From LLM to Agents
Yao Shunyu, the original author of ReAct paper, talk about LLM and Agents.
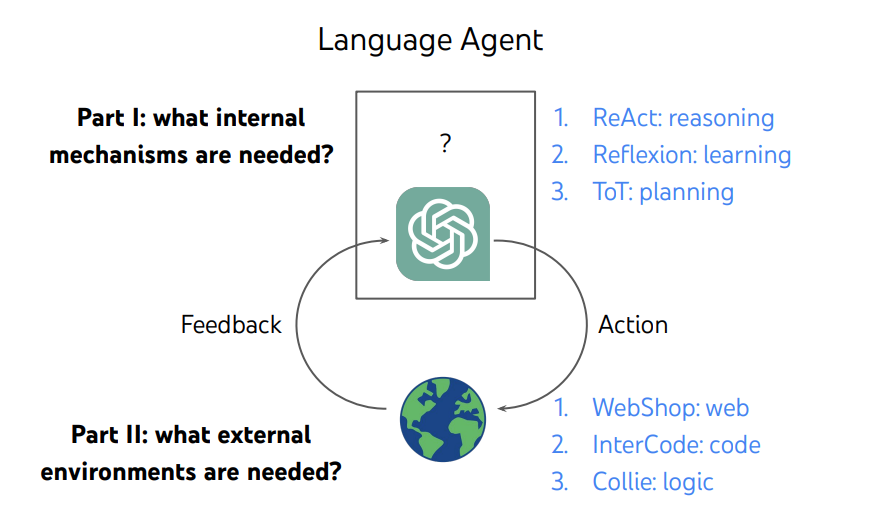
1, ReAct
Reasoning Only: like CoT
Acting Only: like WebGPT (search only)
Need to combine both achive human-like results

Comparing action space with RL, RL is external only but ReAct is acting with both internal and external.
How can we achieve long-term mem? check next point!

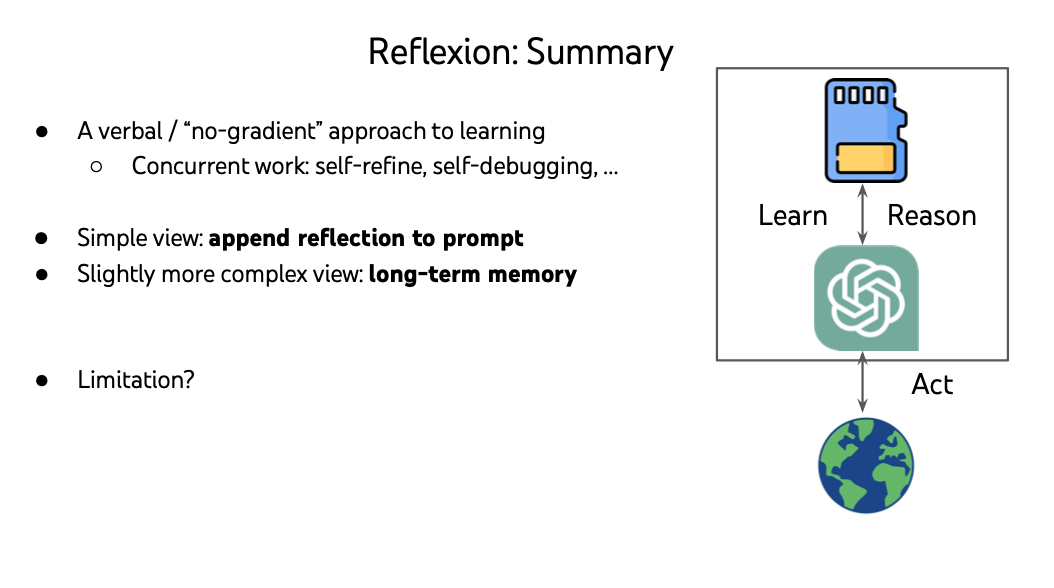
2 Reflexion
Noah Shinn, a undergraduate from northeastern is the first author of this paper.
- Use language feedback instead of scalar feedback,0/1. A feedback would be like runtime error msgs, unit test cases and results.
- Use language update, instead of parameter update like PPO, A3C, DQN…. An update would be like “be sure to handel this corner case”
So this “Verbal” RL would be called Reflexion.
How can we achieve long-term mem? check next point!

Here is the summary of Reflexion.
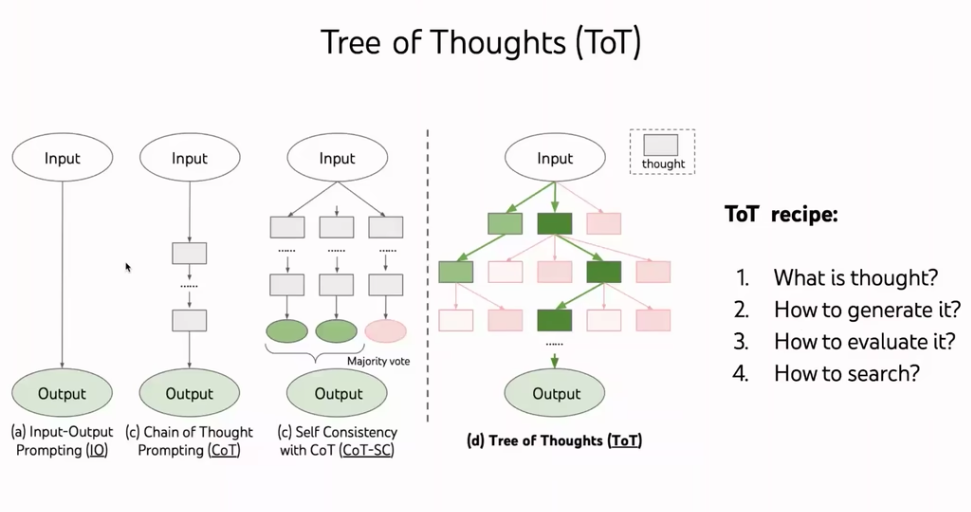
3 Tree of Thoughts
Shunyu’s paper again. Why is it hard for computer to solve 24?
1, Once you get it wrong at one step, it’s impossible to get the results.
2, How to evaluate early choices. Like if you start with number 5, is it good or bad?
So the planning is very important for soving this problem.
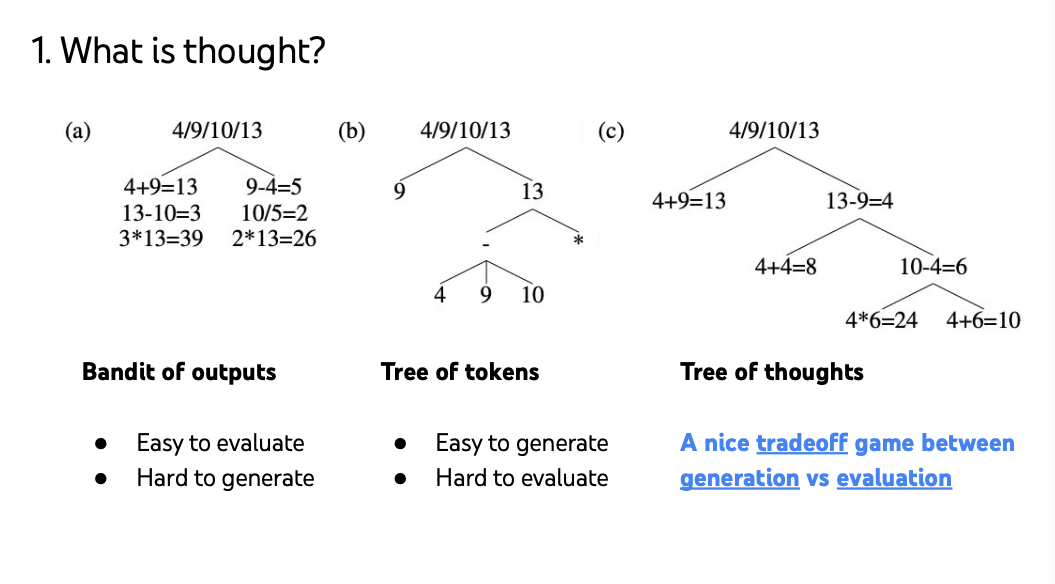
 Bandit of outputs: output all steps to generate 24.
Bandit of outputs: output all steps to generate 24.
Tree of tokens: list all possible tokens.
Thought: tradeoff between these two
 Generate thought is the key, either by sampling or proposal.
Generate thought is the key, either by sampling or proposal.

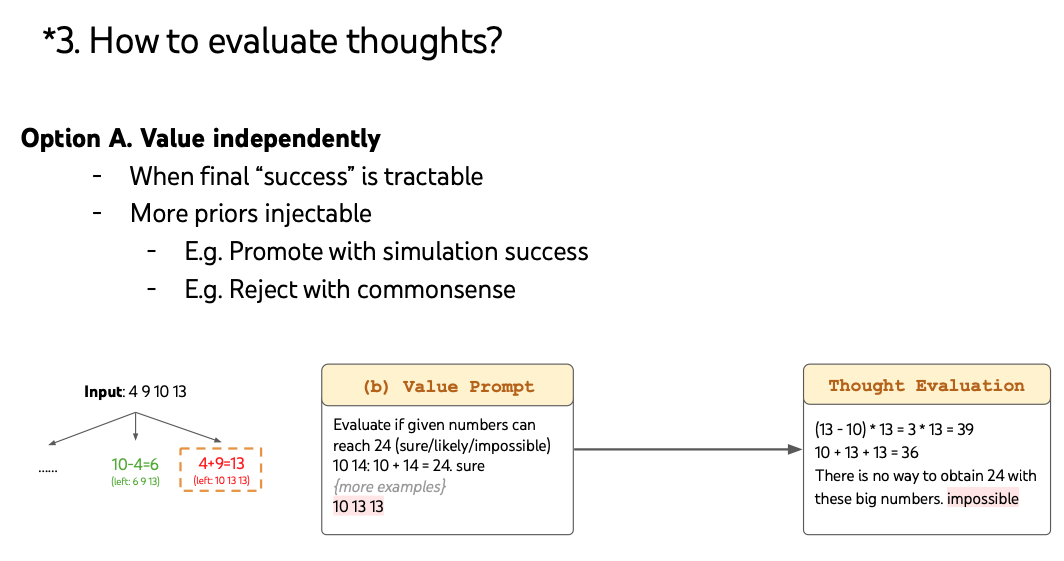
 Evaluation
Evaluation
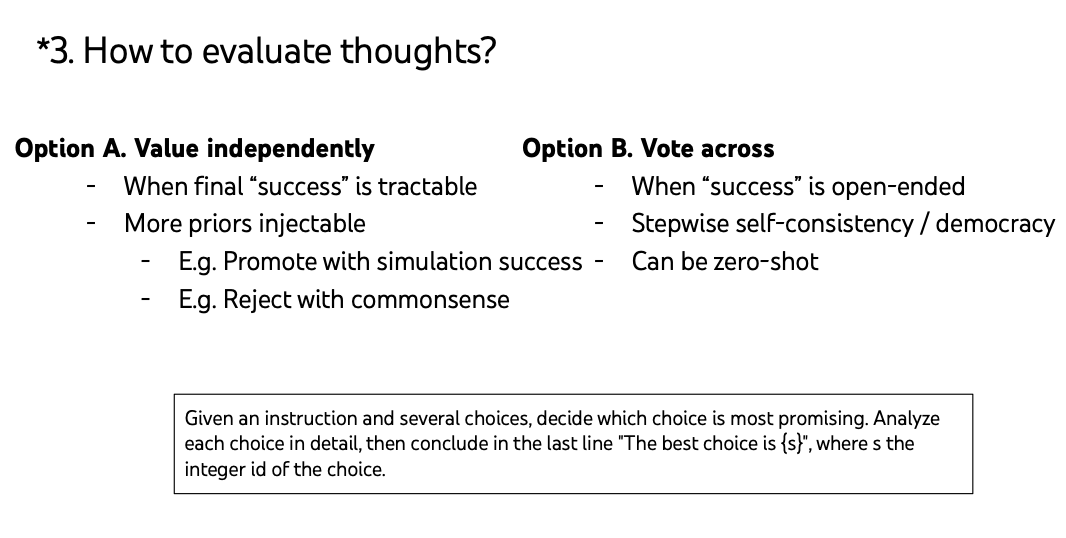 Search can be done by BFS or DFS
Search can be done by BFS or DFS
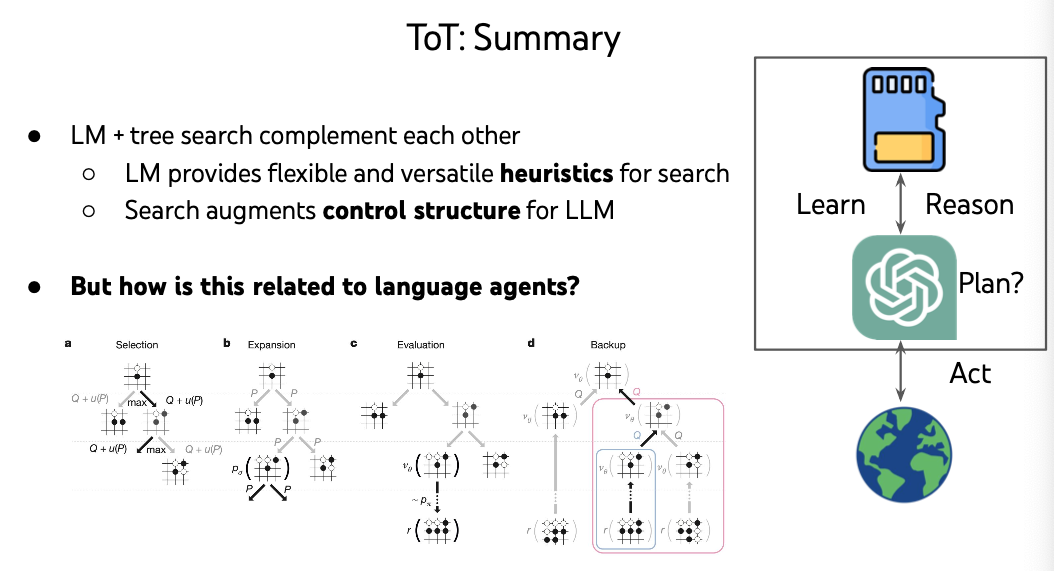
Here is a simple promping solution with ToT, and here is the prompt
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...
