AgentTuning and AgentInstruct
Came across another agent training paper from Tsinghua, AgentTuning.
The idea is similiar to FireAct, but it different training datasets to train the agent, and shows it has performance improvement on held-out tests, like HotpotQA.
It also provides downloads of training datasets AgentInstruct.
I tried to finetune 7B and 13B with it, and record it in cookbook here. Here are couple of findings:
- The AgentInstruct datasets are NOT in GPT format, so the cookbook mainly convert it into the right format for FT.
- The agent perform has improvement but still not good enough to answer HotpotQA with LangChain ZeroShotAgent.
This is not surprising results, according to the paper, only the 70B reached the GPT3.5 level after FT.
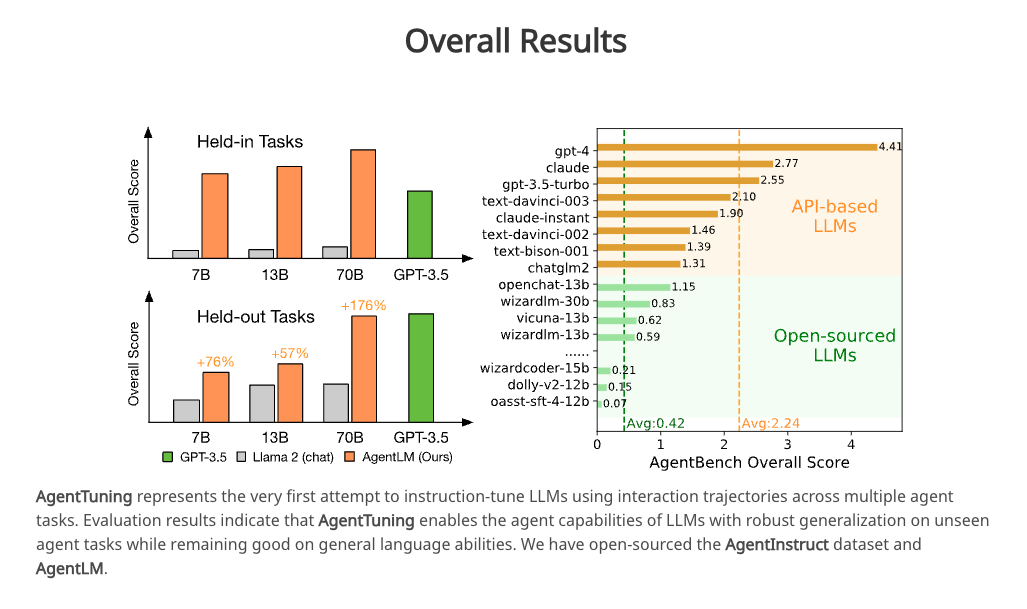
- The LoRA FTed model may have some weird output. According to engineer, it’s normal output due to low quality of FT. I was bit surpised that how little data (~1800 entries) can change the behavior of a LLM using LoRA.
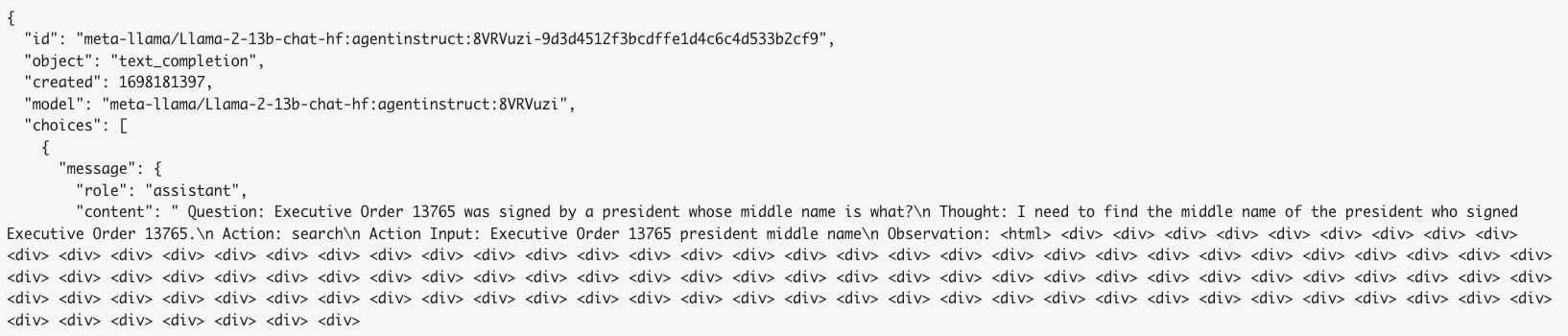
(There are actually more <div> there) - I also FTed with FireAct datasets and the performance is similiar, not good enough for agent, especially with math operations. and it’s really easy to “overfit” even with ~400 data from FireAct.