Andrej Karpathy-WaveNet
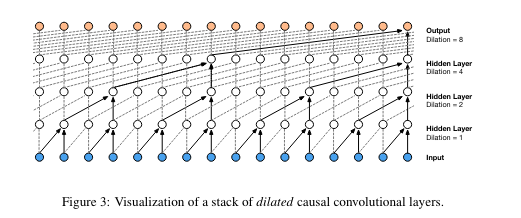
WaveNet published by Google in 2016, a wave generating DNN with dilated casual convolutions.
1 Torchify the code
- BN gives error when in training mode when only gives a single input
- Matrix multiplication only happens in the last dimention
res = torch.randn(b, x, y, z, 80) @ torch.randn(80,200) res.shape == [b, x, y, z, 200] - Explicit cat torch
# want (4, 4, 20) where consecutive 10-d vectors get concatenated e = torch.randn(4, 8, 10) explicit = torch.cat([e[:, ::2, :], e[:, 1::2, :]], dim=2) explicit.shape == [4, 4, 20] ## Implicit ## x = x.view(B, T//n, C*n) - BatchNorm for 2+ Dim data
def __call__(self, x): # calculate the forward pass if self.training: if x.ndim == 2: dim = 0 elif x.ndim == 3: dim = (0,1) #Average over 0 and 1 dim xmean = x.mean(dim, keepdim=True) # batch mean xvar = x.var(dim, keepdim=True) # batch variance - Torch batchnorm1d expected input to be (B,C) or (B, C, L), but code above expect (B, C), or (B, L, C)

- Adding Batch dim
Xtr[7].shape == [8] Xtr[[7]].shape == [1, 8]2 Hierarchical layers (Dilated CNN)
- Convolution is a “for loop”, which allows us to forward Linear layers efficiently over space
# hierarchical network n_embd = 24 # the dimensionality of the character embedding vectors n_hidden = 128 # the number of neurons in the hidden layer of the MLP model = Sequential([ Embedding(vocab_size, n_embd), FlattenConsecutive(2), Linear(n_embd * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(), FlattenConsecutive(2), Linear(n_hidden*2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(), FlattenConsecutive(2), Linear(n_hidden*2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(), Linear(n_hidden, vocab_size), ])