Knowledge Distillation
Distillation was introduced by Hinton and Dean in 2015, another masterpiece from Google.
The fundamental idea is that training and inference have different requirements, so model compressoin, which is the only knowlege reference in this paper, by Dr. Rich Caruana.
The implementatoin would let student learn from teacher’s logits, on top of learning from the groundtruth label.
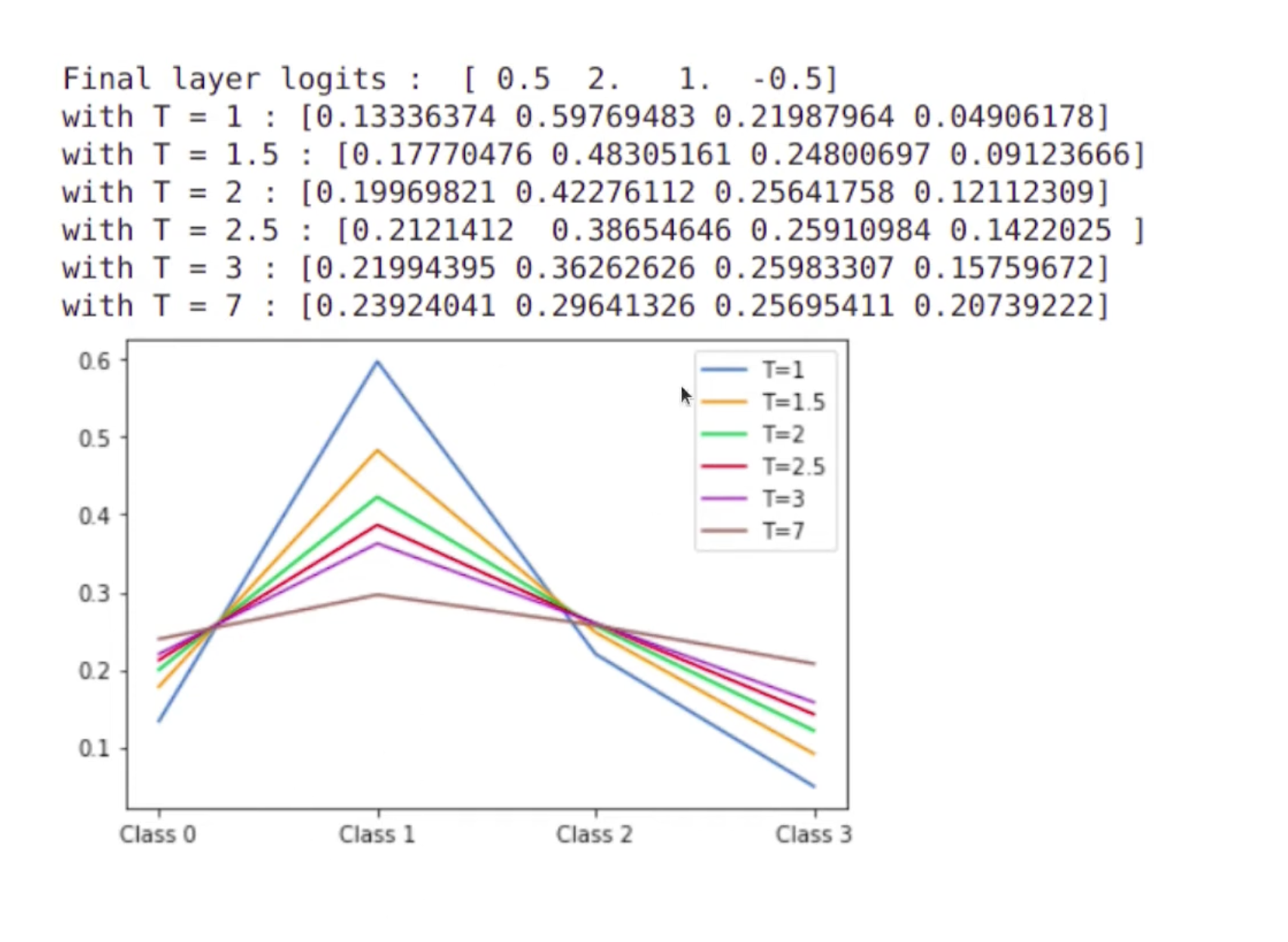
1 Softmax with Temperature
\(q_i=\frac{exp(z_i/T)}{\Sigma_jexp(z_j/T)}\)
The larger the $T$, the smaller are the differences
2 Soft target and Hard target
The teacher’s logit are called soft target, and the true labels are hard target. Get totally lose by add two lose.

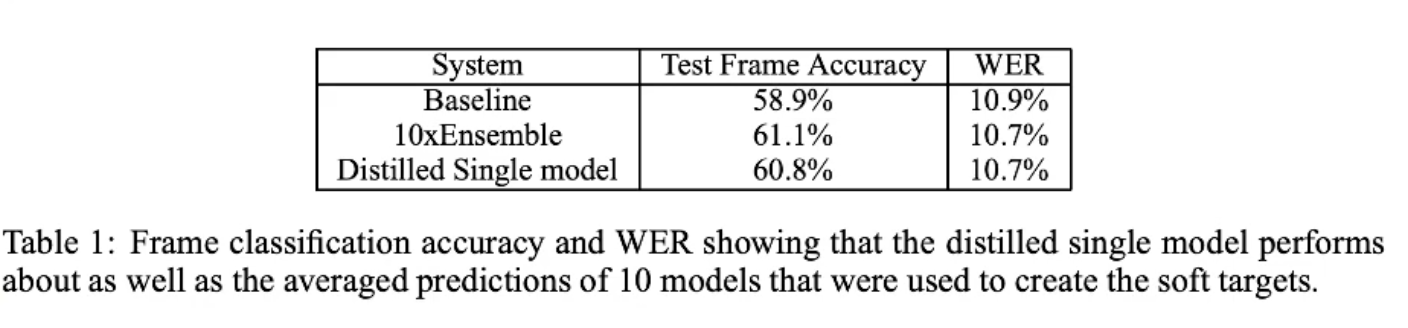
3 Result