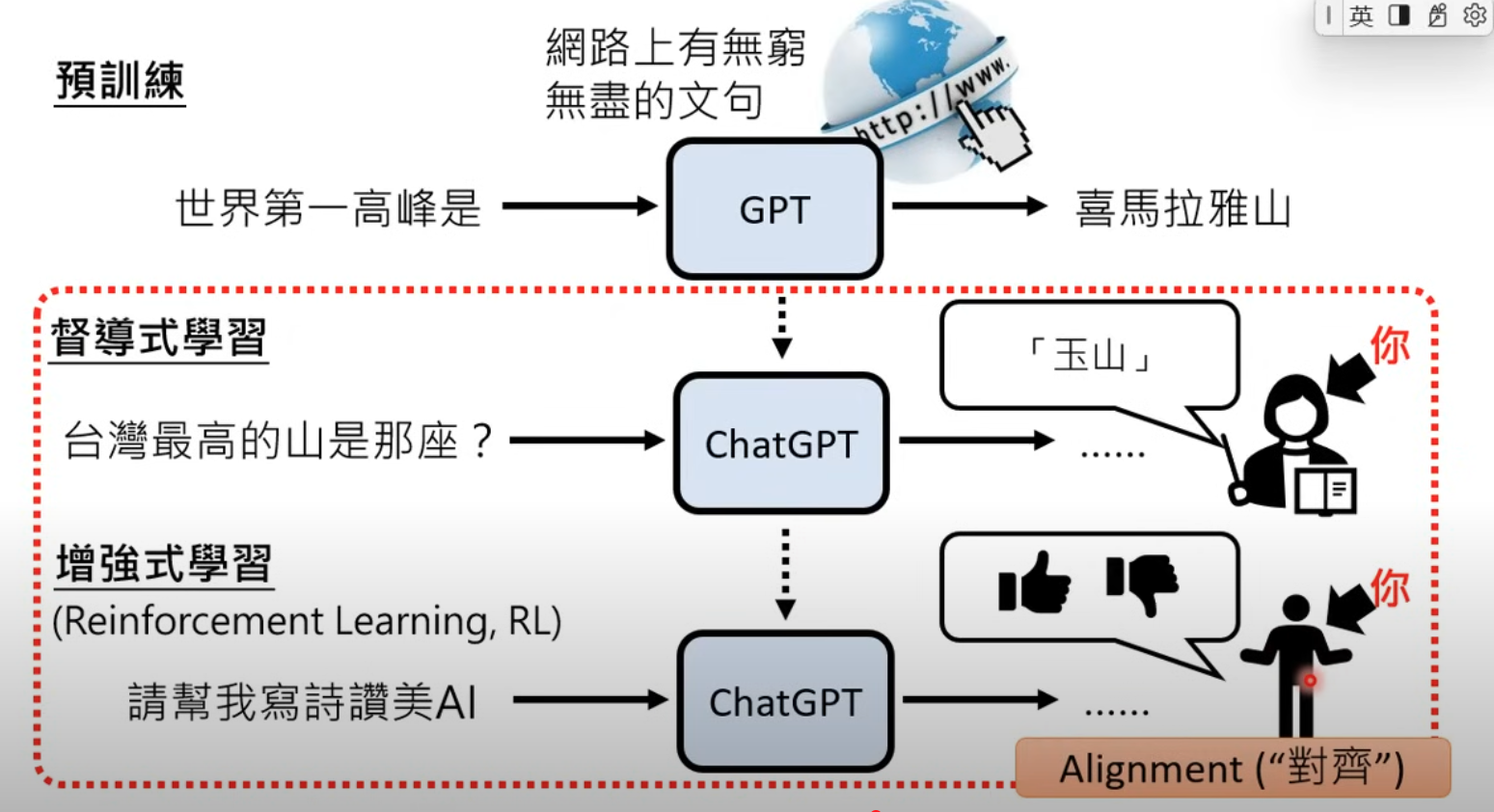
LLM overview in 2024
- Why SFT is before RLHF
- RLHF need basic capability from the model.
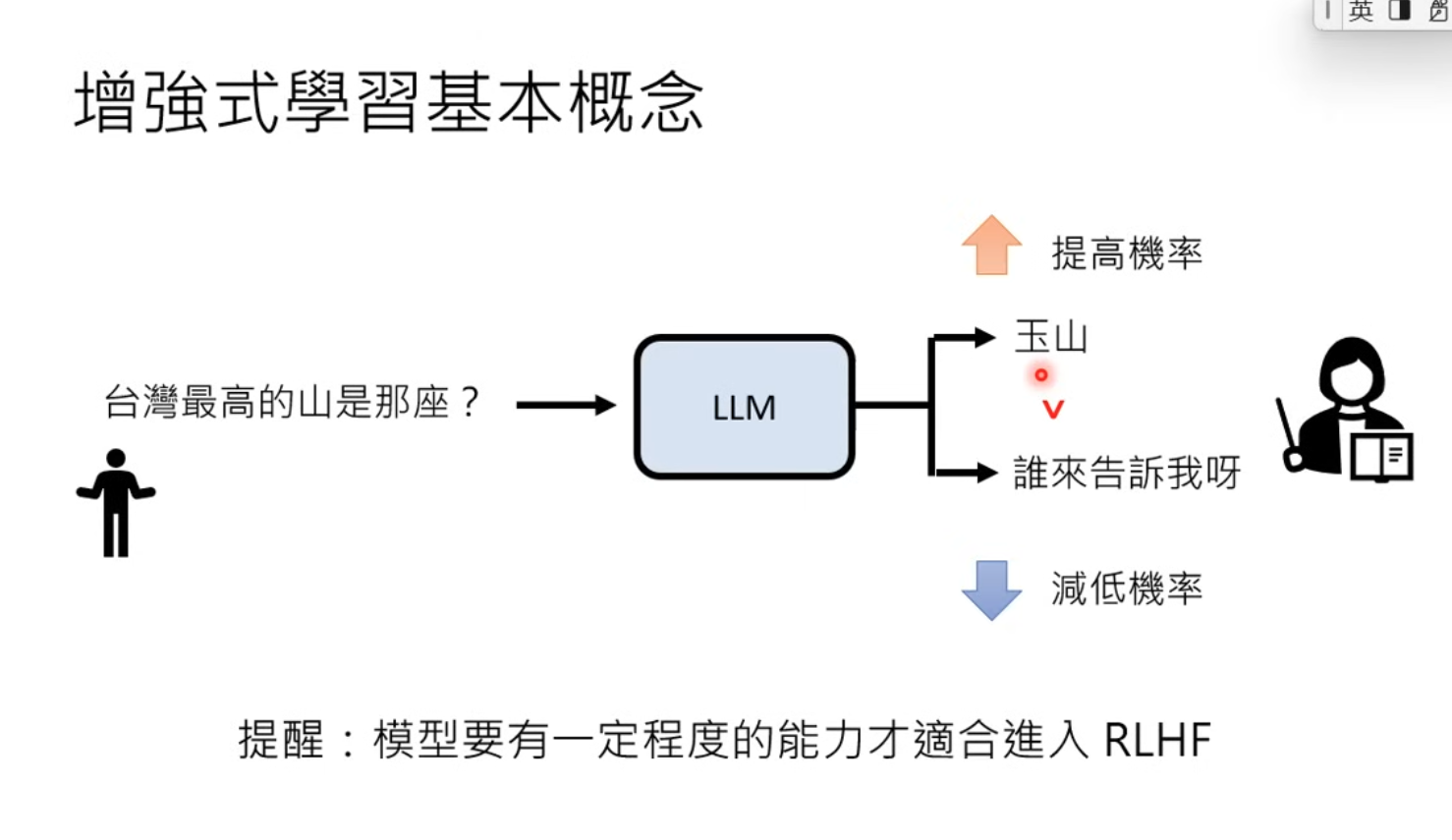
- RLHF need basic capability from the model.
- 2 steps in RLHF
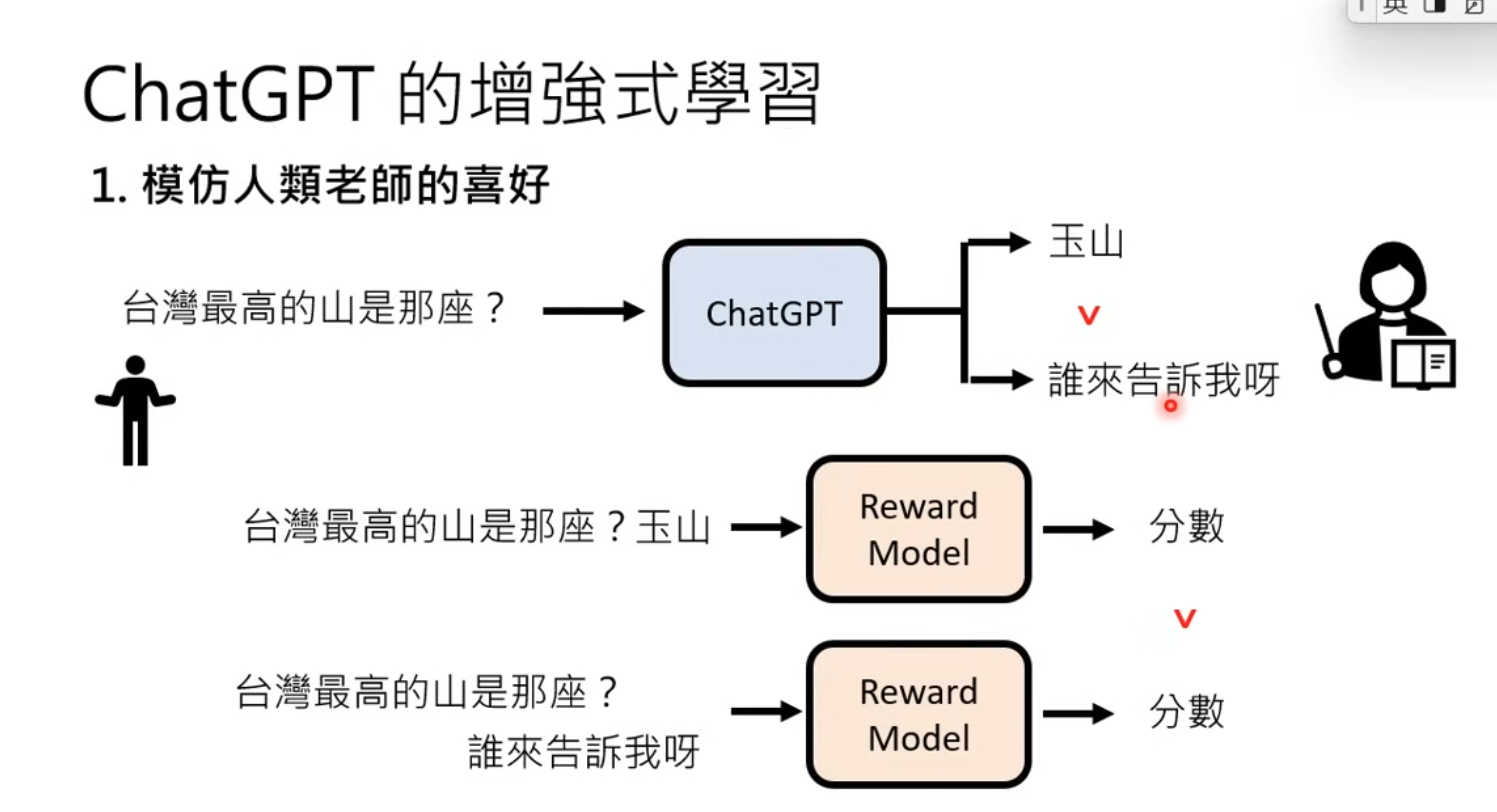
If only learns from HF, then you knows answer to a specific question, but NOT to general questions.- Learn Human preference by training a Reward Model to give rewards for answers
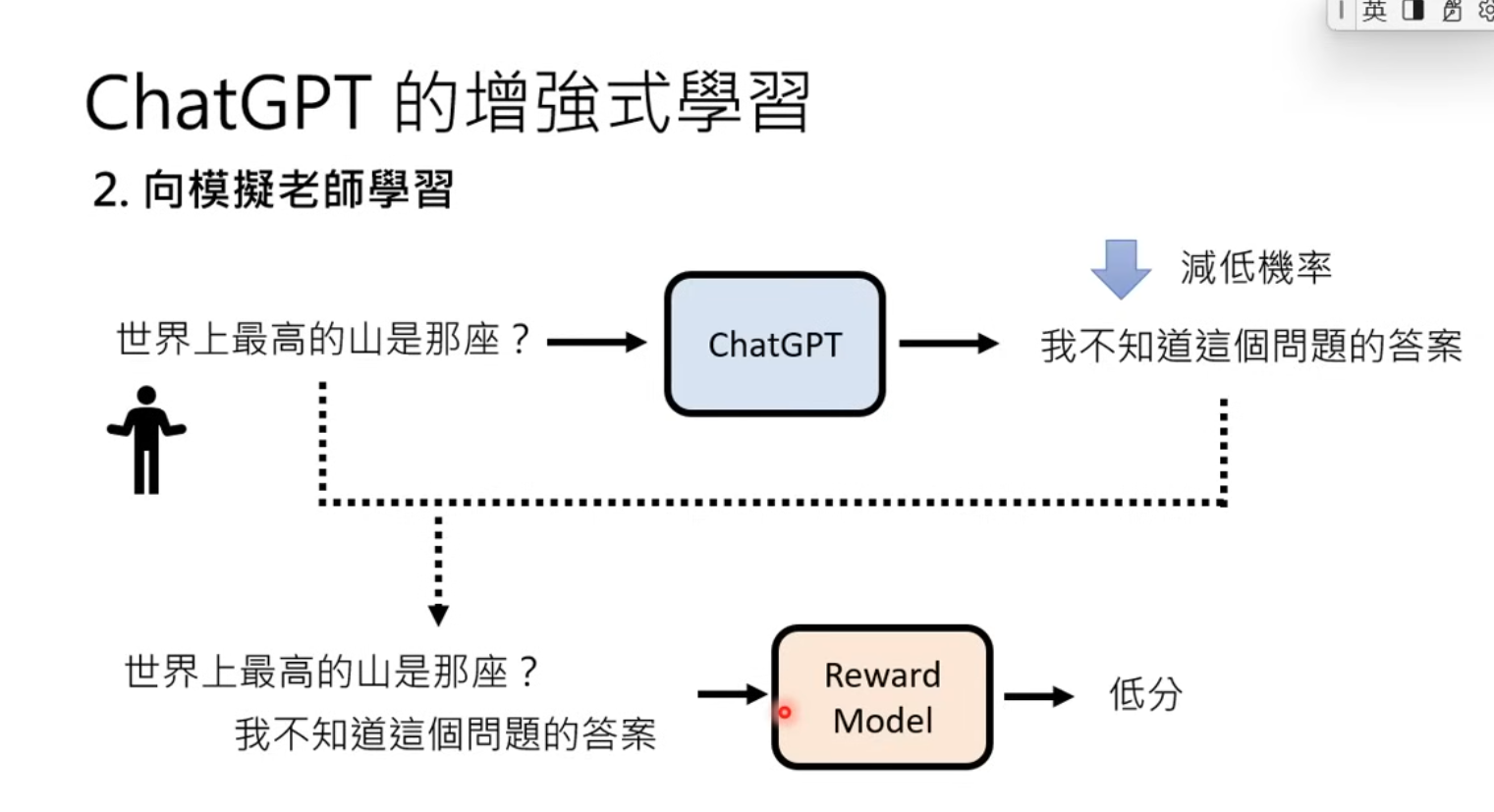
- Adjust network output based on the rewards
- Learn Human preference by training a Reward Model to give rewards for answers
- Alignment
SFT + RLHF = Alignment (to human)