Continuous Batch
Read the blog about continuous batching, from Cade and Shen.
-
The initial ingestion of the prompt takes about as much time as the generation of each subsequent token. No wonder the prompt side does NOT affect the latency.
-
LLM inference is memory-bound calculation.
-
13B model requires 13x2=26 GB for model weights, according to Numbers every LLM developer should know, it’s 2x factor here. and surprisingly, each token consumes 1MB. So for a 40GB A100, there is 40-26=14GB left after model hosting, and it’s only 14K tokens. You can only limit batch size to 7 for 2048-token-sequence.
-
Traditional static batch shown below. Early finished sequence have to wait for late finished seq and cause unutilized GPUs.
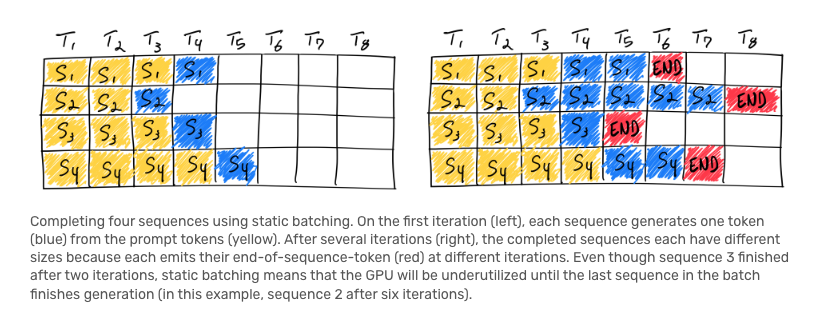
-
Continuous batching: Once a sequence emits an end-of-sequence token, we insert a new sequence in its place. TGI includes this algo in its implementation.
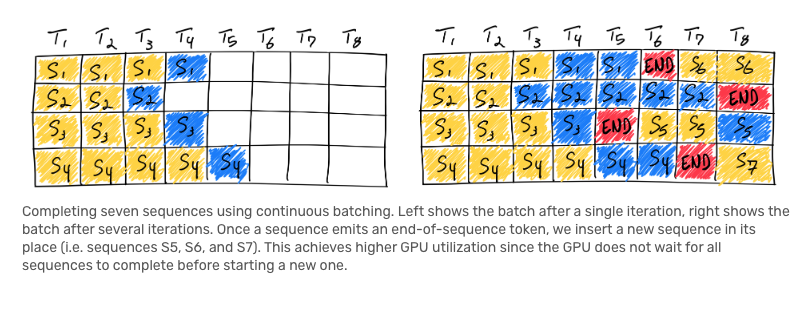
-
PagedAttention and vLLM: They allow the KV cache to be non-contiguous by allocating memory in fixed-size “pages”, or blocks. The attention mechanism can then be rewritten to operate on block-aligned inputs, allowing attention to be performed on non-contiguous memory ranges.. Well, I will write another blog about vLLM in more details when I understand better.