Deepseek V3 - MoE
The Deepseek MoE was introduced in this paper
1. Mix of Experts
In tradition transformer architecture:
- the attention layer has most computation cost
- The FFN layer has most of the parameters (knowledge storage)
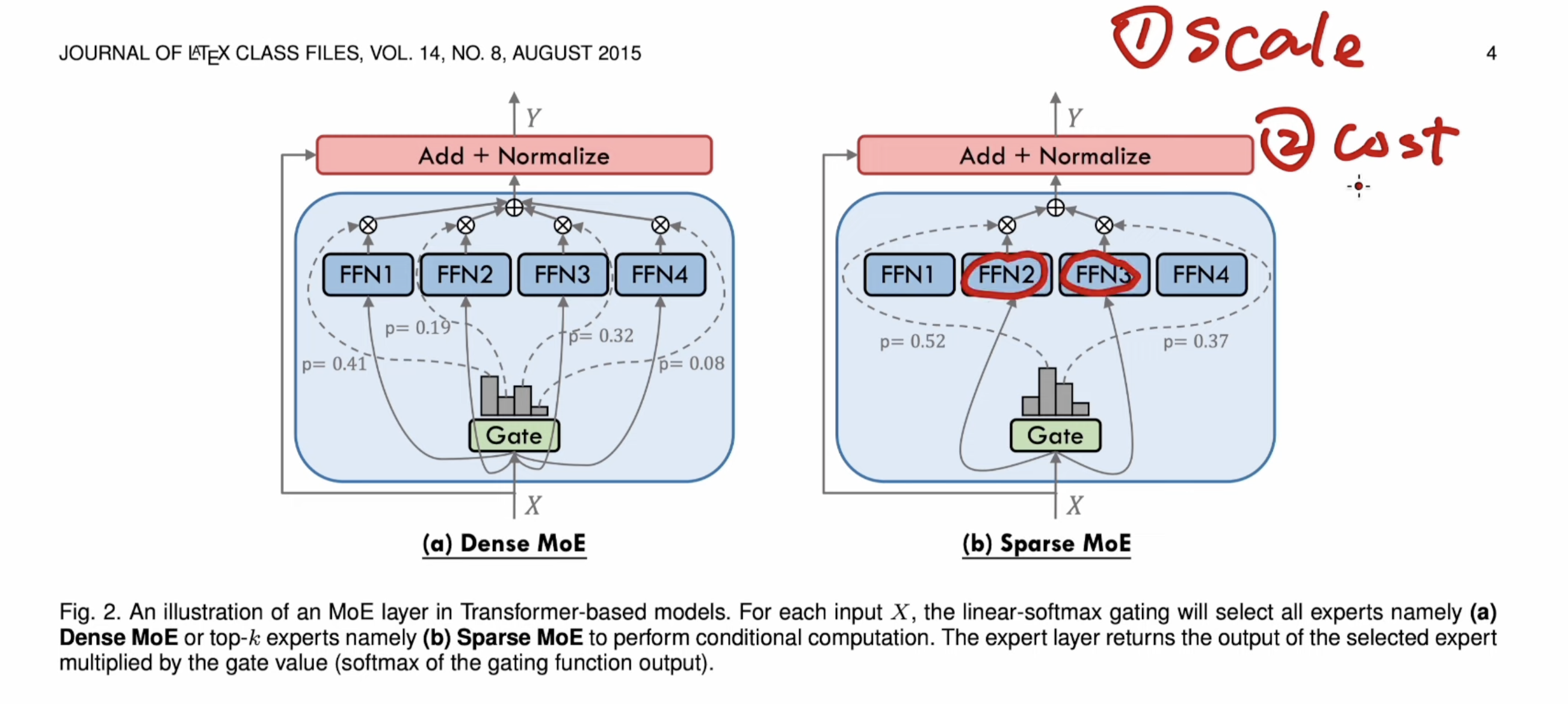
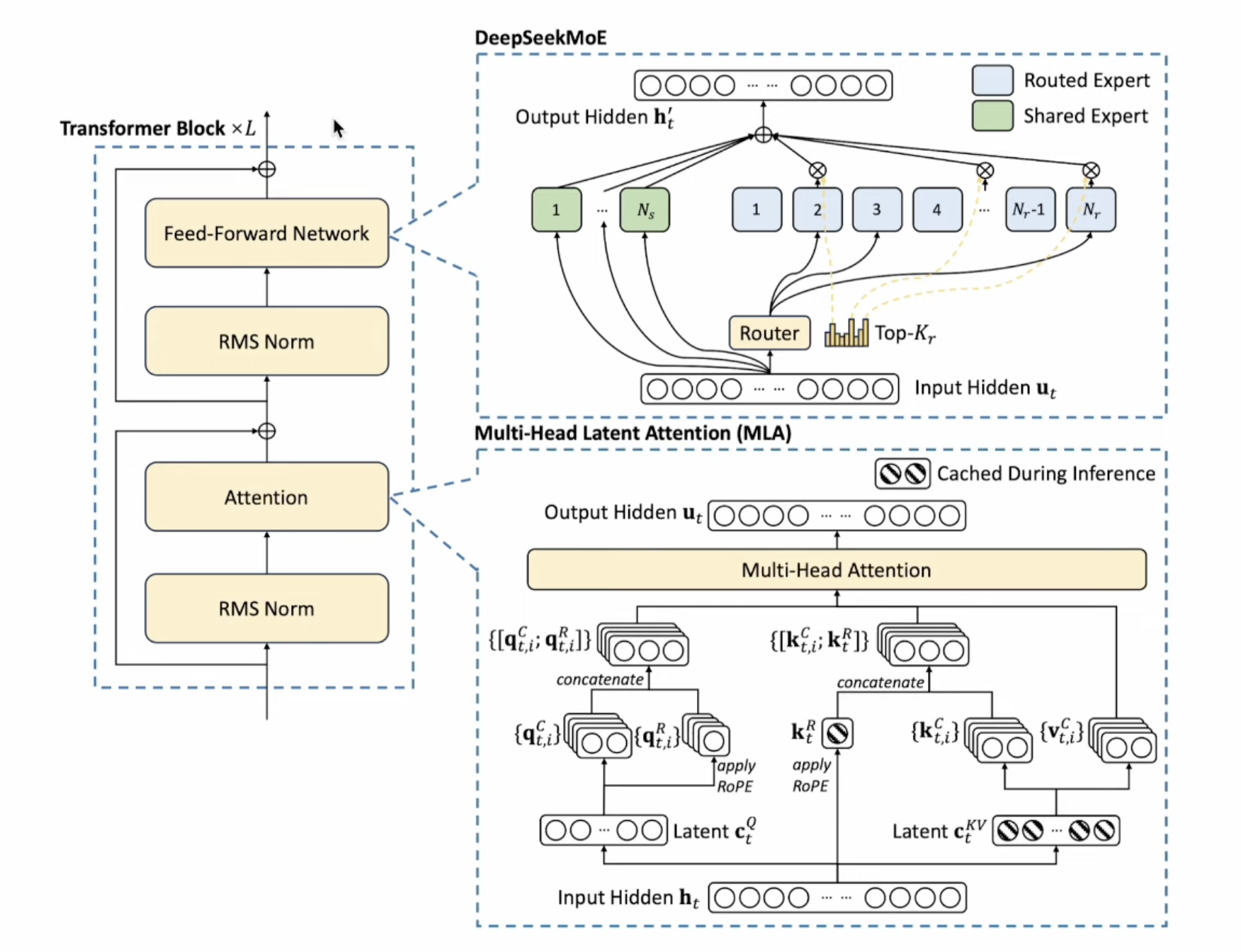 MoE is to split FFN into multiple experts. Dense MoE would do weighted sum for all experts, while sparse MoE is top K experts.
The gate here are actually FFN or MLP network.
MoE is to split FFN into multiple experts. Dense MoE would do weighted sum for all experts, while sparse MoE is top K experts.
The gate here are actually FFN or MLP network.
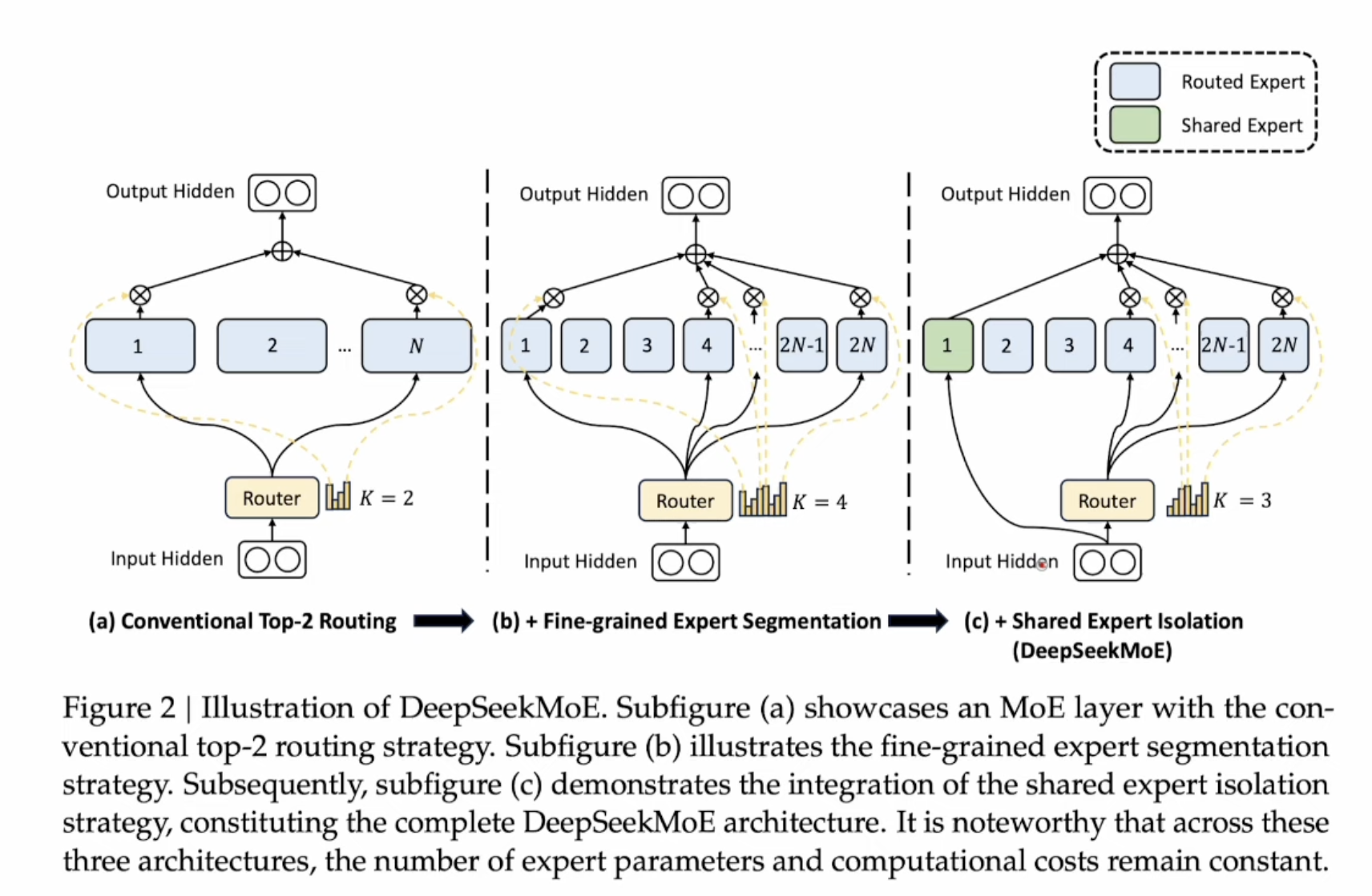
2. Deepseek MoE
Two improvements from DeepseekMoE
- Increase number of experts (k=2->4, x2) and reduce each experts size (MLP size by half). So the total parameter size is the same. It’s similar to model ensamble in Kaggle compeitation, use quantity to trade off quality.
- Add a shared expert. It can help model correction.
3 Switch Transformer
Load balancing is key issue in MoE training. To make sure each expert get similar amount of tokens for training, we can do loss control, adding a loss term to balance the load based on switch transformer
This paper proposed to calculate two vectors
- The probability of each expert got chosen during training. It’s the actally distribution of experts got trained
- The average probability of each expert chosen by the router. It’s the theoretical distribution of experts.
The load balance loss is the differences between these two vectors.
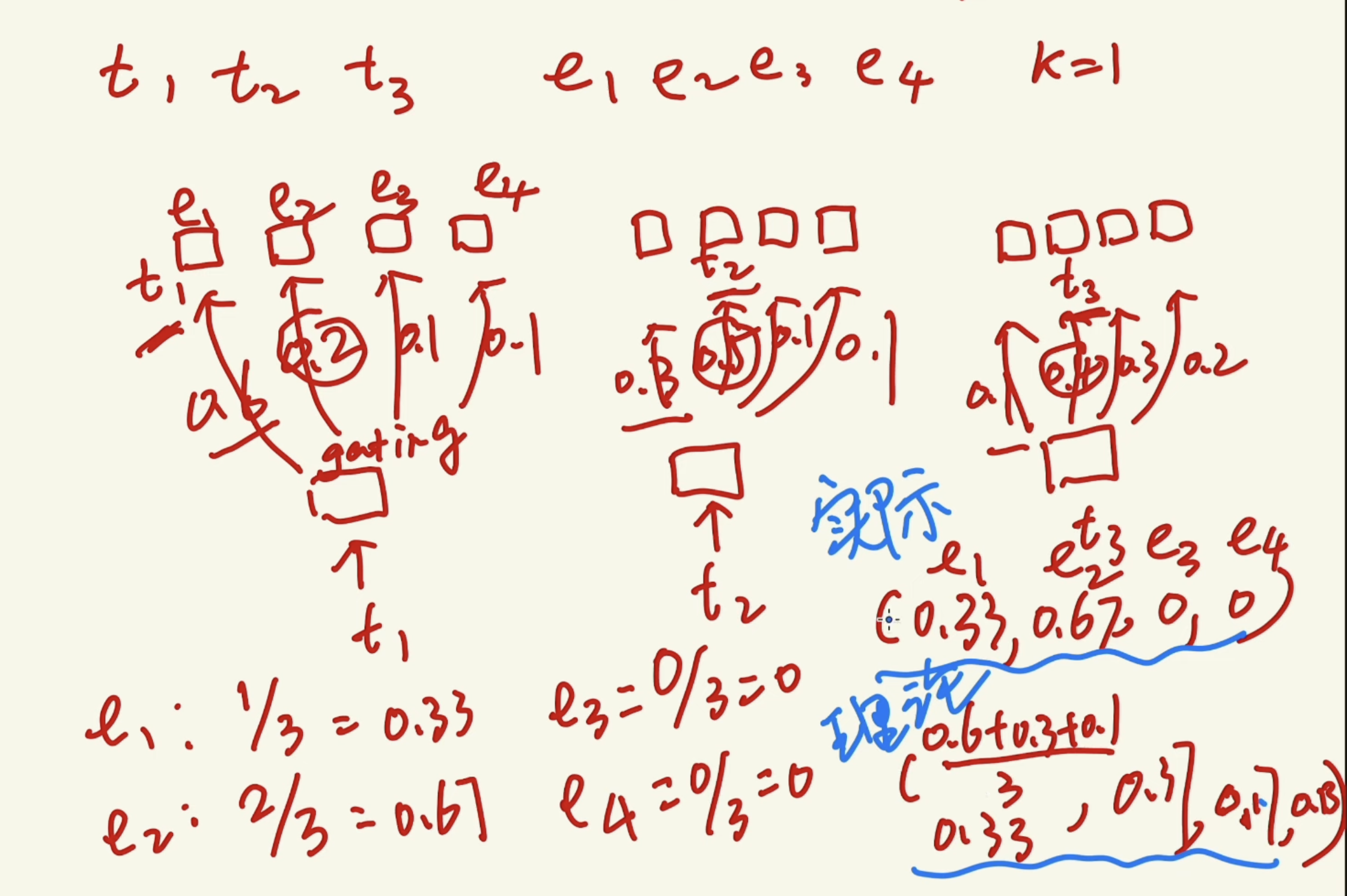 By finding the inner product of these two vectors, authors though it encourage uniform distribution, which leads to minimun loss.
By finding the inner product of these two vectors, authors though it encourage uniform distribution, which leads to minimun loss.
 But this is WRONG. Intuitively, the smaller the inner product, the larger the differences of the two vectors. So the it’s easy to find a counter-example of non-uniform distribution has smaller loss values
But this is WRONG. Intuitively, the smaller the inner product, the larger the differences of the two vectors. So the it’s easy to find a counter-example of non-uniform distribution has smaller loss values

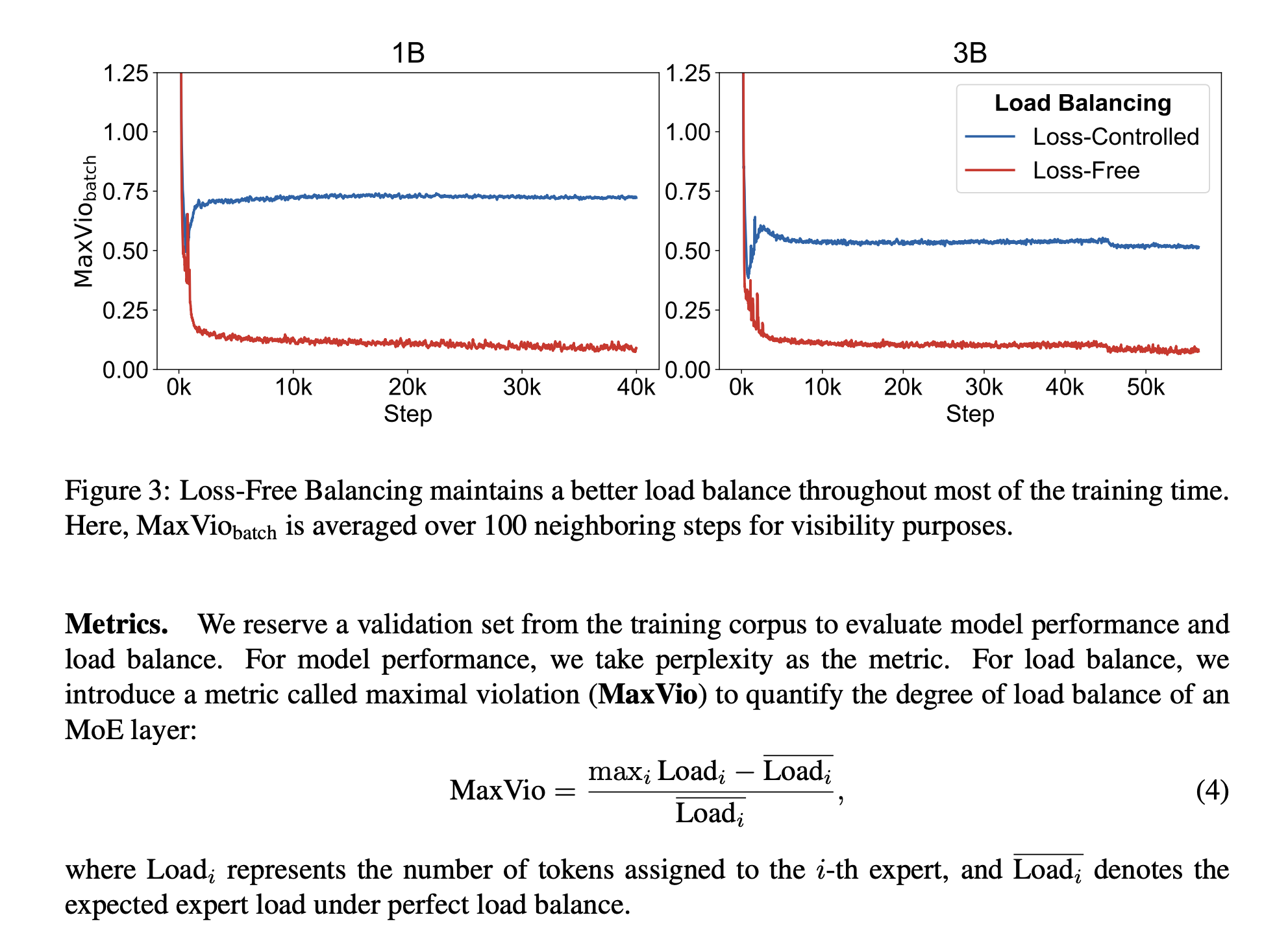
4 Auxilary-Loss-Free Load Balancing
DeepseekMoE use loss less control by introduing a bias in the softmax layer in this Auxilary-Loss-Free Load Balancing paper
The performance, measured by MaxVio, is better than Loss controlled LB.
Couple of other points in DeepseekMoE
- Node limit routing: Limit token sent to N nodes
- No Token dropping in both training and inference: Token dropping is use the skip connection ONLY.
