GenAI by Hung-yi Lee 2024-03
It’s been a while that I follow Dr Lee’s 2024 lecture. But watched his video about GPT-4o yesterday and would like to continue this series
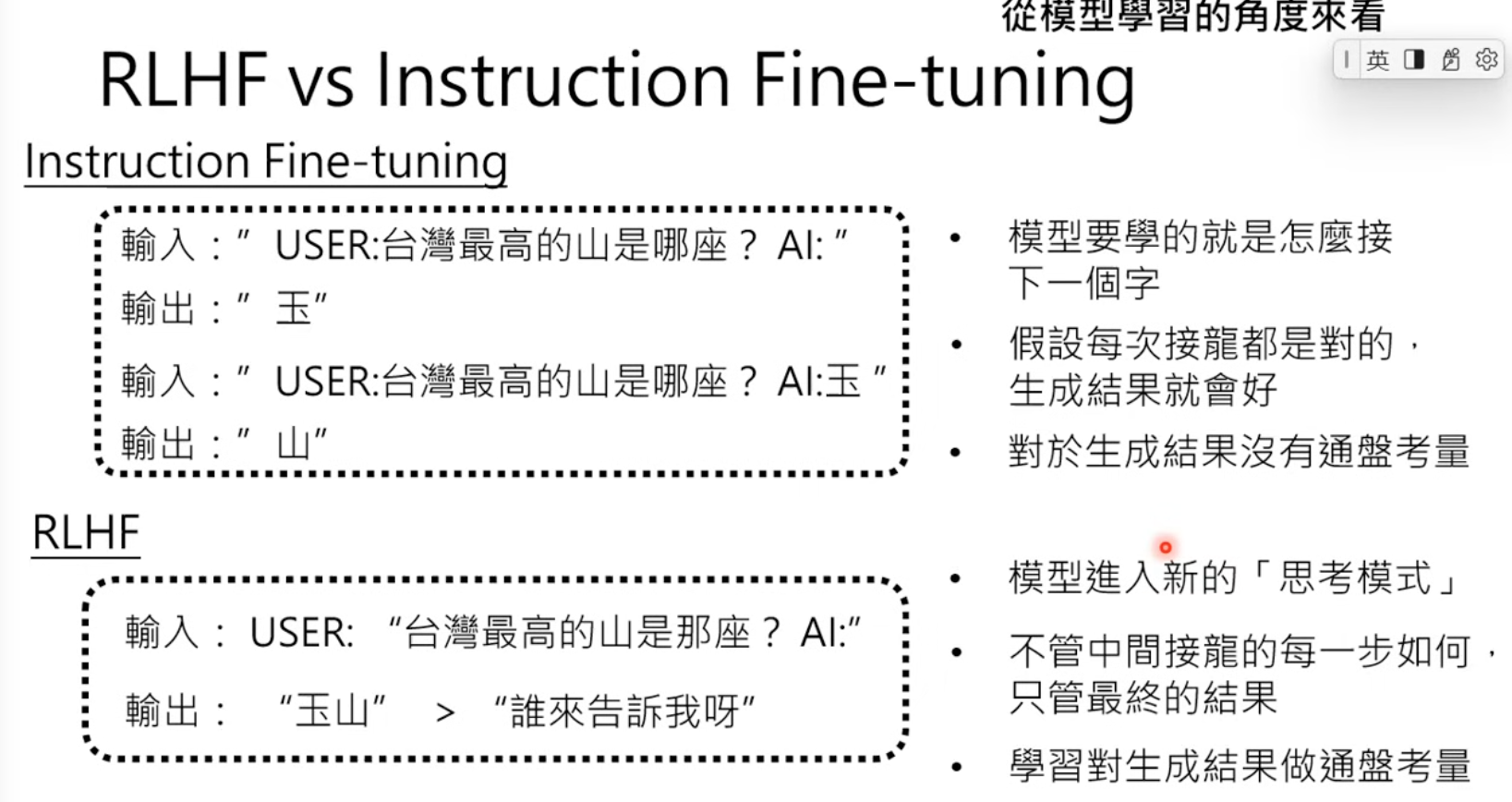
0 RLHF
First let me summary the last step of alighment RLHF.
The key takeways is that instructed FT is focus on process, versus RLHF is focusing on results.
 We can also train a reward model to simulate human preferences
We can also train a reward model to simulate human preferences
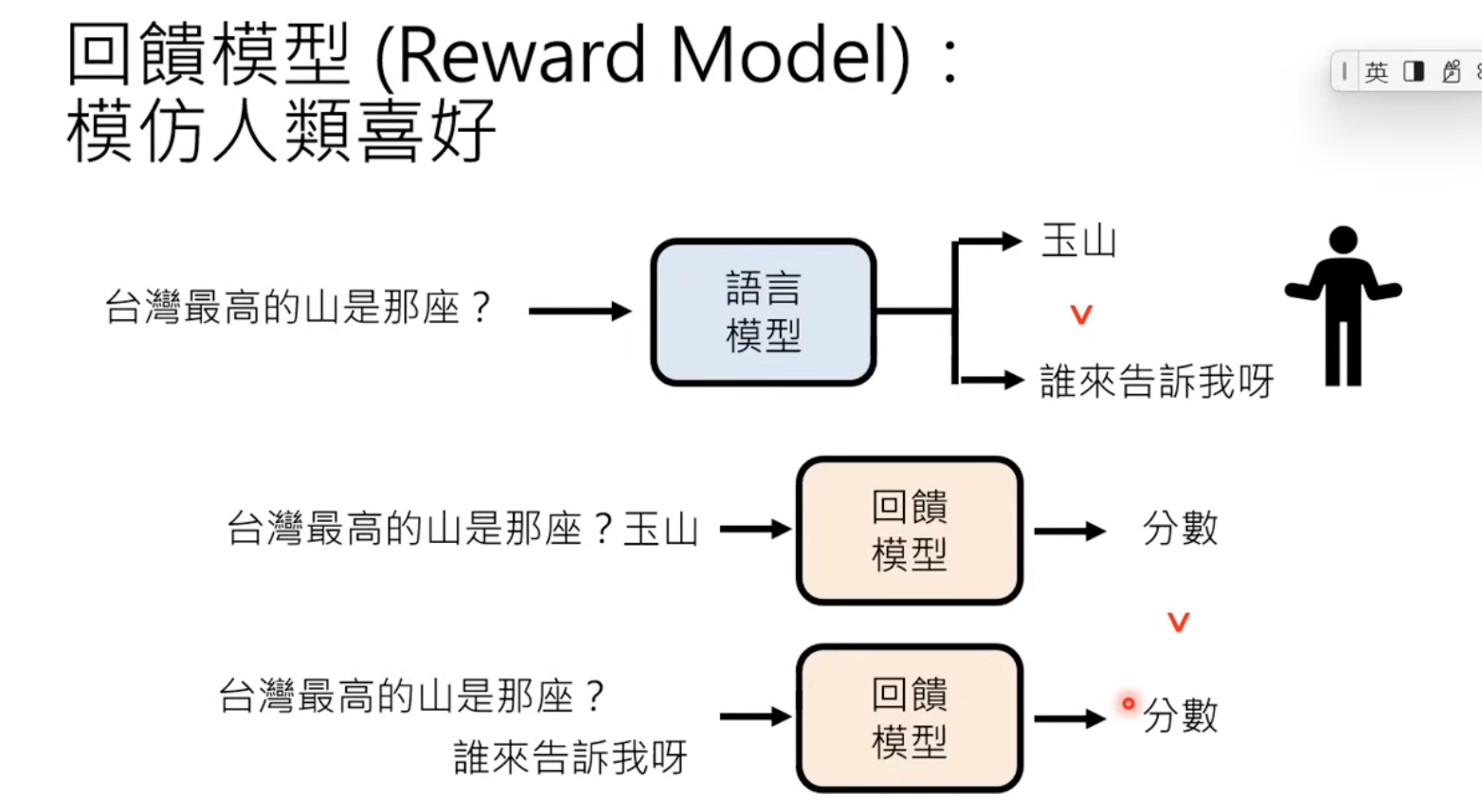 But over optimization with reward model could also leads to issues
But over optimization with reward model could also leads to issues

1 Speech models
Summarize of speech models
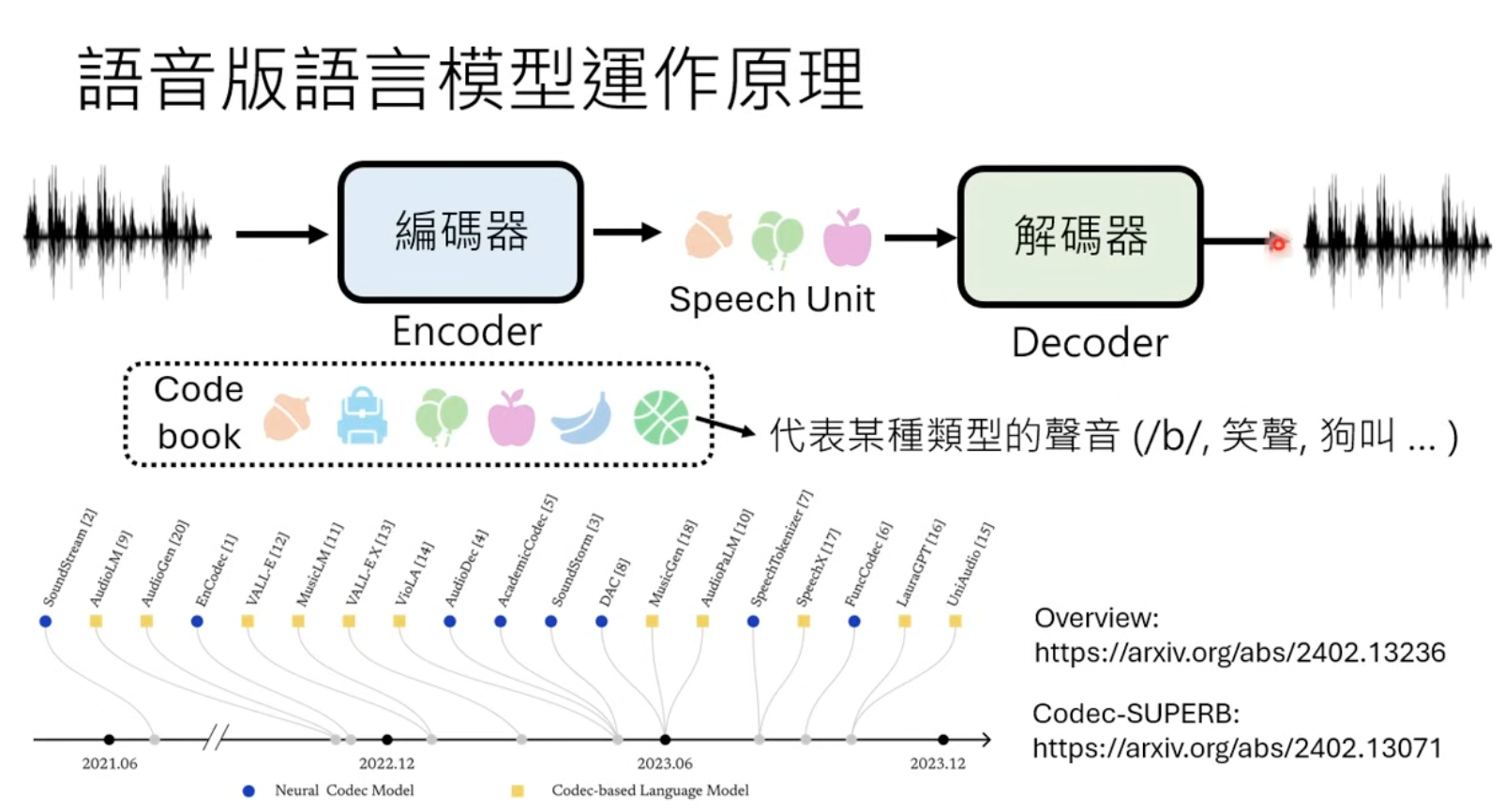 Both Meta and Google has models based on speech units
Both Meta and Google has models based on speech units
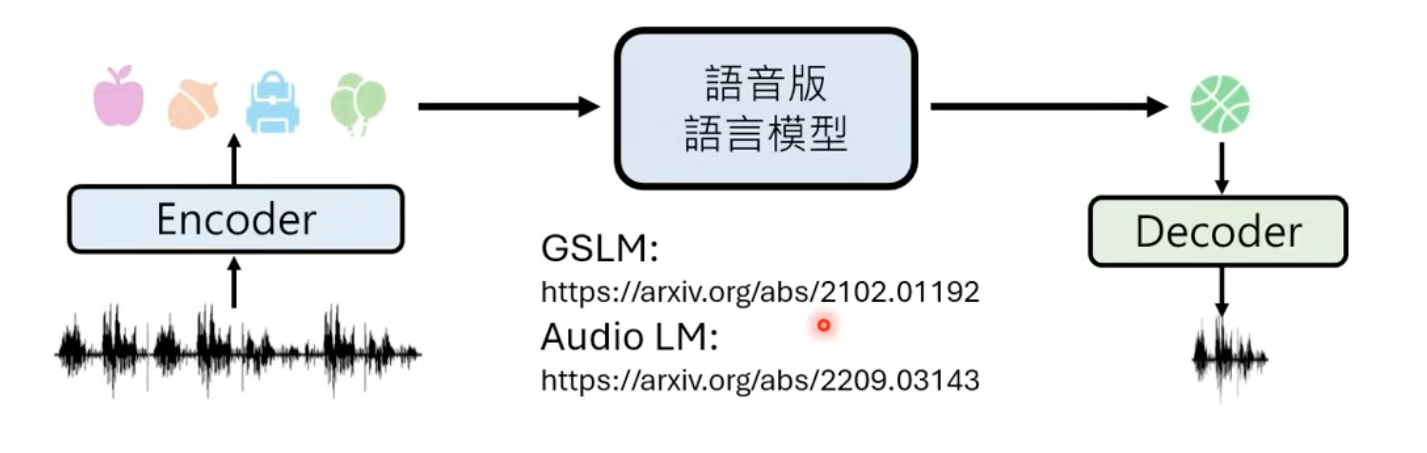
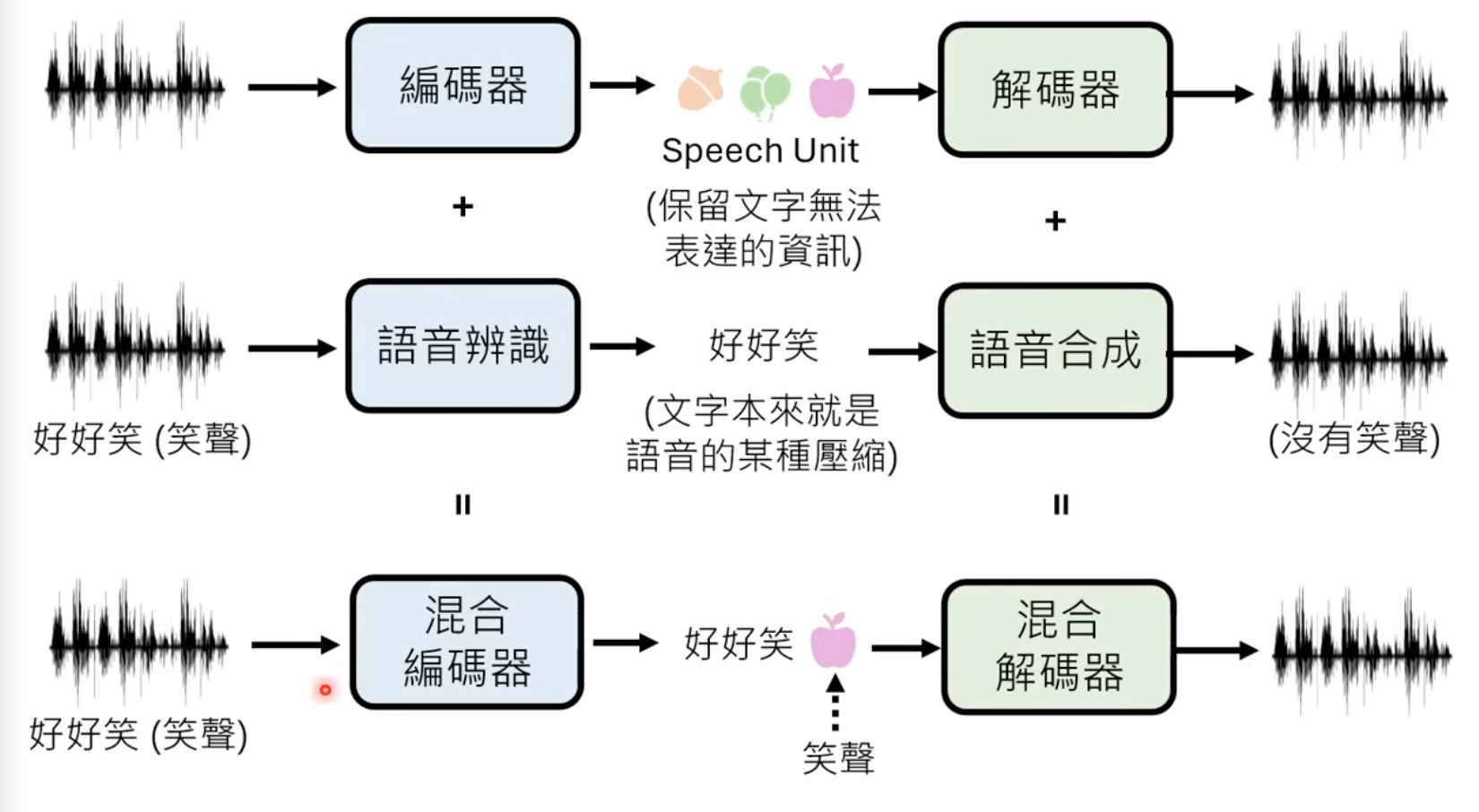
Language is actually a specially type of compression for audio, but without expressions. So there is one possible solution with combined encoders
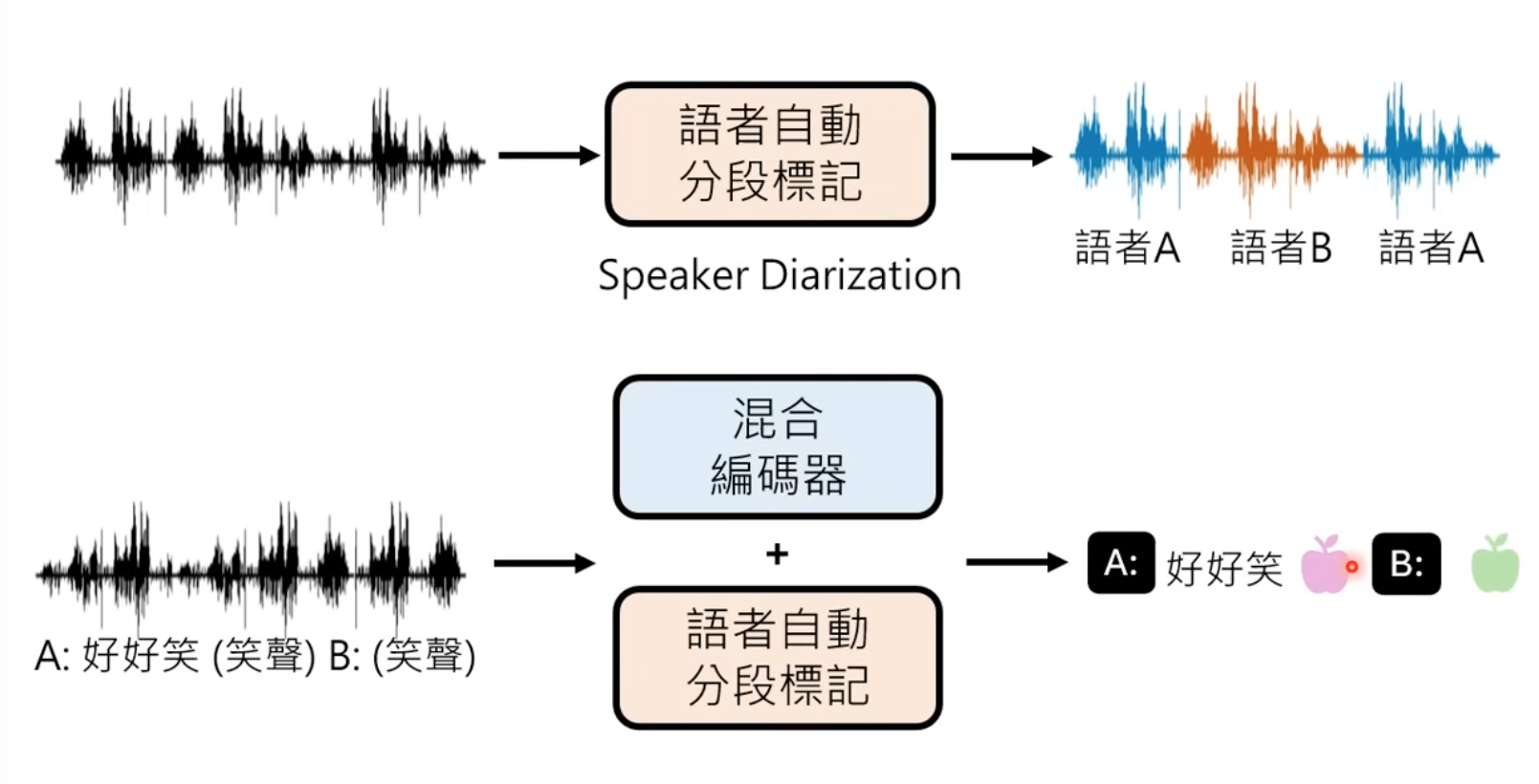
2 Speaker Diarization
This is used for distinguish different speakers.
3 Training
- It’s reported that OpenAI used over 100M hours of Youtube video for pre-training.
- It could learn some Background Music. It could be a feature instead of bugs.
- 1M hour x 60min x 100 token/min = 6 Billion tokens. While Llama3 used 15 Trillion tokens, wihch is 2500x
- Use GPT models as initialization
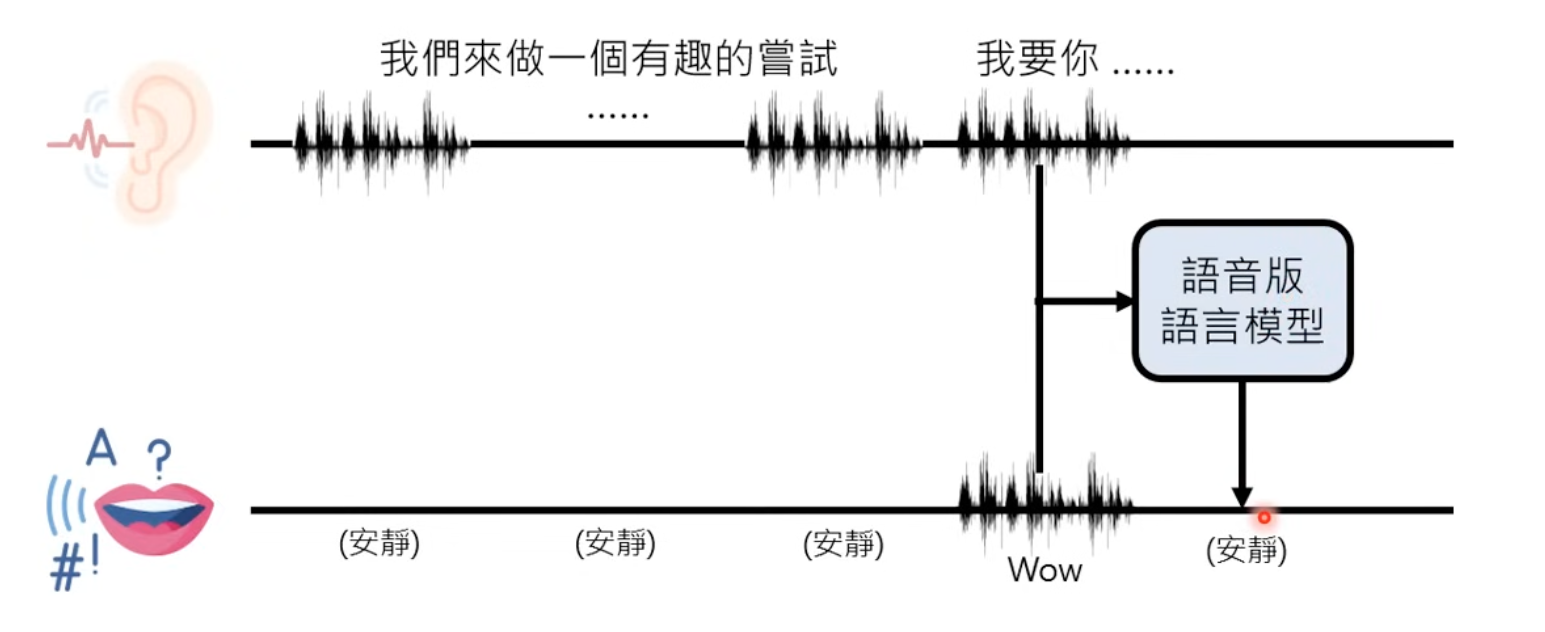
4 Speak and listening
The challenages is to tell when AI should listen, when should speak.
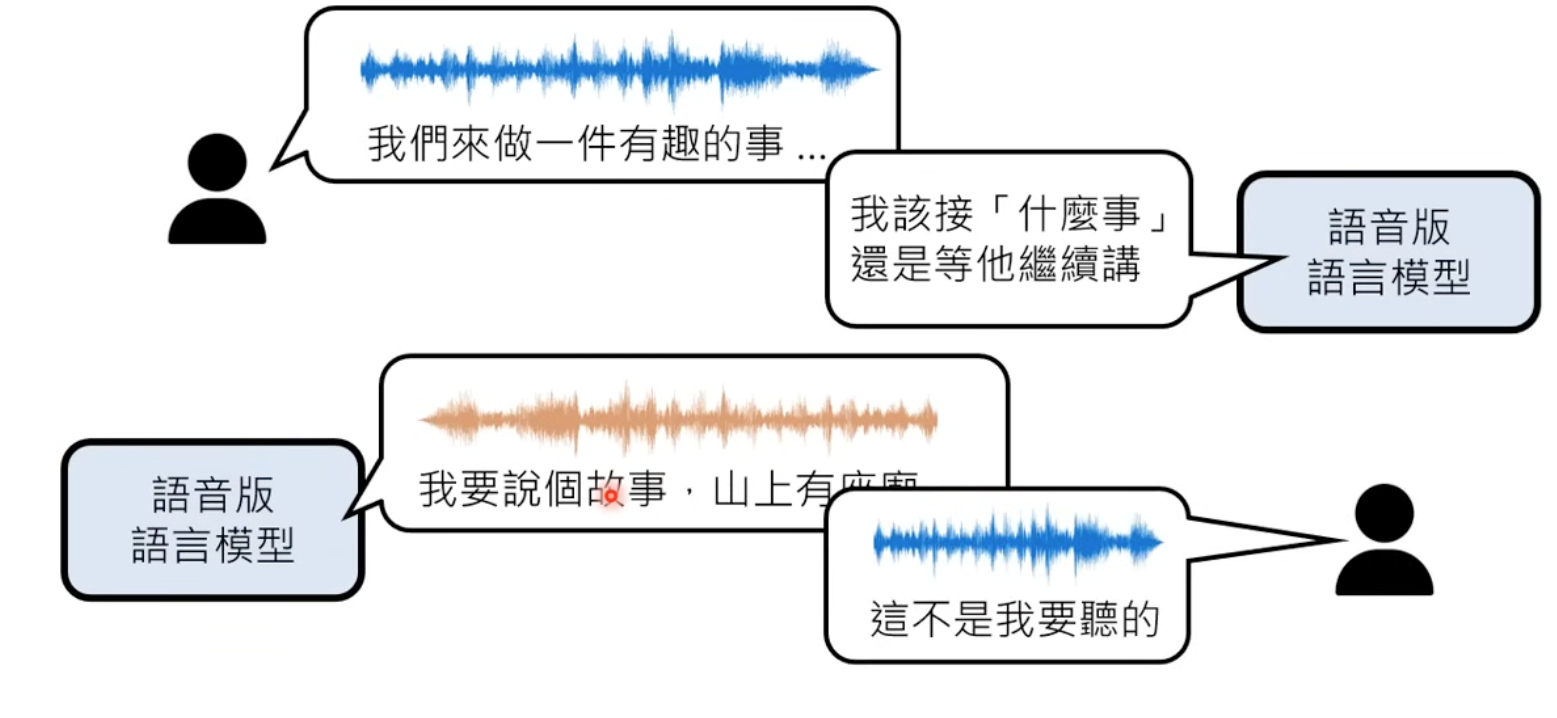 Possibile solution is get live responses of be quiet or speak.
Possibile solution is get live responses of be quiet or speak.
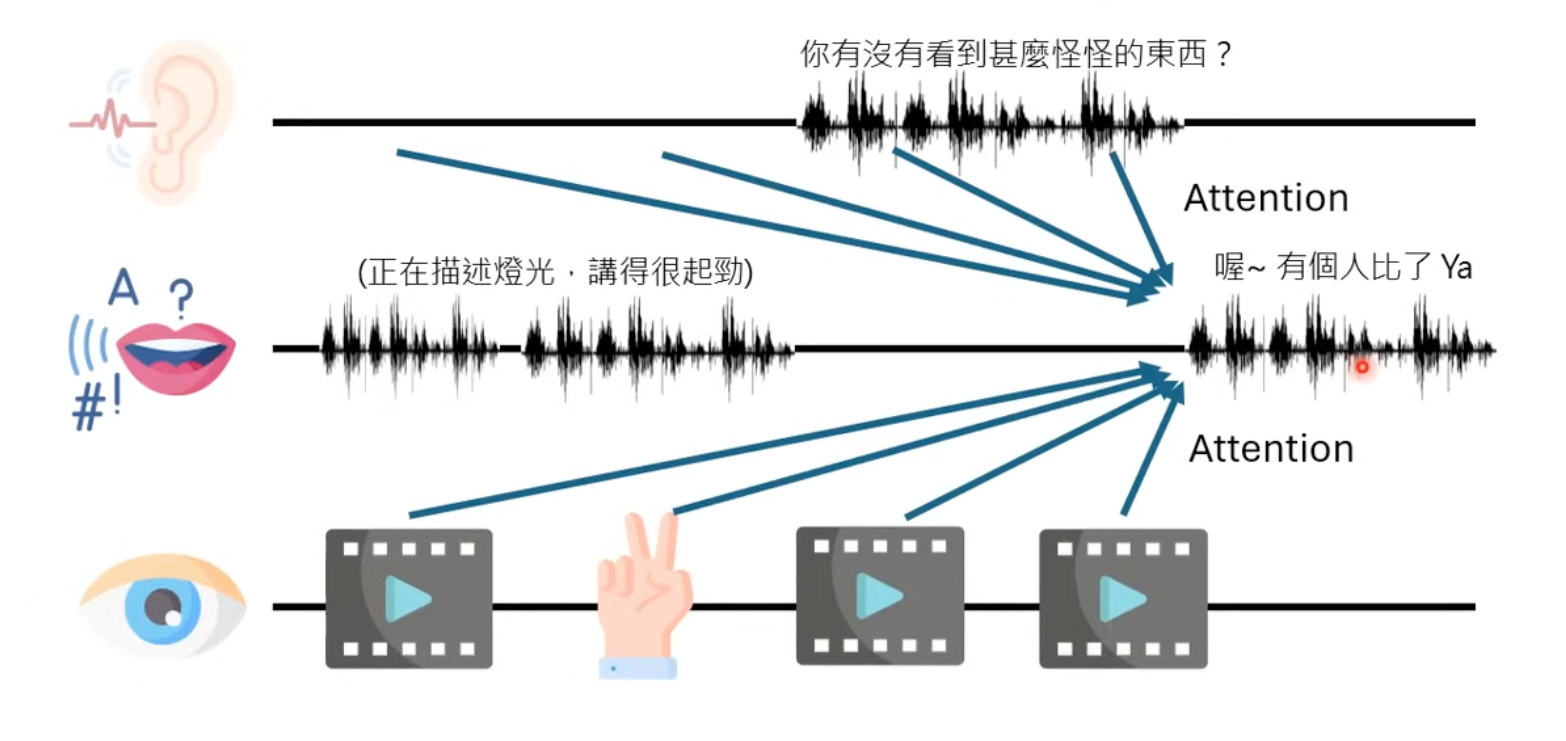
5 Look
The attention is applied to previous seen images in memory