Deepseek R1 - Training
Continue with Deepseek R1 from EZ Encoder. Link
0 Overview
R1 overview. The great achievment of R1 is making many previous ideas really work in LLM

1 RL without SFT
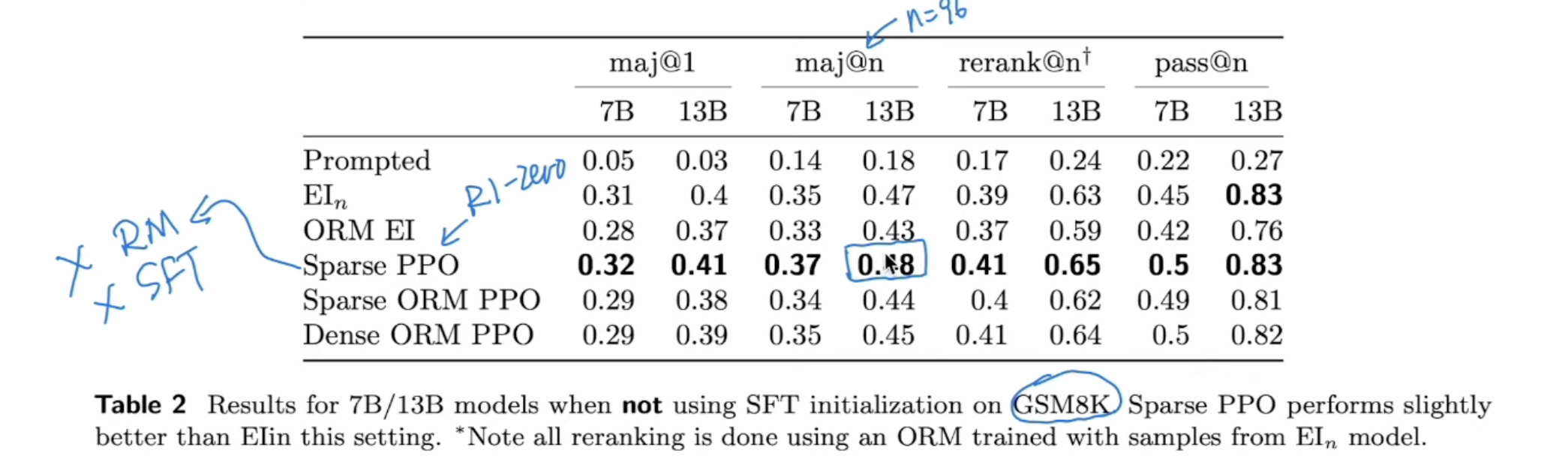
Teaching Large Language Models to Reason with Reinforcement Learning evaluate different RL methods for reasoning model, and tried RL without Reward Model, without SFT initialization.
The result was relatively good, but nothing compared to R1 due to model size is very small 13B. (Sparse is result-only RM, and dense is process RM)
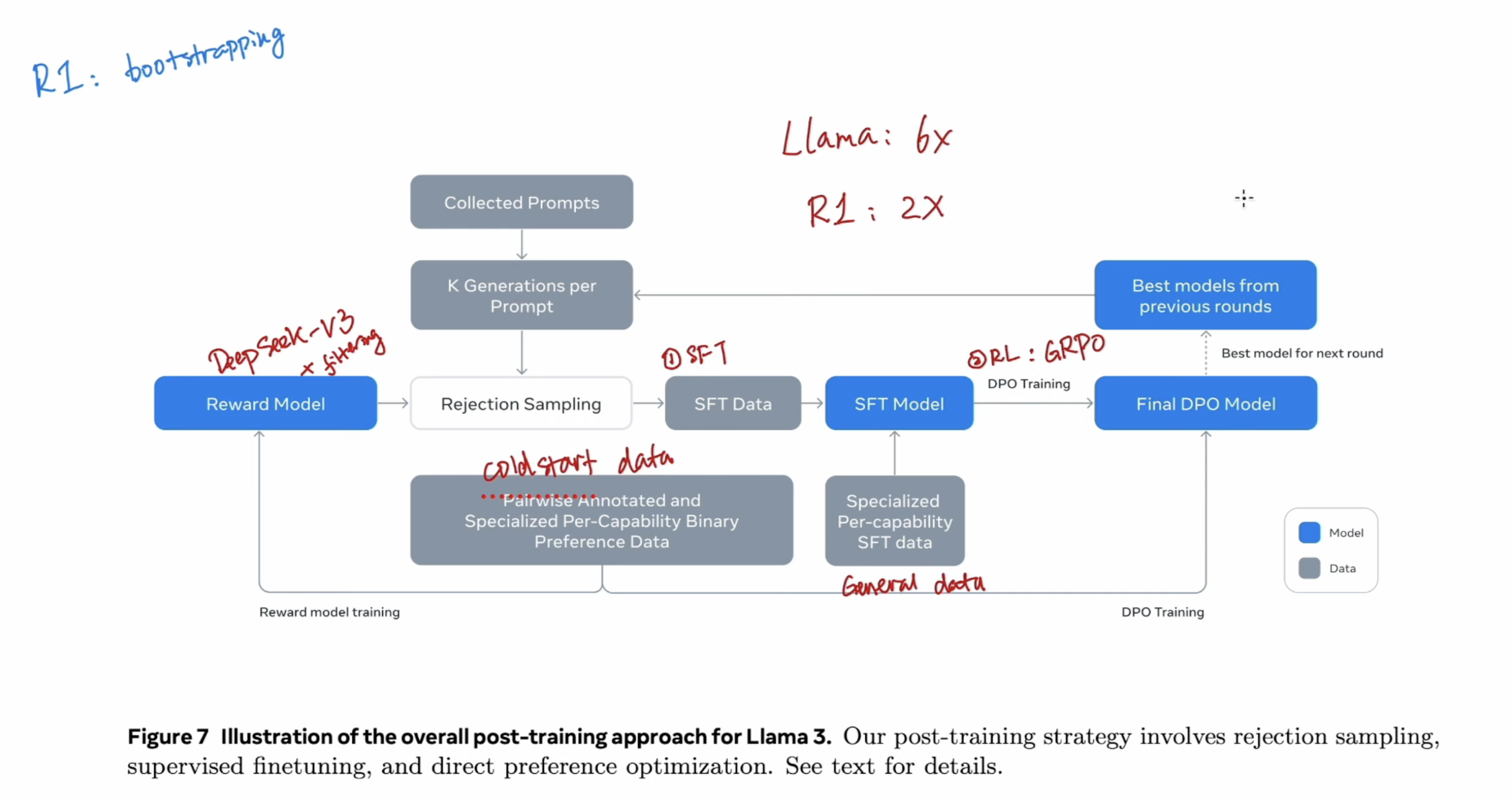
2 Training paradiam
The training paradiam is similiar to Llama 3, using Deepseek V3 as the reward model to clean reasoning data – Rejection Sampling
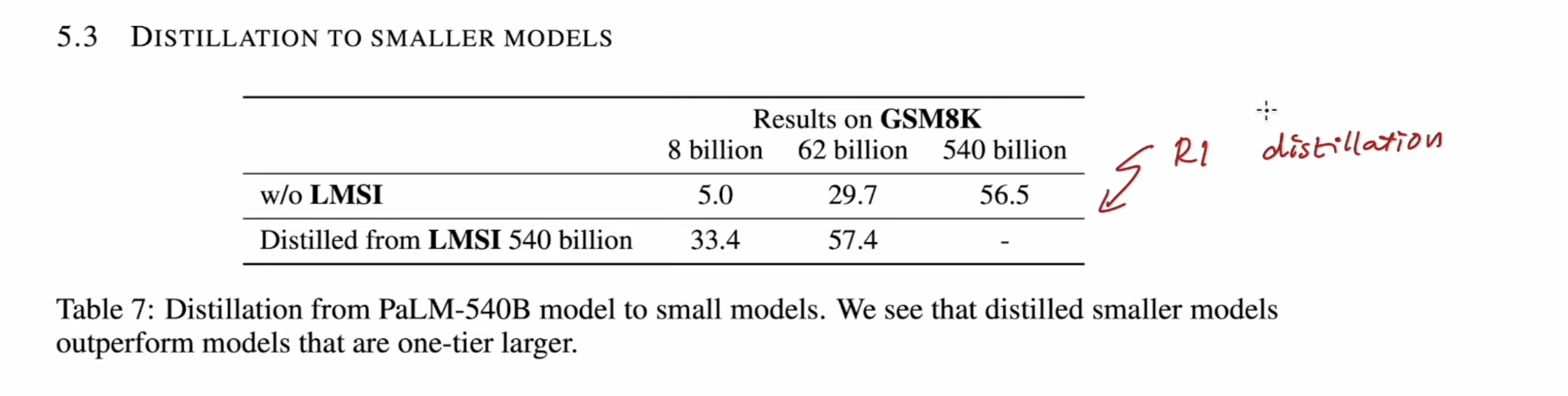
3 Distillation
LLM can self improve paper compared model distillation to a smaller model.
4 R1 Training
The RW in R1 is rule based, focusing on accuracy and formatting.
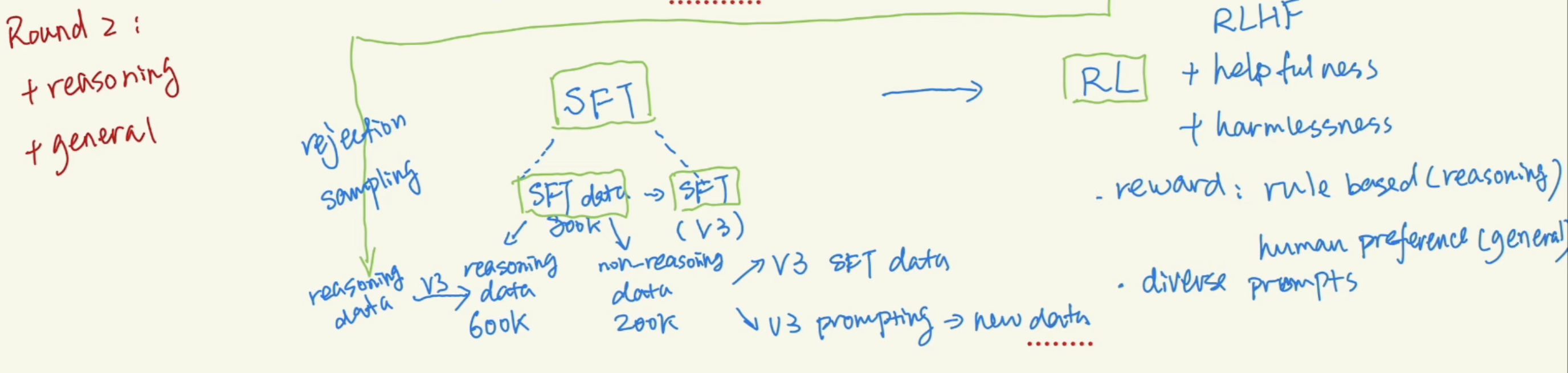
 There are 2 rounds of training for R1. Round 1 focusing in reasoning,
There are 2 rounds of training for R1. Round 1 focusing in reasoning,
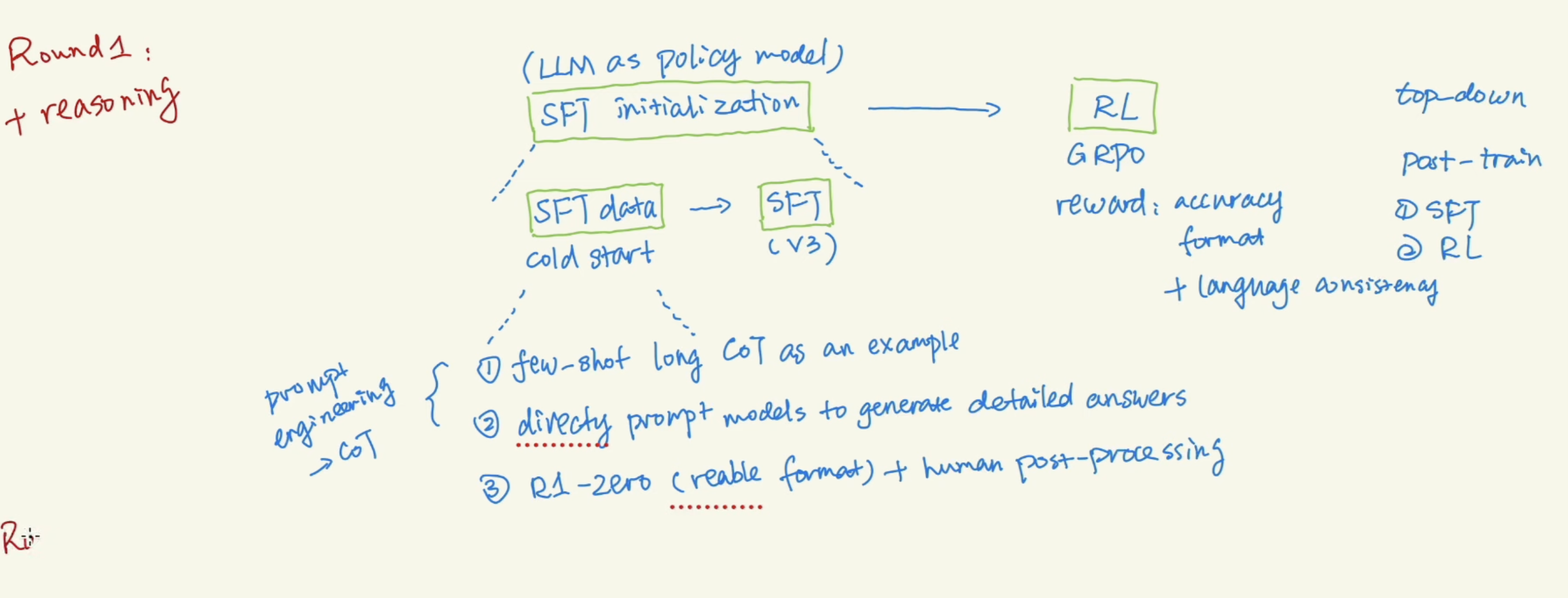 Round 2 is adding on general capability. Use model trained in round 1 to generate reasoning data, and rejection sampling by V3. Have 800K of training data in total.
Round 2 is adding on general capability. Use model trained in round 1 to generate reasoning data, and rejection sampling by V3. Have 800K of training data in total.
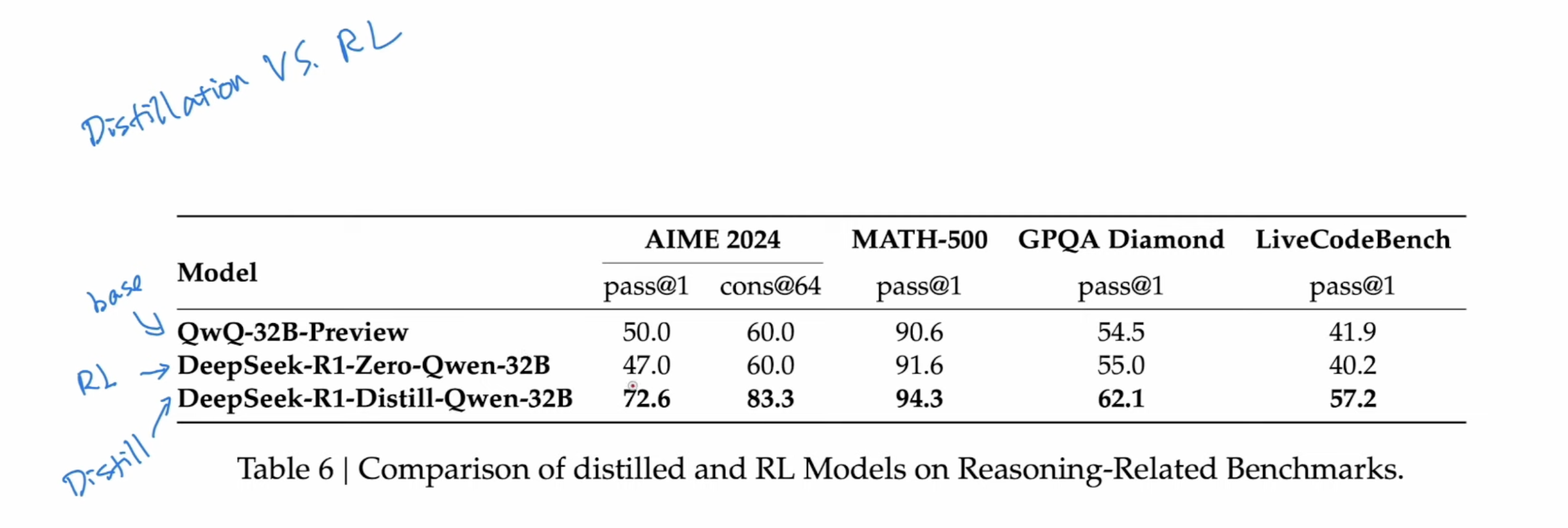
 QwQ 32B preview was used in the paper to compared with RL and distillation methods
QwQ 32B preview was used in the paper to compared with RL and distillation methods
Two failed attempts
- PRW may lead to reward hacking
- MCTS is not practical here due to large search space.
5 Followup works
- s1: Simple test-time scaling thinks 600K data is too much, and 1K is enough. Used s1k dataset to generate reasonable good results.
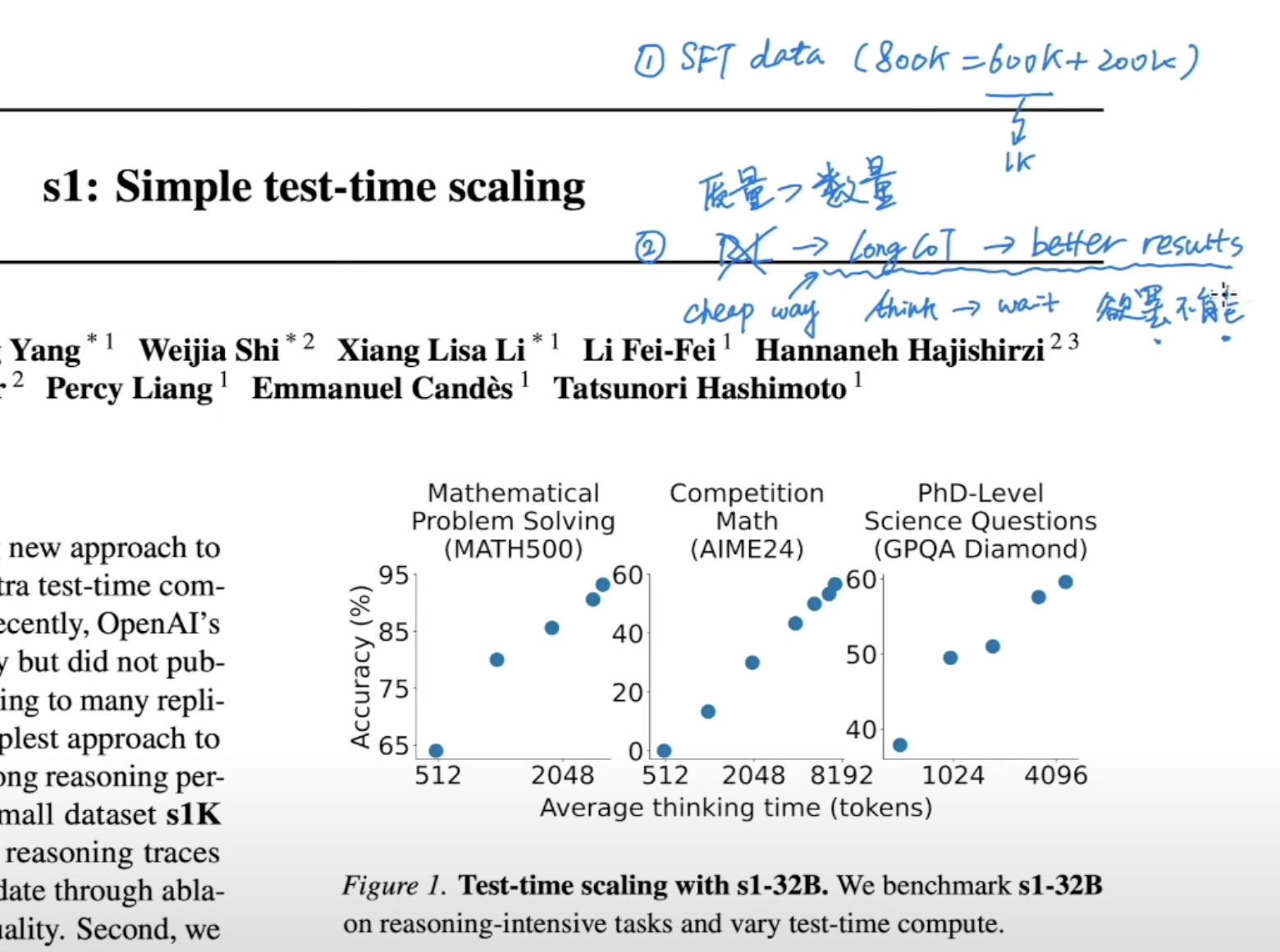 Also used “wait” replace “</think>” to generate long CoT as budget forcing, which is referred as sequential scaling. The parallel scaling is majority voting.
Also used “wait” replace “</think>” to generate long CoT as budget forcing, which is referred as sequential scaling. The parallel scaling is majority voting.

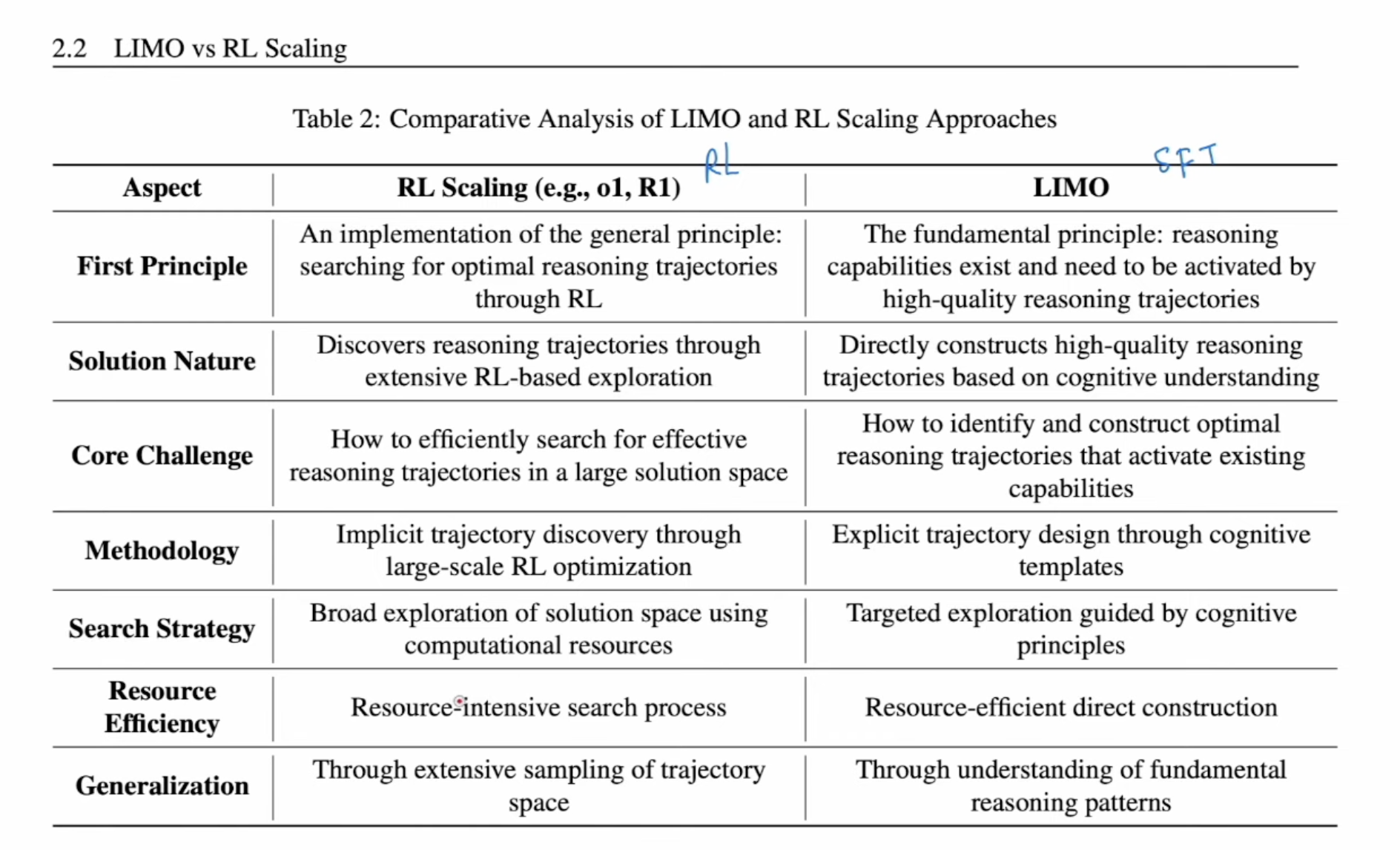
- LIMO: Less is More for Reasoning only used 871 samples as “cognitive template” to post-train model.
- Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
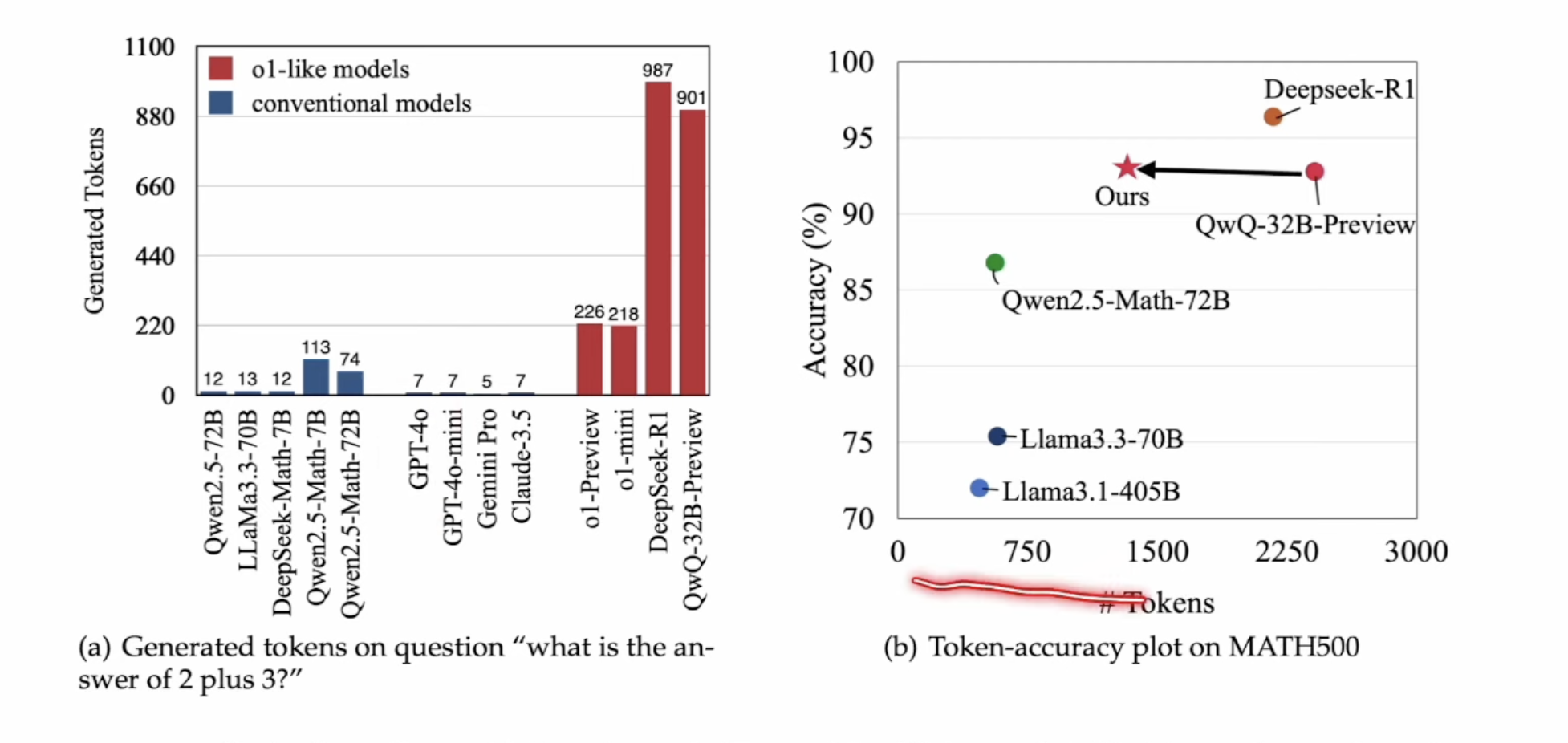 Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs penalize LLM generating “Alternatively”, which is generated at the beginning of a throught, which is thinking too short to get the correct answer.
Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs penalize LLM generating “Alternatively”, which is generated at the beginning of a throught, which is thinking too short to get the correct answer.
