Flash Attention
It’s time to dig into some LLM optimization algirthms. My first googled question was “Flash Attention vs Paged Attention”, which are two popular optimizations. Here are some quick points.
 a. Flash Attention paper is from Stanford, and key contributor Tri Dao is with Together.xyz right now.
a. Flash Attention paper is from Stanford, and key contributor Tri Dao is with Together.xyz right now.
b. Paged Attention is from Berkeley Ion’s group, and implemented in vLLM.
Flash Attention is a very efficient algo with hardware level optimization, the you can barely know nothing about it from the graph below, even though it’s quoted in everywhere.
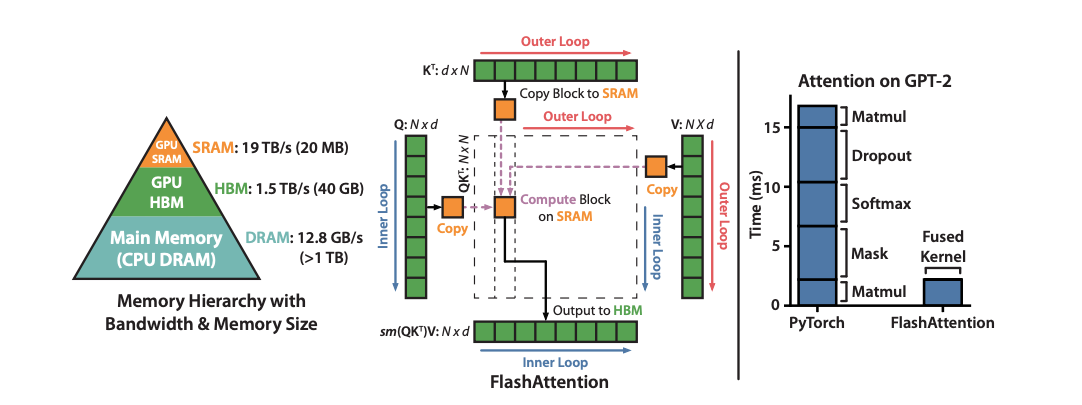
I found an excellent Zhihu page to explain it, in great detail and clear logic. I can simply quote is here without any more explanation. The notes below are for self reminding tips.
- The whole idea of FA is to reduce MAC(Memory Access Cost) at the cost of FLOPS. Try to do more calculations in SRAM(Static RAM) rather ine HBM(High Bandwidth Memory).
- The key idea to imporve Self-Attention is to do calculation in blocks. All matrics calculations are easy to break down into blocks but the Softmax is not straightfoward. Let’s take a look how to optimize it.
- Here is the original stable version of softmax formular. (Form 10 is stablization)
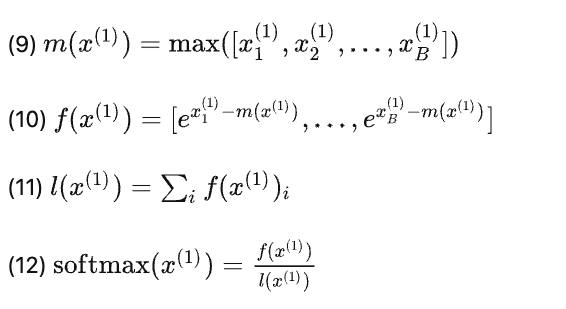
- We are break it down into two blocks and the way to calculate local softmax for block 1 is the same, which is actually showned above. Now the question is now to update the global results when we add the second block.

- Update parameters when block 2 local calculation is done.

- There are more details to explain formula 18, which is straightforward and I will skip here. Now you can update the global software max.

- Put everything together, here is the final formula in the code.
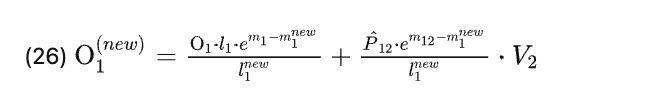 See code line 12 for the key update.
See code line 12 for the key update.

- Why FA is faster? Let’s see what’s the original calculation cost.
 9. With FA and the assumption that M (on-chip SRAM size) » d (head dimemsion)
9. With FA and the assumption that M (on-chip SRAM size) » d (head dimemsion)

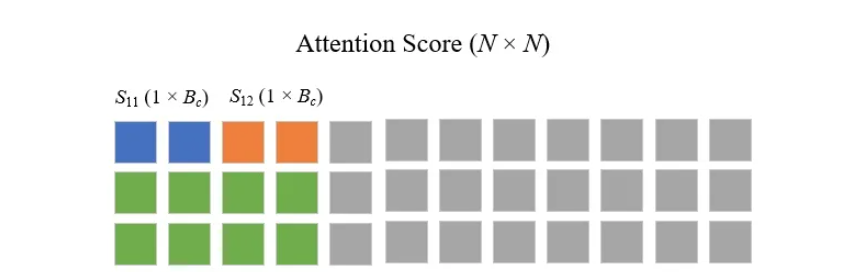
- For a more straightforward view, the NxN attentions score matrix is breakdown into batches to calculate local softmax
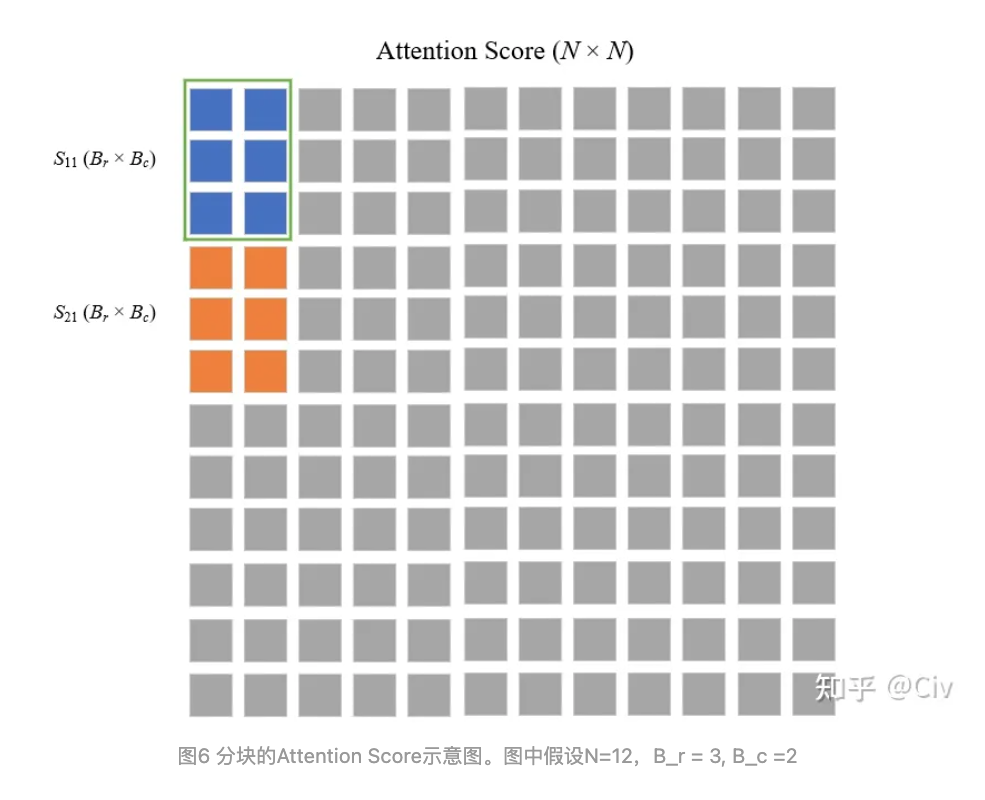
- The rows are actually only for batch processing purpose. Author simplified to 1 row and how exactly softmax are calculated locally(with multiple columns).
Levargeing GPU and manipulate different memory on GPU are something we did lots when optimization RTM(Reserve Time Migration) in CGG. Glad to read this paper and see ML is getting into this black magic field!