Disaggregated Serving
Disaggregated Serving is about separeting prefill(generate the first token) and decoding(generate token-by-token autoregressively) phase of LLM, and this blog is from the authors of the original paper and gives great explanations.
0 Motivations
The prefill and decode phase determines TTFT and TPOT(ITL) of LLM output.
The throughput is no longer a good measure of the LLM performance, and goodput is adopted to measure requests meeting the SLO(Service-Level Objectives)
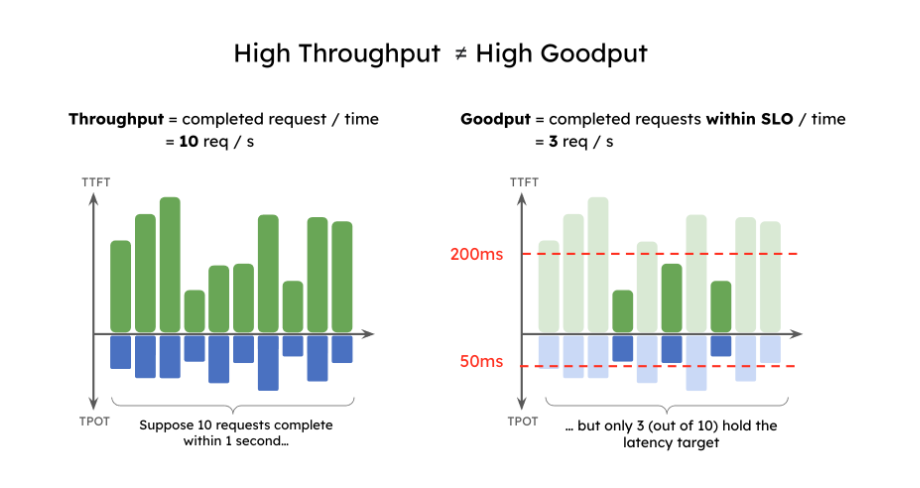
Continuous batching is the used to increase GPU utilization rate and is good for throughput increasement.
1 Colocating issues
The two phases have very distinct characteristics in computation. Prefill is very compute-bound, and decoding is memeory-bound. So colocating resource causes
- interfences
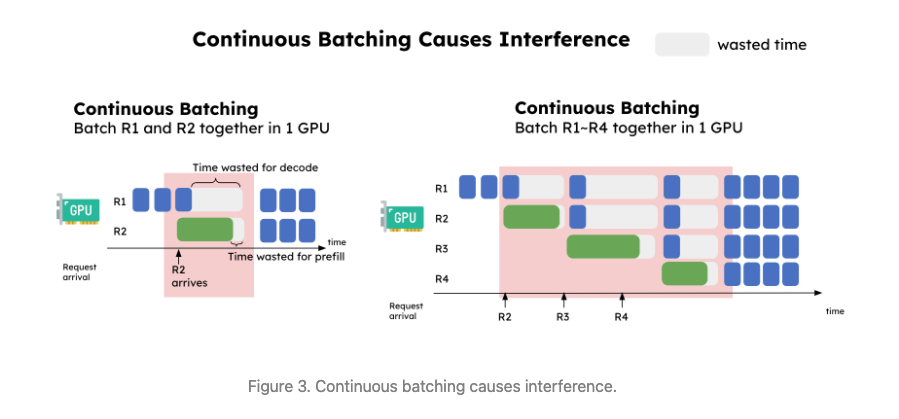 The waste time is increasing when we get a steady steam of incoming requests. (Good to notice that each request is processed at same rate, no matter it’s prefill or decoding). So we have to over-provision resources to get SLO.
The waste time is increasing when we get a steady steam of incoming requests. (Good to notice that each request is processed at same rate, no matter it’s prefill or decoding). So we have to over-provision resources to get SLO. - couples the resource allocation and parallelum strategies The parallelism strategies (tensor, pipeline, or data parallelism) are inherently coupled for the prefill and decoding computation.
2 Disaggrgating Prefill and Decoding
The idea is simple: disaggregating prefill and decode into different GPUs and customize parallelism strategies for each phase.
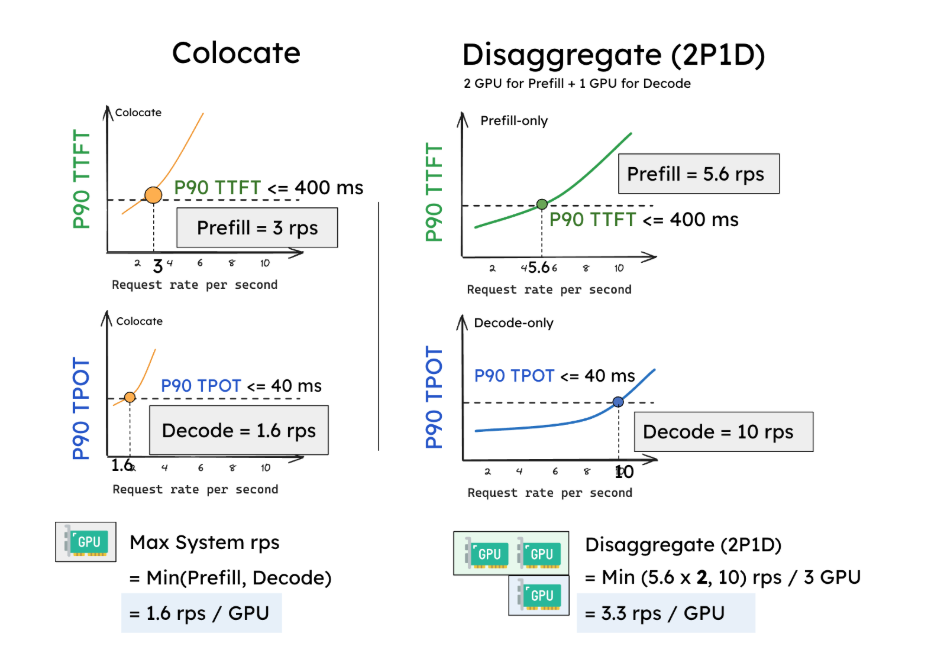 Even though more GPU is used, but per GPU throughput is higher.
Even though more GPU is used, but per GPU throughput is higher.
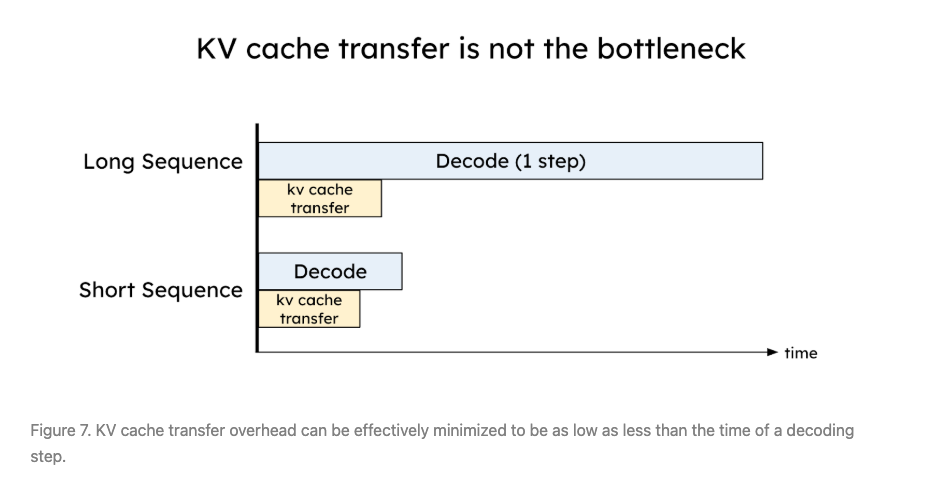
Disaggregation comes at the cost of transferring intermediate states (i.e., KV Cache) between prefill and decoding GPUs. With NVLink (600GB/s) and PCI-e 5.0 (64GB/s), the kv cache transfer time is less than decoding 1 step!
3 Disagg VS Chunked Prefill/Piggybacking
- Dynamic SplitFuse from DeepSpeed (MS)
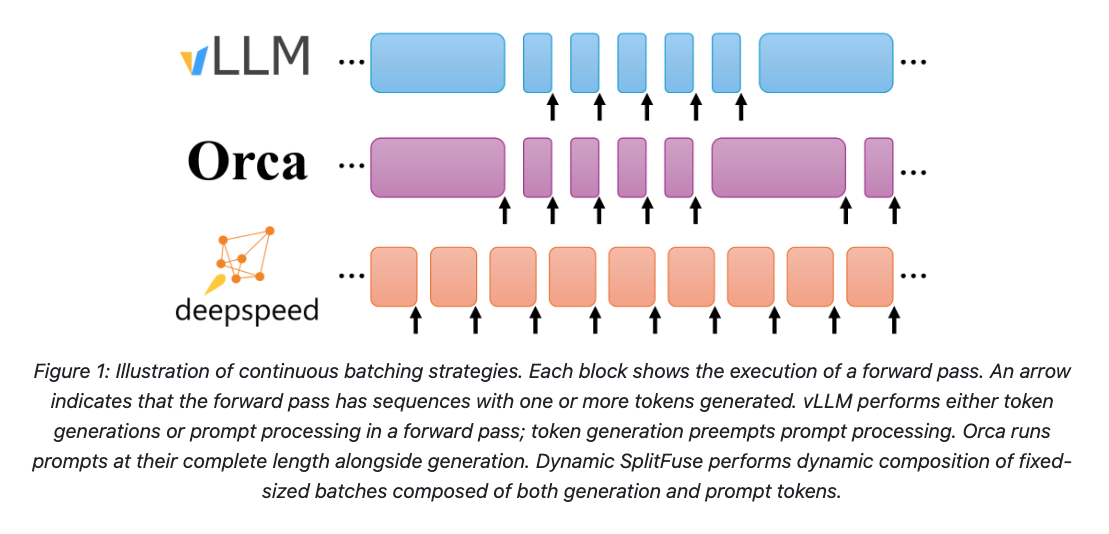 The key idea of splitfuse to split a lengthy prefill into smaller chunks, thereby forming a batch with better GPU utilization by combining a chunk of prefill with piggybacked decoding tasks.
The key idea of splitfuse to split a lengthy prefill into smaller chunks, thereby forming a batch with better GPU utilization by combining a chunk of prefill with piggybacked decoding tasks.
- Chunked Prefill and piggybacking from MS and google, implemented in vLLM
Pipeline Parallelism splits a model layer-wise, where each GPU is responsible for a subset of layers; compared to Tensor Parallelism which shards each layer across the participating GPUs. PP has a much better compute-communication ratio and does not require expensive interconnects. but it introduces pipeline bubbles
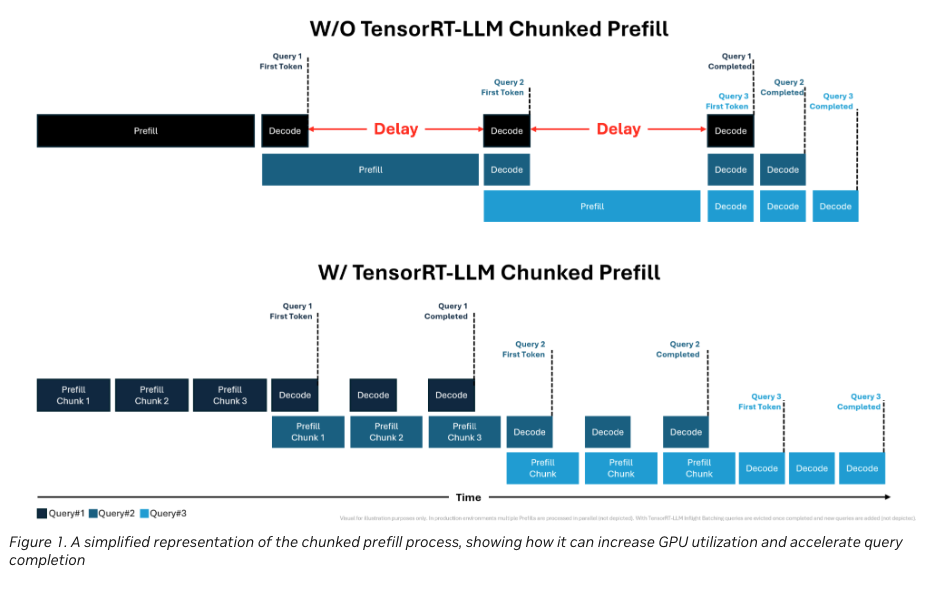 It may be promising for better throughput but does NOT tradeoff between TTFT and TPOT but to adhere to both.
It may be promising for better throughput but does NOT tradeoff between TTFT and TPOT but to adhere to both.
For TTFT, chunked-prefill cause overheads regardless of chunksize For TPOT, colocating slows down all these decoding tasks