Deepseek V3 - MLA
Let’s summarize the learning of deepseek V3 from recent weeks
0 Testing datasets
- MMLU-Pro: Univ of Waterloo’s Multi-Task Language Understanding Benchmark, enhaunced and released in 2024.12,000 Qs
- GPQAGraduate-Level Google-Proof Q&A Benchmark. 448 Qs
- Math-500 OpenAI’s Math test sets.
- CodeForces Coding competition website
- SWE-Bench OpenAI’s coding datasets from Github issues
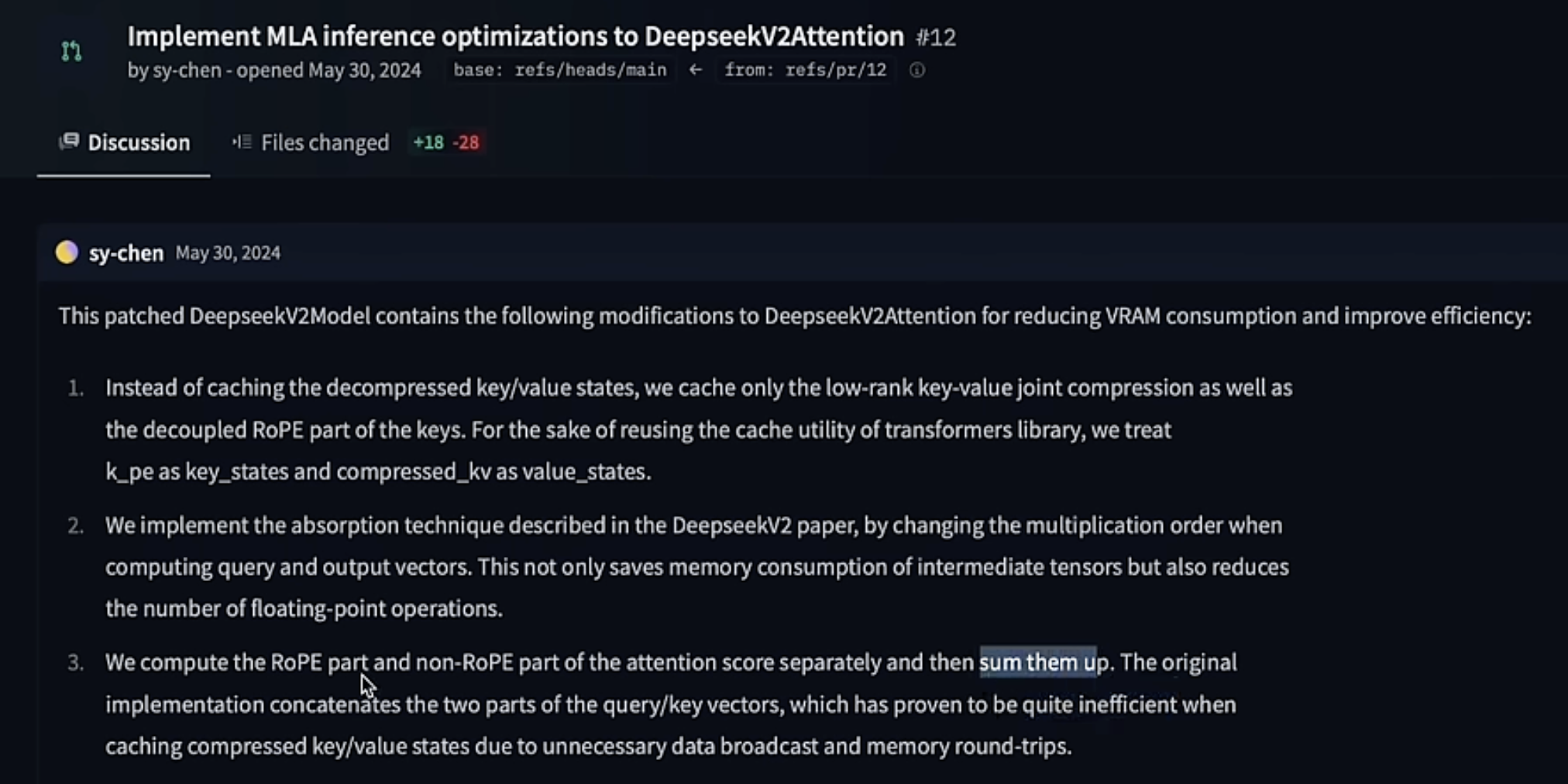
1 Multi-Head Latent Attention
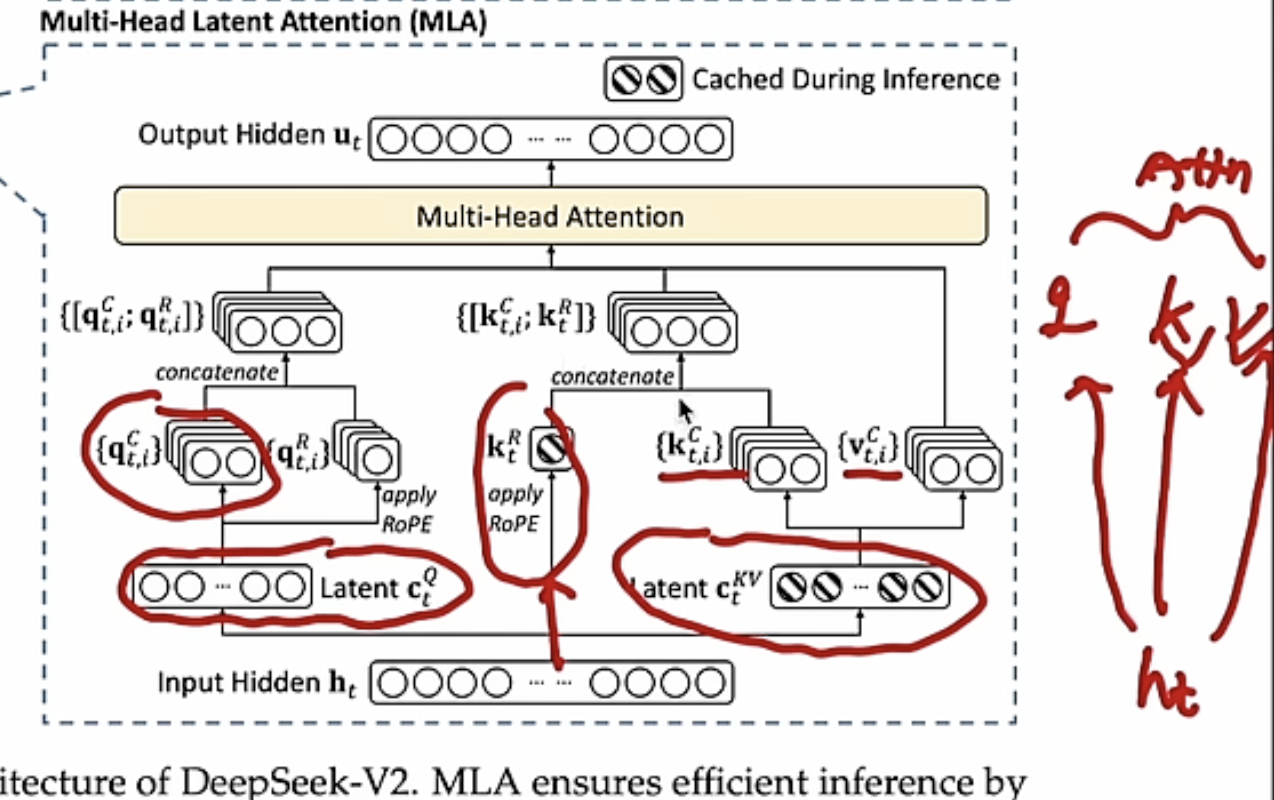
MLA was introduced in Deepseek V2 paper, and it’s Low Rank Decomposition for KV cache.
 You can directly calculate attention from the latent vector C, without restore it back to K/V. That’s the because the upscale matrix $W^{uk}$ can be absorbed into the weight matrix $W^q$
You can directly calculate attention from the latent vector C, without restore it back to K/V. That’s the because the upscale matrix $W^{uk}$ can be absorbed into the weight matrix $W^q$
 Query was also low-rank decomposed to save memory
Query was also low-rank decomposed to save memory

3 Rotary Position Embedding
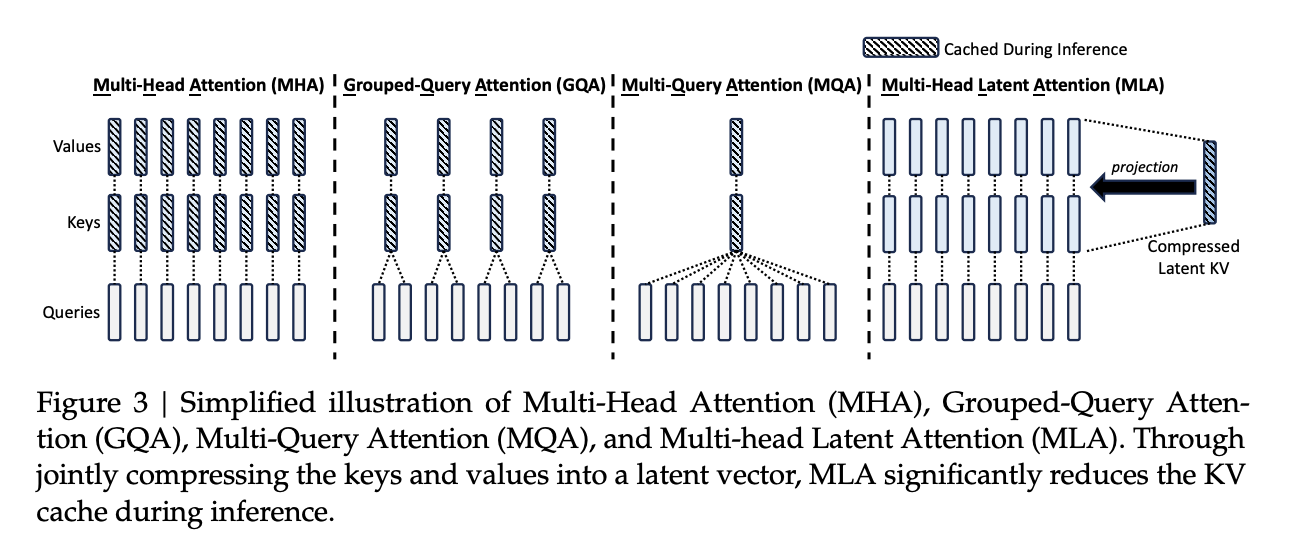
Two major branches of PE, absolute and relative.
The absolute PE, pro is simple to implement, con is that if the training is short, then the LM can NOT know long position, weak in extensability
 RoPE is combining both absolute and relative PE. The left figure is the one without PE, middle is adding absolution PE, which can change the vector length. RoPE is designed to maintain vector length, and only applied to Q/K
RoPE is combining both absolute and relative PE. The left figure is the one without PE, middle is adding absolution PE, which can change the vector length. RoPE is designed to maintain vector length, and only applied to Q/K
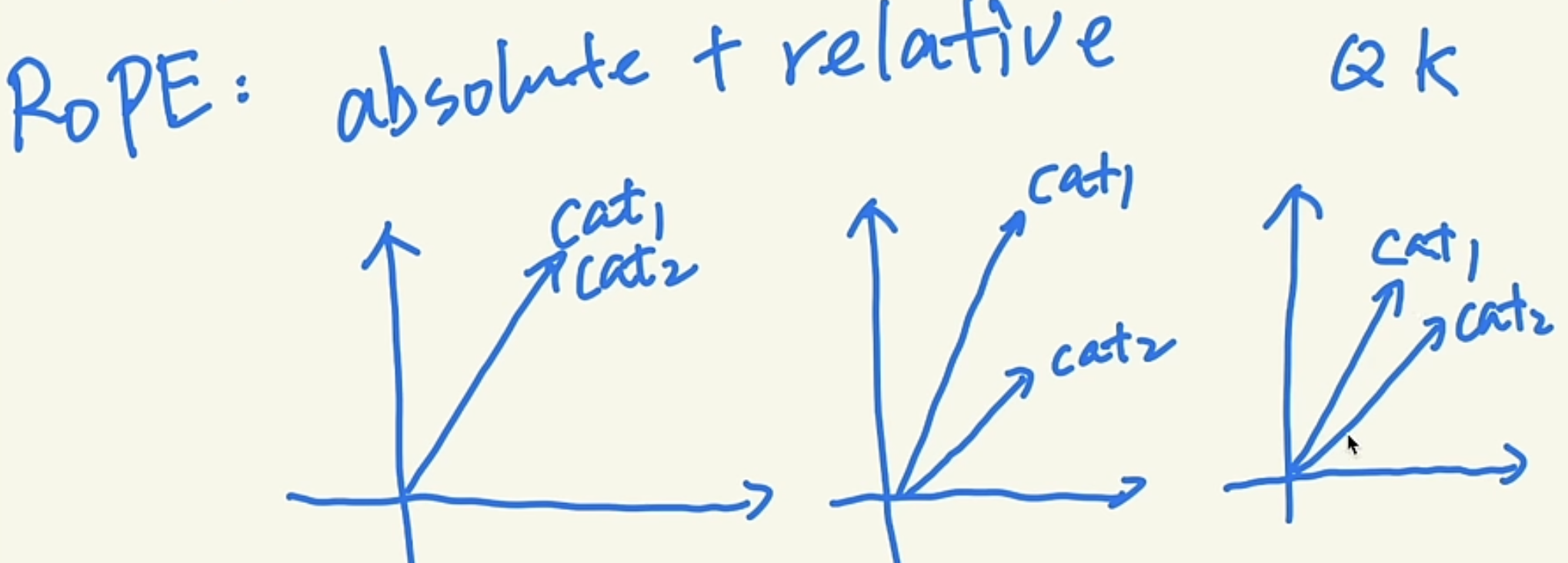 Here is the how RoPE is applied in math, $R_q$ and $R_k$ are rotation for Q, and K, which has the absolute PE attributes, and it can be combined as $R$ during attention calculation, which has the relative PEattributes.
Here is the how RoPE is applied in math, $R_q$ and $R_k$ are rotation for Q, and K, which has the absolute PE attributes, and it can be combined as $R$ during attention calculation, which has the relative PEattributes.
But since the RoPE has position information, the K can no long be cached in the MLA schema. We have to decouple RoPE.
From formula, you can see $W^{uk}$ can no long be absorbed by $W^q$ due to the position coupled $R$

To solve this issue, we must recompute the keys for all the prefix
tokens during inference, and concat with cached KV. That’s why the RoPE branch shows up in following arch.
Another discussion on HF showed the summation is better than concat