GenAI by Hung-yi Lee 2024-02
Continue with Part 1, The 5th way of prompt engineering.
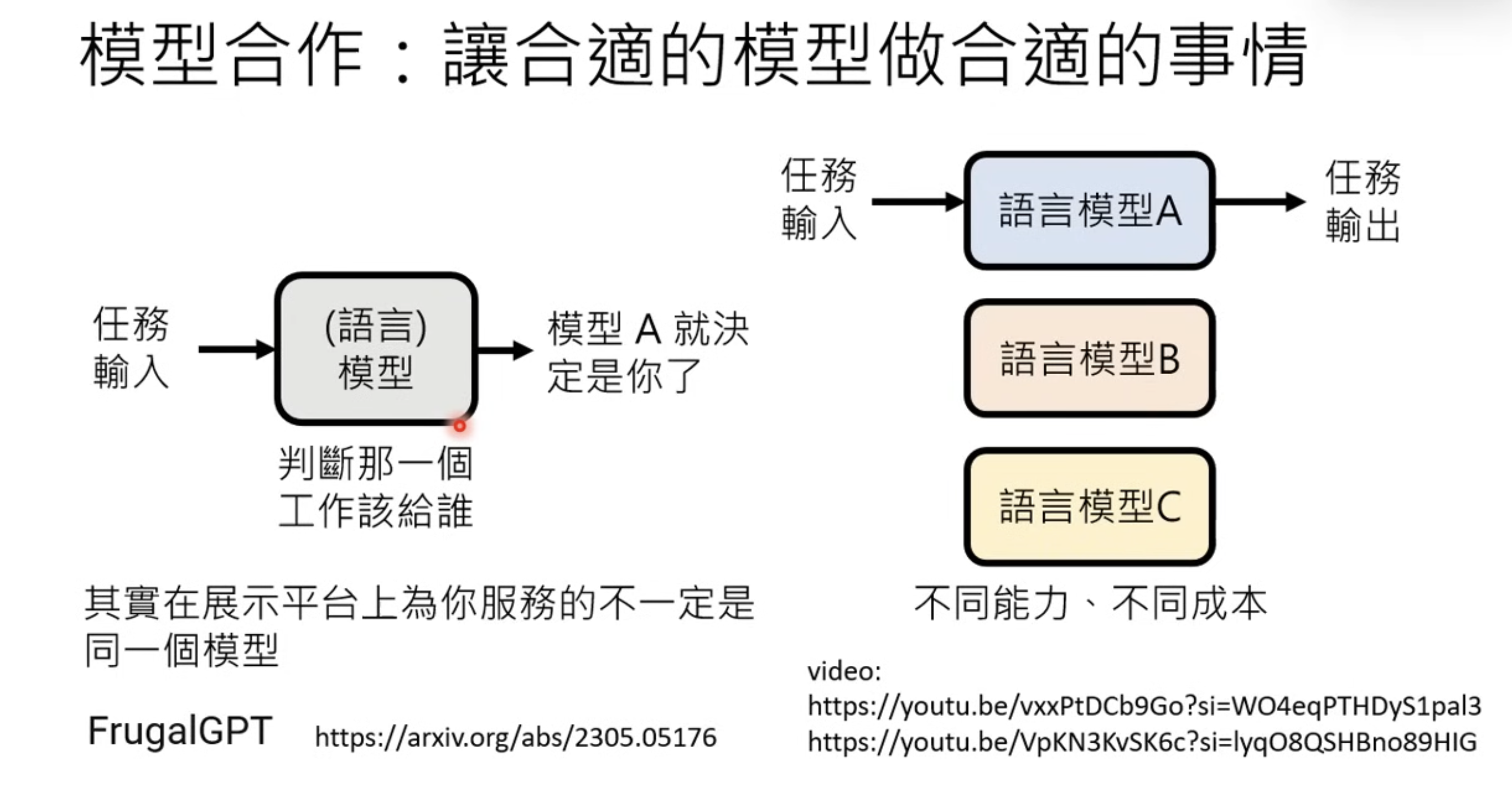
5 Model Cooperation
Model Cooperatation could be due to cost.
This is similar to MoE but no LLM architecture is changed here.
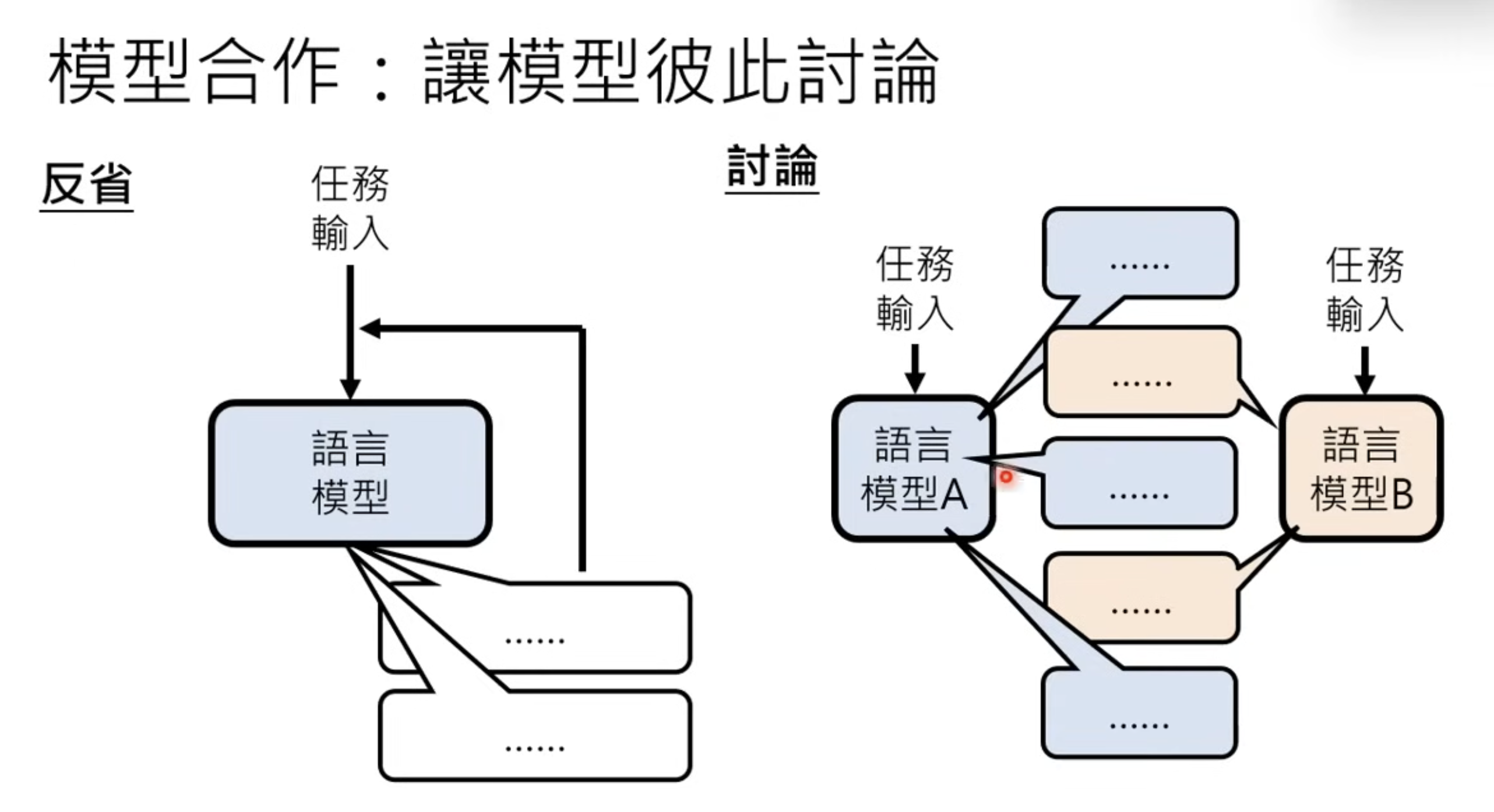
 Or quality improvment based on reflect
Or quality improvment based on reflect
 Exchange-of-Throught is about different cooperatoin between model.s
Exchange-of-Throught is about different cooperatoin between model.s
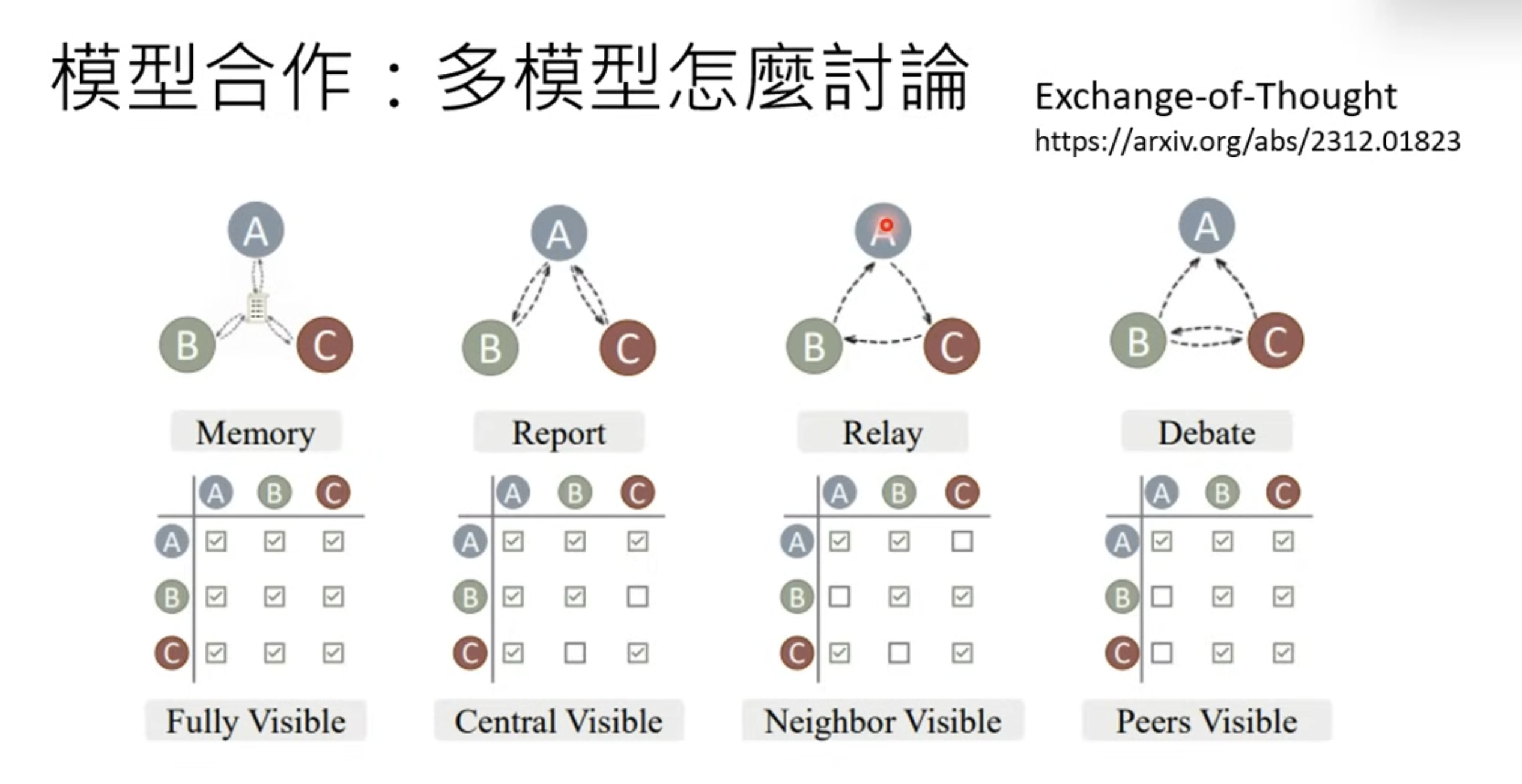 The discussion is the longer the better. But on general, the models are very polite and no intend to argue. You need to purposely prompt them to get into discussion.
The discussion is the longer the better. But on general, the models are very polite and no intend to argue. You need to purposely prompt them to get into discussion.

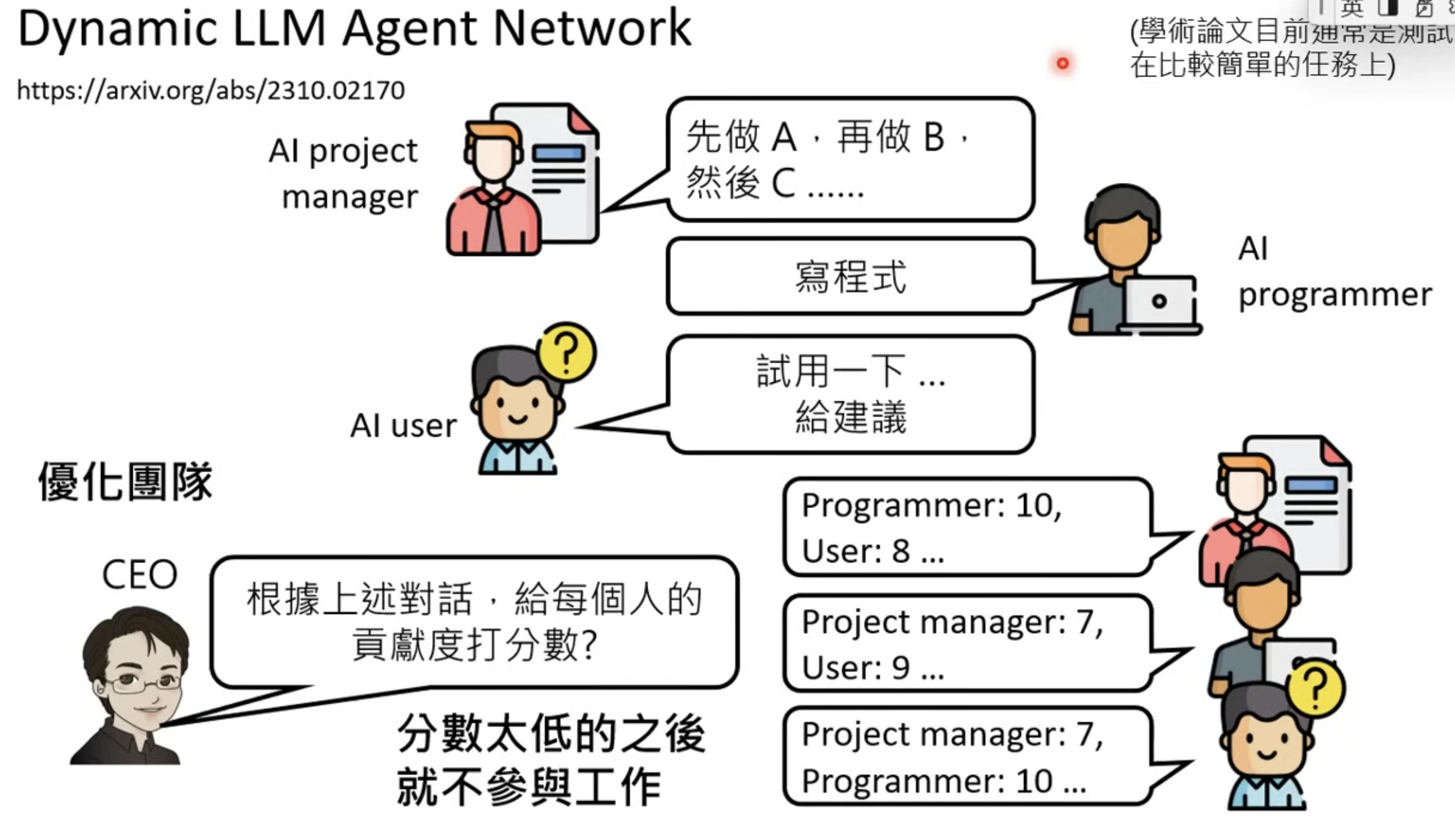
Different roles can be assigned to models. But lots of spoiler for Frieren!
 and Dynamic LLM agent can also judge the performance of each LLM and exchange the low performing ones.
and Dynamic LLM agent can also judge the performance of each LLM and exchange the low performing ones.
Couple of multi role Agents
MetaGPT
ChatDev
Generative Agent
Now Let’s get into LLM training
1. Pretraining
Funny metaphor for different phase of training.
 This part of talk is very basic, going through topics like hyperparameter and initialization. An interesting point is show how much data is needed to train Syntactic, Semantic and Winograd knowledge.
This part of talk is very basic, going through topics like hyperparameter and initialization. An interesting point is show how much data is needed to train Syntactic, Semantic and Winograd knowledge.
WCS (Winograd Schema Challenge) is test of machine intelligence proposed in 2012 by Hector Levesque.
The first cited example of a Winograd schema is due to Terry Winograd.
The city councilmen refused the demonstrators a permit because they [feared/advocated] violence.
The choices of “feared” and “advocated” turn the schema into its two instances:
The city councilmen refused the demonstrators a permit because they(concilmen) feared violence.
The city councilmen refused the demonstrators a permit because they(demonstrators) advocated violence.
Data engineering for LLM pre-training is mainly data cleaning.
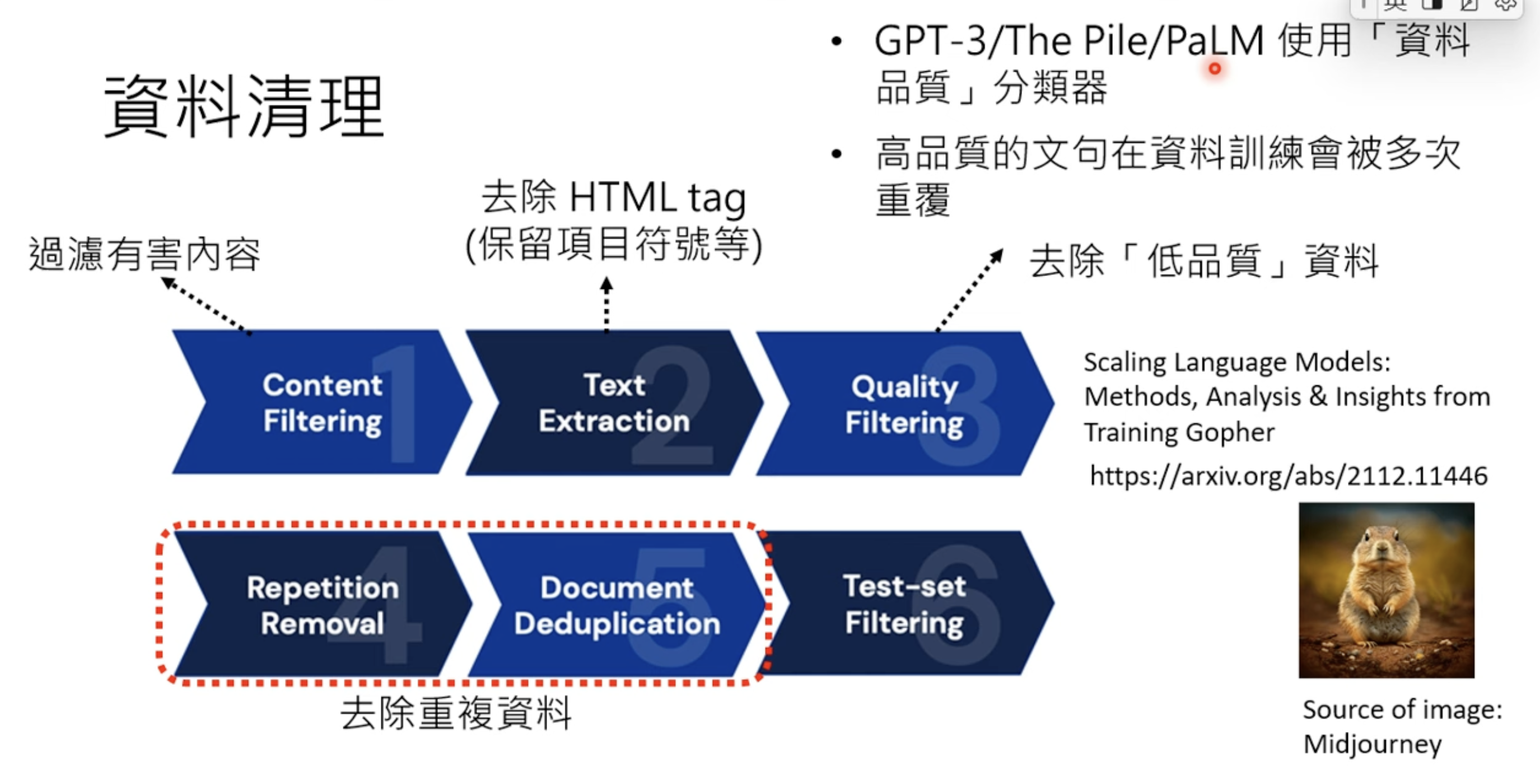 Otherwise some repeatation is shocking.
Otherwise some repeatation is shocking.
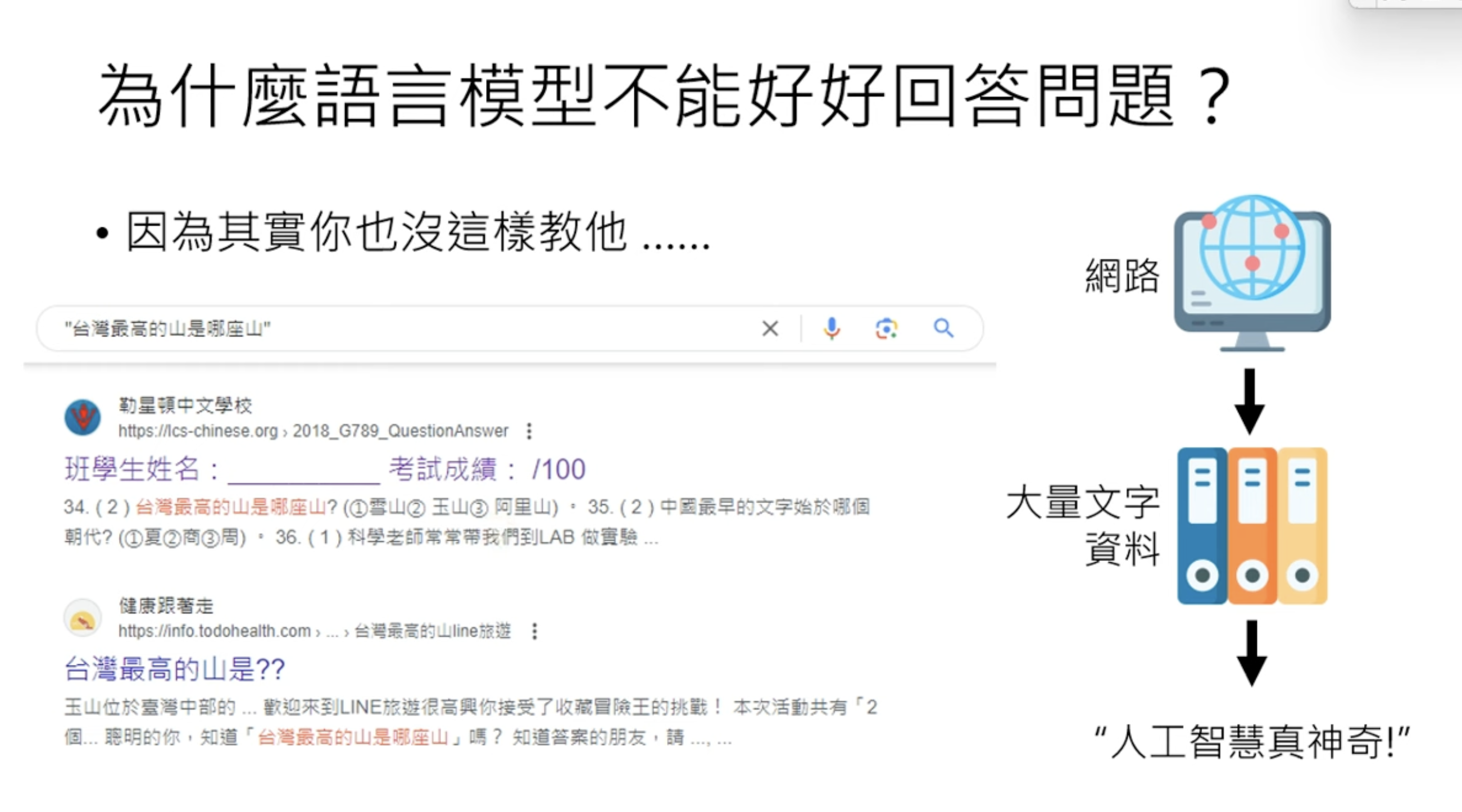
 Best takeaway from this talk, why pre-training is not good enough? Because the knowledge online may not direct answers. This is why SFT is used in the alignment.
Best takeaway from this talk, why pre-training is not good enough? Because the knowledge online may not direct answers. This is why SFT is used in the alignment.
2. Instruction FT
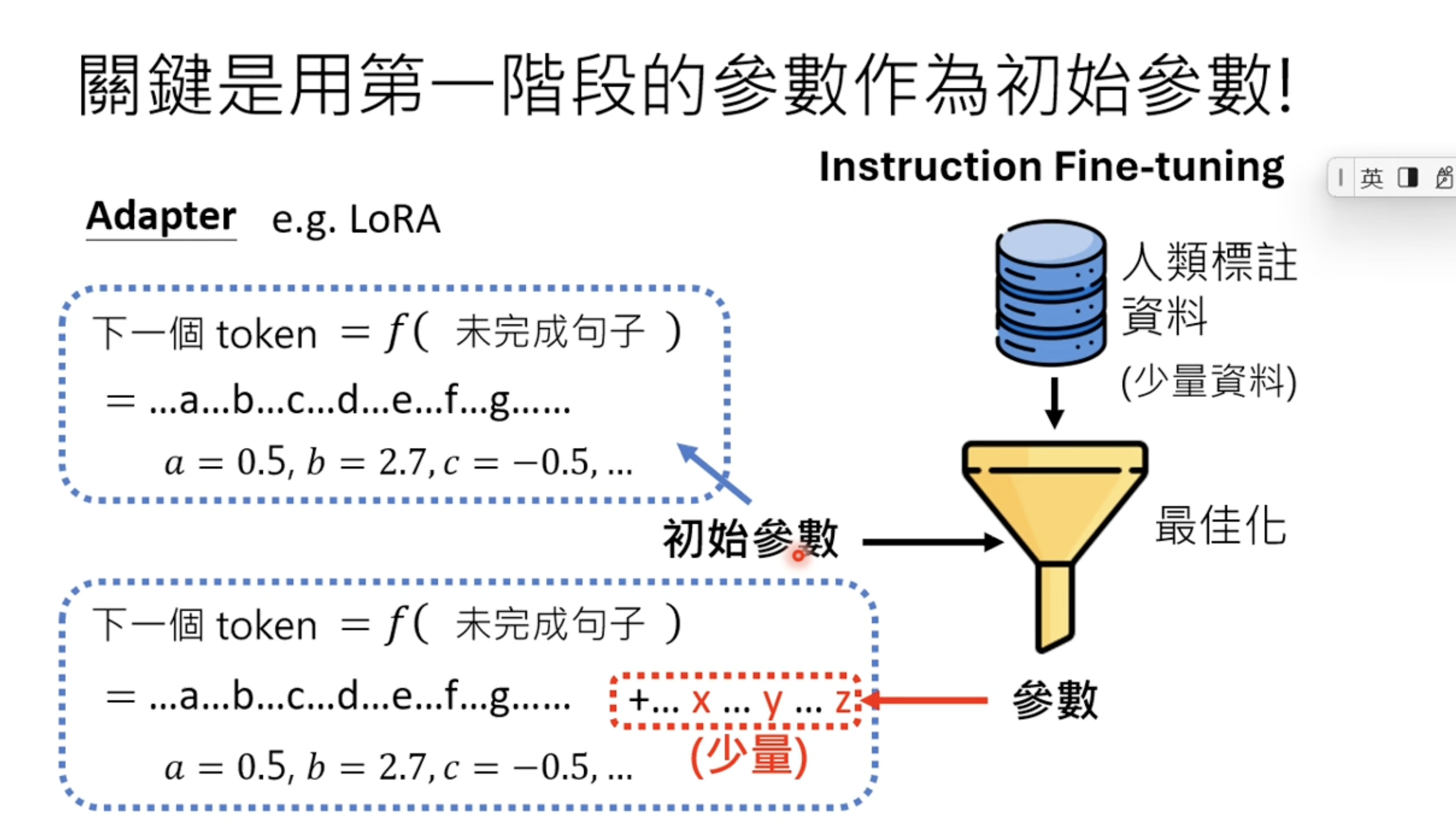
To avoid FT changing original parameters, we can use adapters. and LoRA is one of them.
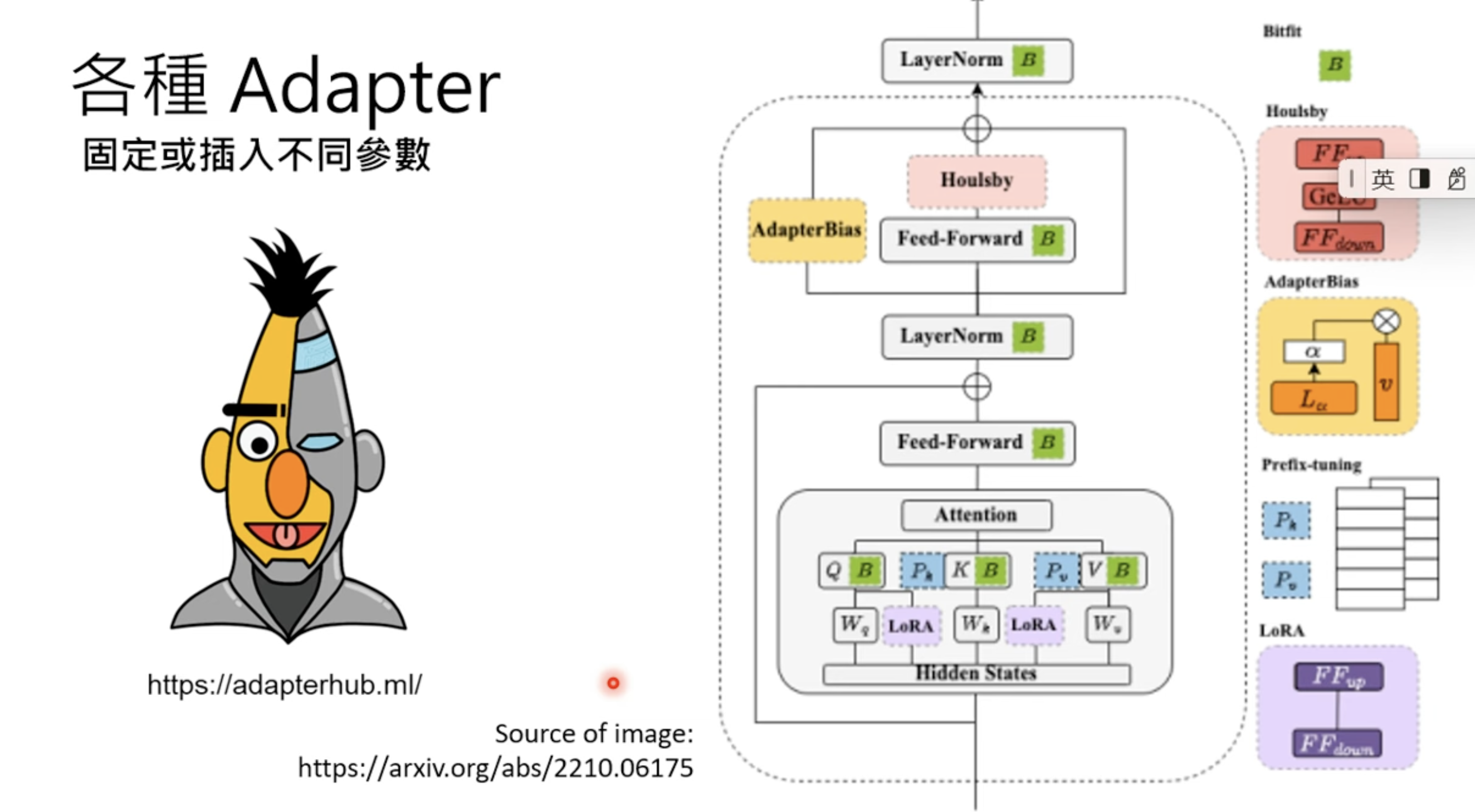
 There are collections of adapters
There are collections of adapters
 Two ways of FT. The second one is widely used.
Two ways of FT. The second one is widely used.
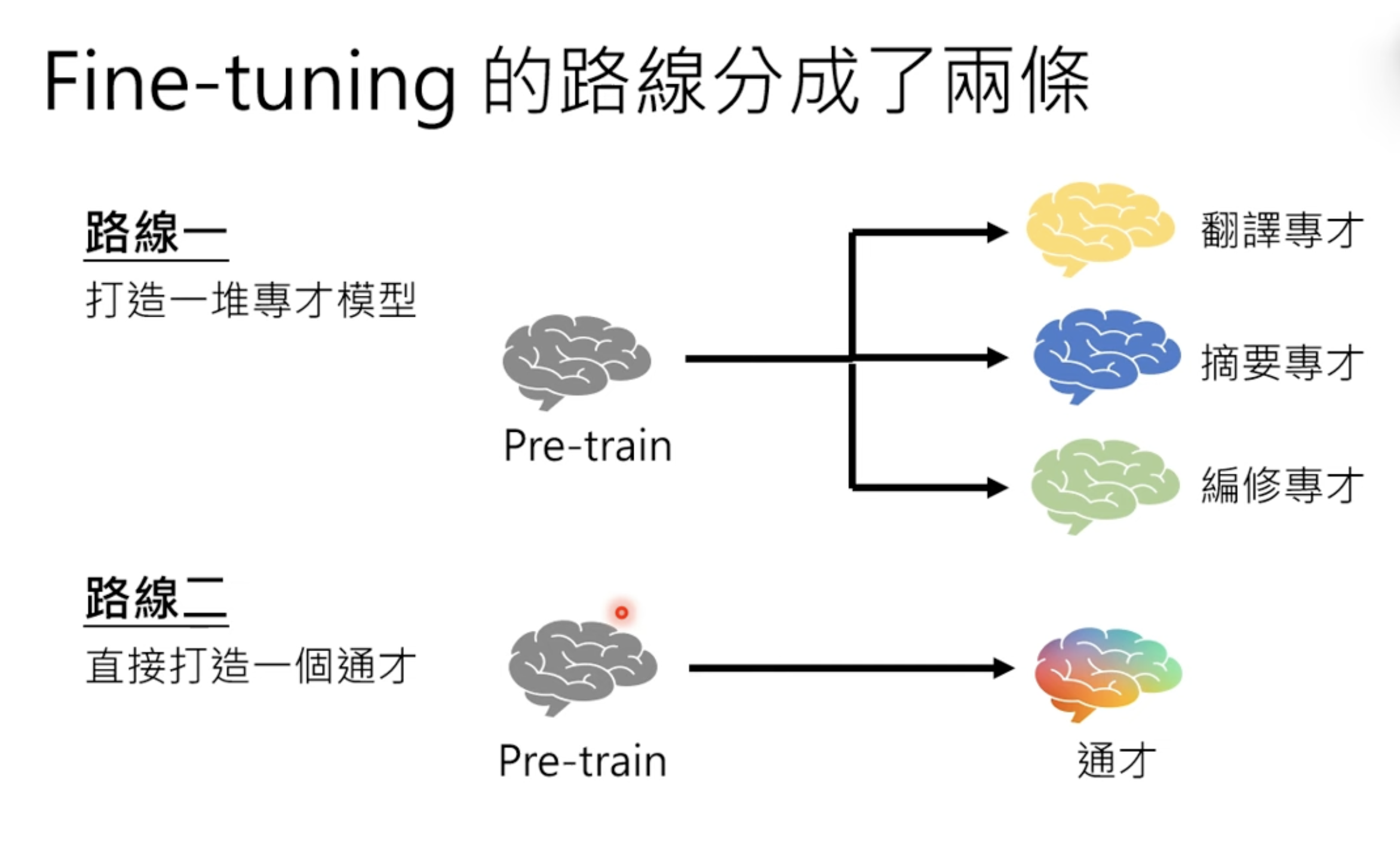 The ability to learn to be a general is beyand imagination
The ability to learn to be a general is beyand imagination
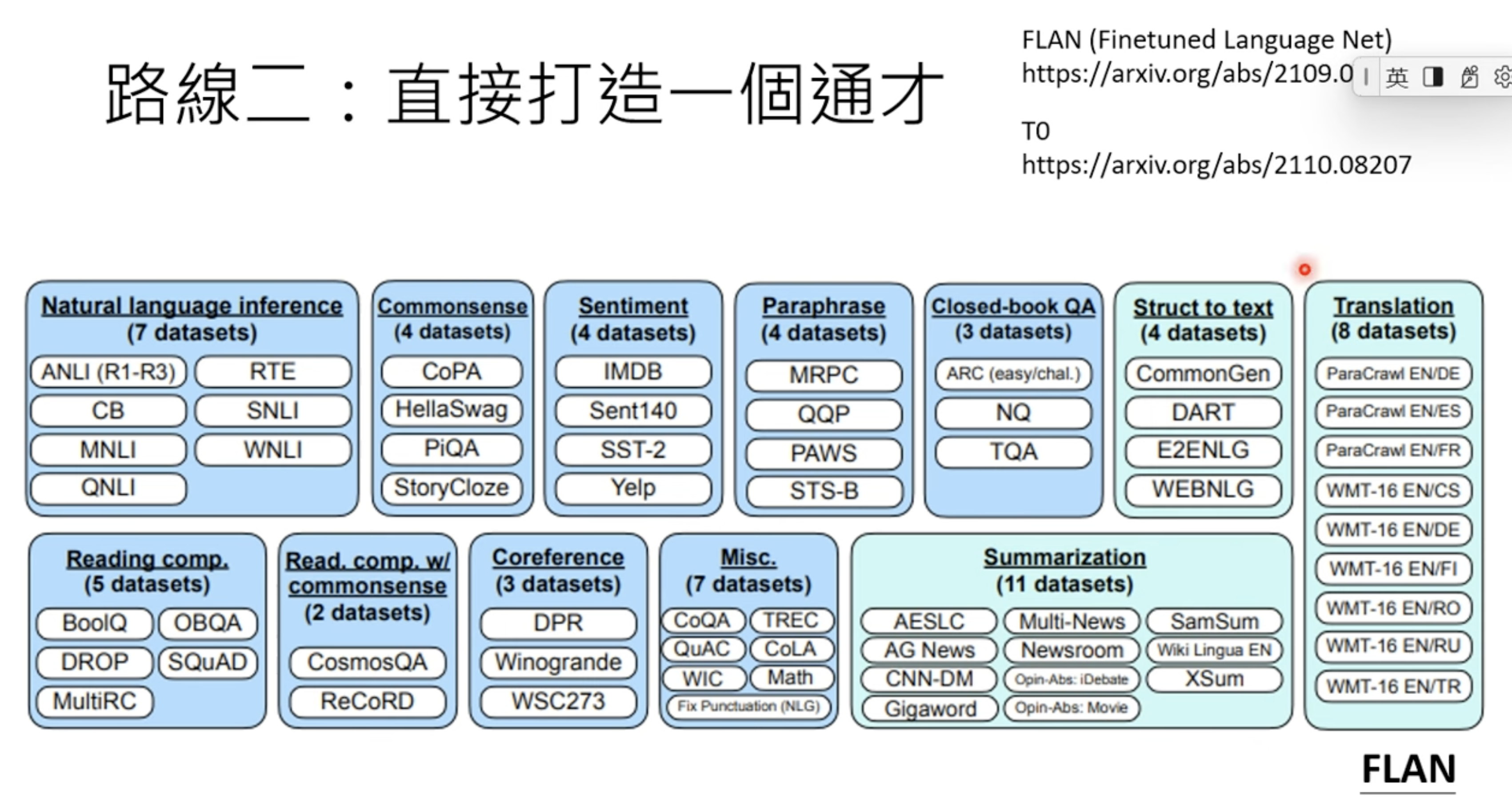
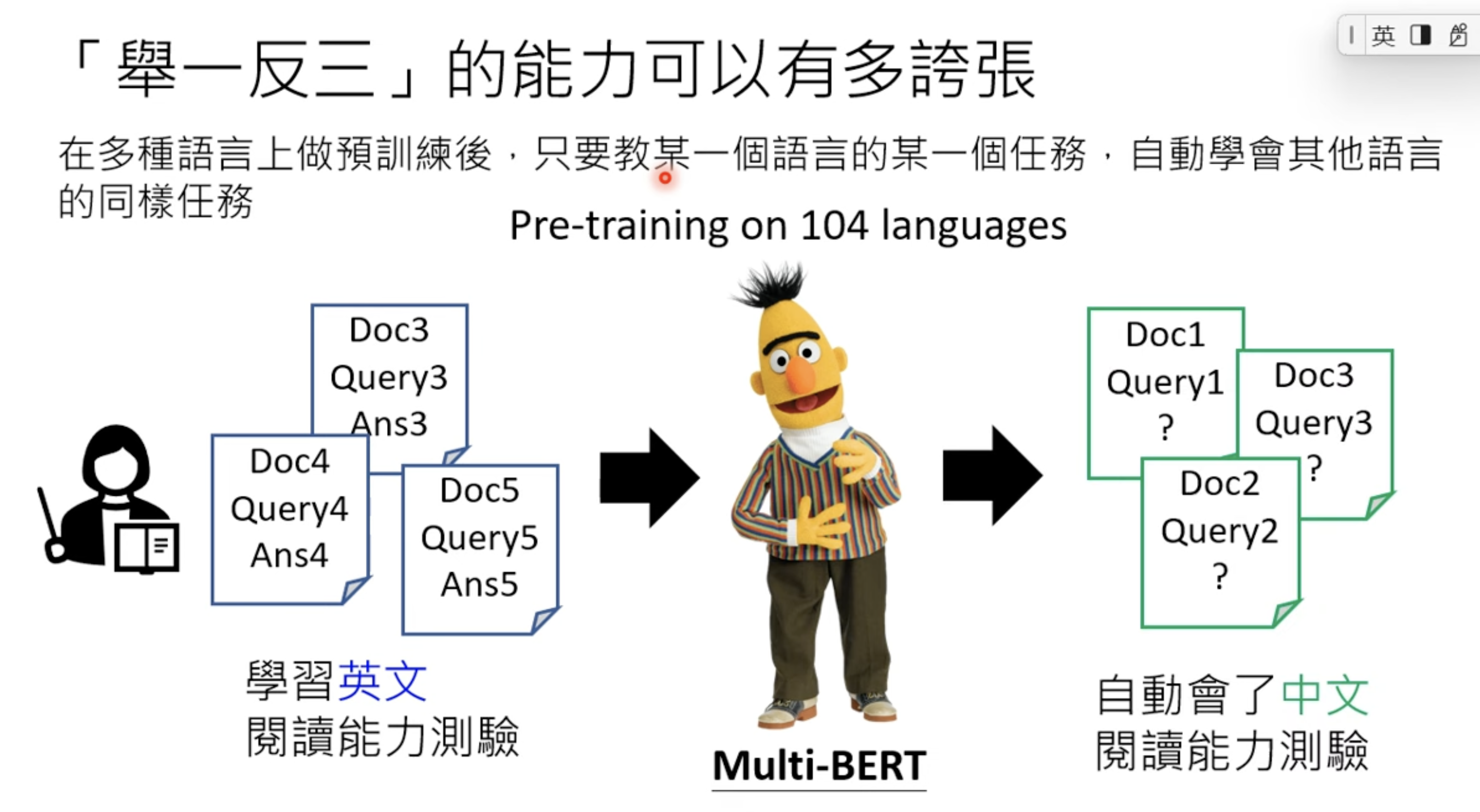 FLAN from google is an example, and T0 from Huggingface. I never heard of neither one.
FLAN from google is an example, and T0 from Huggingface. I never heard of neither one.
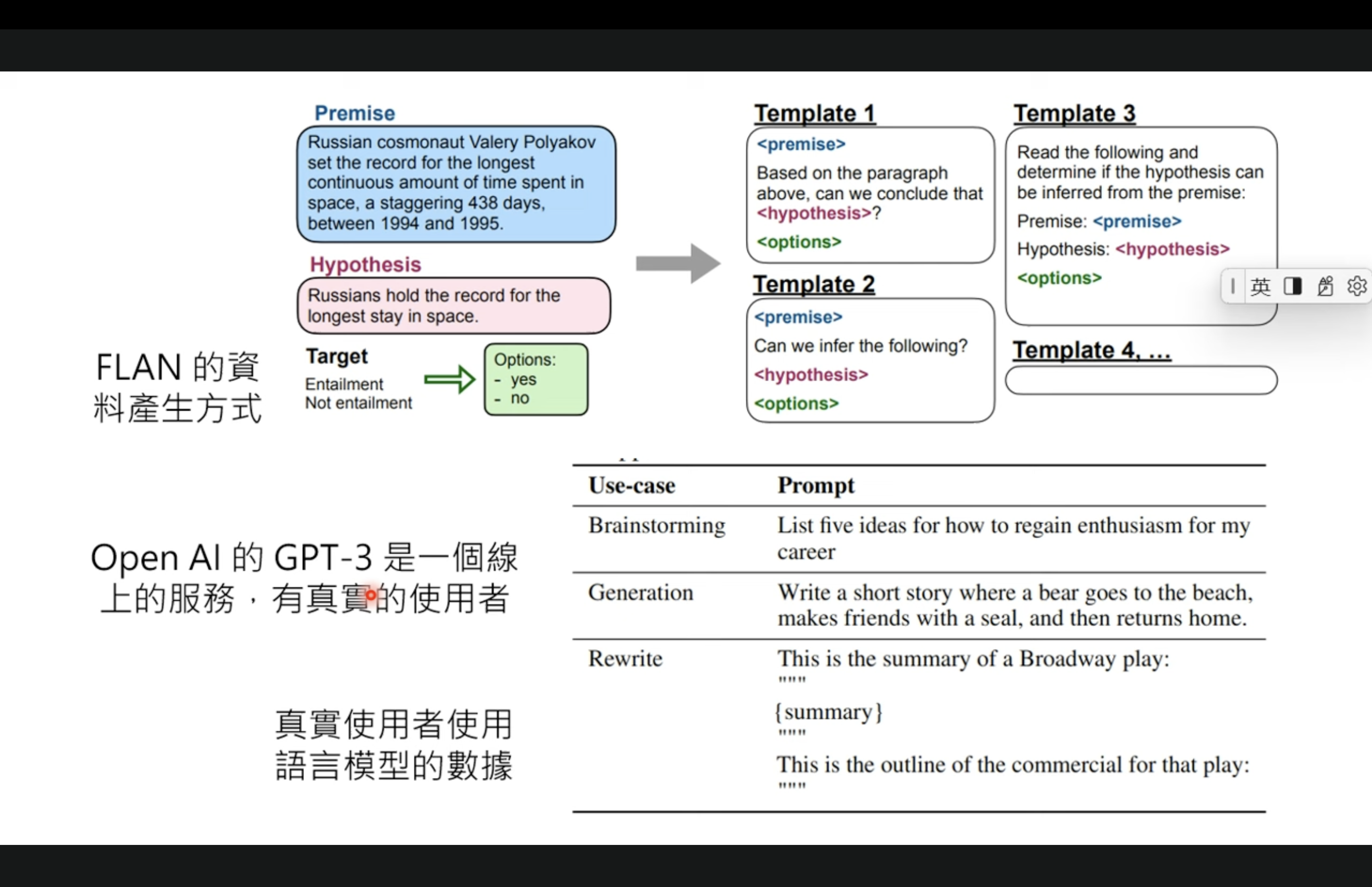
 But Instruct GPT is better than FLAN, due to the FT data quality. FLAN training data are from templates, and GPT is collecting from real human input.
But Instruct GPT is better than FLAN, due to the FT data quality. FLAN training data are from templates, and GPT is collecting from real human input.
 Even Llama2, only used 25K data in FT.
Even Llama2, only used 25K data in FT.
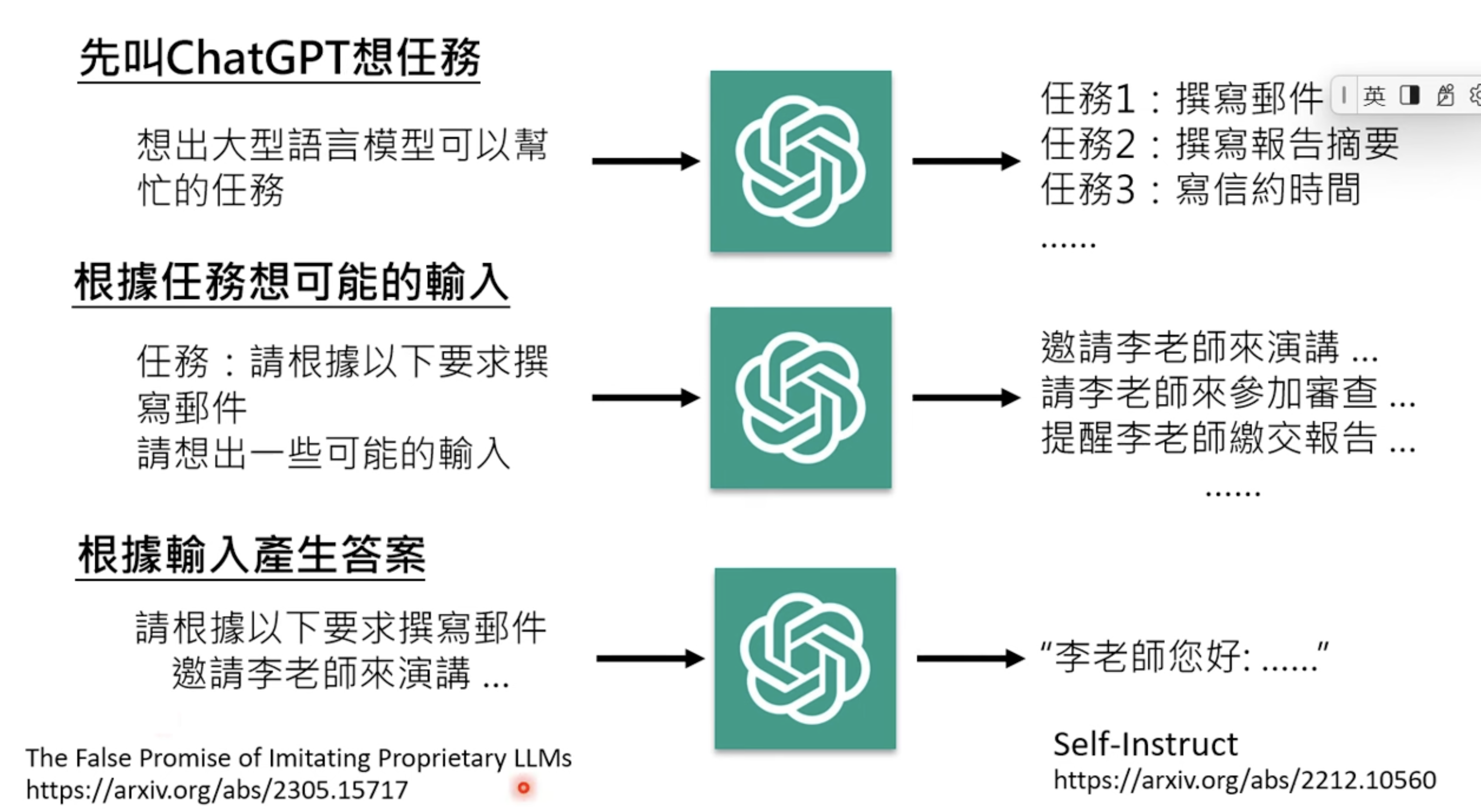
 How to get high quality FT data? Reverse GPT is a common practice, even though prohibited by OpenAI terms
How to get high quality FT data? Reverse GPT is a common practice, even though prohibited by OpenAI terms
 How to get the weights of pretrain model? It’s not impossible until Llama comes
What a great quote here!
How to get the weights of pretrain model? It’s not impossible until Llama comes
What a great quote here!
