Andrej Karpathy-GPT continues
Andrej took a sleep break and here is the second part of his intruct.
1 QKV
Here are the Andrej’s view on QKV matrix
$Q$: What the token is looking for
$K$: What the token contains
$V$: What the unique for current token to be aggregated by weights from Q and K
# self-attention!
B,T,C = 4,8,32 # batch, time, channels
x = torch.randn(B,T,C)
# let's see a single Head perform self-attention
head_size = 16
key = nn.Linear(C, head_size, bias=False)
query = nn.Linear(C, head_size, bias=False)
value = nn.Linear(C, head_size, bias=False)
k = key(x) # (B, T, 16)
q = query(x) # (B, T, 16)
wei = q @ k.transpose(-2, -1) # (B, T, 16) @ (B, 16, T) ---> (B, T, T)
tril = torch.tril(torch.ones(T, T))
#wei are not initialized as all zeros
#wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
# Add value matrix
v = value(x)
out = wei @ v
#out = wei @ x
out.shape # B,T,head_size

- Attention can be applied to any graph relations
- No position information
- No cross batch interactions
- encoder-w/o mask. decoder-w mask
- cross-attention, q/k/v from different source
- Use scale to control the variance of q@k (will be head_size^2 w/o scale), otherwise the softmax will be one-shot

2 Multi-heads, FFWD
Multi-heads attention
self.sa_head = Head(n_embed)
# n_embed = head_size * num_heads
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
FFWD is considered as each token to obsorb the cross-token information, so it’s added right after the attention, communication followed by computation.
Also add residue connection and layer norms for better optimization.
 Layer normal is applied BEFORE the SA and FFWD, which is different from the original paper. It’s called Pre-Norm formation
Layer normal is applied BEFORE the SA and FFWD, which is different from the original paper. It’s called Pre-Norm formation
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
Dropout was also added. One interesting point about dropout is you can considier it as ensamble of different NNs, each one is after random dropout.
3 Encoder
For translation job, the tokens can talk to each other as much as they want. So the encoder does NOT have mask and generate $K$ and $V$ for the decode. ($Q$ are still from decode input)

For GPT3, $n_{model}$ is n_embed, which is $n_{heads}*d_{head}$
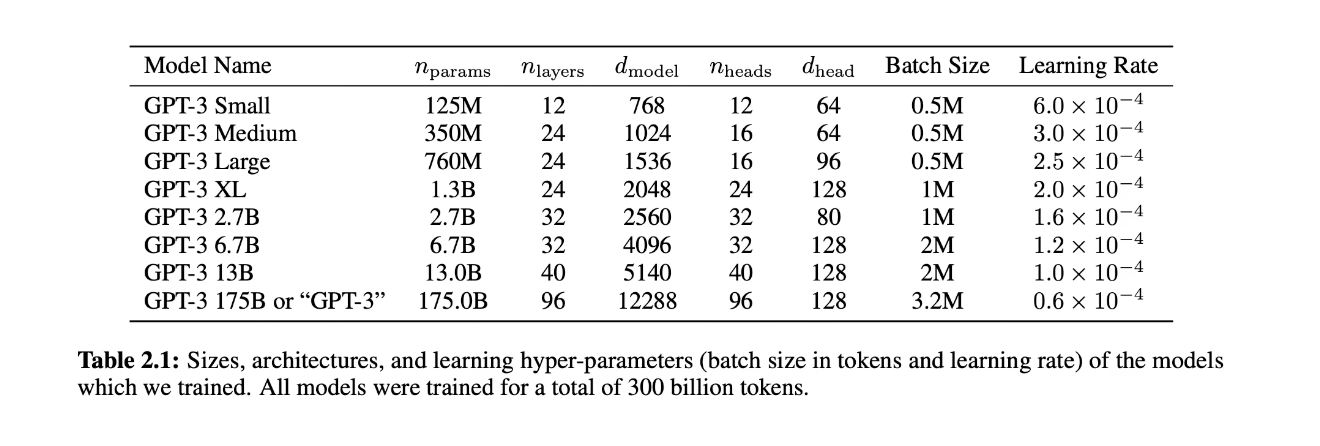
Size of parameters can be calculated by following code
model = BigramLanguageModel()
m = model.to(device)
# print the number of parameters in the model
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')