Andrej Karpathy-GPT from scratch
If there is one video you should watch about GPT, this is it. Karpathy’s dive deep on code level of explanation of GPT, it’s a bless to all GenAI engineers.
1 The naive tokenizer
This tokenizer just tokenize each words into characterss. Firstly let’s build the dictionary chars
chars = sorted(list(set(text)))
print(''.join(chars))
# !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
vocab_size = len(chars)
print(vocab_size)
# 65. The first char is `\n`
The encode and decode are simple map between chars and ints
# create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s]
decode = lambda l: ''.join([itos[i] for i in l])
print(encode("hii there"))
#[46, 47, 47, 1, 58, 46, 43, 56, 43]
print(decode(encode("hii there")))
# 'hii there'
2 Train and Target data
block_size is the length of context window
and each block_size+1 window can generate block_size pairs of inputs and targets
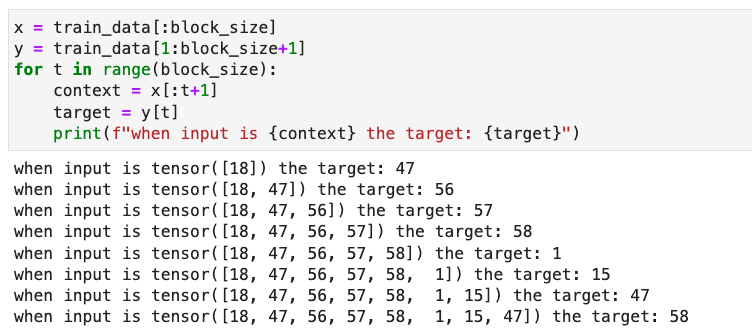
Here is how we generate the new tokens and concatenates to the origin ones.
$B$: Batch size
$T$: Time Dim/Seq length
$C$: Channel Dim/Dictionary size
def generate(self, idx, max_new_tokens):
# idx is (B, T)
# logits is (B, T, C)
for _ in range(max_new_tokens):
# get the predictions
logits, loss = self(idx) # [B,t,C], t is range from 1 to T
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution, and take 1 sample
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
The self(idx) in the code above will call forword which is defined as below:
def forward(self, idx, targets=None):
# idx and targets are both (B,T) tensor of integers
#self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)
logits = self.token_embedding_table(idx) # (B,T,C)
if targets is None:
loss = None
else:
B, T, C = logits.shape
#pytorch expects [minibatch, C,...] order for logits/targets
logits = logits.view(B*T, C)
targets = targets.view(B*T) # or .view(-1)
loss = F.cross_entropy(logits, targets)
return logits, loss
Now we can define the optimizer and starts the training
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(m.parameters(), lr=1e-3)
batch_size = 32
for steps in range(100):
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = m(xb, yb)
# zero the grad before each backprop.
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
print(loss.item()) #4.8
Please notice that there is no context reading when predict the next characters. Only ONE single character is used to predict the next character. This can be improved by introducing Transformers.
3 Math tricks for self-attention
To get the mask for self-attentions, here are the tricks. We simply average over the all the previous tokens (inclusive) for each token.
Firstly is the original defination
# We want x[b,t] = mean_{i<=t} x[b,i]
xbow = torch.zeros((B,T,C))
for b in range(B):
for t in range(T):
xprev = x[b,:t+1] # (t,C)
xbow[b,t] = torch.mean(xprev, 0) #(C)
This can be accelerated by Matrix with lower trian glization
# TxT triangle
wei = torch.tril(torch.ones(T, T))
# Averaged by sum of 1s per row
wei = wei / wei.sum(1, keepdim=True)
# wei.sum()-> (1+T)*T/2
# wei.sum(...)->[[1],[2],[3]...]
# wei.sum(0, ...)->[[..., 3, 2, 1]]
xbow2 = wei @ x # ((B,)T, T) @ (B, T, C) ----> (B, T, C)
torch.allclose(xbow, xbow2) # True
Softmax is a type of normalization, so we can replace 0 with -inf, which will be mapped to 0 by softmax.
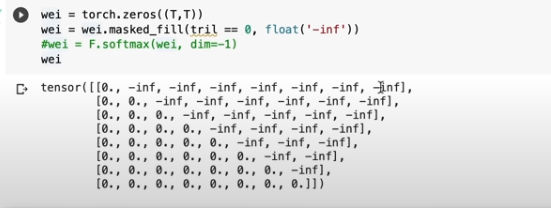
tril = torch.tril(torch.ones(T, T))
wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1) #row dir.
xbow3 = wei @ x
torch.allclose(xbow, xbow3) #True
4 Adding position embedding
But this time position embedding is same for every token, so it won’t help. and we also added a layer before the last logits, so the channel value is changed to n_embed now and a head layer will map from n_embed to vacab_size
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx and targets are both (B,T)
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
logits = self.lm_head(x) # (B,T,vocab_size)