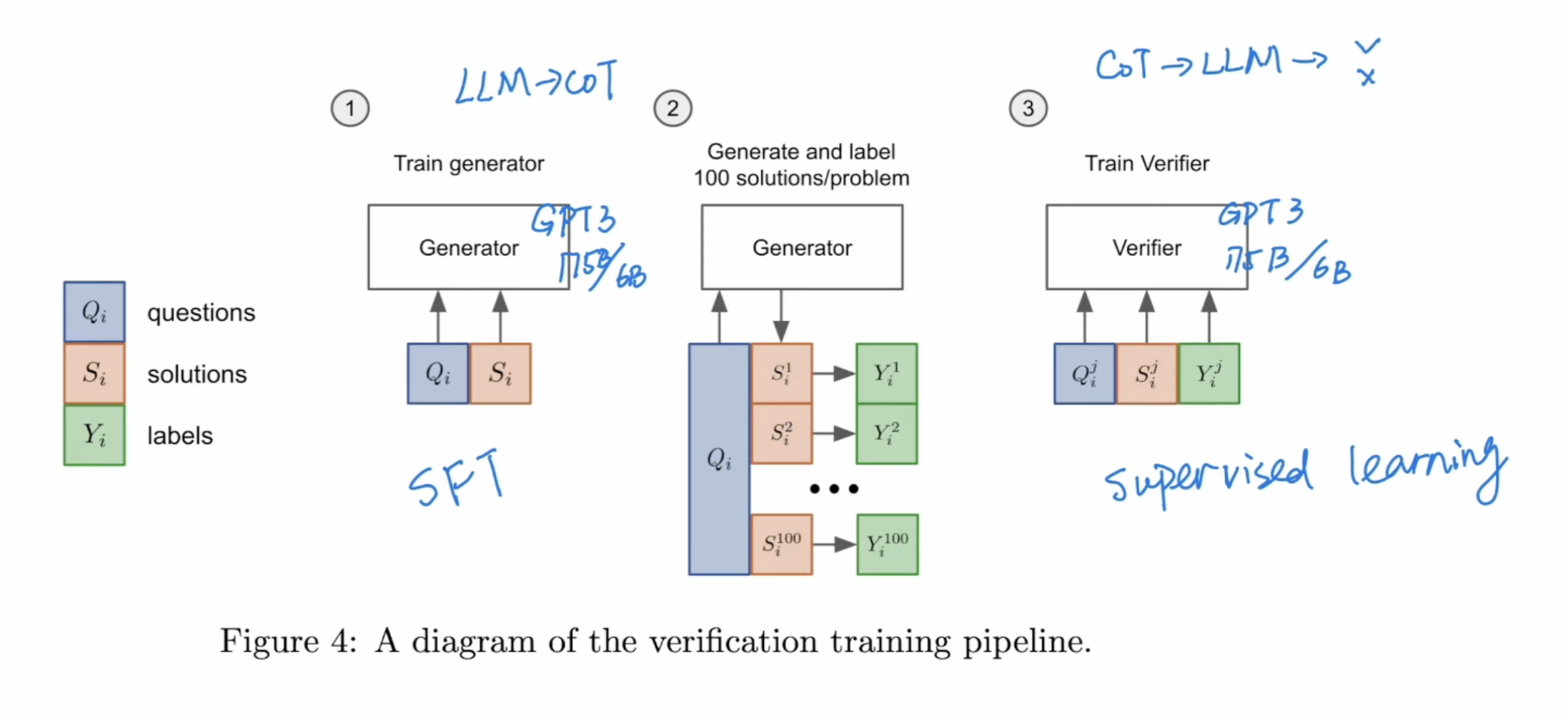
Three contribution to OAI’s paper on using CoT for math problems.

- GSM8K (Grade School Math) are element school level test datasets with human annotated CoT.
- Verifier training
- Test Time Compute
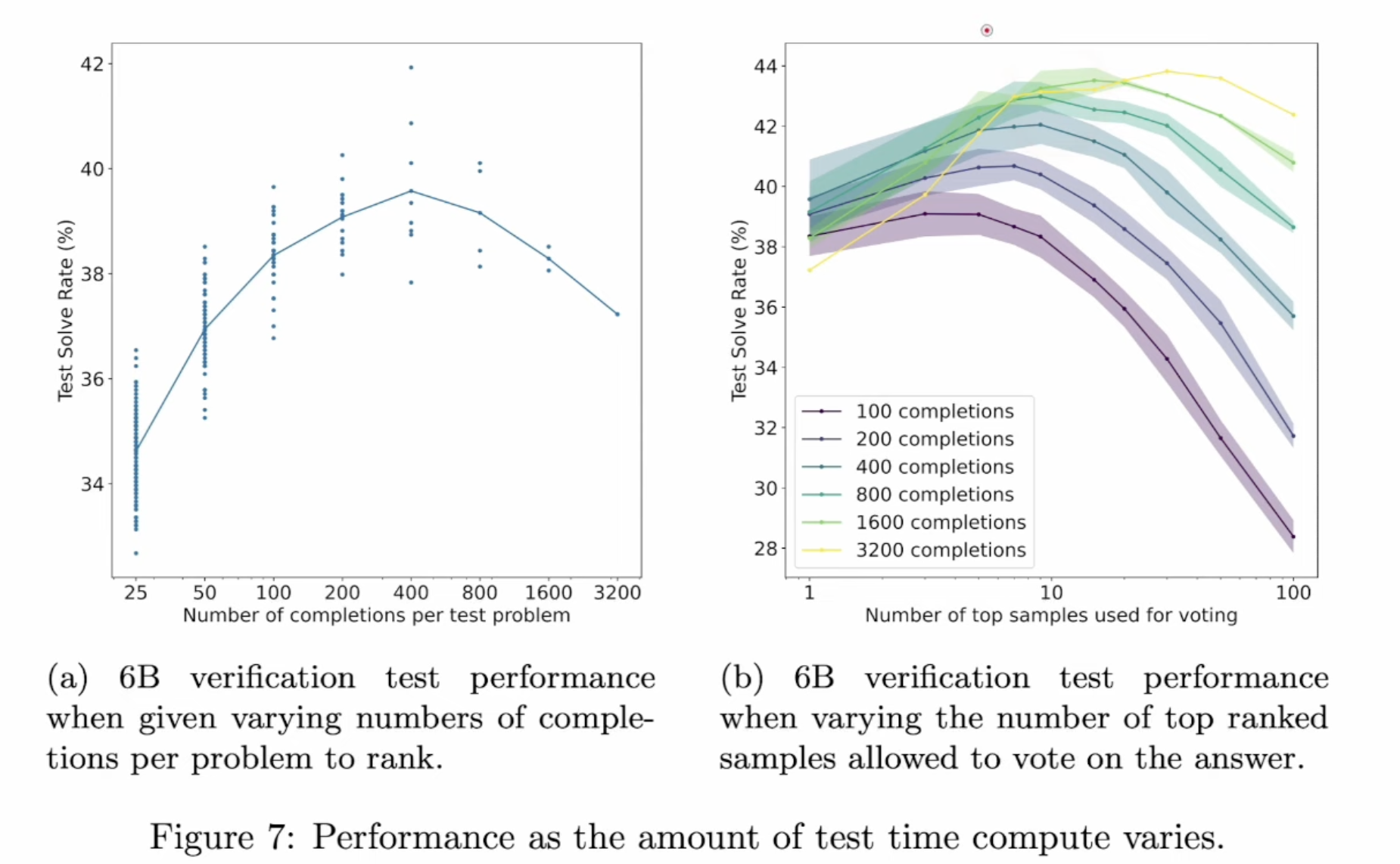
The quality goes down after verifier test more than 400 results, but we can combine majority voting to further boost the performance ( voting amount 10 results)
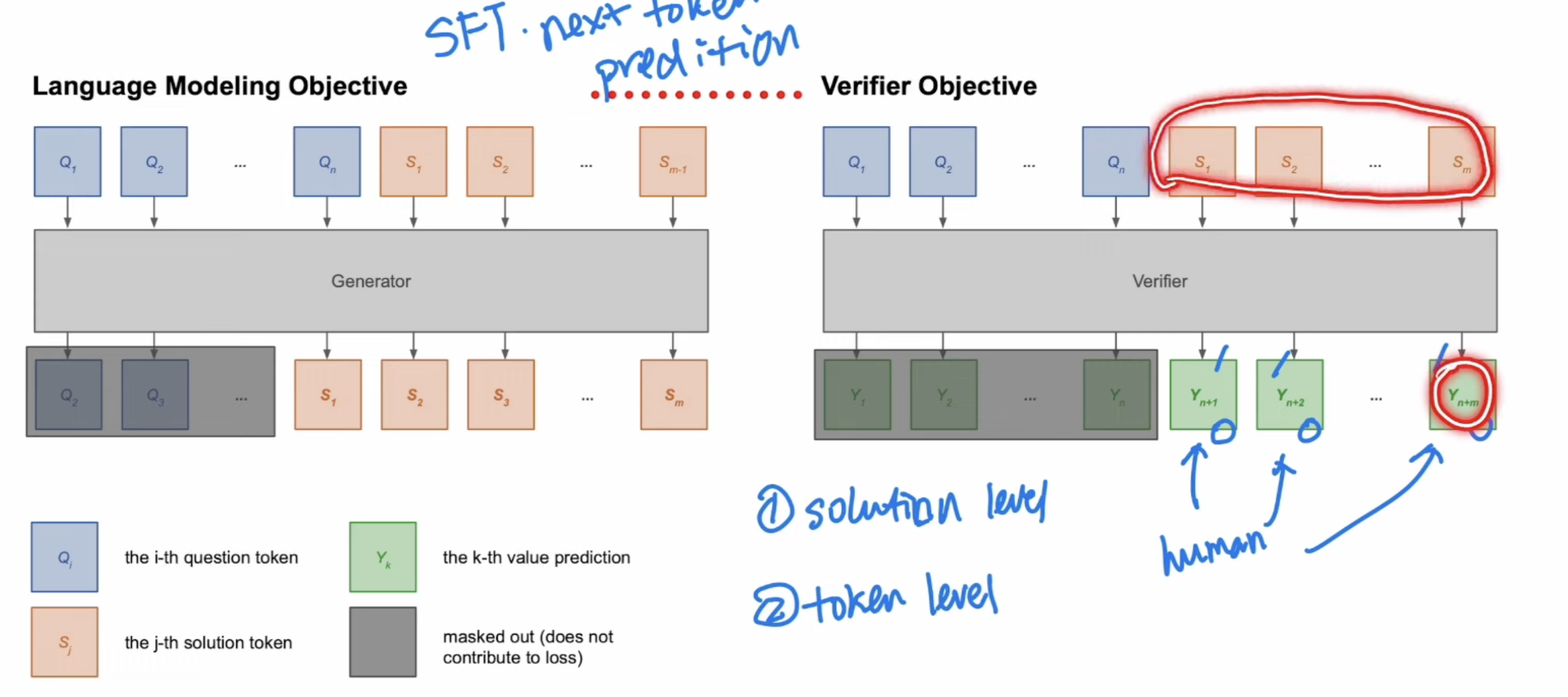
 Training the verifier can be at token level(use all token prediction) or solution level(Only use the last token). Token level can surpass solution level in the long run. Token level is similar to value functions, needs to tell the final results at early tokens. It has better results than solution level so widely used in OAI.
Training the verifier can be at token level(use all token prediction) or solution level(Only use the last token). Token level can surpass solution level in the long run. Token level is similar to value functions, needs to tell the final results at early tokens. It has better results than solution level so widely used in OAI.
The last technical paper from OAI, use PRM800K trained a PRW model. and use reward model Only as verifier. This paper shows PRM is better than ORW

Deepmind’s paper use reward model both for RL rewarding and as verifier. It shows similar performance of PRM and ORM, both are better than majority voting with 70B base model. Deepseek R1 actually shows otherwise, and simply use majority voting. It could be due to emergent ability with Deepseek’s 640B base model V3.

Main drawbacks of PRM is human annotation and this math shephard paper use LLM to auto annotation. The author was intern at Deepseek so this is very similar to Deepseek R1 approach.
