Kaiming’s ML overview at MIT
Kaiming He joint MIT as associate professor in Feb 2024 and deliveried “Deep Learning Bootcamp” as his first public talk as MIT professor. It’s very pleasant to go over his 1hr talk and here are some notes
DL is all about repensentation.
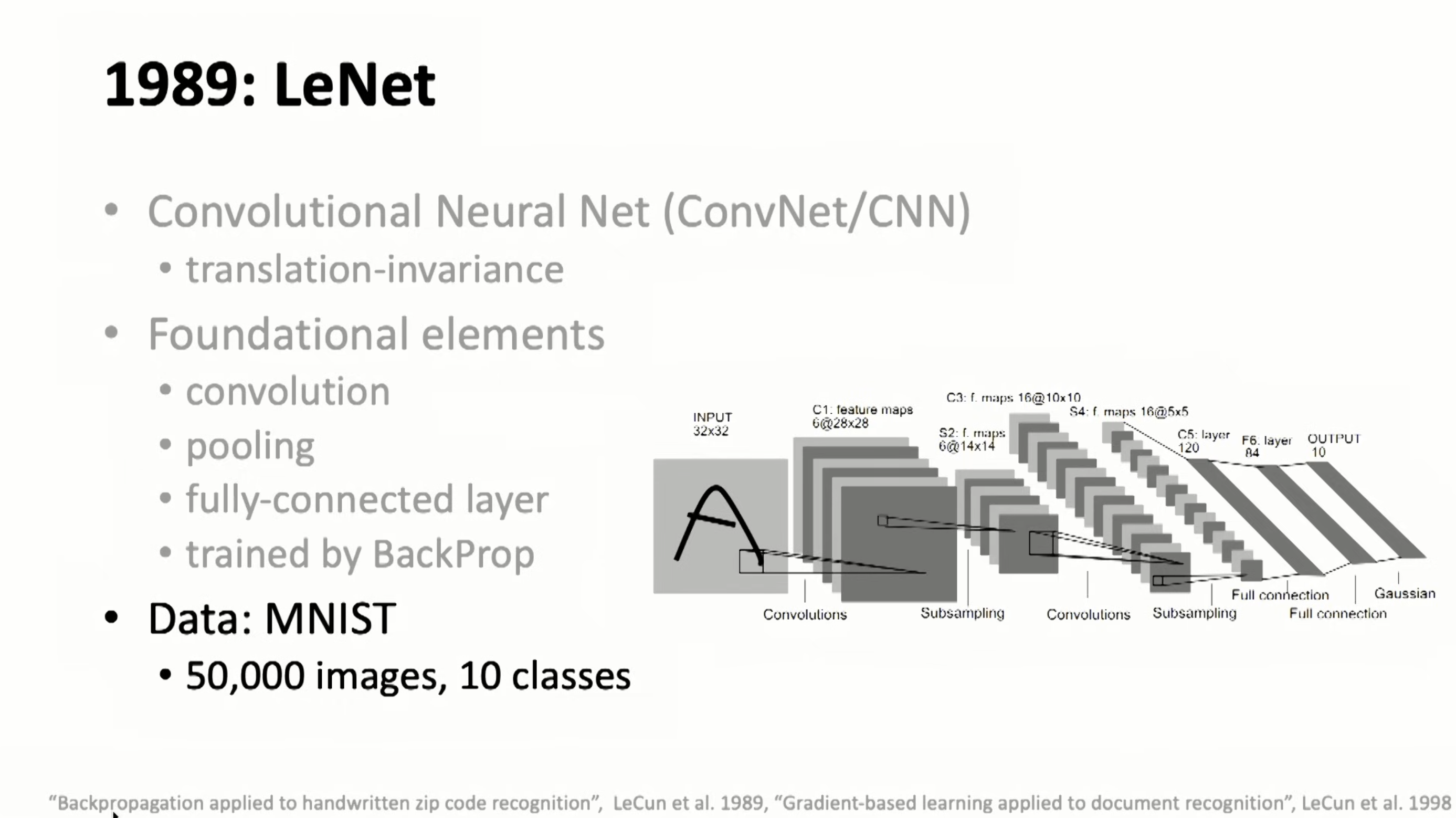
 LeNet was firstly introduced in 1989
LeNet was firstly introduced in 1989
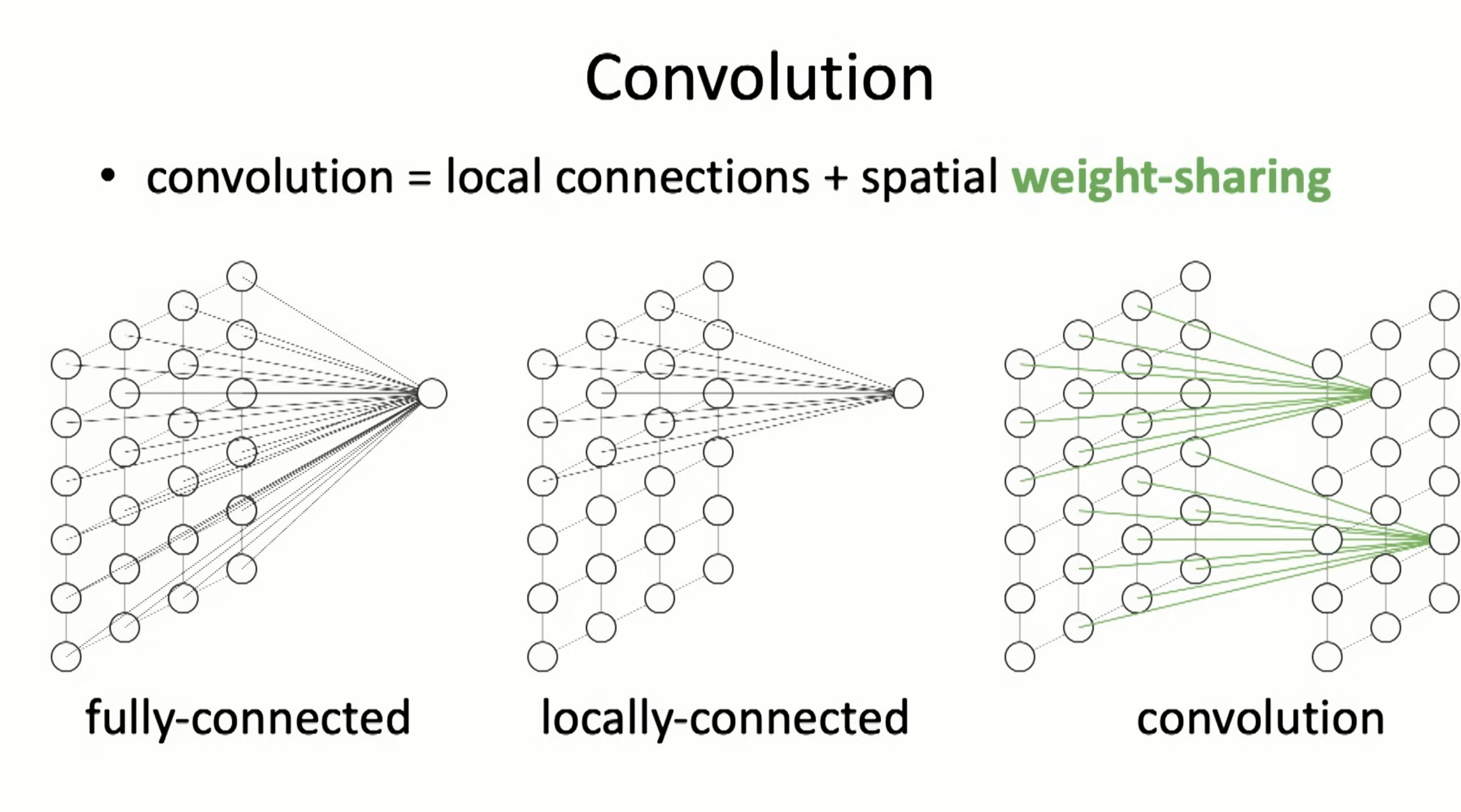
 Conv is local connections with weight sharing.
Conv is local connections with weight sharing.
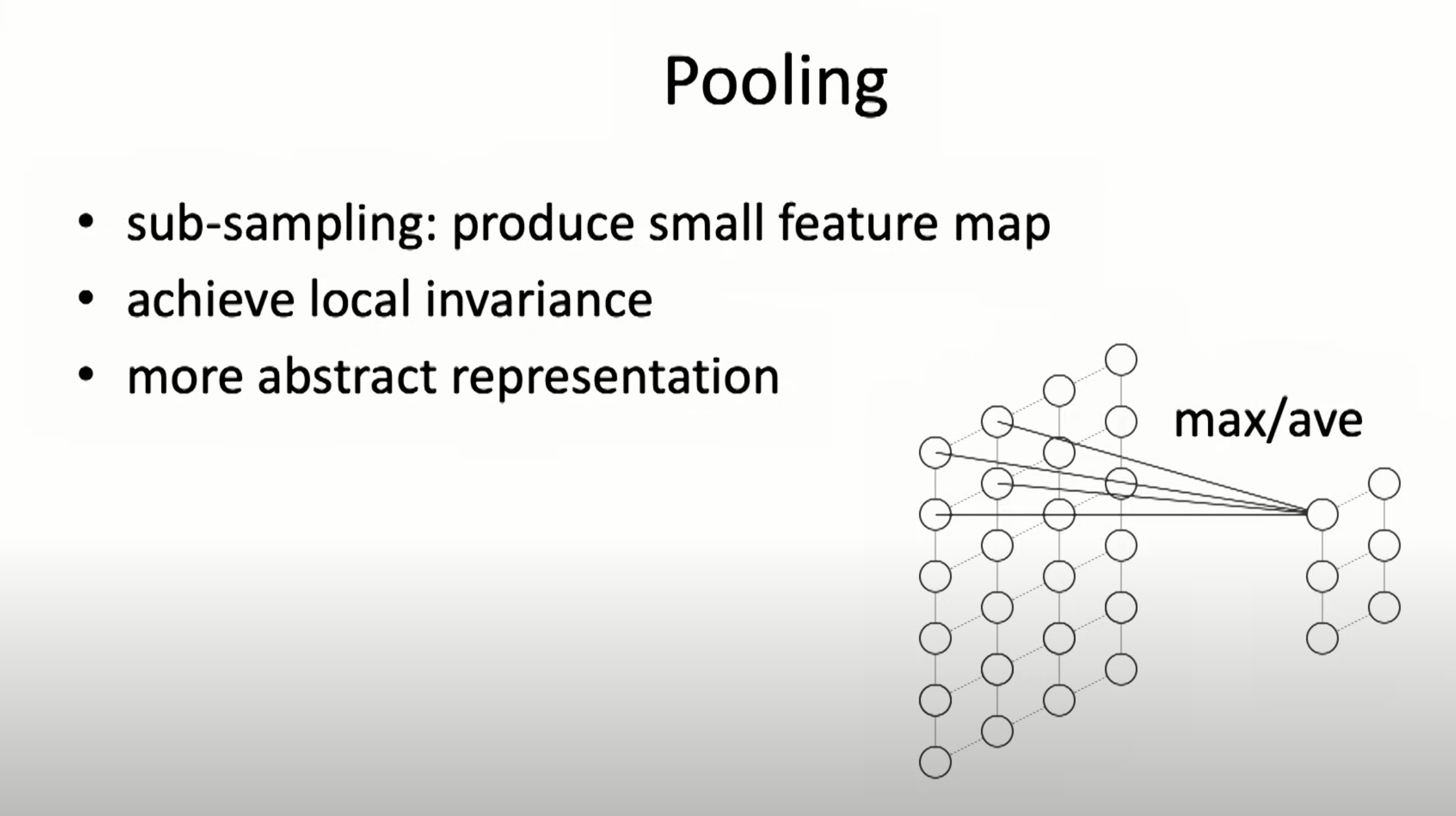
 Pooling is about local invariance
Pooling is about local invariance
 AlexNet in 2012 is big break through after 20yrs.
AlexNet in 2012 is big break through after 20yrs.
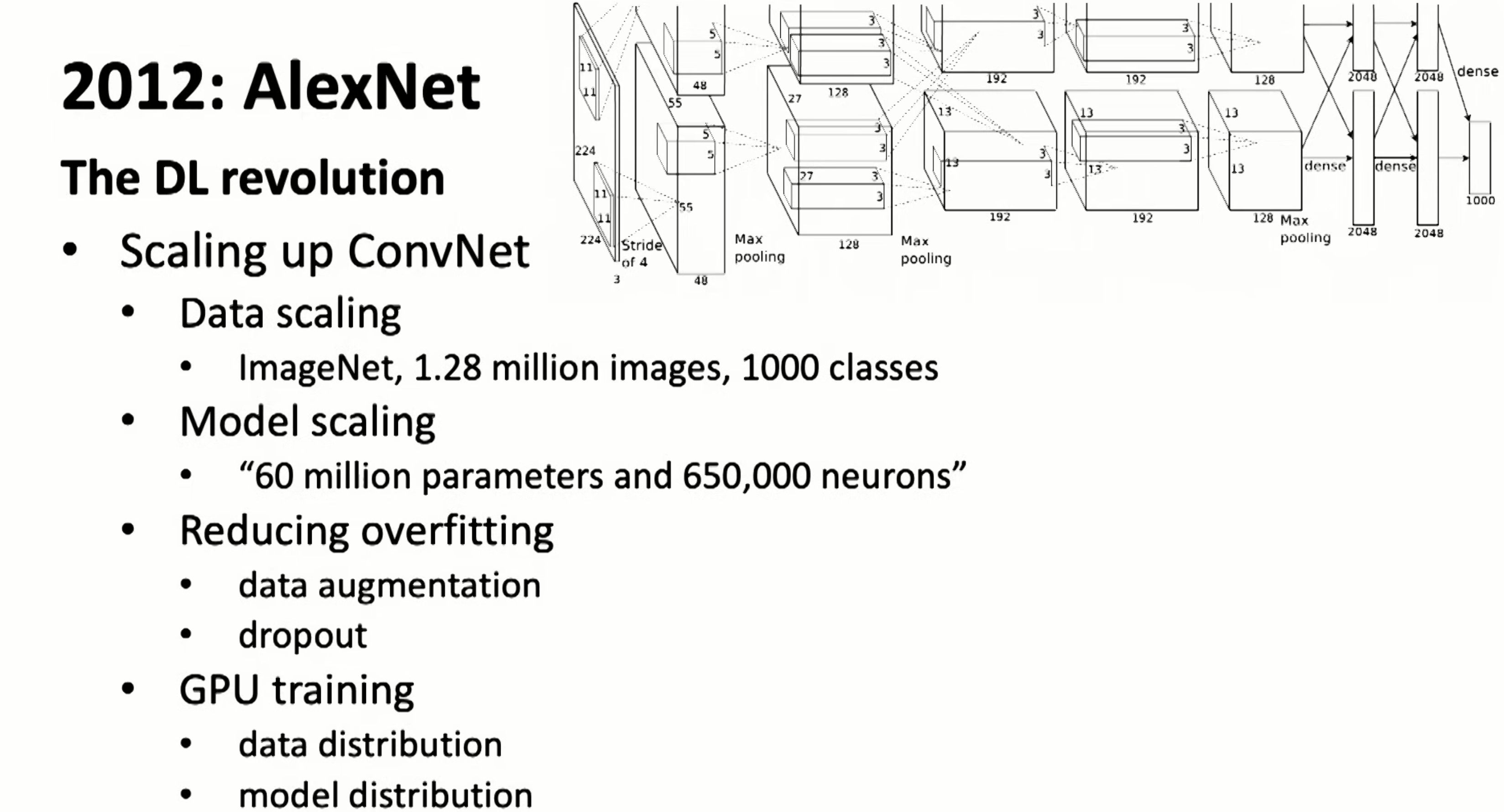 The net goes wider for more features
The net goes wider for more features
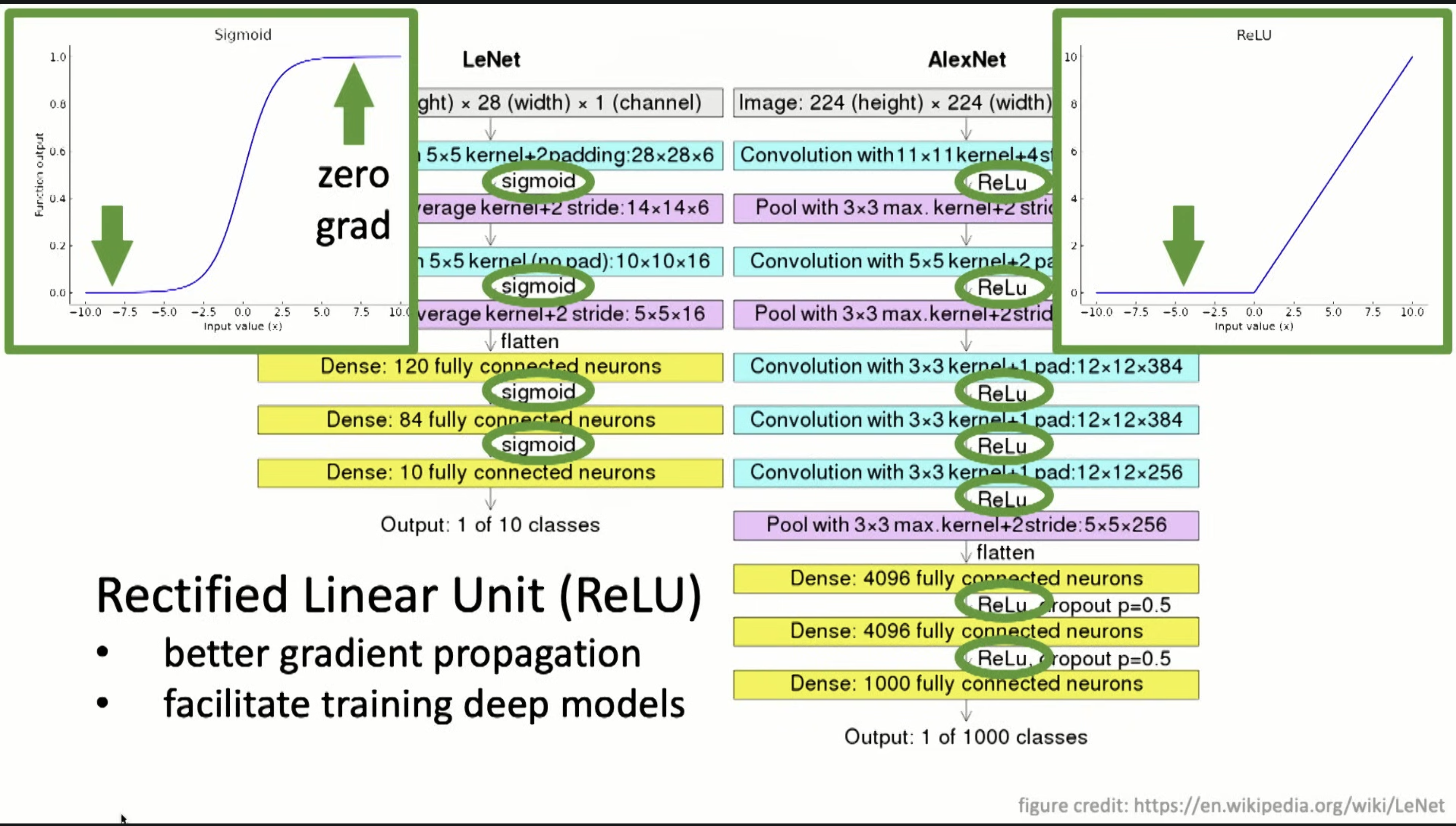
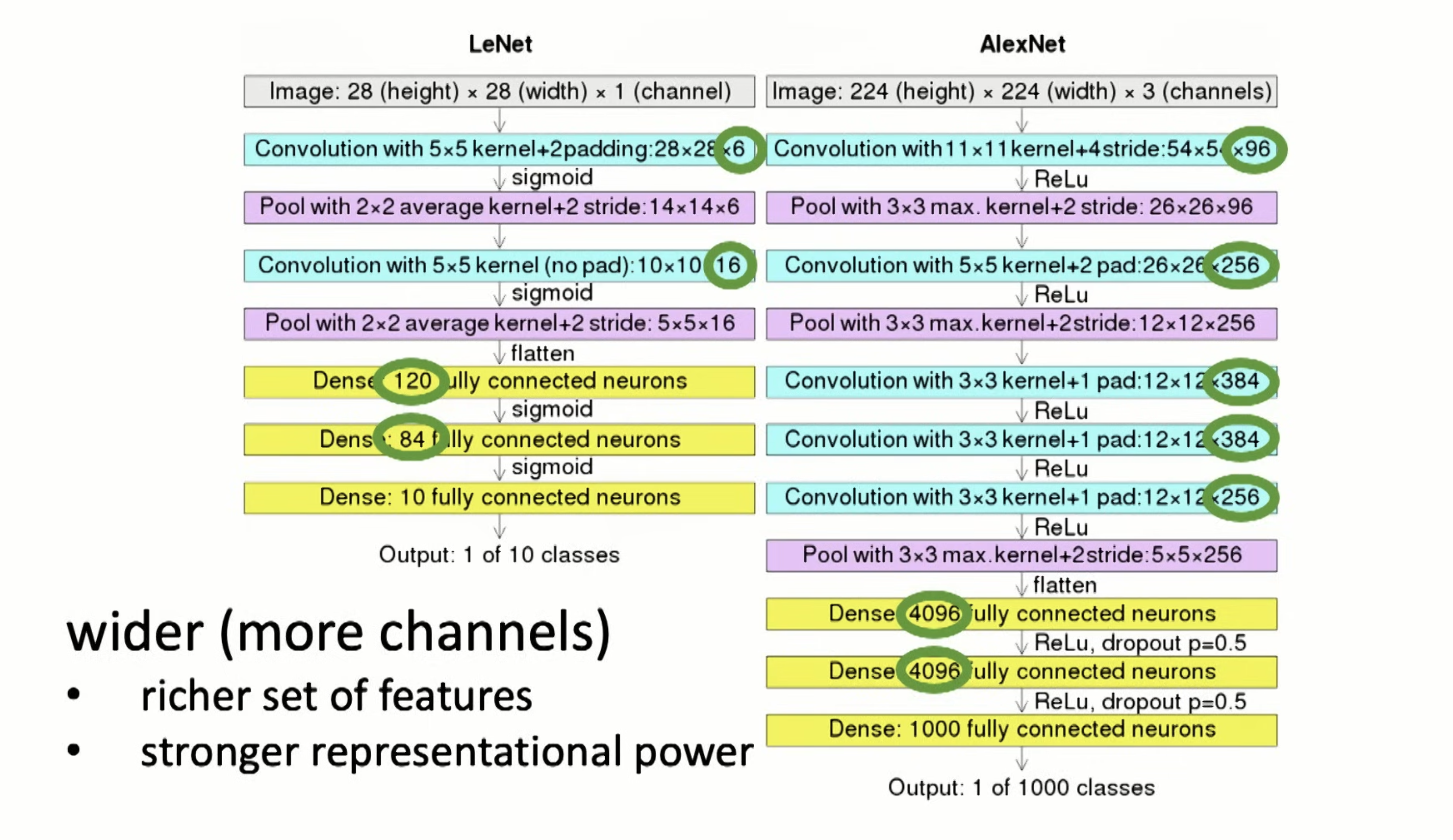 and used ReLU for better gradient prop. And used “dropout”
and used ReLU for better gradient prop. And used “dropout”
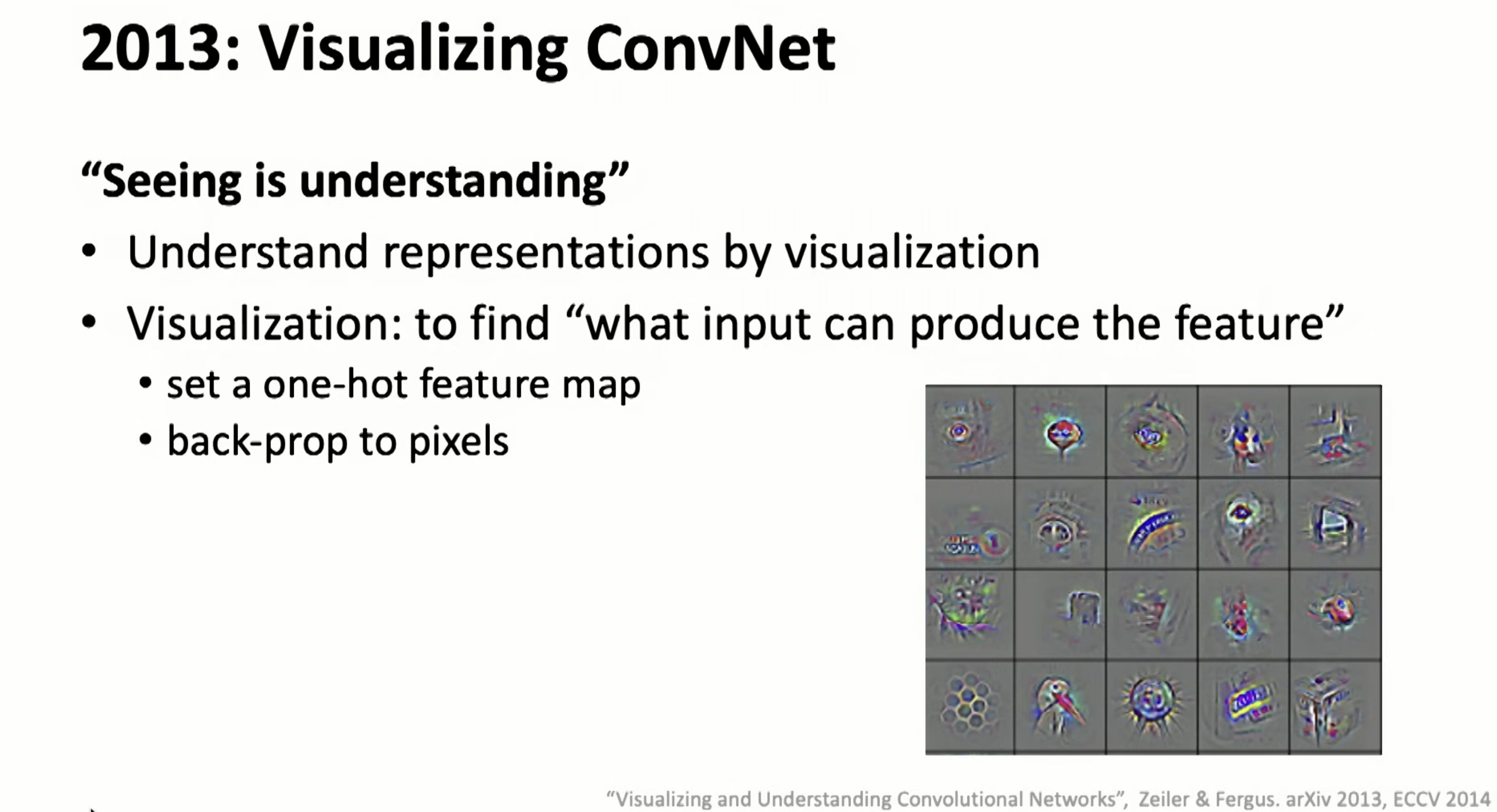
 Finally I understand how the visualization works– by back prop a one-hot feature map to pixels!!!
Finally I understand how the visualization works– by back prop a one-hot feature map to pixels!!!
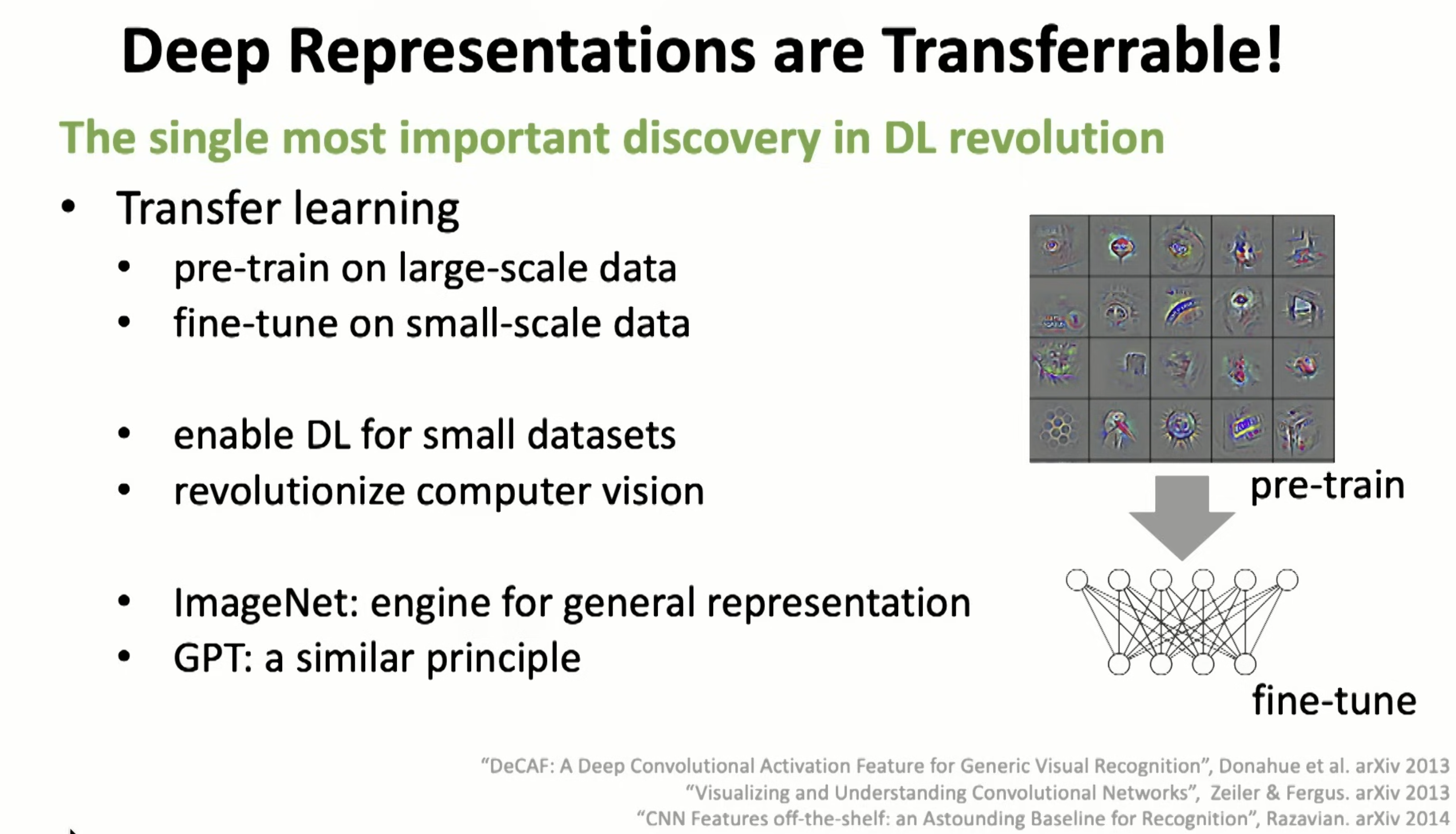
 Single most important finding, wow, didn’t think in this way before.
Single most important finding, wow, didn’t think in this way before.
 VGG in 2014, too deep to train
VGG in 2014, too deep to train
 Let’s see why from initilization
Let’s see why from initilization
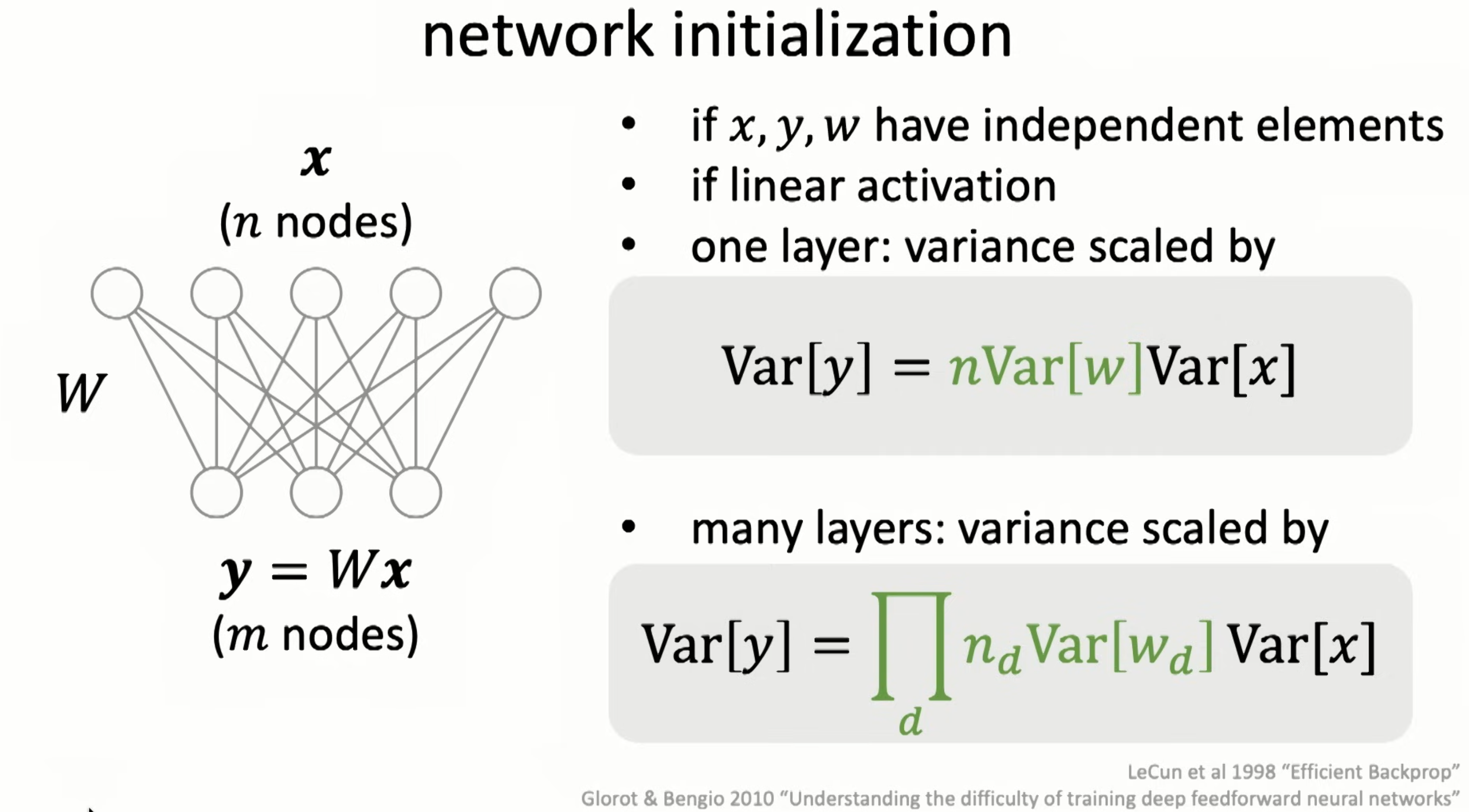 Vanishing gradients in backprop.
Vanishing gradients in backprop.
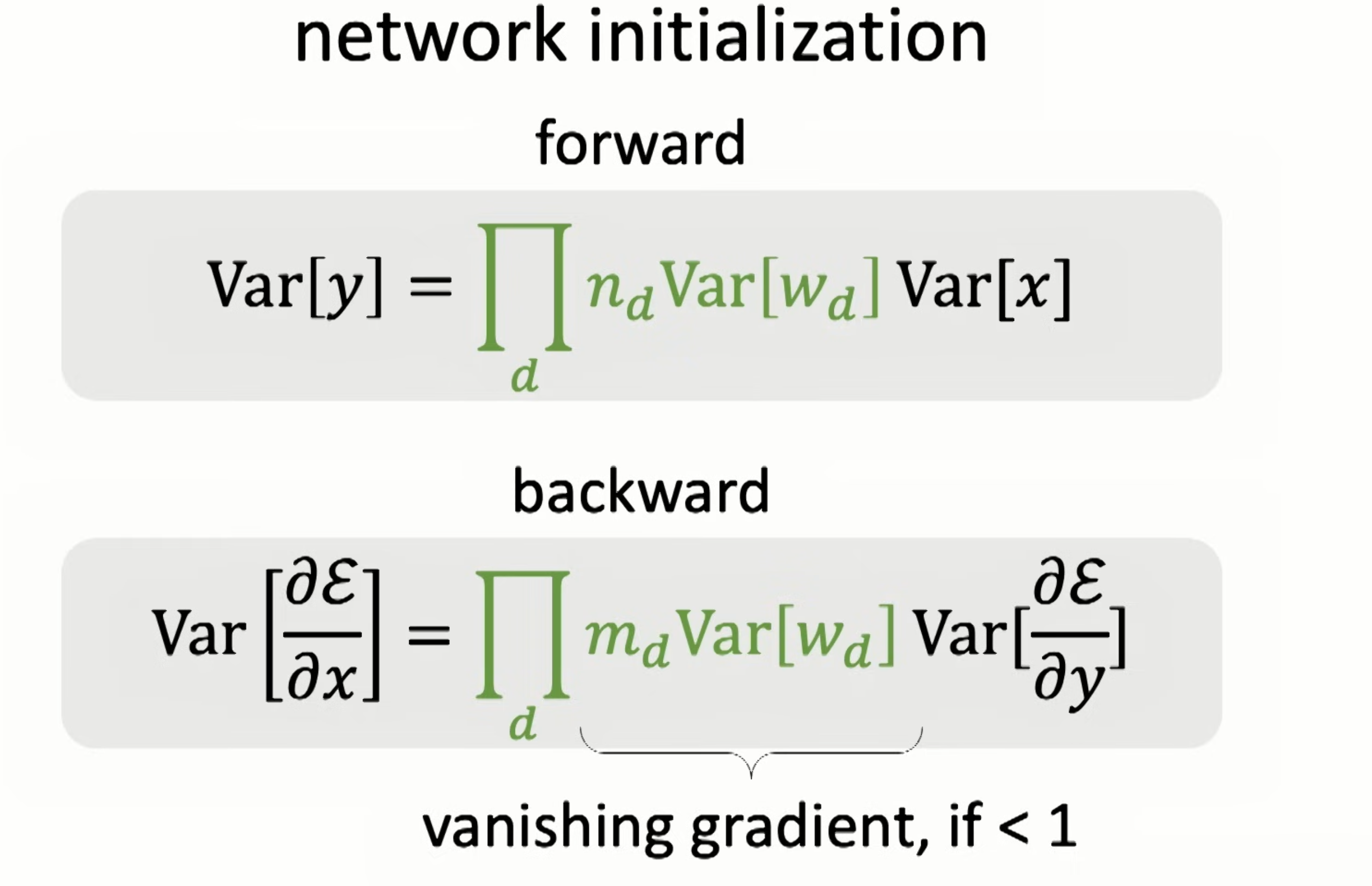
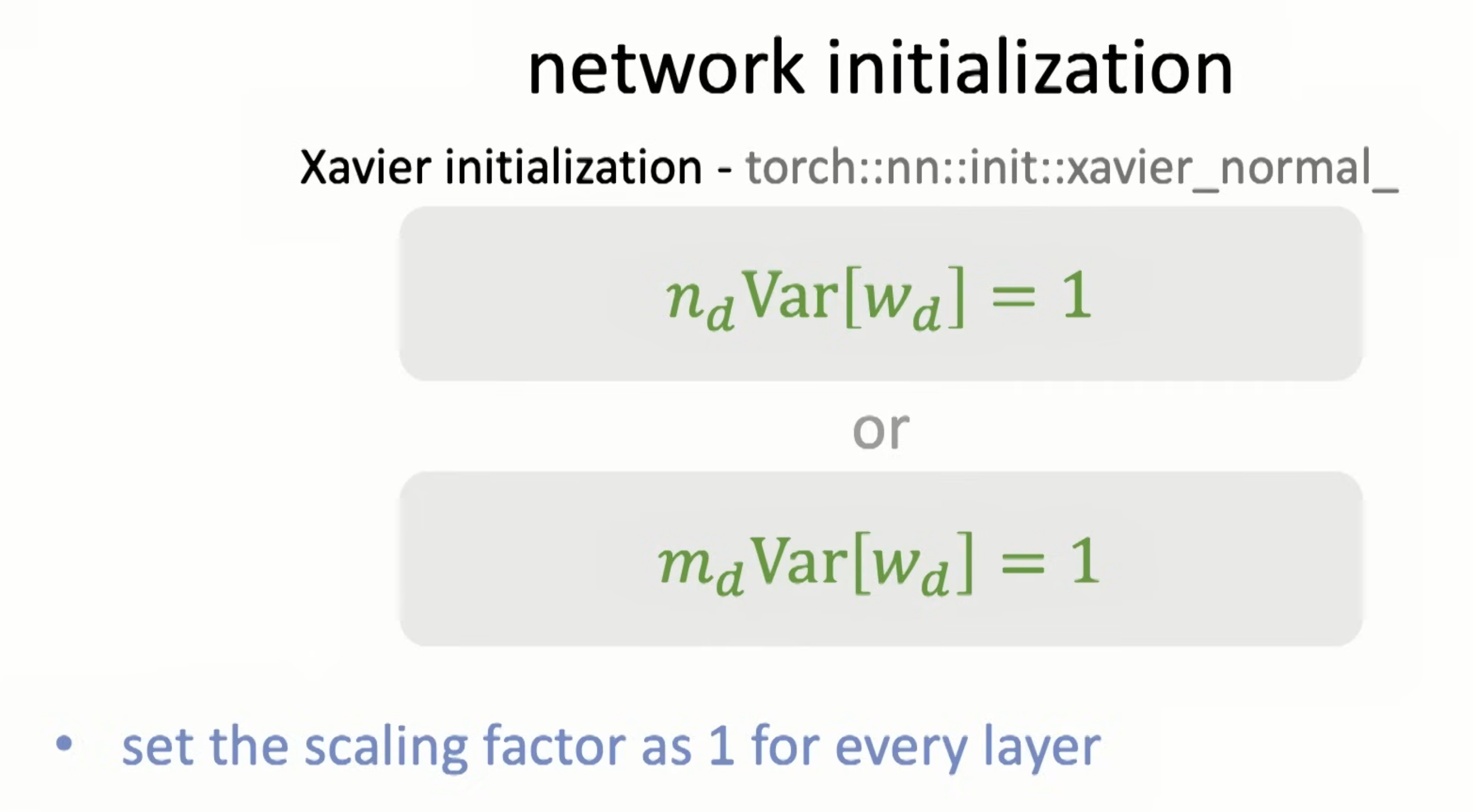
Two simple approaches to help w vanishing gradients.
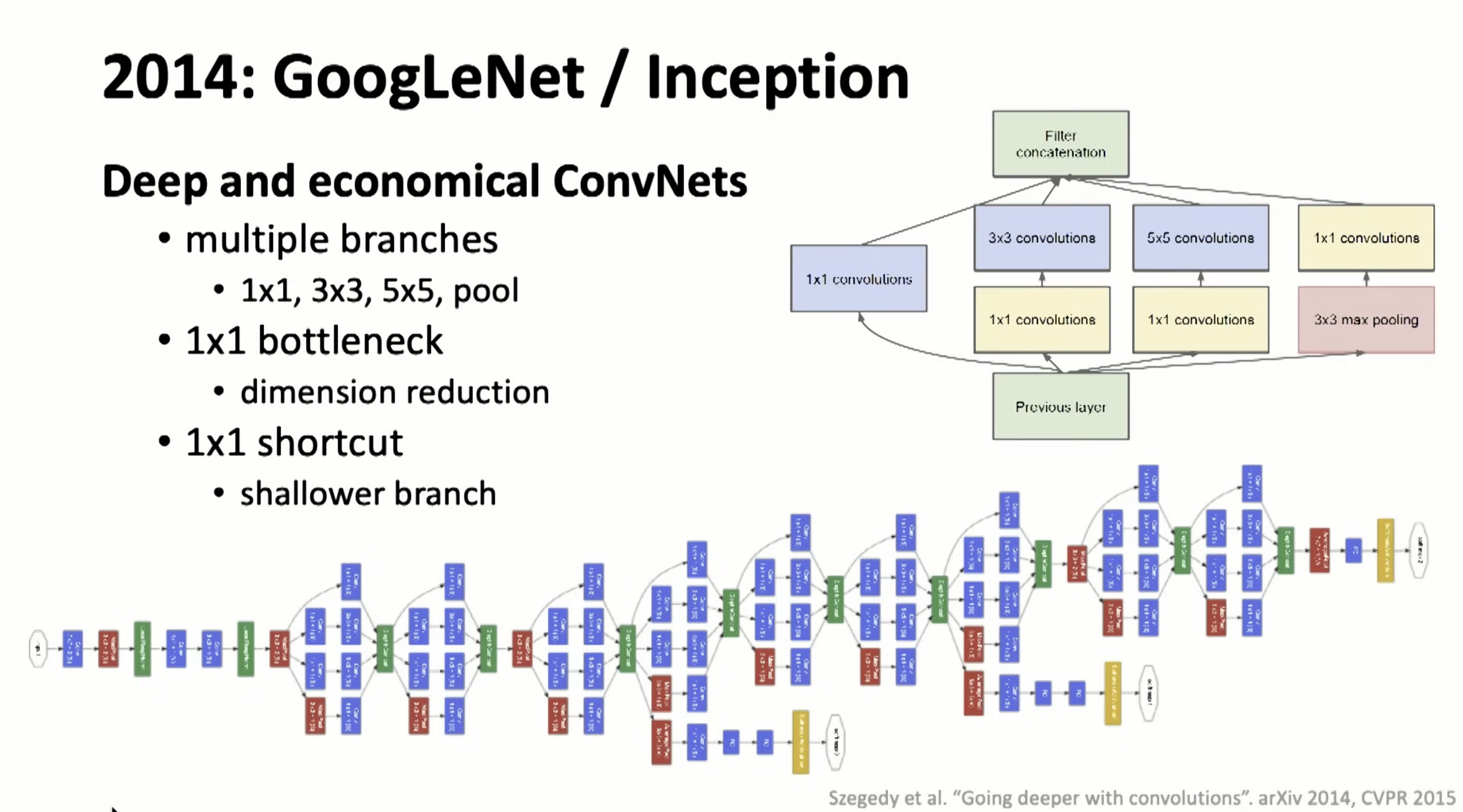
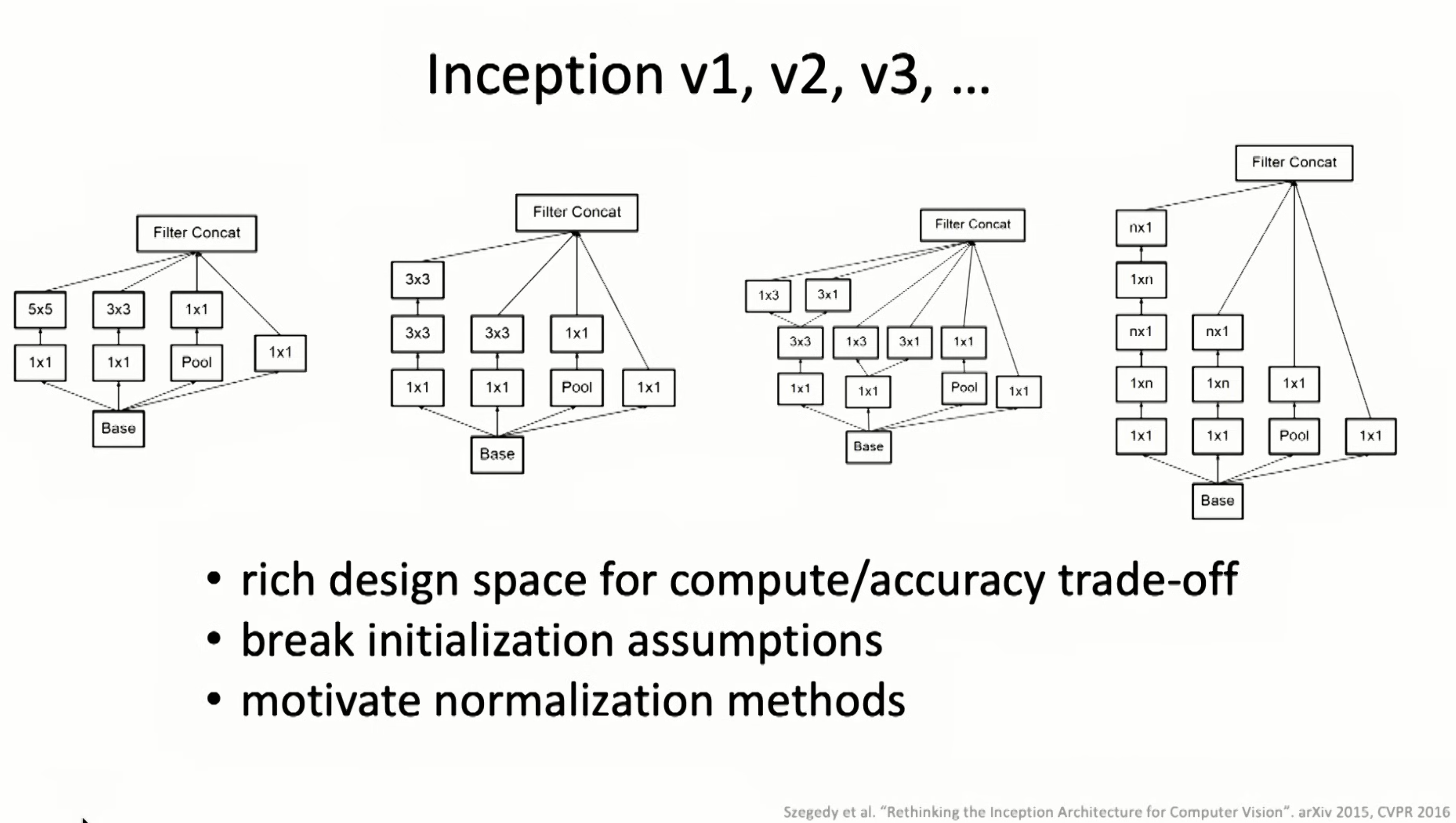
 Inception module was the first time I read paper about NN structures. and varies of inceptions were invented
Inception module was the first time I read paper about NN structures. and varies of inceptions were invented
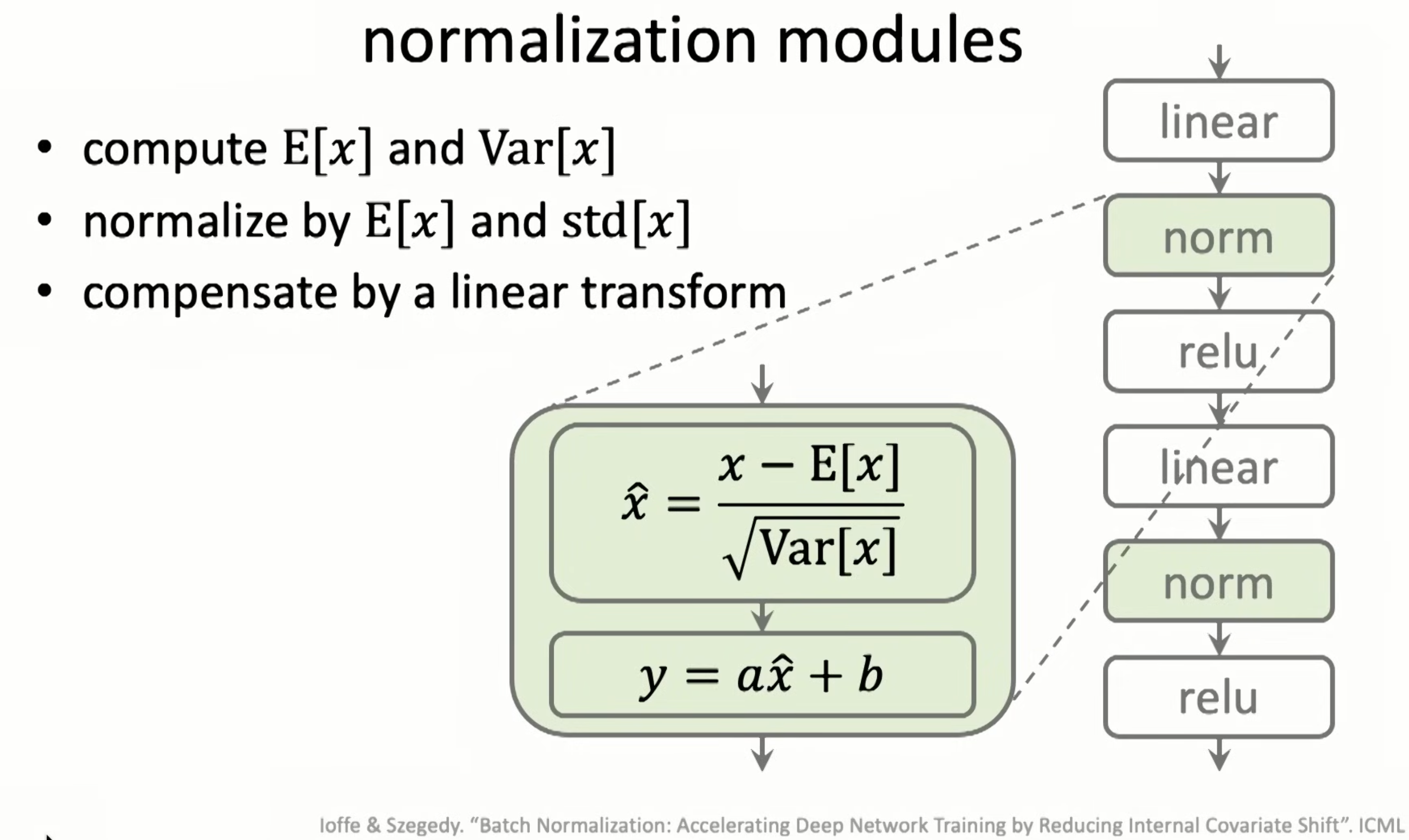
 Normalization in 2015.
Normalization in 2015.
 Batch Norm
Batch Norm
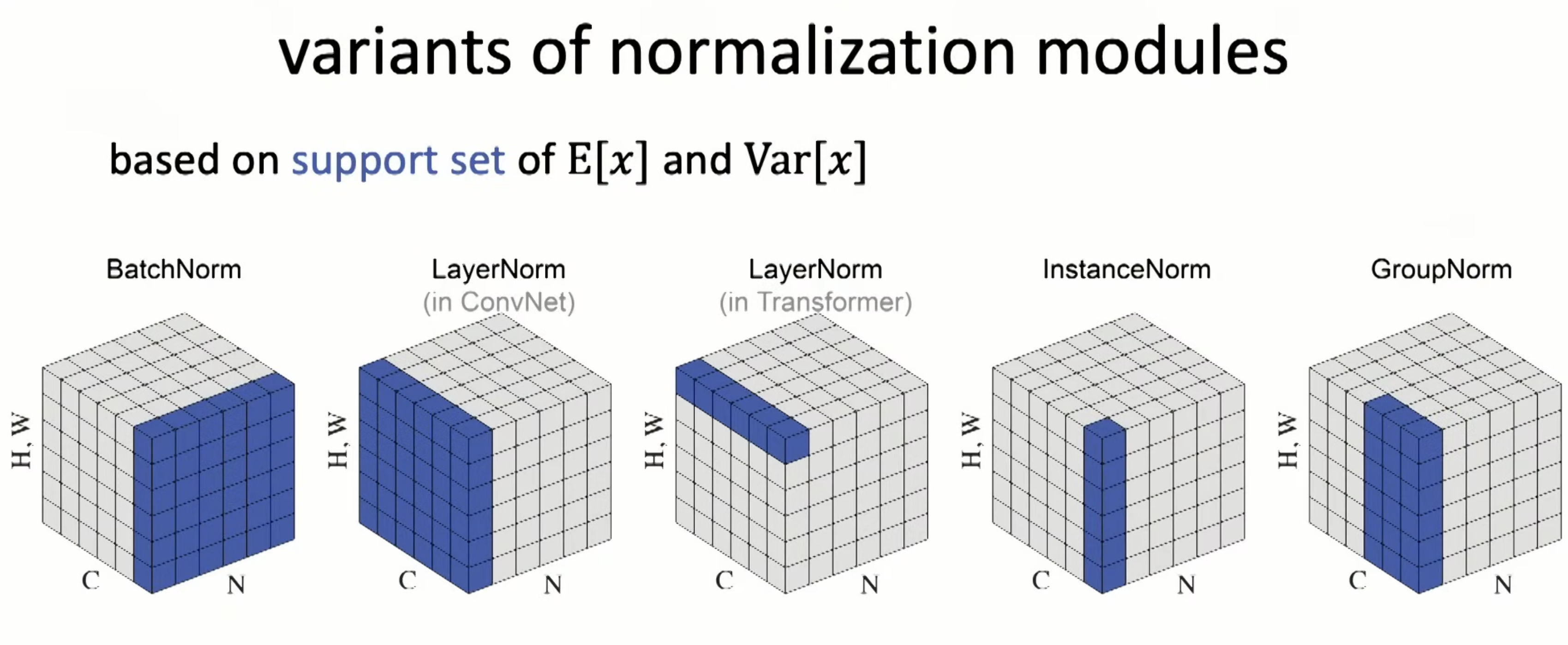
 Norm in different dimentions
Norm in different dimentions
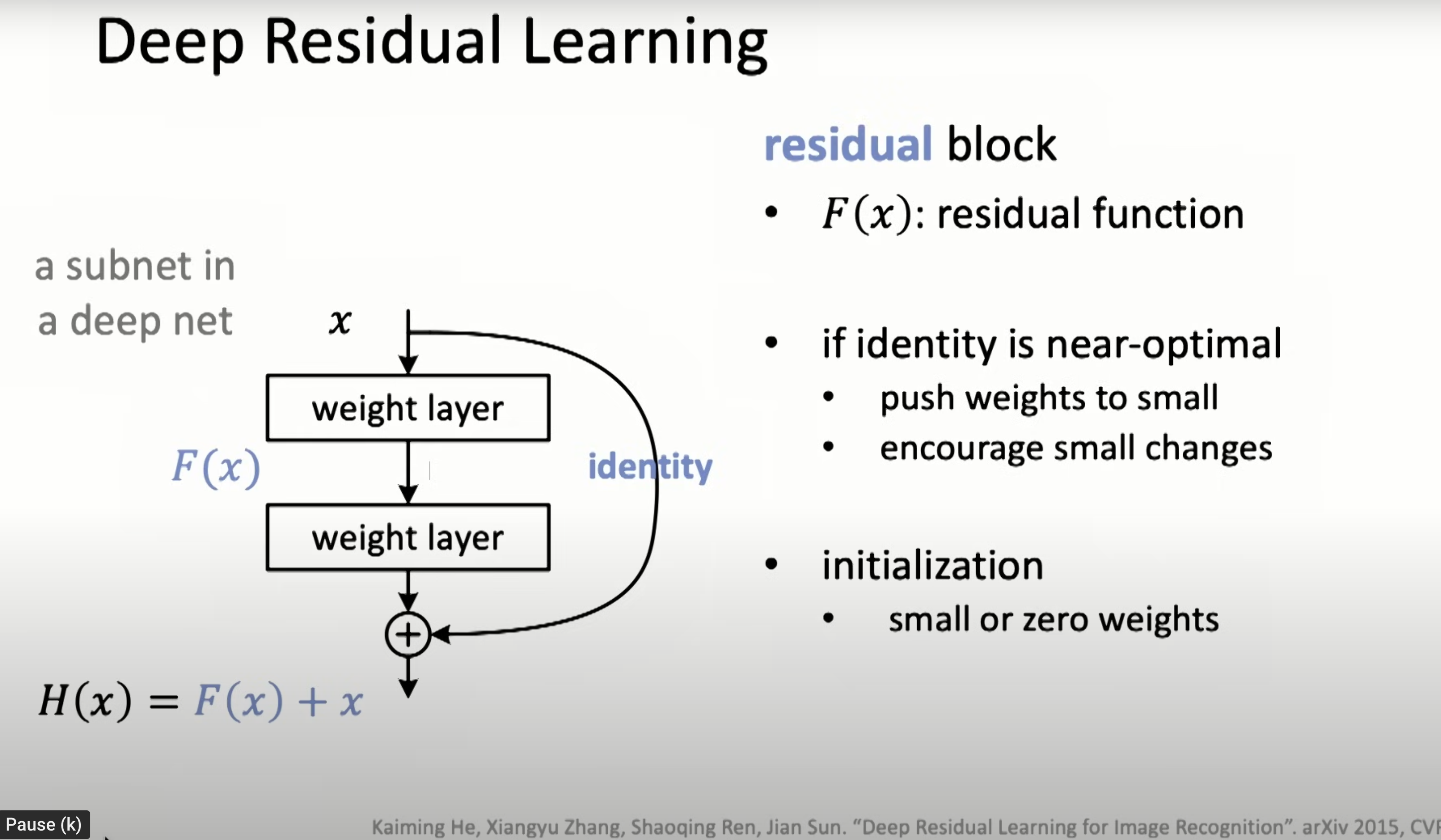
 Resnet in 2015
Resnet in 2015
 Can train much deeper nets by fitting the residual
Can train much deeper nets by fitting the residual
 All the key components of DL
All the key components of DL
 RNN is weight sharing in time
RNN is weight sharing in time
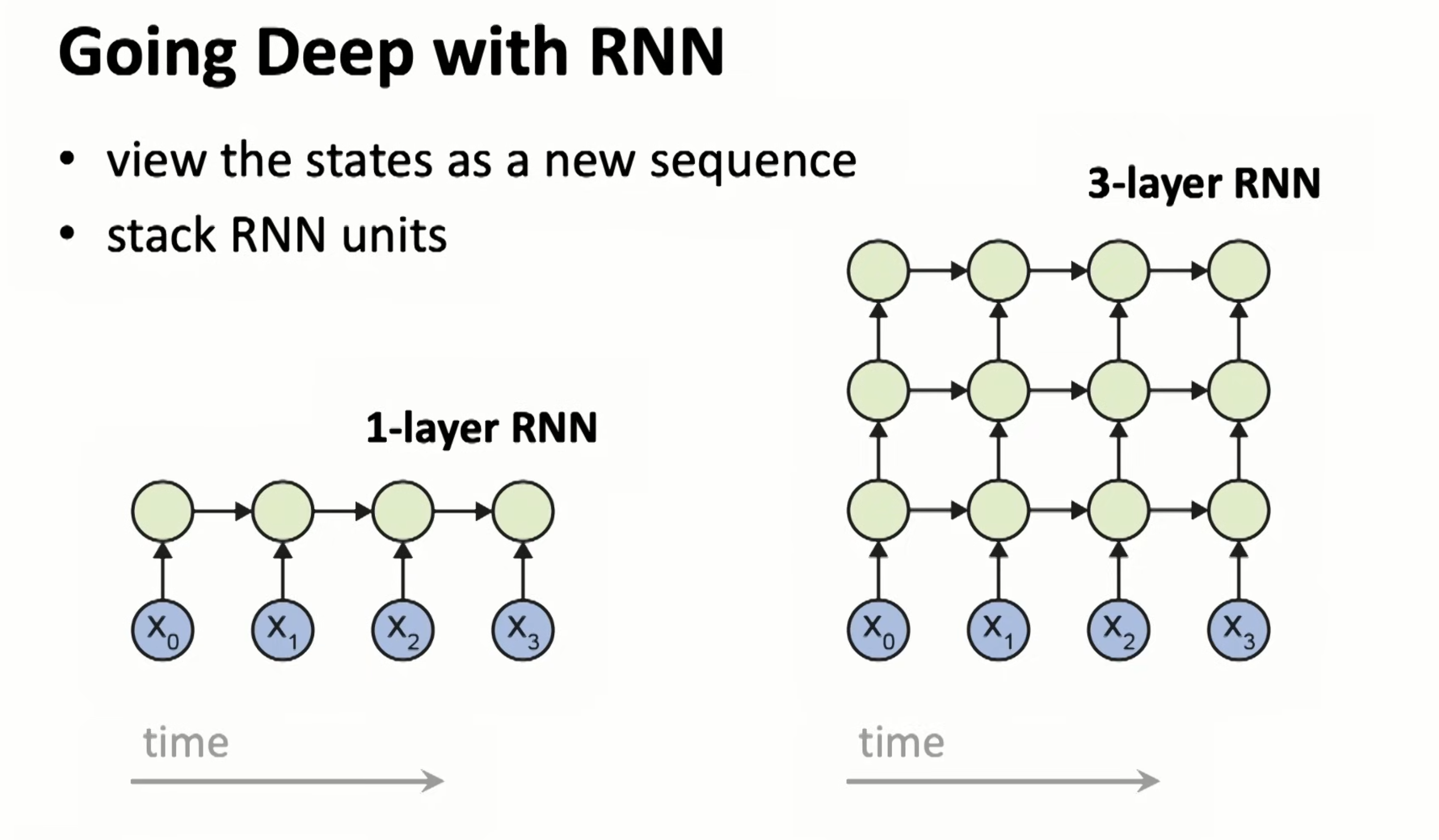
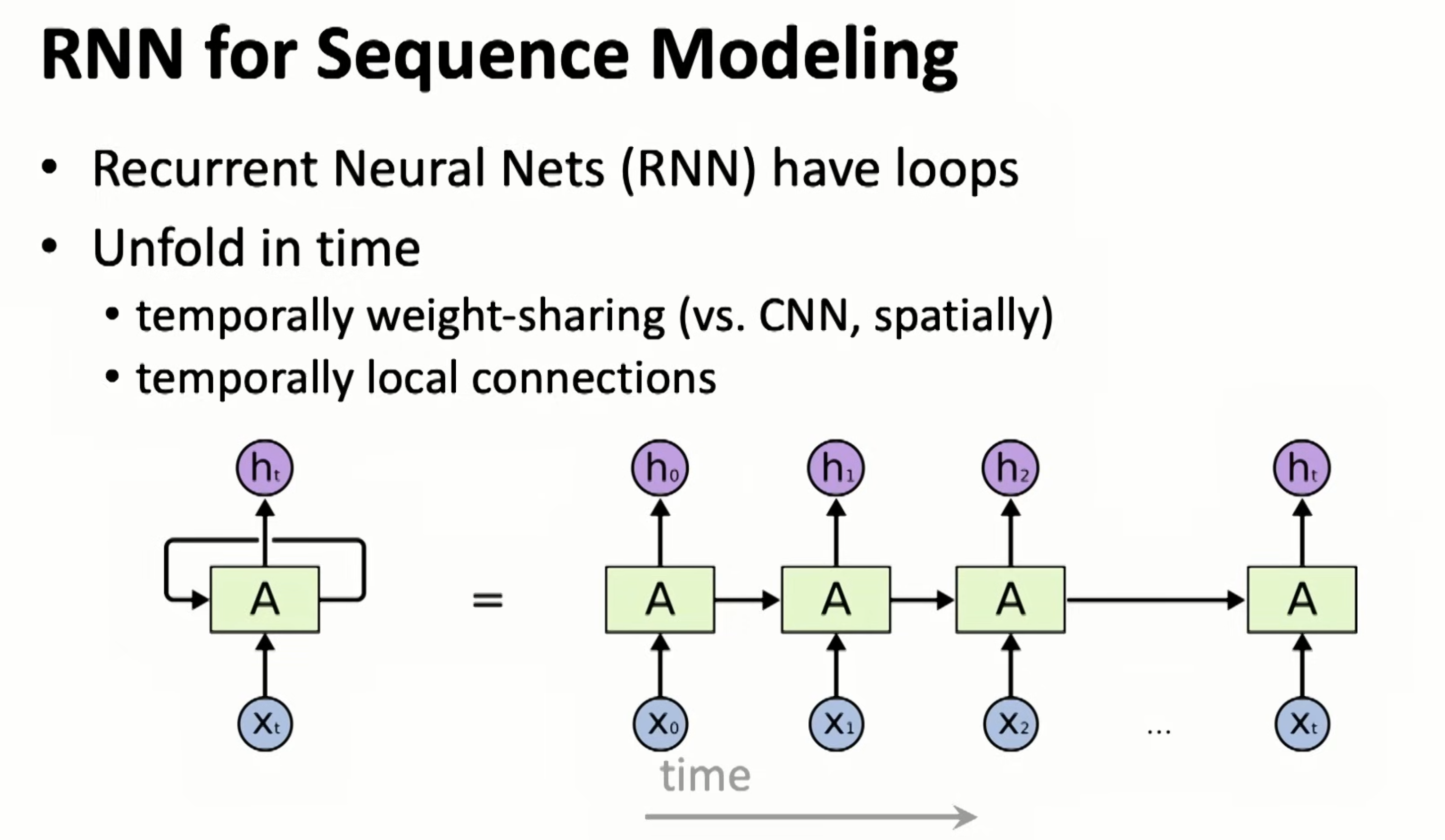 It can do deep too
It can do deep too
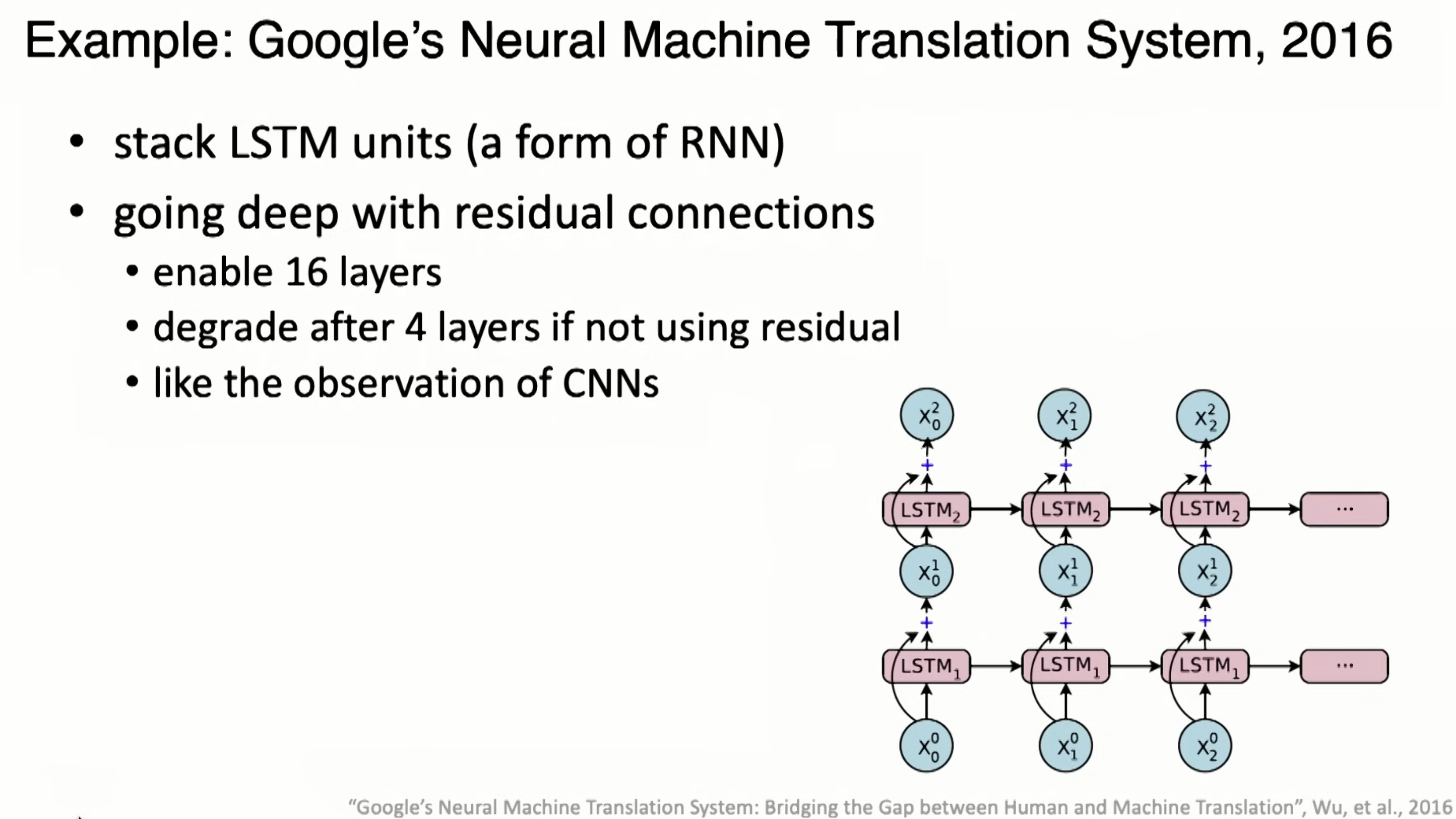
and Google Translate in 2016 is an example.
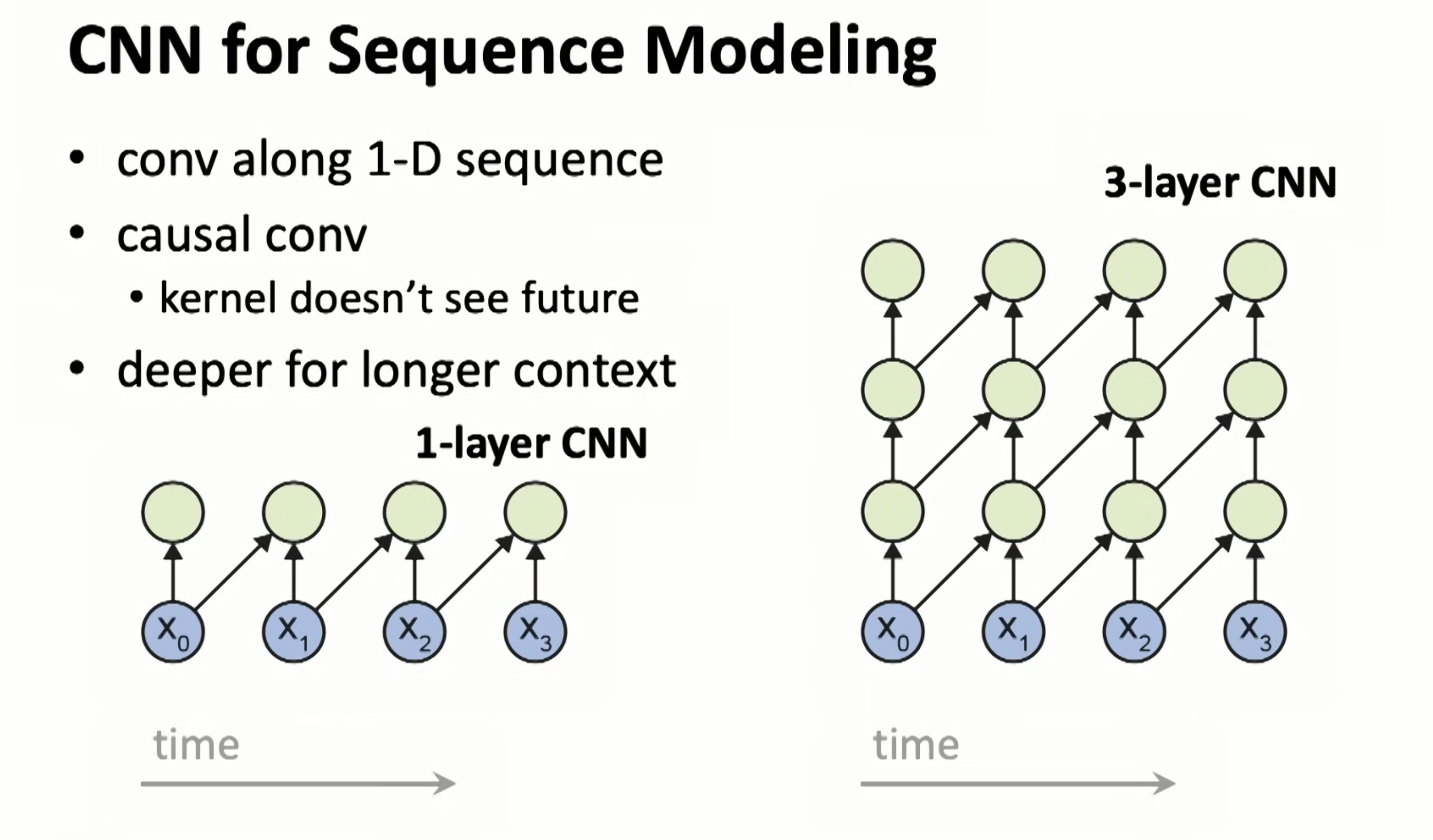
 Use CNN for sequence model, which is casual
Use CNN for sequence model, which is casual
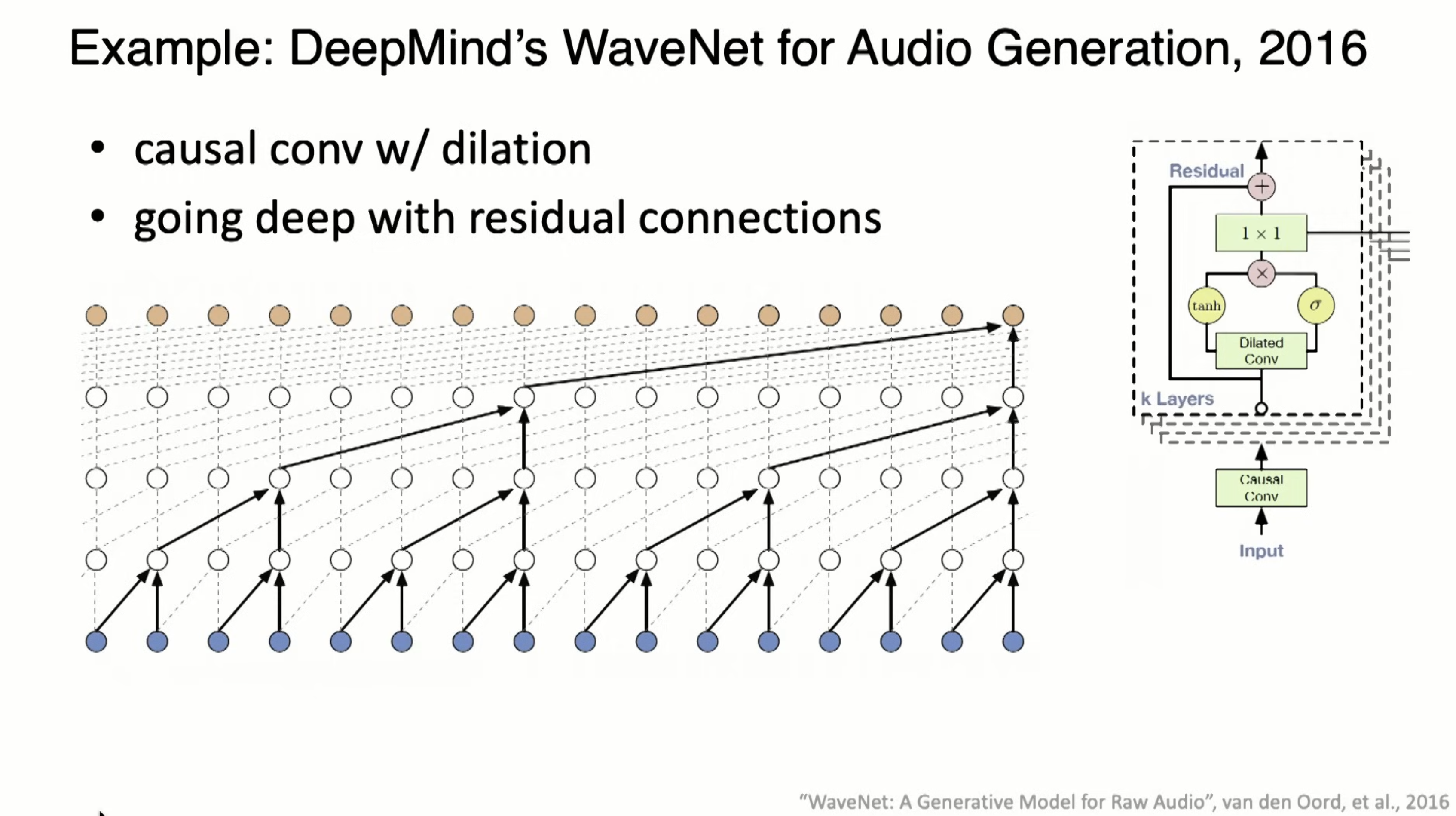
 WaveNet in 2016, used dilation, which is skip connections.
WaveNet in 2016, used dilation, which is skip connections.
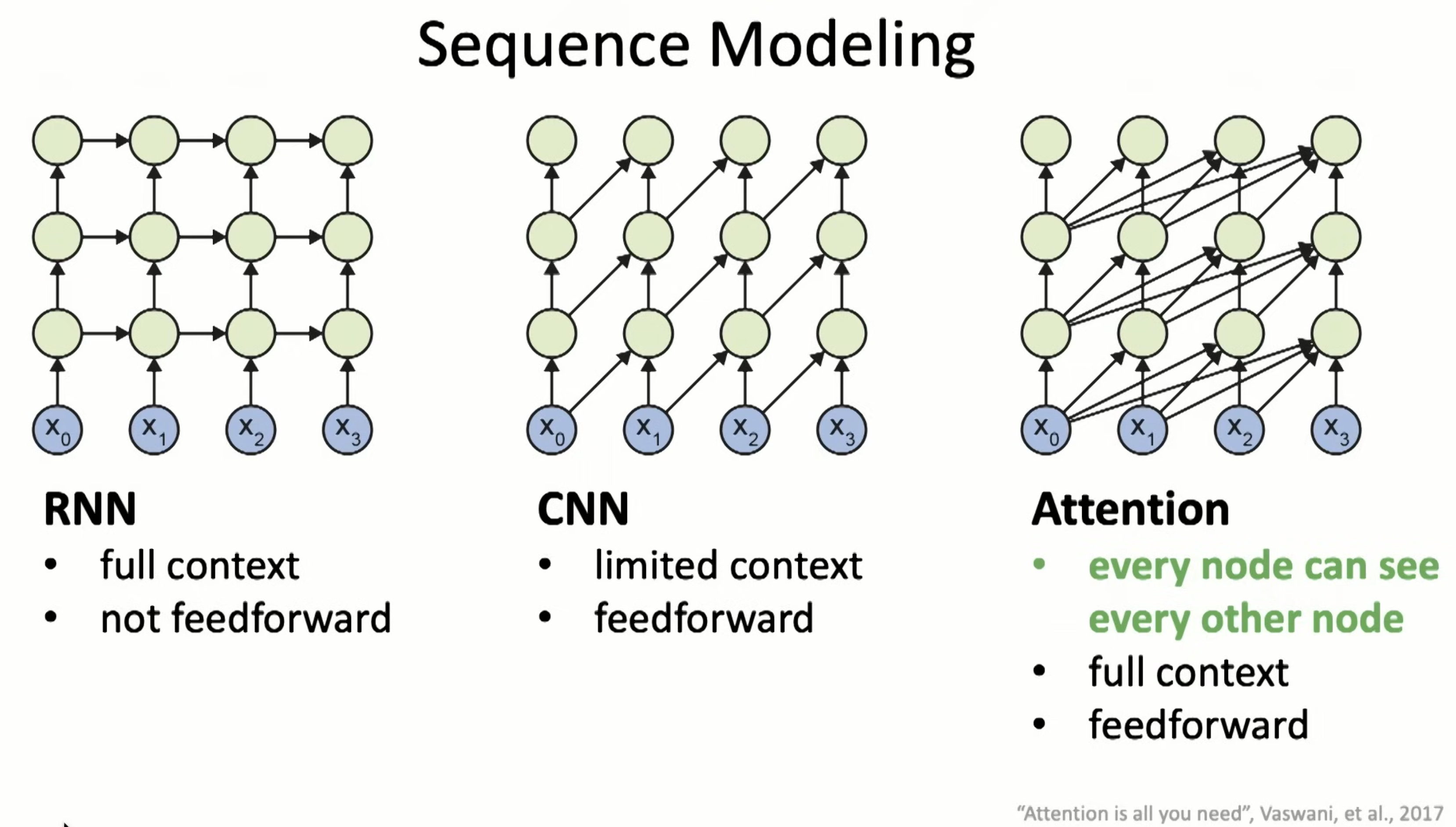
 Attention is combining both RNN and CNN for sequency models
Attention is combining both RNN and CNN for sequency models
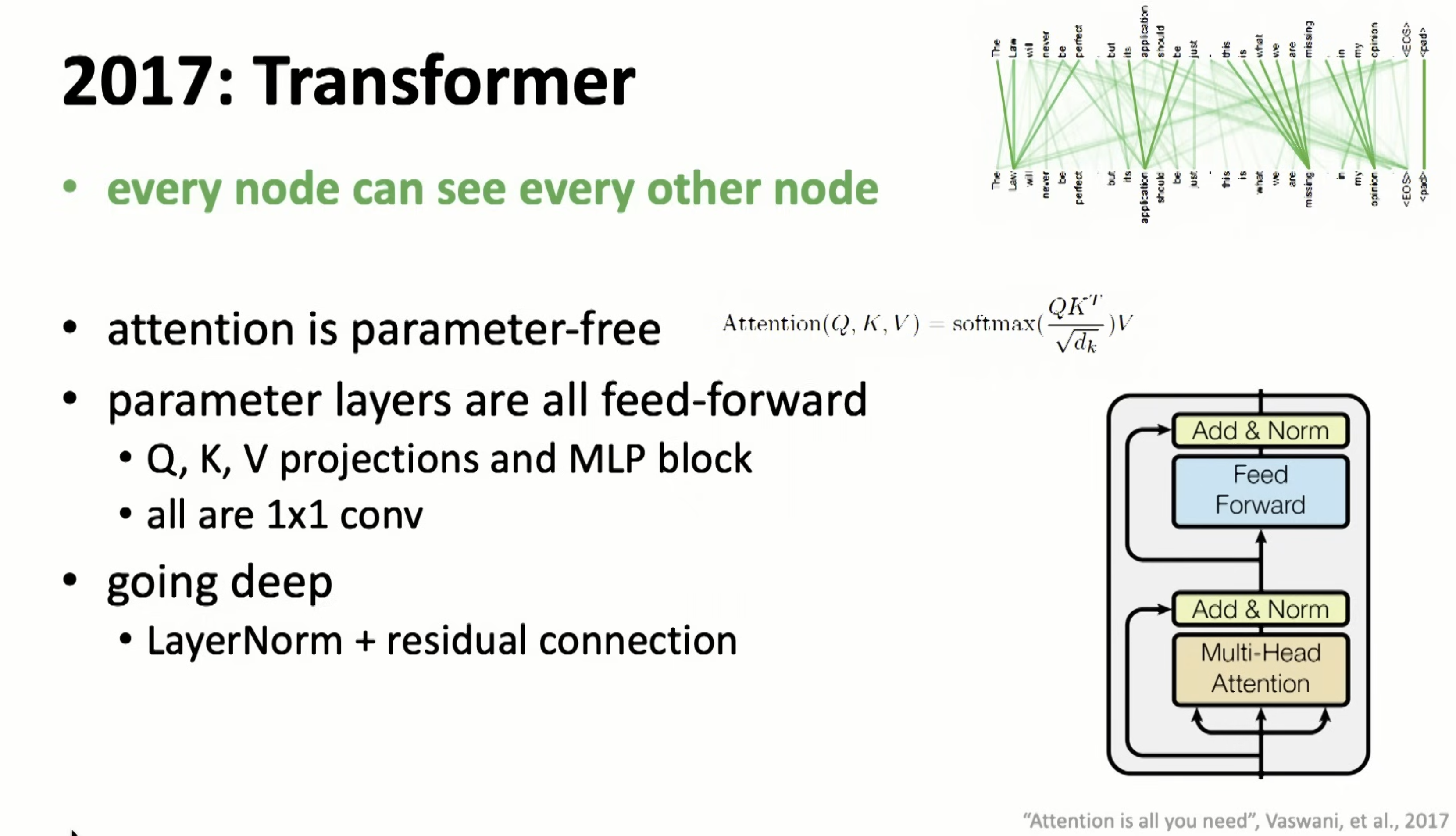
 Transformers in 2017
Transformers in 2017
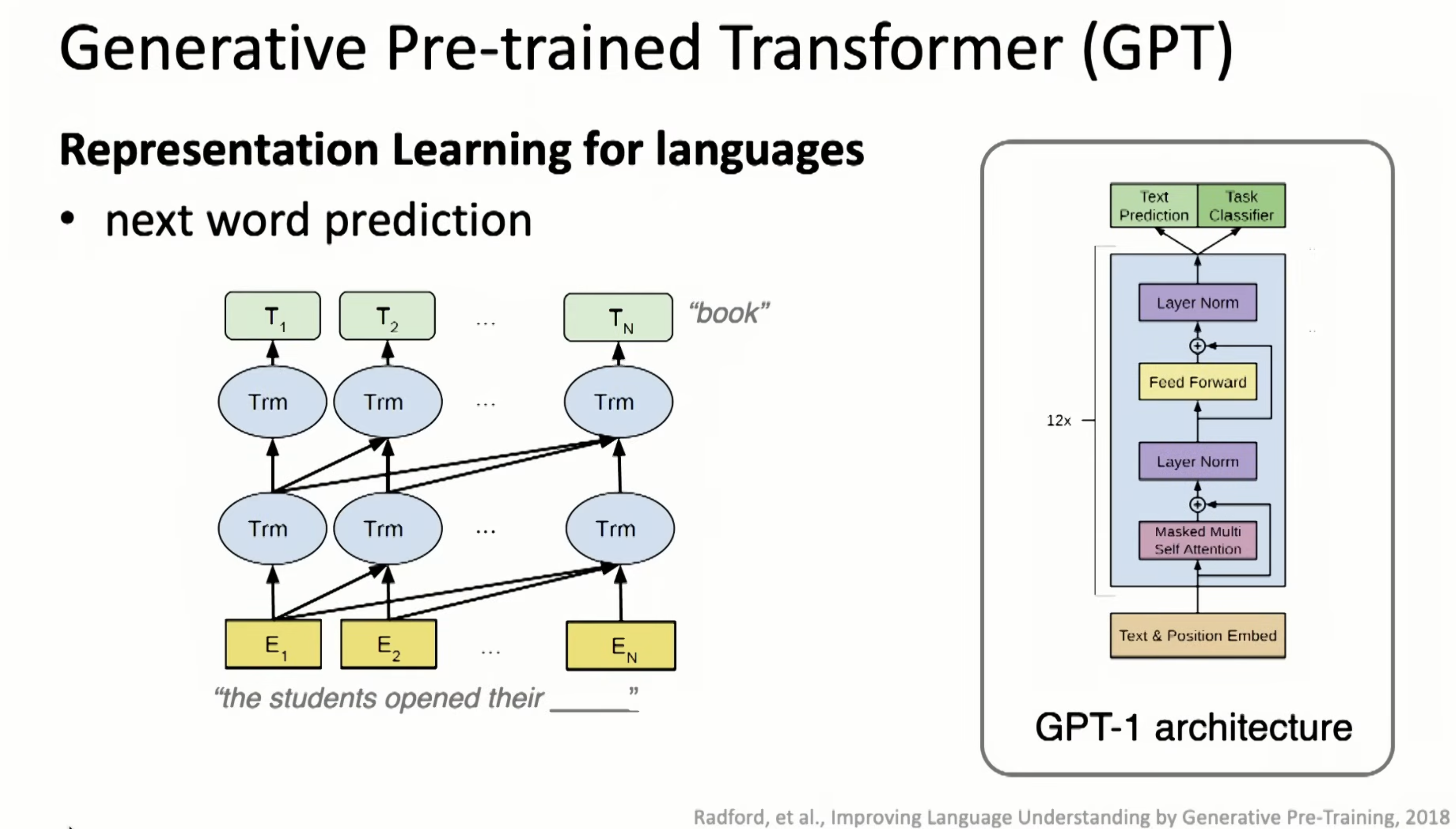
 Applied in NLP, we have GPT
Applied in NLP, we have GPT
 AlphaFold is applied to proteins
AlphaFold is applied to proteins
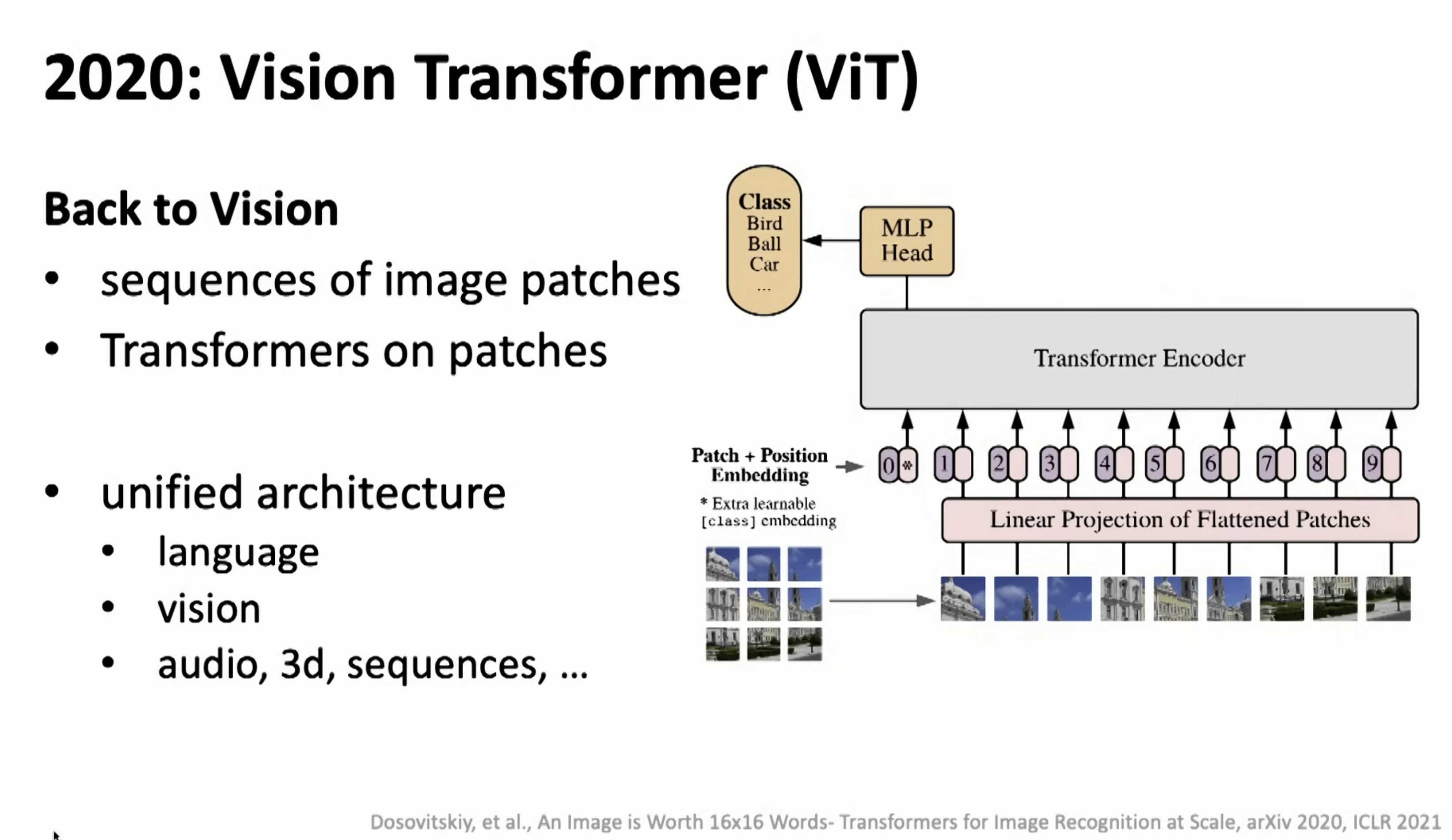
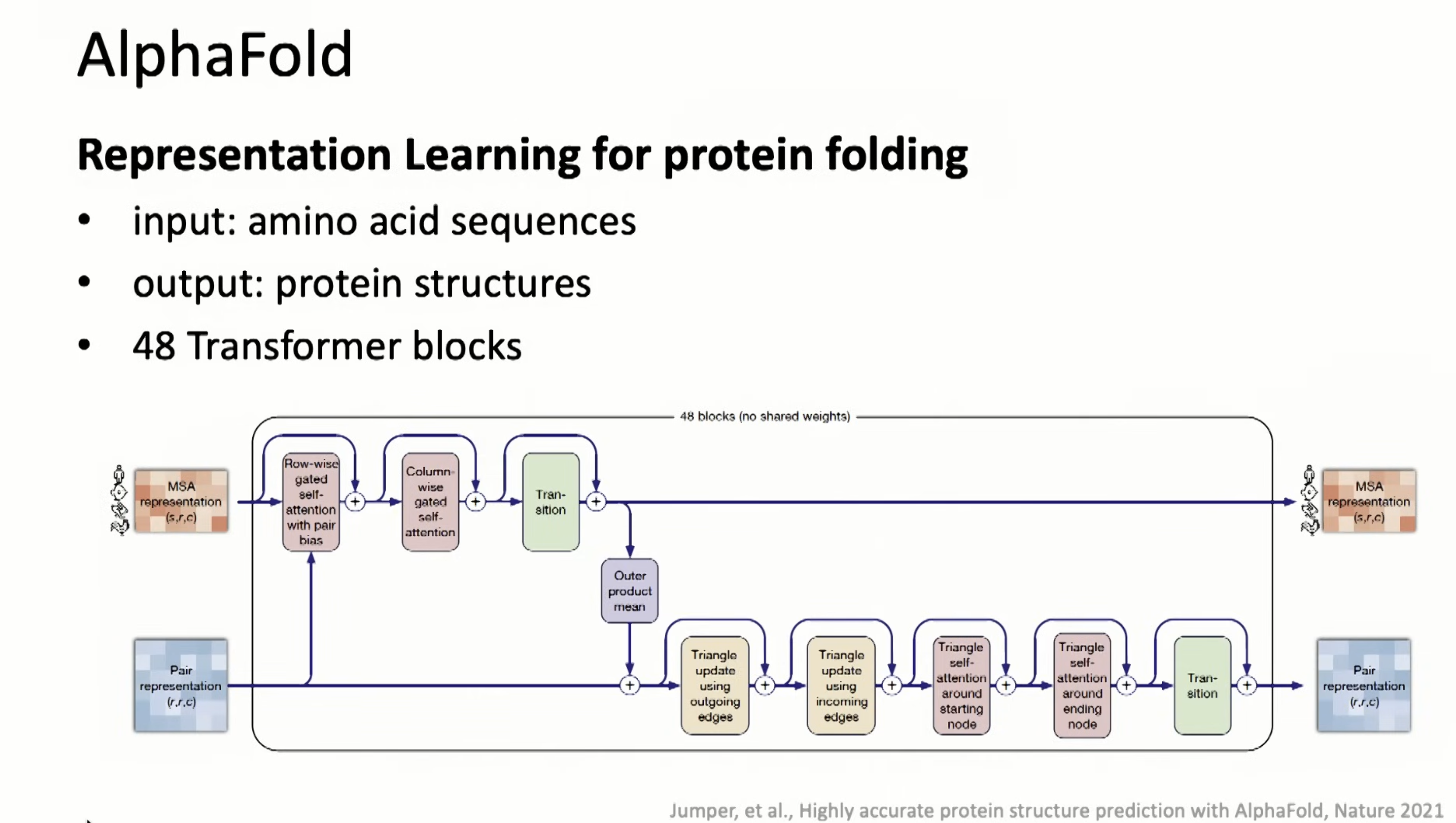 Applied to general CV/audio
Applied to general CV/audio
 Takeaways, representation and deep/how to go deep
Takeaways, representation and deep/how to go deep
