LLM Pre-Training and Inference
This is from Cameron Wolfe’s website and discussed LLM pretraining and Inference in details with code. Very educational and I will write multiple study notes around his blogs.
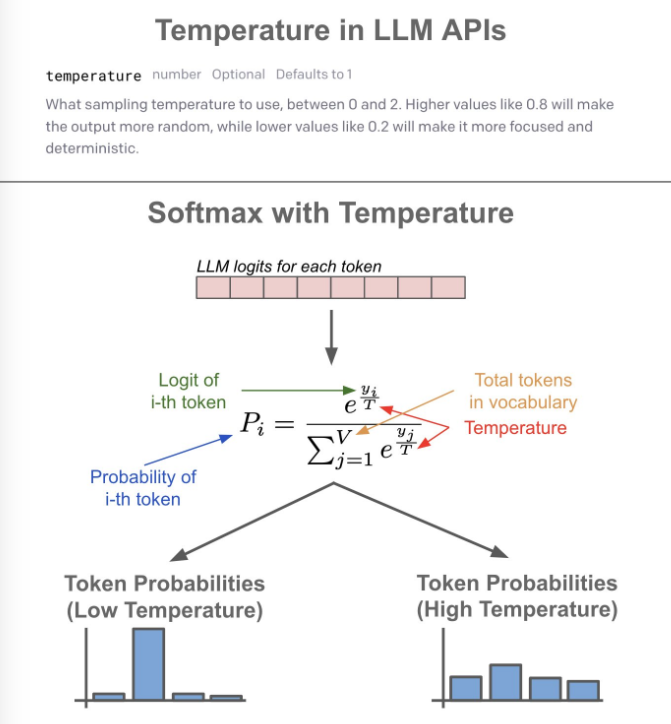
1 Temperature
Finally I see the formular for temperature, which is used to scale the logits after inference forward pass, as simple as that!
Now you can see close to 0 temperature will have logits get super large value so the value the logits itself does NOT matter. Then the distribution is more even, and random output is more likely.
logits = logits[:,-1,:] / temperature
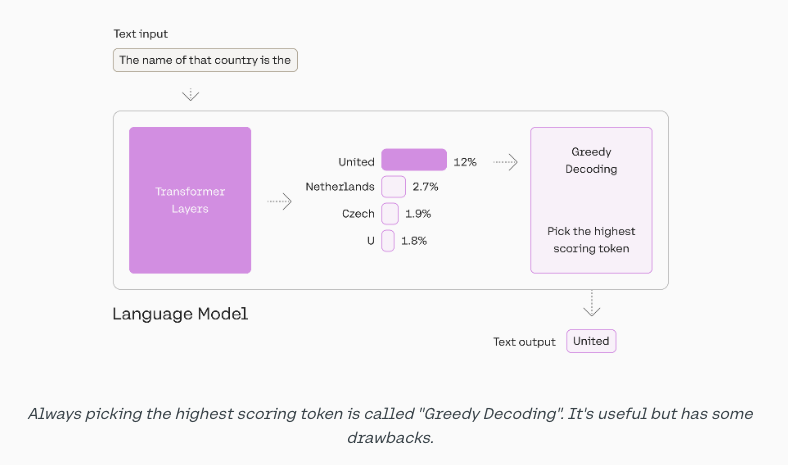
2 Top-K and Top-P
This is from Cohere’s docs.
- Greedy decoding: Pick the top token
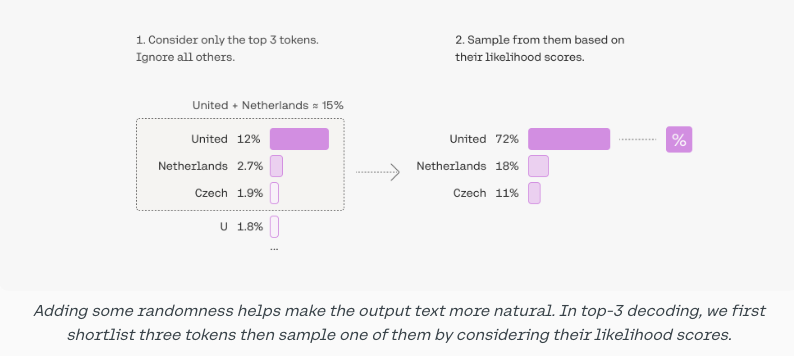
- Top-K: Pick from amongst the top k tokens. When k=1, it’s greedy decoding
- Top-P: Pick from amongst the top tokens whose probabilities add up to p%. Or called Nucleus Sampling, dynamically set the size of the k. When both
kandpare enabled,pacts afterk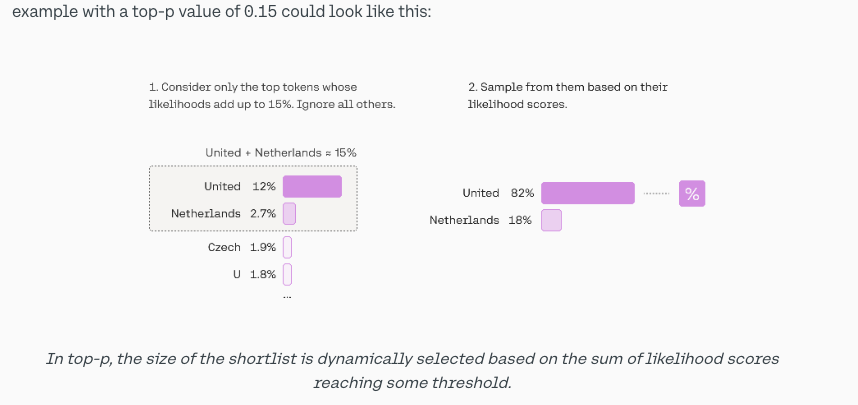
3 Weight Tying
A new concept is introduced here for training. Some steps can share neural network weights.
But wte and lm_head they are transposed, how can their weight directly be euqal???

4 Pretraining
Next token prediction underlies all LLM models pretraining and inference. I will skip tokenziation, embedding and transformer steps (will dive deep in other notes) but directly goes to the token prediction part.
The next token is predicted by passing a token’s output vector as input to a linear layer, which outputs a vector with the same size as our vocabulary. The blue vector will predict the last pink vector, and model will be trained to maximize the prob. of the correct token.
Predicting tokens across a sequence. We perform next token prediction for EVERY token in a sequence and aggregate the loss over them all.
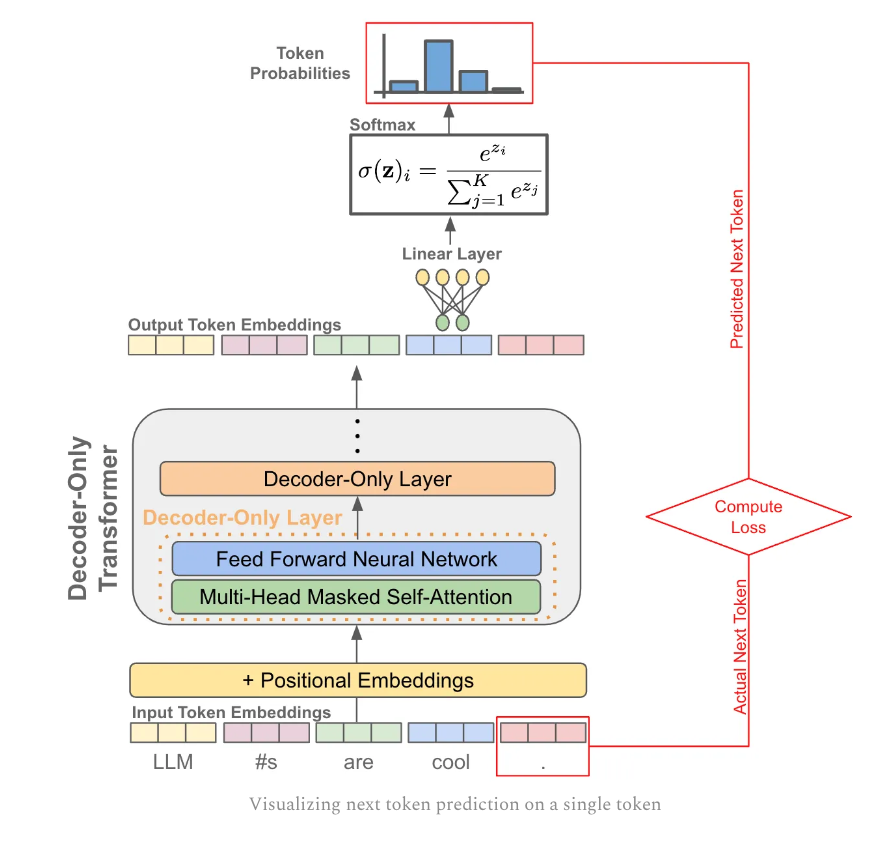
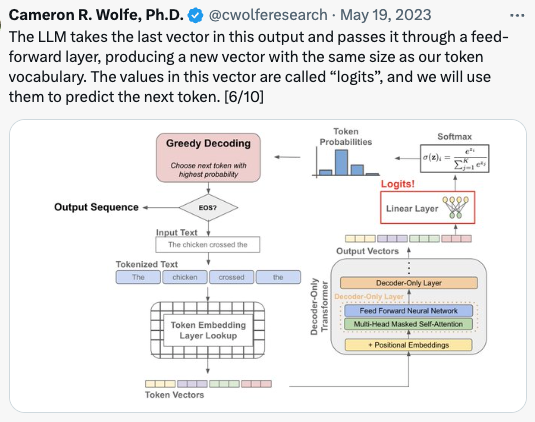
5 Autogressive Inference
Inference is similar but only use the LAST vector in the output and passes it through feed-forward layer and product logits. This is from Cameron’s twitter post
6 Distributed with DDP and FSDP
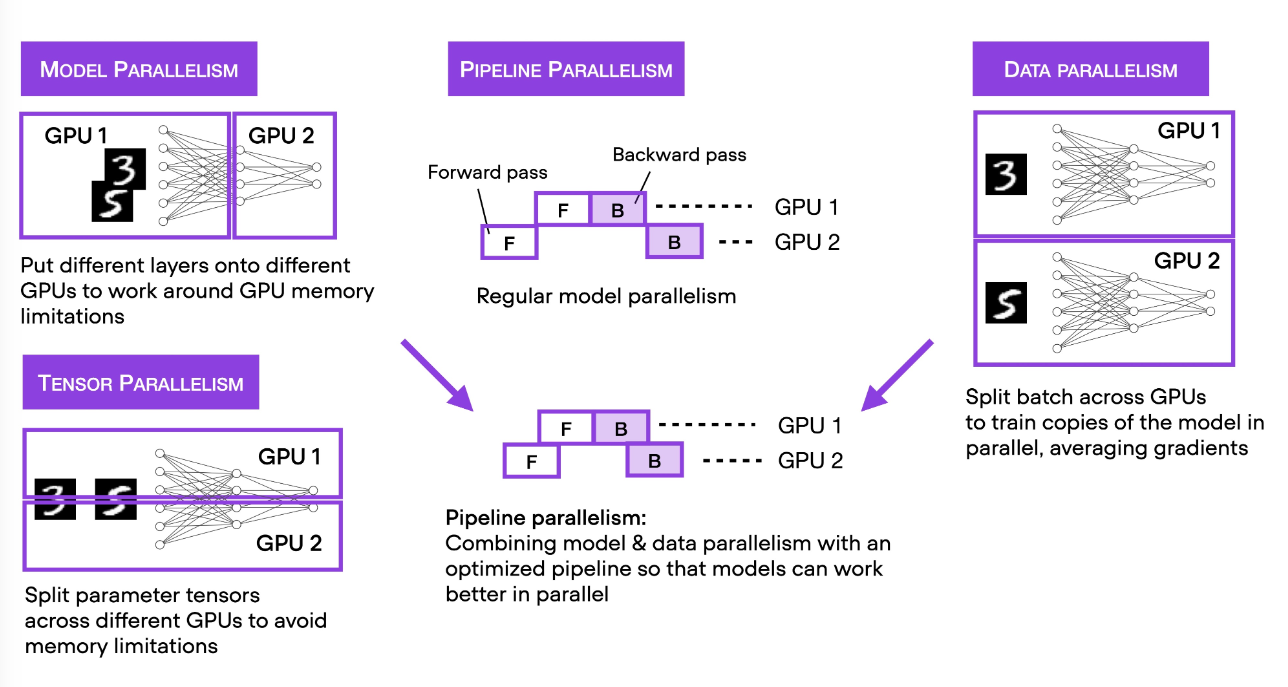 Training with DDP requires that we simultaneously run multiple training processes (same number as # of GPUs)
Training with DDP requires that we simultaneously run multiple training processes (same number as # of GPUs)
training LLM, FSDP is used for models can NOT be hold in single GPU.