Deepseek V3 - MTP
Great explanation of the MTP used in Deepseek V3. Video source is part 4 of this series.
1 Overview
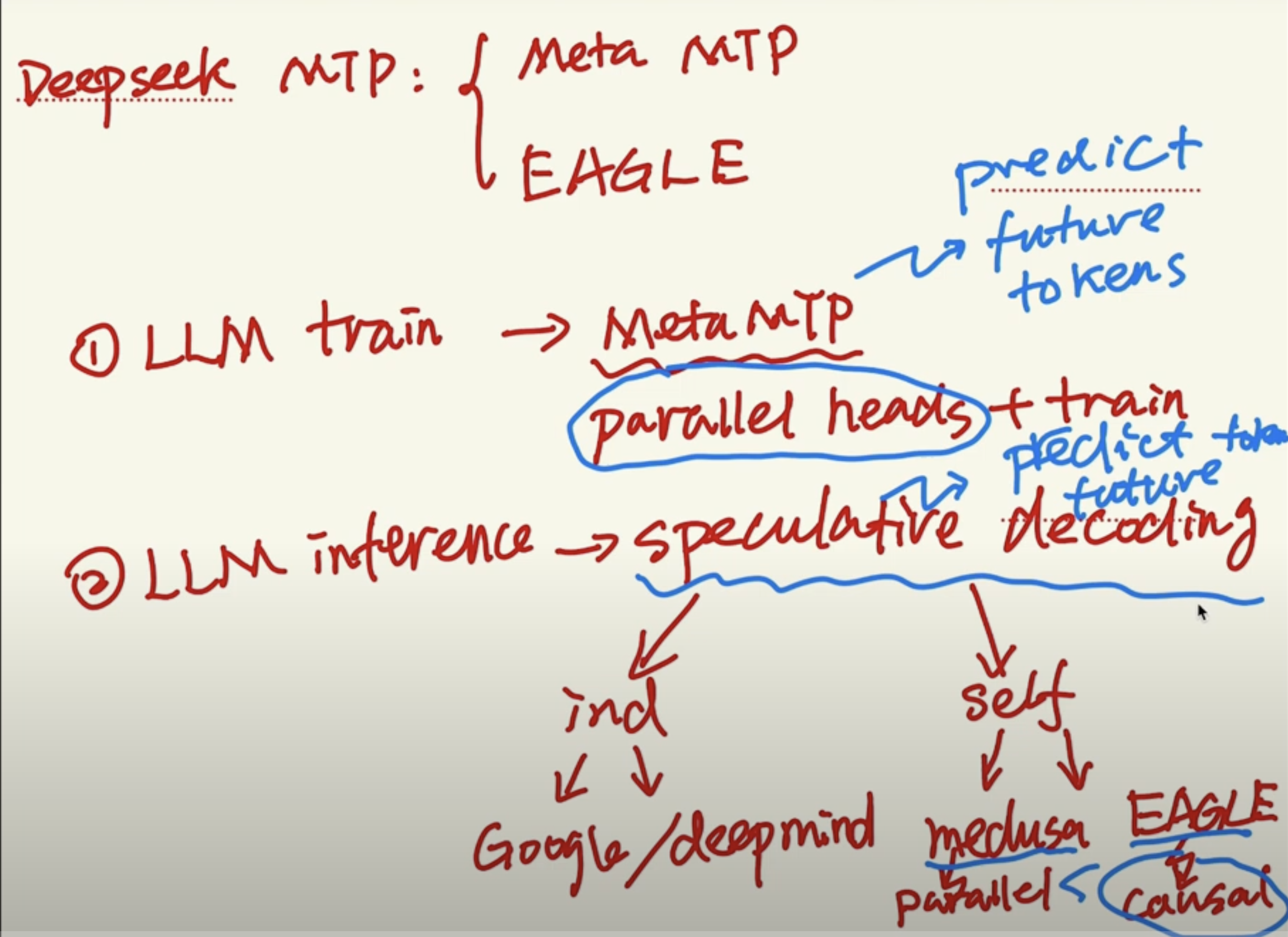
Multi-Token-Prediction of Deepseek is applying Eagle’s causal heads idea, into Meta’s MTP training(paper).
2 MTP Training
Using multiple heads to predict mulitple tokens during training.
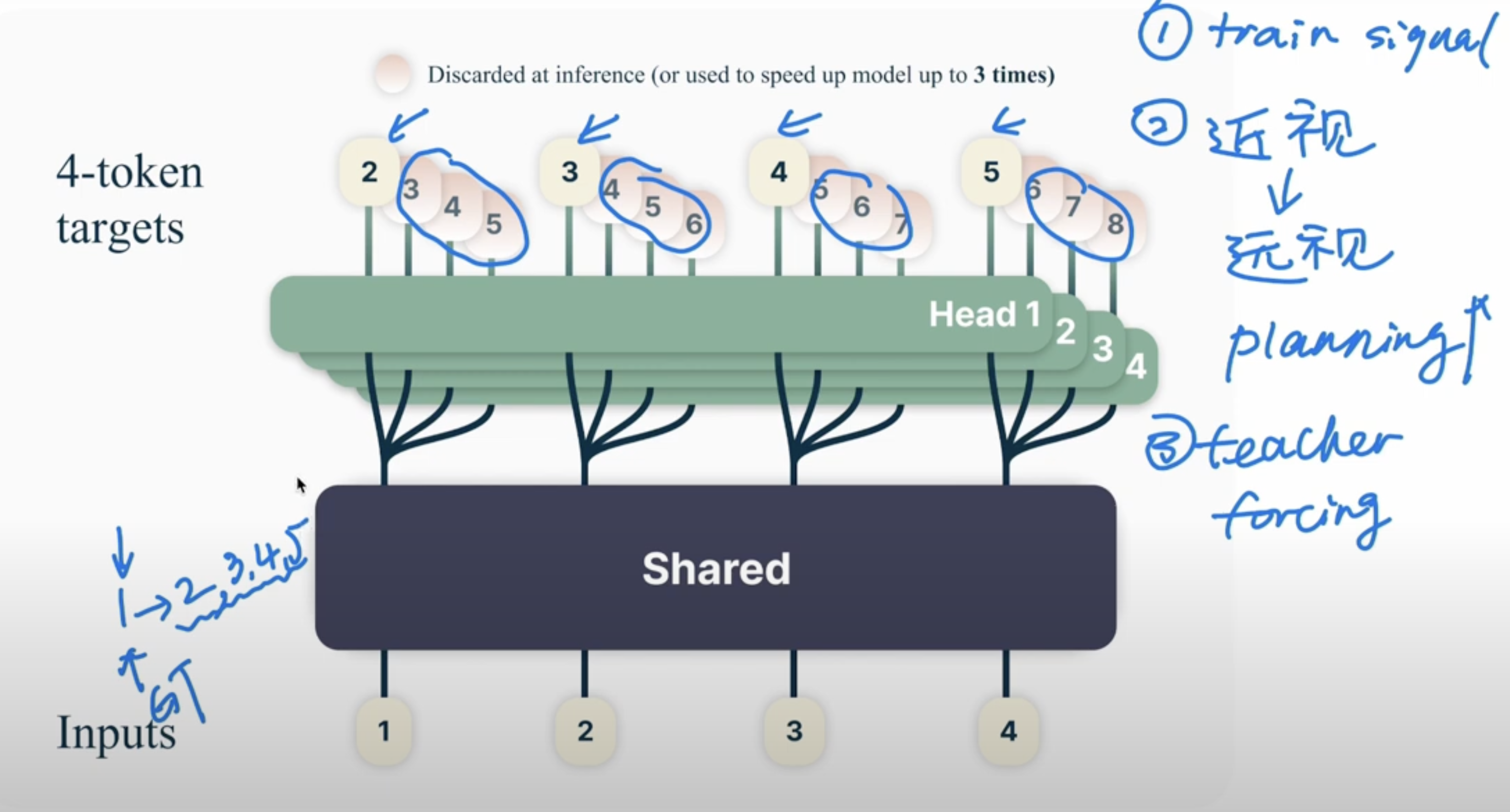 and it can have following advantages
and it can have following advantages
- Enhaunce training signal
- Planning capability. Not just one short-sighted token only, but can predict future tokens
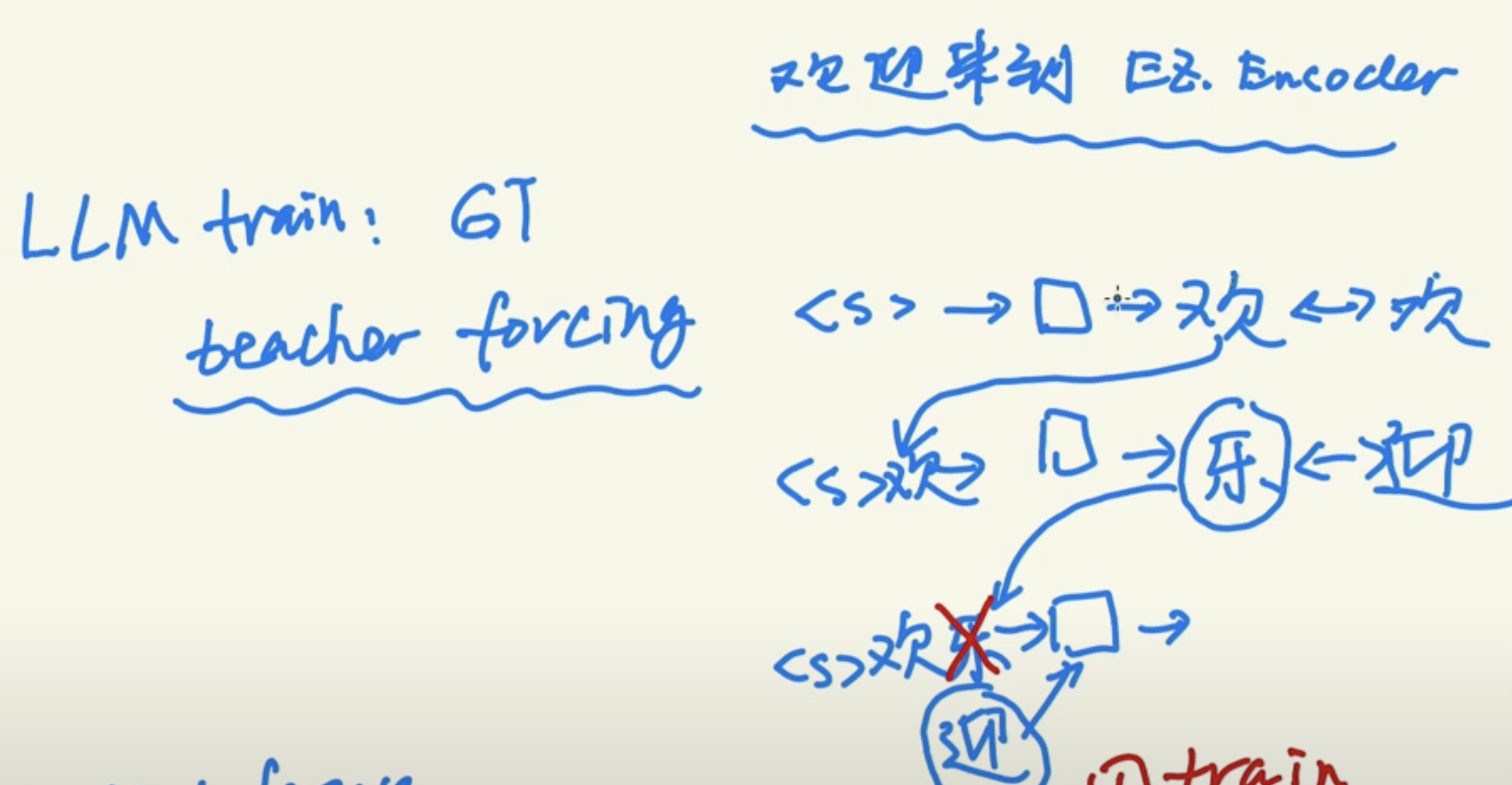
- Solve the Teaching Forcing issue. In the following example, 3->5 is a hard transition. Next token prediction can only get 1/7 training on the hard transition, but the MTP can get 6/21 training on it.
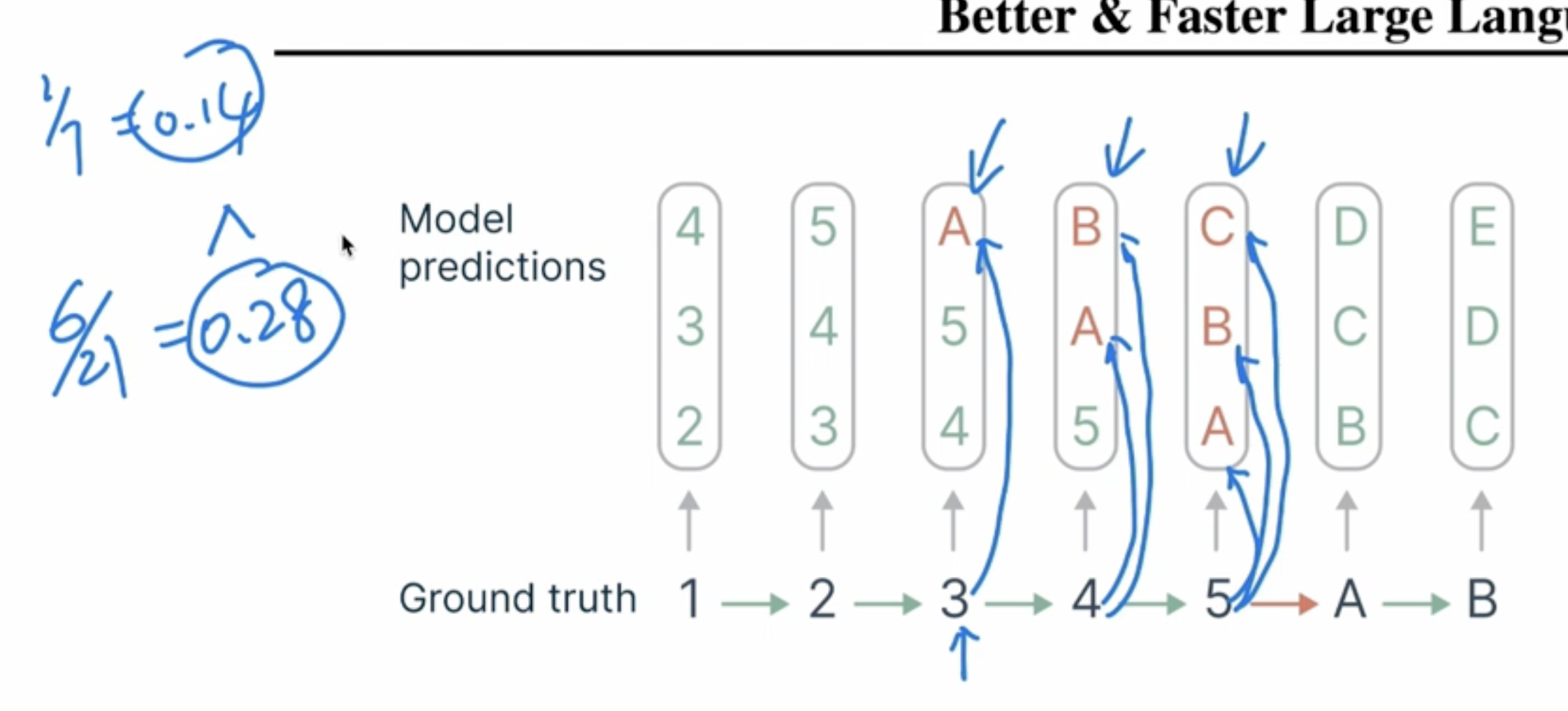 Here is another explanation of Teaching Force in training. You can see the model prediction 乐 instead of 迎 after 欢. But in the next round of training, the input was forced backed to 迎.
Here is another explanation of Teaching Force in training. You can see the model prediction 乐 instead of 迎 after 欢. But in the next round of training, the input was forced backed to 迎.
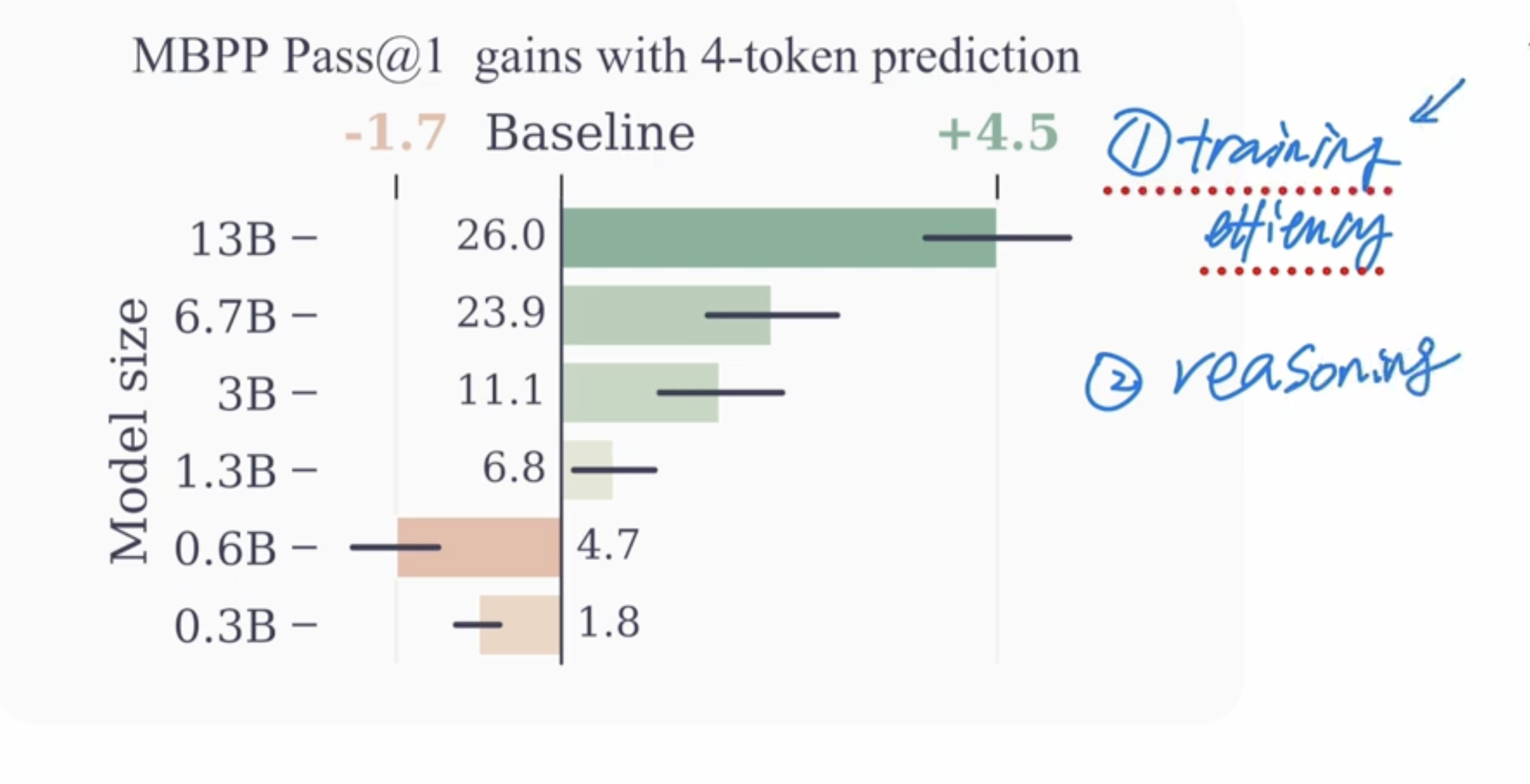
 MTP works on relative large size models, but it’s not working on smaller models. (pass@k meaning pass k unit tests). Still MTP can improve training efficiency and improve reasoning capability.
MTP works on relative large size models, but it’s not working on smaller models. (pass@k meaning pass k unit tests). Still MTP can improve training efficiency and improve reasoning capability.
3 Speculative Decoding
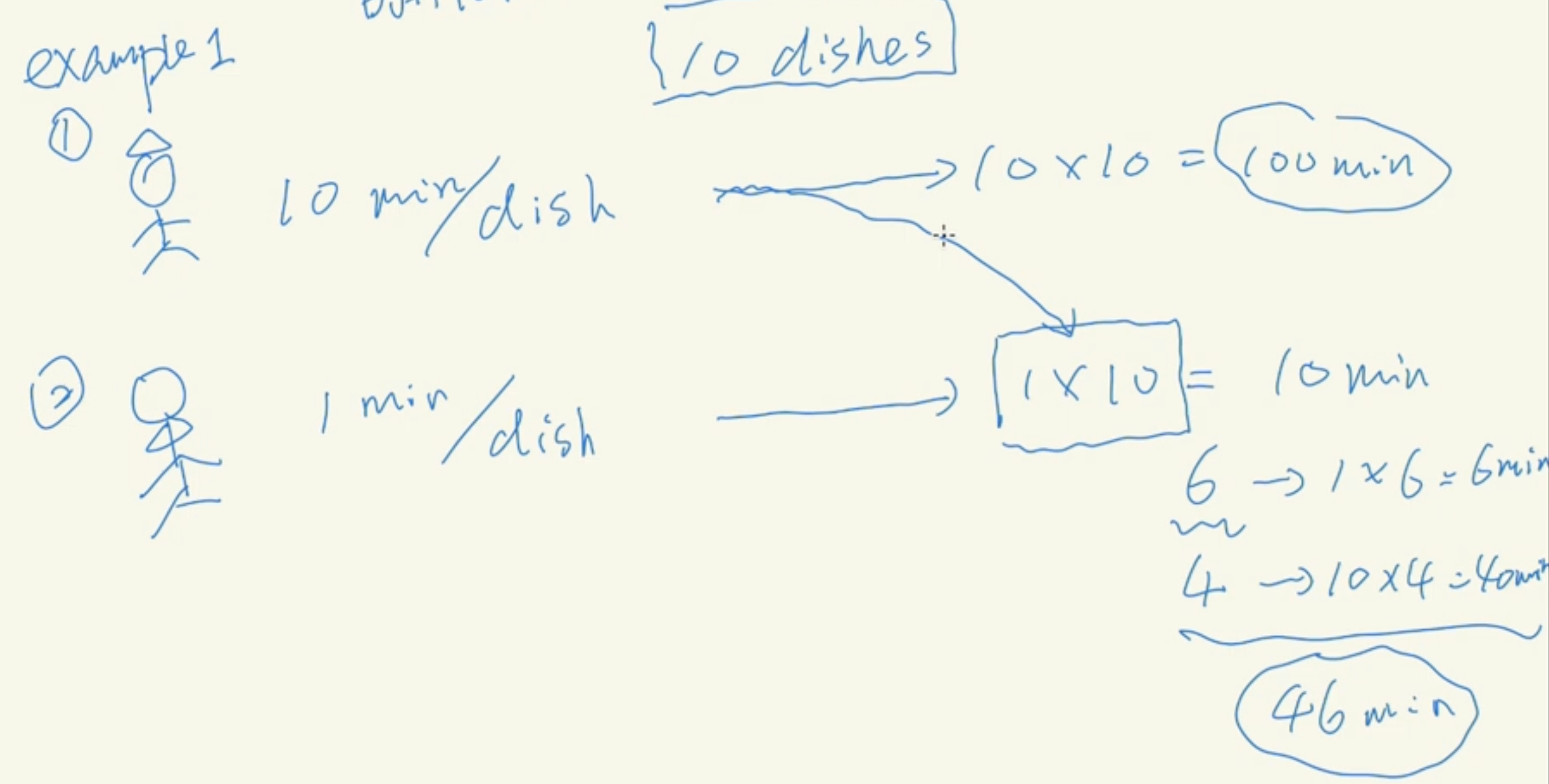
An analagy of Speculative Decoding with two chiefs.
 Another example is branch prediction. A CPU would predict which branch of code would execute so it calculate it ahead of time.
Another example is branch prediction. A CPU would predict which branch of code would execute so it calculate it ahead of time.
 There are two major branches of SD, one is independanc path, having two models, one big and one small, as in the orignal Google/Deepmind paper.
There are two major branches of SD, one is independanc path, having two models, one big and one small, as in the orignal Google/Deepmind paper.
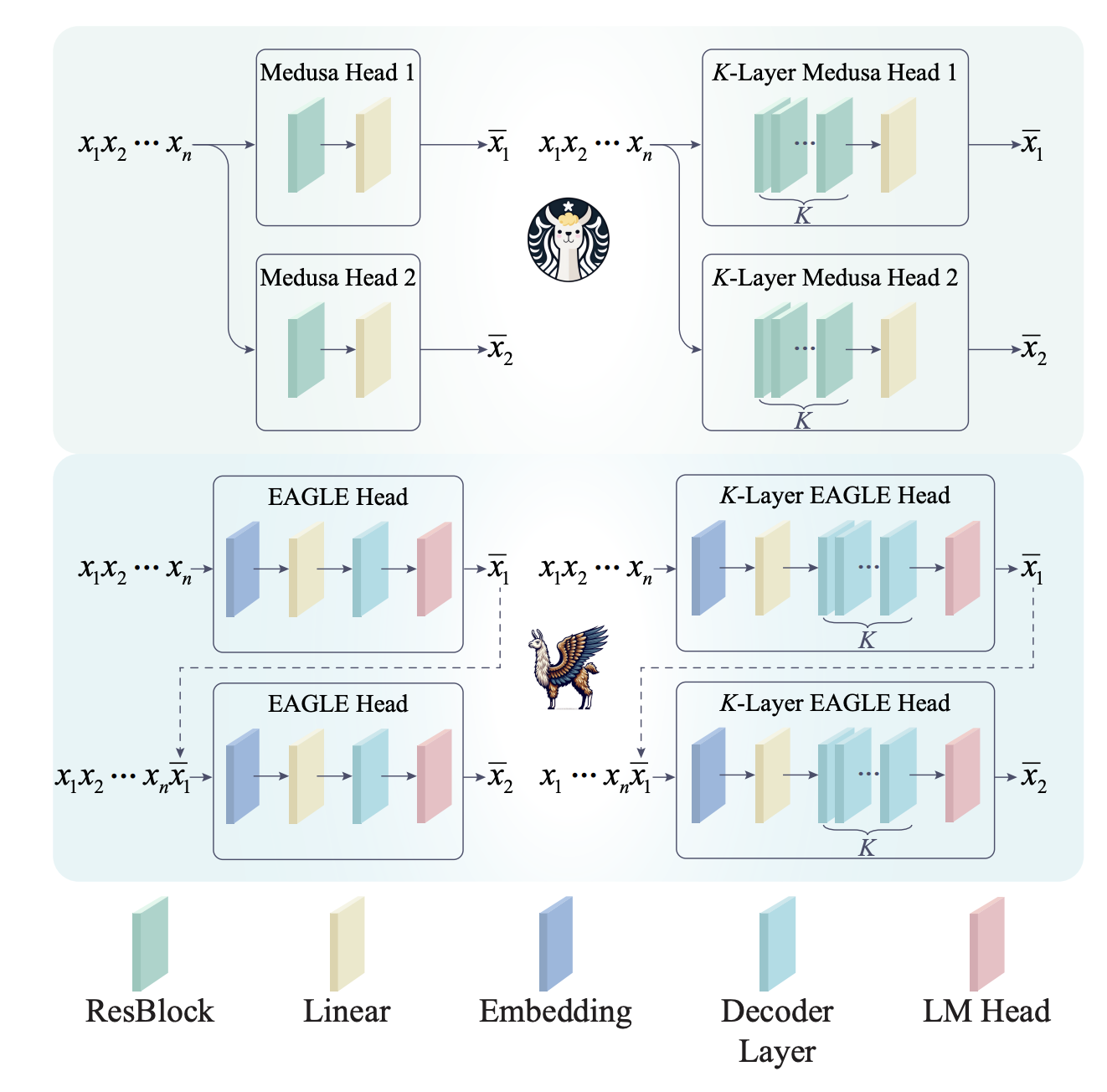
 Medusa absorb the small model into the big model, by predicting multiple tokens by parellel heads, and eagle improve it by changing to causal heads
This picture if from KOALA paper, which improve both method by adding K-layers.
Medusa absorb the small model into the big model, by predicting multiple tokens by parellel heads, and eagle improve it by changing to causal heads
This picture if from KOALA paper, which improve both method by adding K-layers.
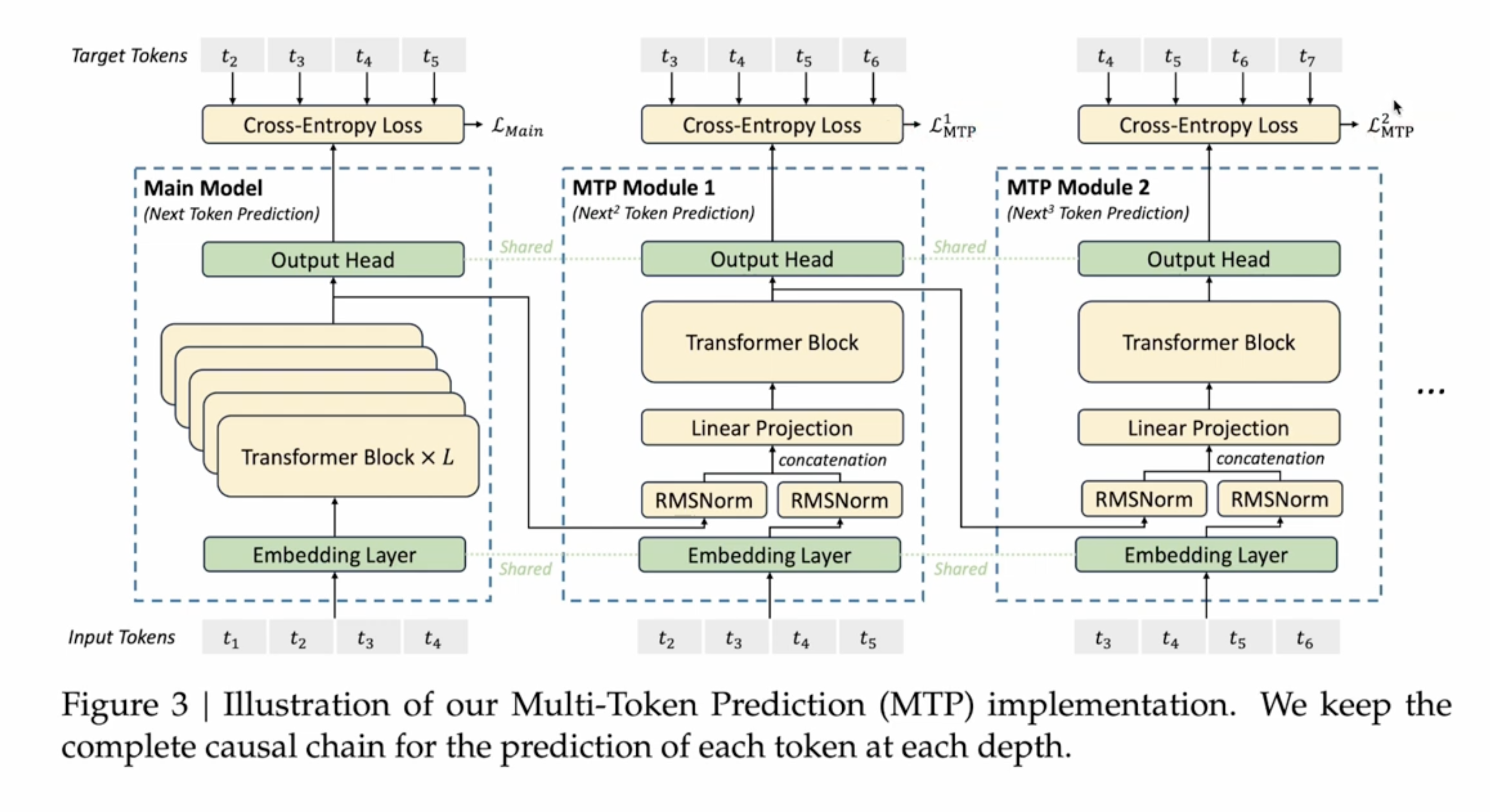
4 MTP in Deepseek
MTP with causal heads, that’s the MTP used in deepseek