Llama2 tricks (2)
This is summary of explanantion of KV cache and RoPE in this video. I really like how Bai explained RoPE.
1 KV Cache
First review the meaning of Q/K/V
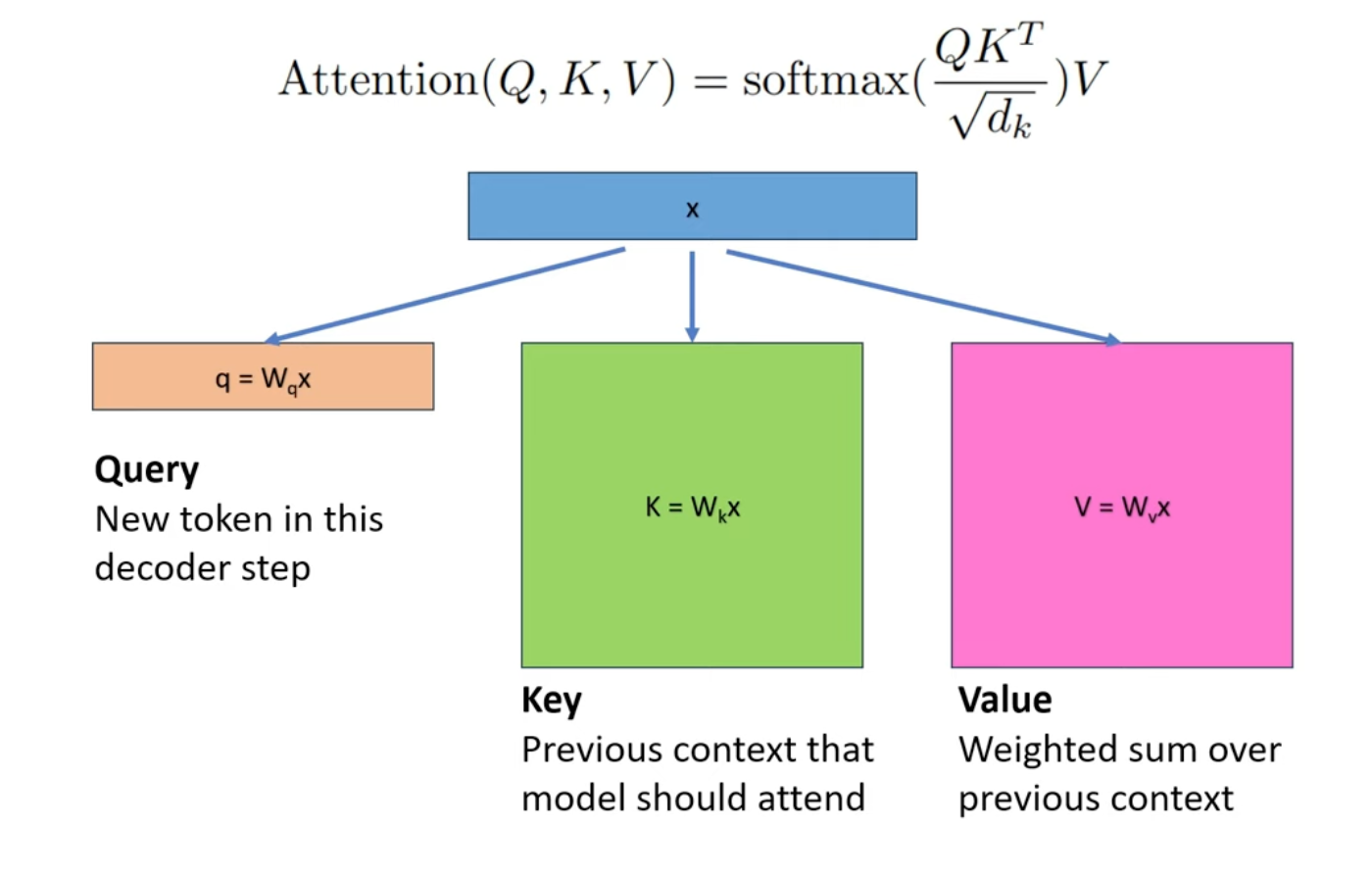
So for a word, it’s corresponding to a column in K and a row in V. It won’t change after it’s calculated. That’s why we can cache the previous results.
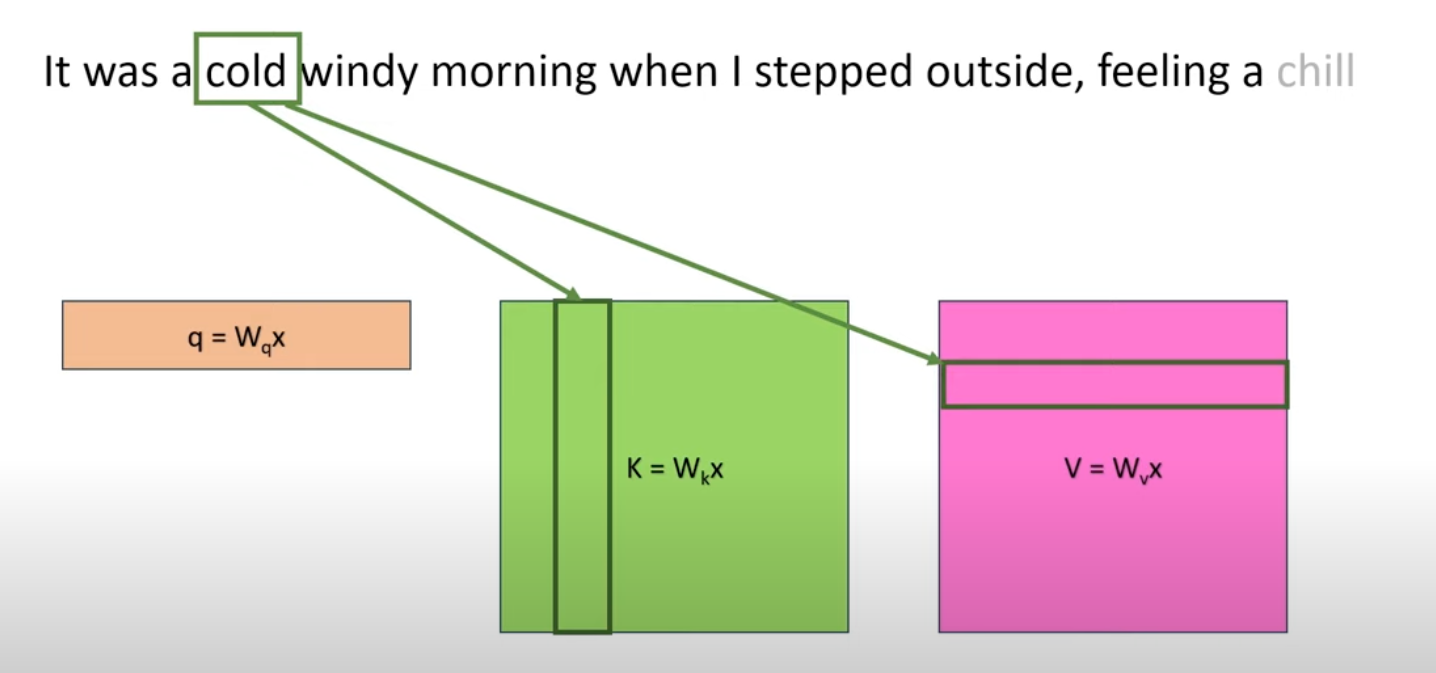 So everytime we only need to add information related to new tokens.
So everytime we only need to add information related to new tokens.
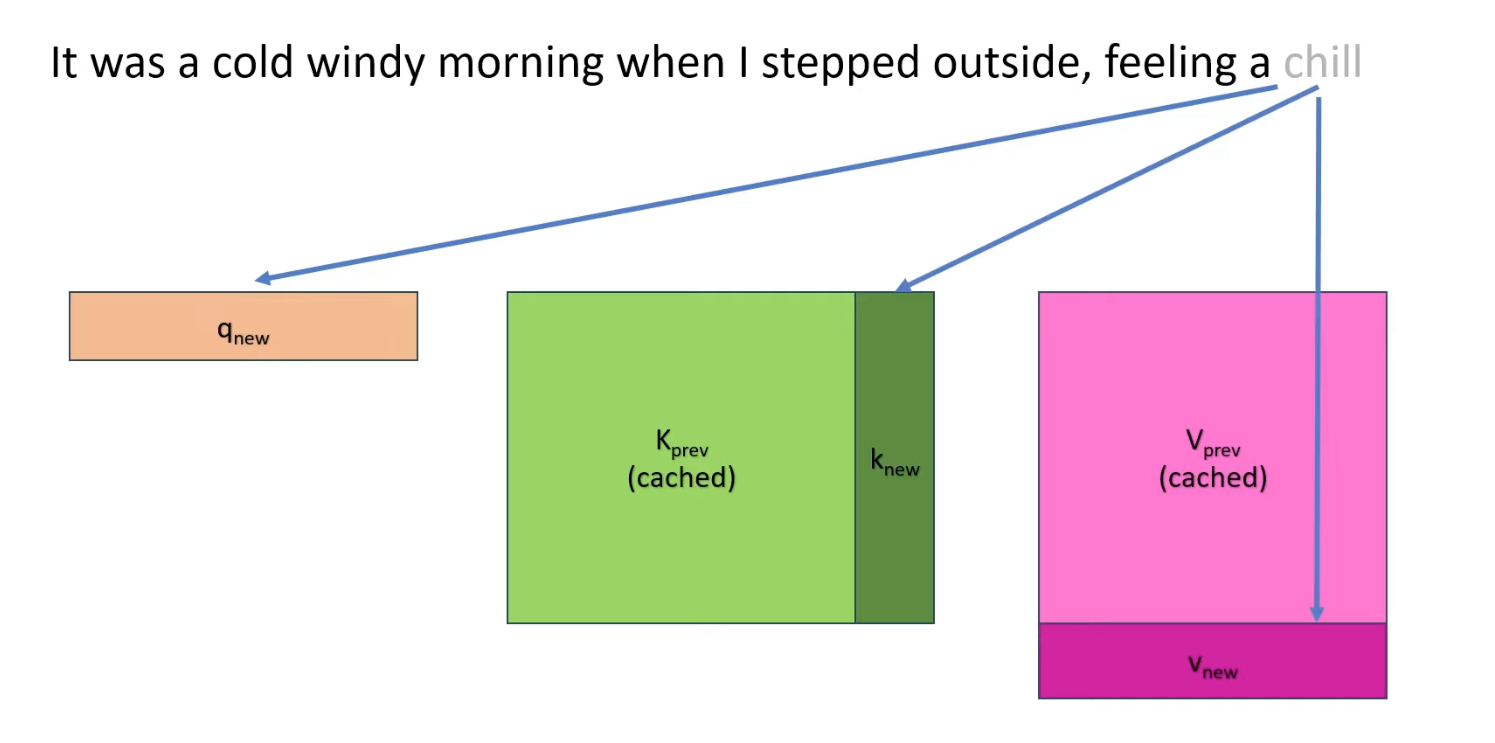 The size of the KV cache can be estimated by following formular
The size of the KV cache can be estimated by following formular

A 30B model can use up to 180GB, which is much larger than the model size.

TTFT is slower than ITL is due to no KV cache is available for the first token. I missed this question during interview…
2 RoPE
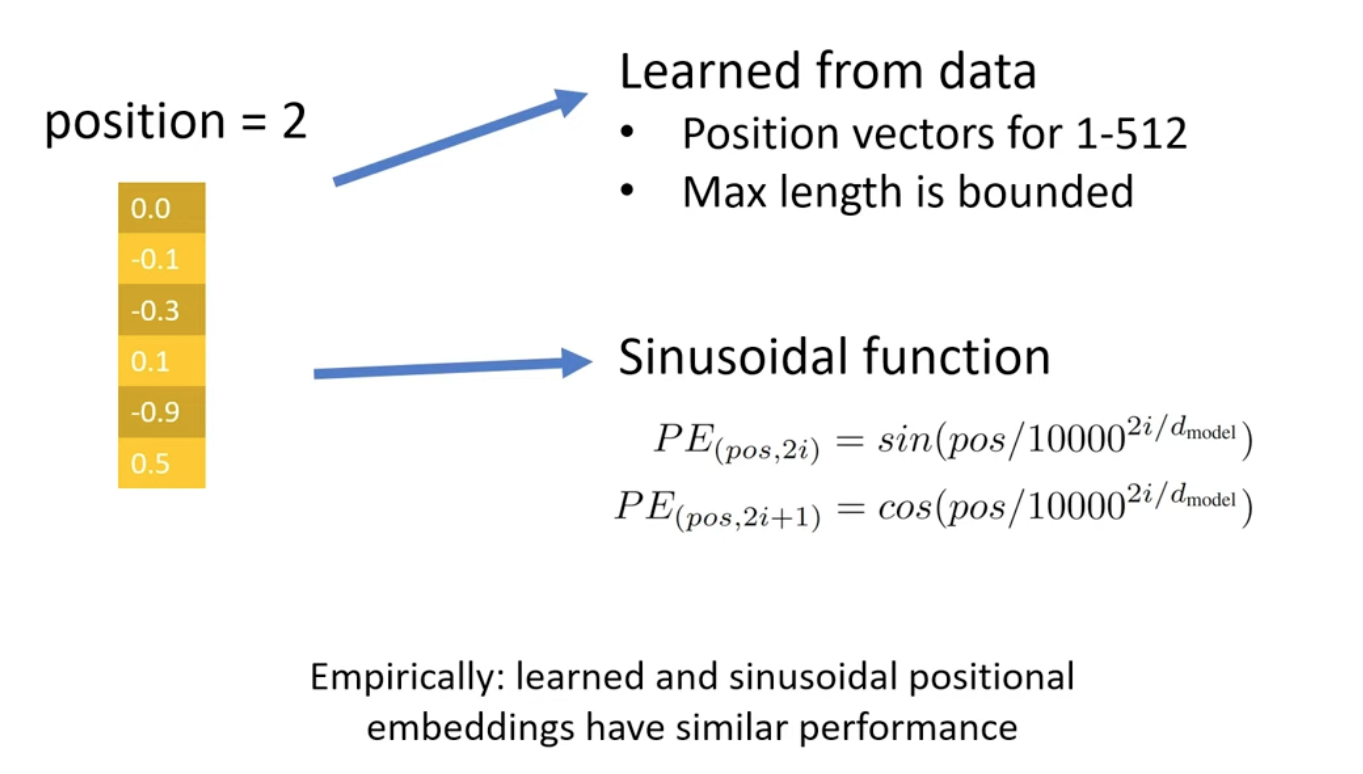
- Absolute Position Enbedding
The issues is that 1, positions are bounded, and 2, there is no relative position relationship. Pos2 and Pos500 are all differnt from Pos1.
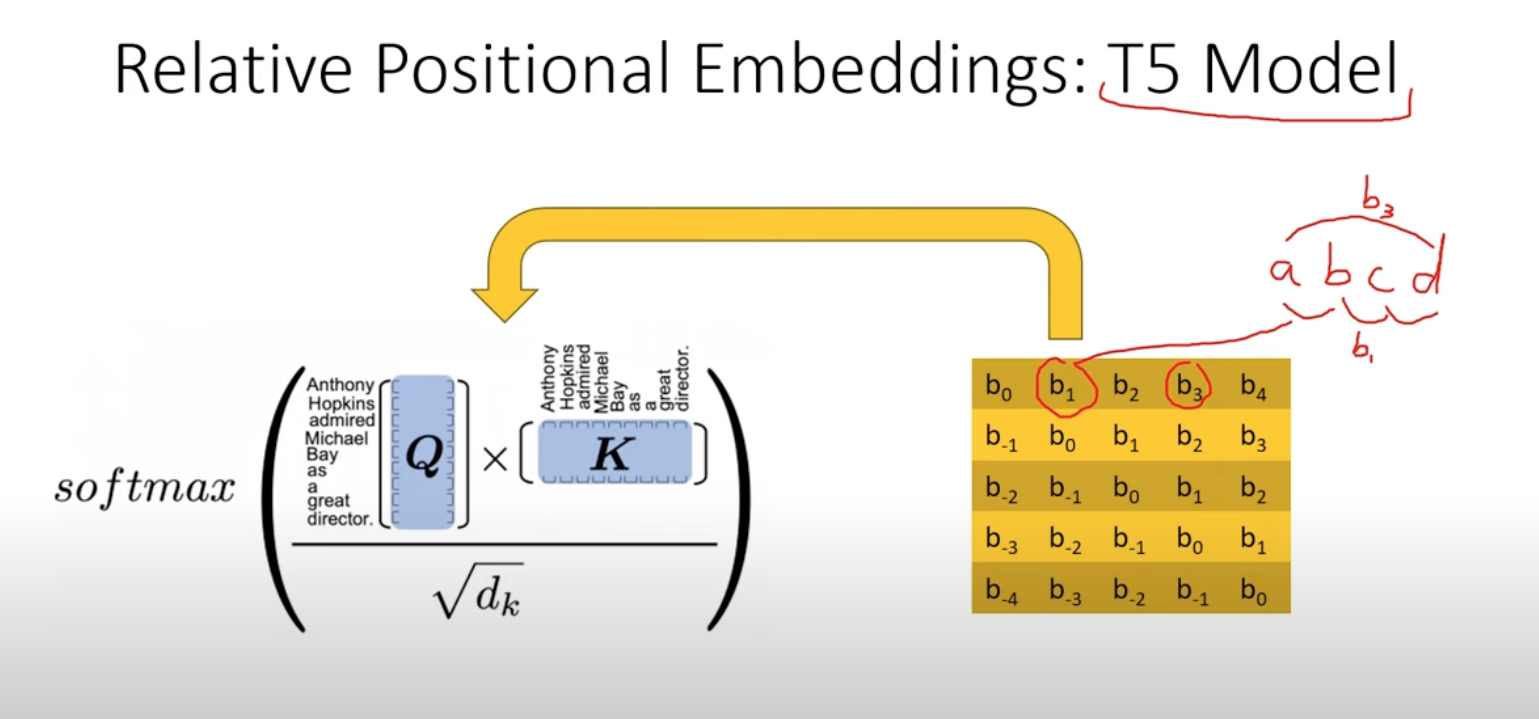
- Relative Positional Embedding
Use the relative positions between words. But it’s slow b/c it introduces extra step in self-attention and changes in each step, so we can NOT use KV cache.
- Rotary Positional Embedding
- Use ROTATION to represent the position of the word in a sentence.
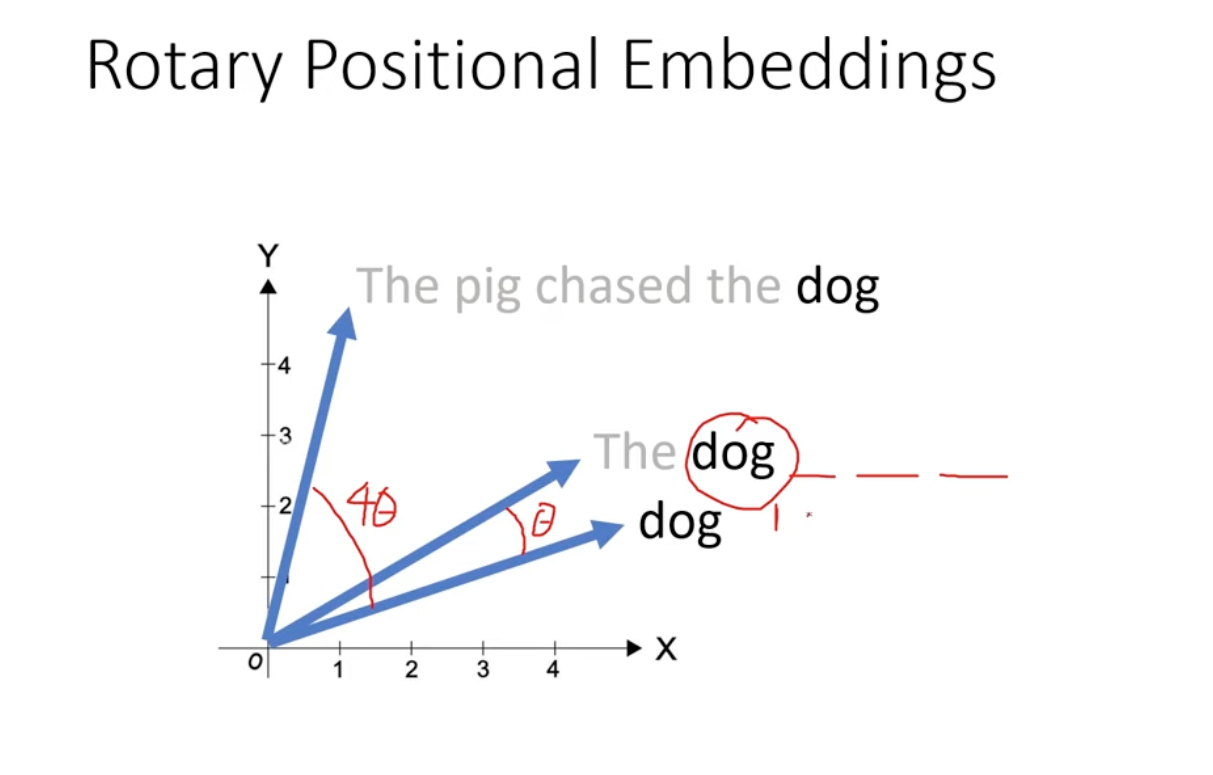
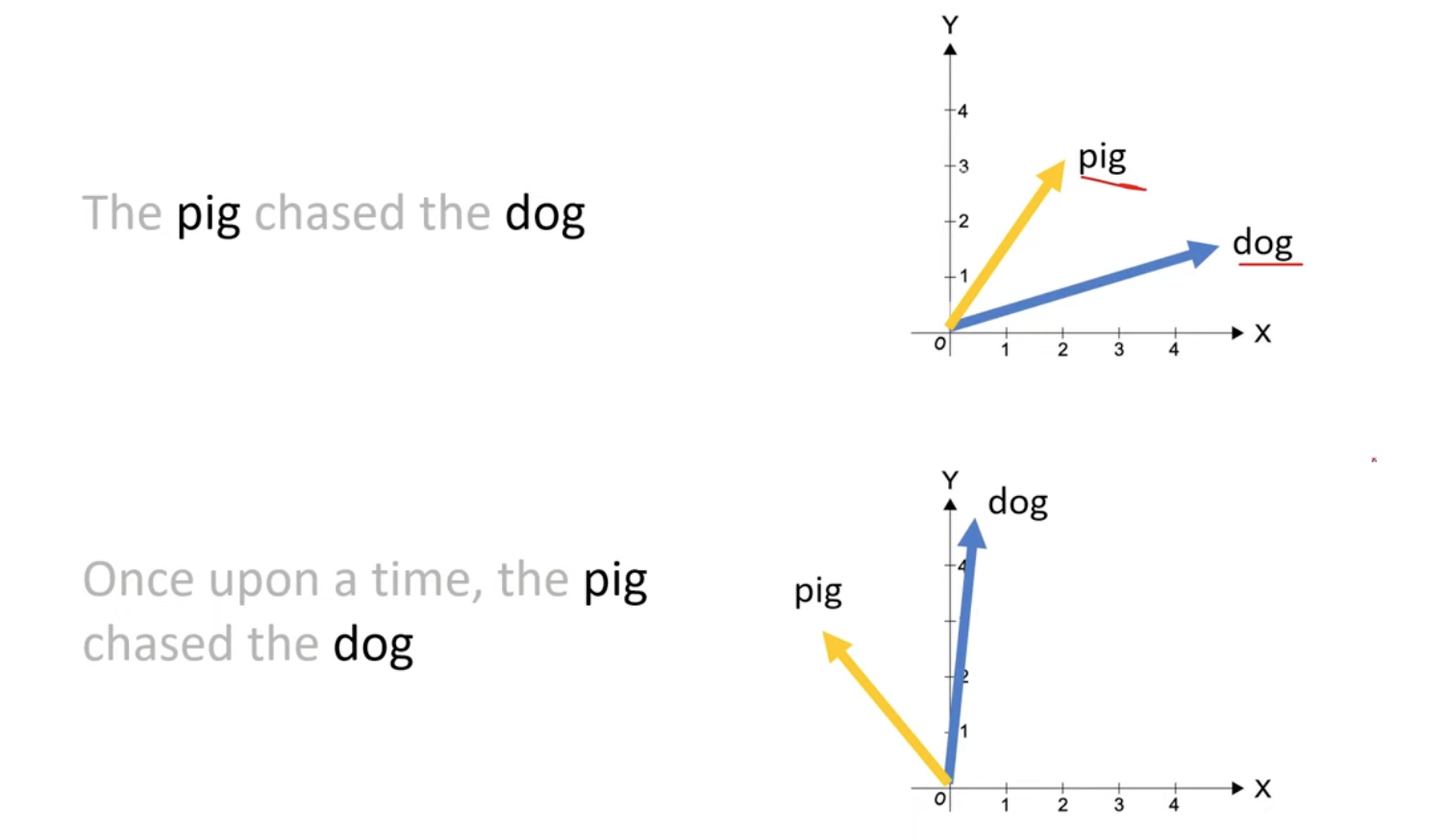
- The embedding won’t change when adding new tokens after it (so we can use KV cache!)
- The relative position of the words are preserved.
- The implemention of 2-d vectors is by the rotation matrix. and for high dim vectors, treate them as groups of 2-d vectors.
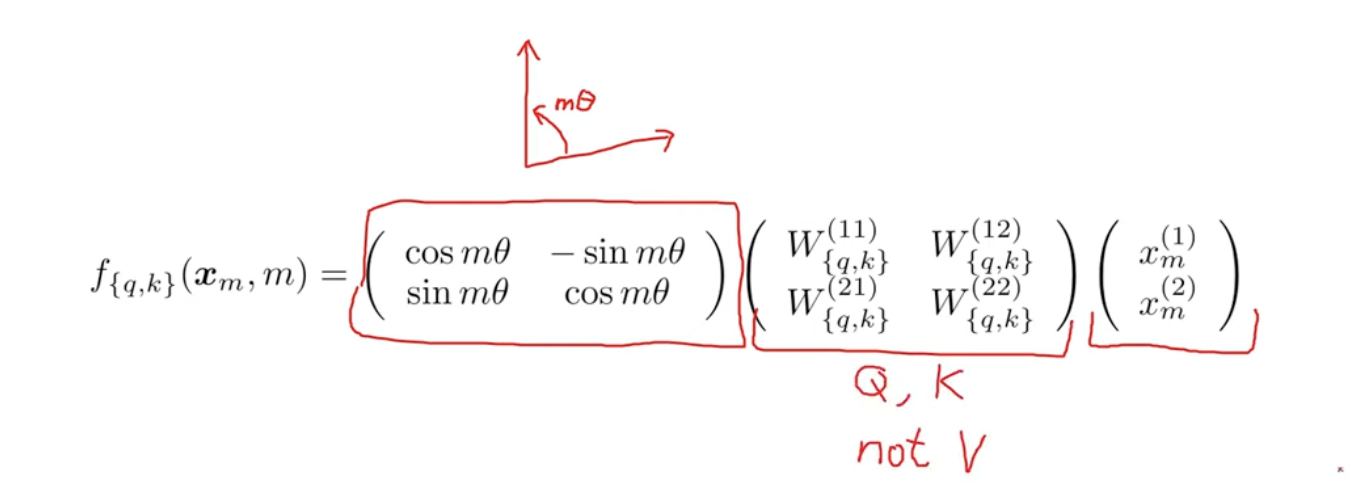
- The actually implementions is simplified as below.

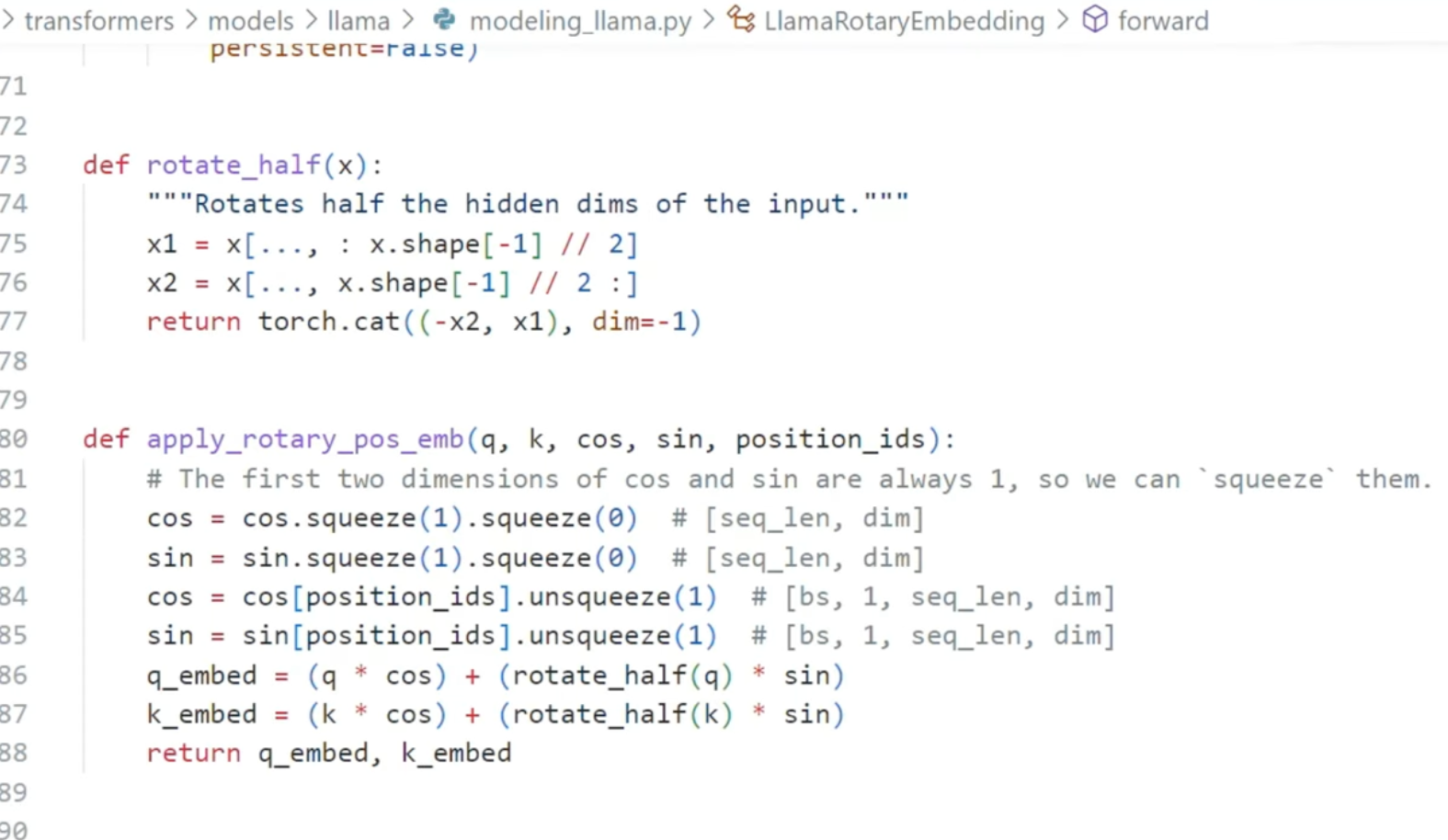
- Use ROTATION to represent the position of the word in a sentence.
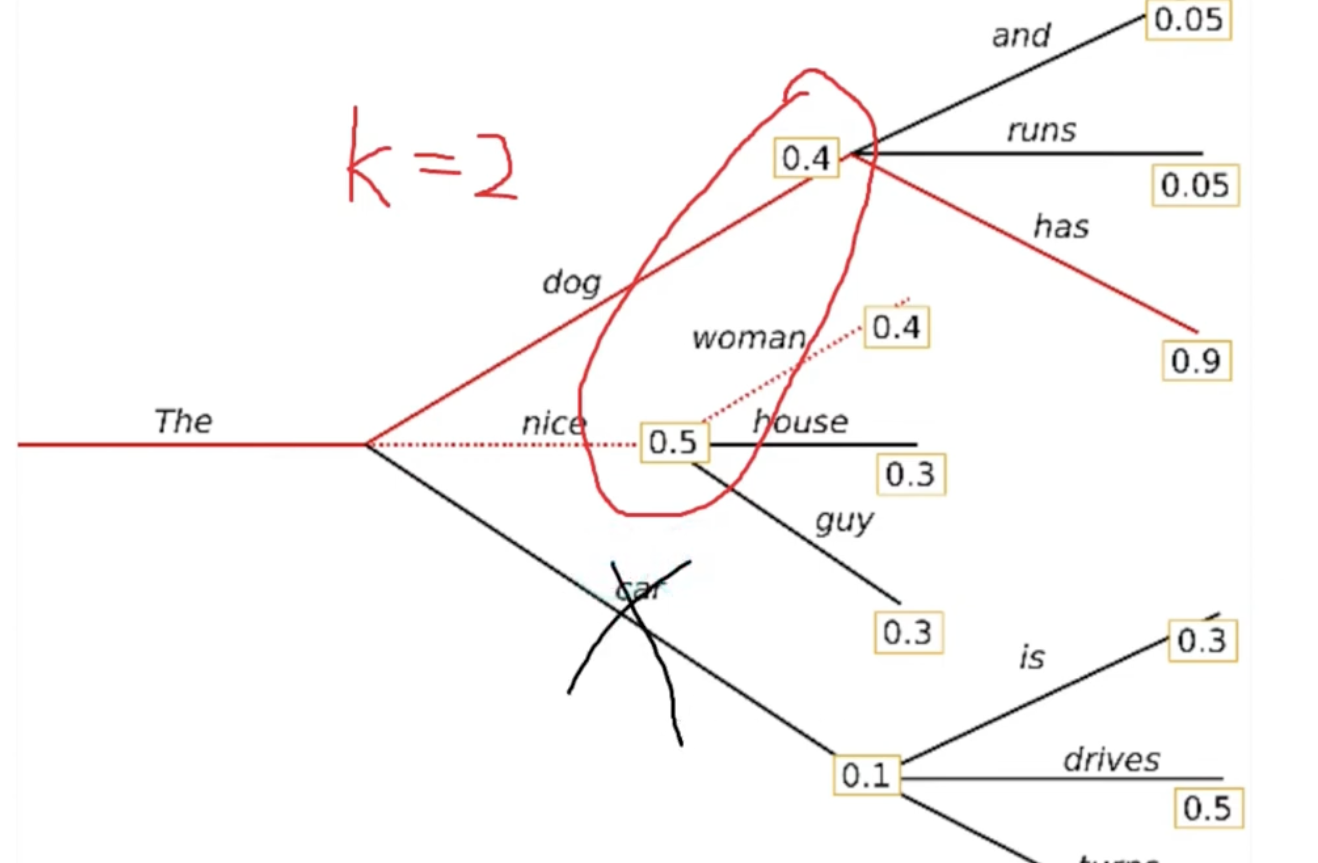
3 Beam Search
- Greedy search without beam search. Only find the one w largest prop.
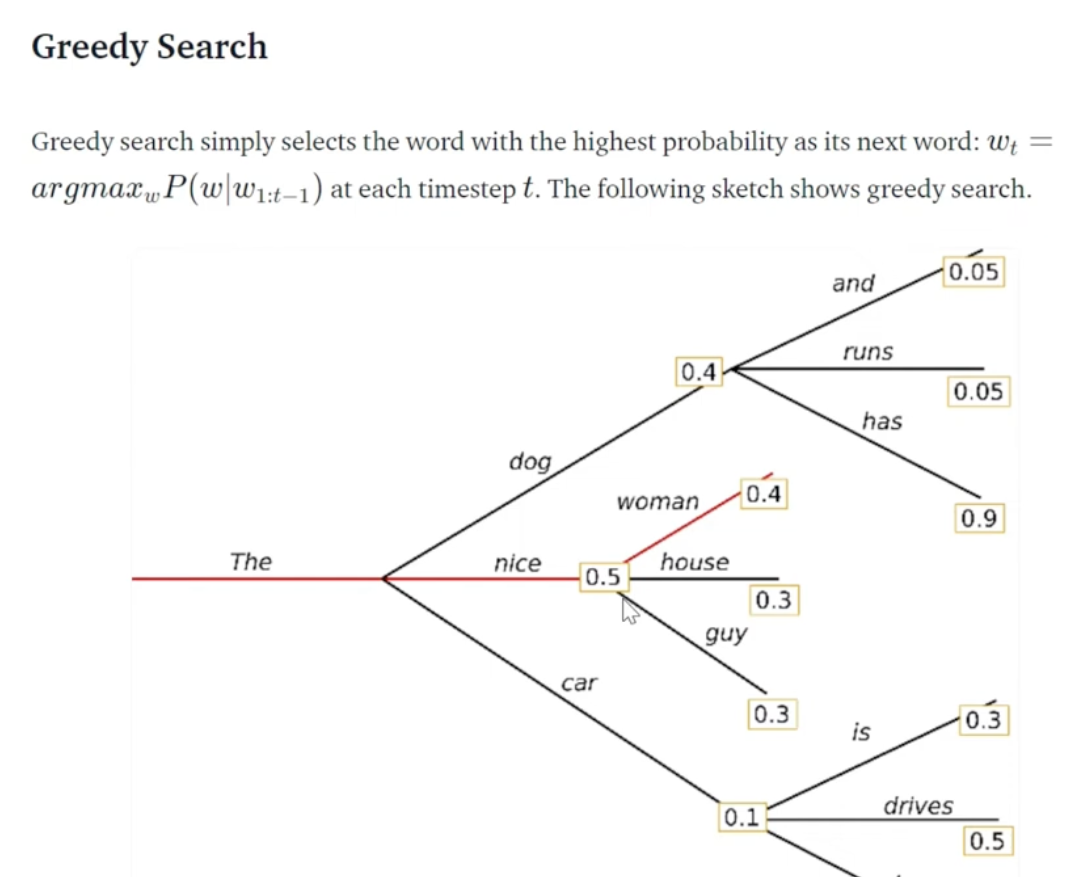
- Beam search keep top K results at each step