Andrej Karpathy-Tokenizer
Tokenizer sounds trivial but plays such an important role in LLM. It actually simply explains why LLM is not good at math arithmatics.
0 Unicode and UTF
Issues in LLM may track back to tokenizations.
 Mapping from character to numbers, ASCII is using 1 byte to map 128 most common used characters.
Mapping from character to numbers, ASCII is using 1 byte to map 128 most common used characters.
 Resource for Unicode here
Resource for Unicode here
Unicode converts characters, or grapheme according to this video, to code points. There are over 1M code points in the codespace and only 12% are used ( so lots of rooom to grow)
 UTF-8 manifesto here.
UTF-8 manifesto here.
UTF(Unicode Tranformation Format) converts unicode to bytes. UTF-8/16 converts to 1~4 bytes and UTF-32 to 4 bytes(directly converting same as ASCII to 1 byte). UTF-8 is most widely used.
 So we should use unicode aware string to get correct string length
So we should use unicode aware string to get correct string length
s="👍"
len(s) == 4
s=u"👍"
len(s) == 1
If raw byte sequences can be directly feed into LLM, it would be great improvment but still not available for now. (one paper)
1. BPE(Byte Pair Encoding)
The example from wiki is simple and clear. Repetitively replacing “byte pairs” with new code, so dictionary with new byte pairs keep growing and the encoding length keep decreasing.
- Given a list of integers, return a dictionary of counts of consecutive pairs.
#characters to bytes utf8 = "test".encode("utf-8") #bytes to integers #ids = list(utf8) ids = list(map(int,utf8)) # ord to get the unicode of cha ids[0] == ord('t') def get_stats(ids, counts=None): """ Example: [1, 2, 3, 1, 2] -> {(1, 2): 2, (2, 3): 1, (3, 1): 1} """ for pair in zip(ids, ids[1:]): # iterate consecutive elements counts[pair] = counts.get(pair, 0) + 1 return counts stats = get_stats(ids) ## stats a list of {(pair0, pair1):freq} ## max return keys for a map, based on the max value top_pair = max(stats, key=stats.get) #Get the character of this byte chr(top_pair[0]) - In the list of integers (ids), replace all consecutive occurrences of pair with the new integer token idx.
def merge(ids, pair, idx): """ Example: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx=4 -> [4, 3, 4] """ newids = [] i = 0 while i < len(ids): # if not at the very last position AND the pair matches, replace it if ids[i] == pair[0] and i < len(ids) - 1 and ids[i+1] == pair[1]: newids.append(idx) i += 2 else: newids.append(ids[i]) i += 1 return newids - Training for the tokenizer by iteratively merging the most common pairs to create new tokens.
# Remove 256 original chars num_merges = vocab_size - 256 # input text preprocessing text_bytes = text.encode("utf-8") # raw bytes ids = list(text_bytes) # list of integers in range 0..255 # merges = {} # (int, int) -> int vocab = {idx: bytes([idx]) for idx in range(256)} # int -> bytes for i in range(num_merges): # count up the number of times every consecutive pair appears stats = get_stats(ids) # find the pair with the highest count pair = max(stats, key=stats.get) # mint a new token: assign it the next available id idx = 256 + i # replace all occurrences of pair in ids with idx ids = merge(ids, pair, idx) # save the merge merges[pair] = idx vocab[idx] = vocab[pair[0]] + vocab[pair[1]] #End - Decode and Encode
Decode may not work for every bytes, soerror="replace"will catch the fell through bytesdef decode(self, ids): # given ids (list of integers), return Python string text_bytes = b"".join(self.vocab[idx] for idx in ids) text = text_bytes.decode("utf-8", errors="replace") return textEncoding needs to find the pair with the lowest merge index
def encode(self, text): # given a string text, return the token ids text_bytes = text.encode("utf-8") # raw bytes ids = list(text_bytes) # list of integers in range 0..255 while len(ids) >= 2: stats = get_stats(ids) pair = min(stats, key=lambda p: self.merges.get(p, float("inf"))) # subtle: if there are no more merges available, the key will # result in an inf for every single pair, and the min will be # just the first pair in the list, arbitrarily # we can detect this terminating case by a membership check if pair not in self.merges: break # nothing else can be merged anymore # otherwise let's merge the best pair (lowest merge index) idx = self.merges[pair] ids = merge(ids, pair, idx) return ids
2 OpenAI Implementations
- GPT-2 splitter
Copied from GPT-2 code
import regex as re ## \p{L} any letters ## \p{N} any numbers gpt2pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""") print(re.findall(gpt2pad, "Hello's World123 !! ")) ##['Hello', "'s", ' World', '123', ' ', ' !!', ' '] - tiktoken
The recommended library for tokenization. The regular express is similar to gpt-2 hereimport tiktoken # GPT-2 (does not merge spaces) enc = tiktoken.get_encoding("gpt2") print(enc.encode(" Hello World!!!")) ## [220, 220, 18435, 2159, 10185] # GPT-4 (merge spaces) enc = tiktoken.get_encoding("cl100k_base") print(enc.encode(" Hello World!!!")) ## [256, 22691, 4435, 12340] - Artifacts
encoder.json and vocab.bpe are downloaded from openai.with open('encoder.json', 'r') as f: encoder = json.load(f) # <--- ~equivalent to our "vocab" (chars->idx) ## encoder['!'] = 0 ## encoder['a'] = 64 with open('vocab.bpe', 'r', encoding="utf-8") as f: bpe_data = f.read() bpe_merges = [tuple(merge_str.split()) for merge_str in bpe_data.split('\n')[1:-1]] # ^---- ~equivalent to our "merges" (char, char)->new_idx ## bpe_merges[10000]=(' exper', 'iments') - Special tokens
There is ONE special token in GPT-2len(bpe_merges) == 5000 # 256 raw byte tokens. 50,000 merges. +1 special token len(encoder) == 50257 encoder['<|endoftext|>'] == 50256and there are 5 special tokens in GPT4 and 3 of them are FIM related. (Fill in the Middle, to be learned )
special_tokens = { ENDOFTEXT: 100257, FIM_PREFIX: 100258, FIM_MIDDLE: 100259, FIM_SUFFIX: 100260, ENDOFPROMPT: 100276, }
3 Sentencepiece
This is from Google used by Llama and Mixtral.
OpenAI’s tiktoken encodes to utf-8 and then BPEs bytes. sentencepiece BPEs the code points and optionally falls back to utf-8 bytes for rare code points (rarity is determined by character_coverage hyperparameter), which then get translated to byte tokens.
byte_fallback is one of the key parameters to play with when dealing with rare characters.
Tons of parameters, NOT favoured.
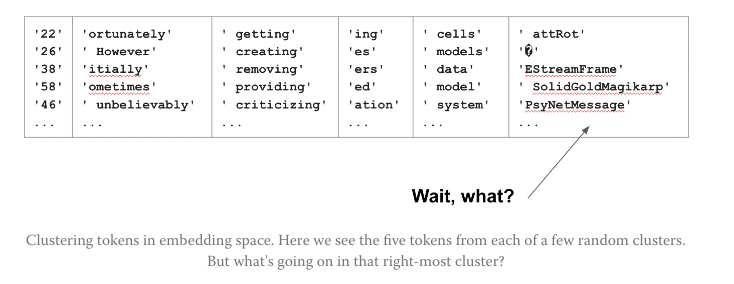
4 SolidGoldMagikarp
This blog explains this famous reddit username.