ML101 -2
This blog is mainly about optimizers. It’s good to review them all.
Overall problem to be solved, different parameters need different learning rate
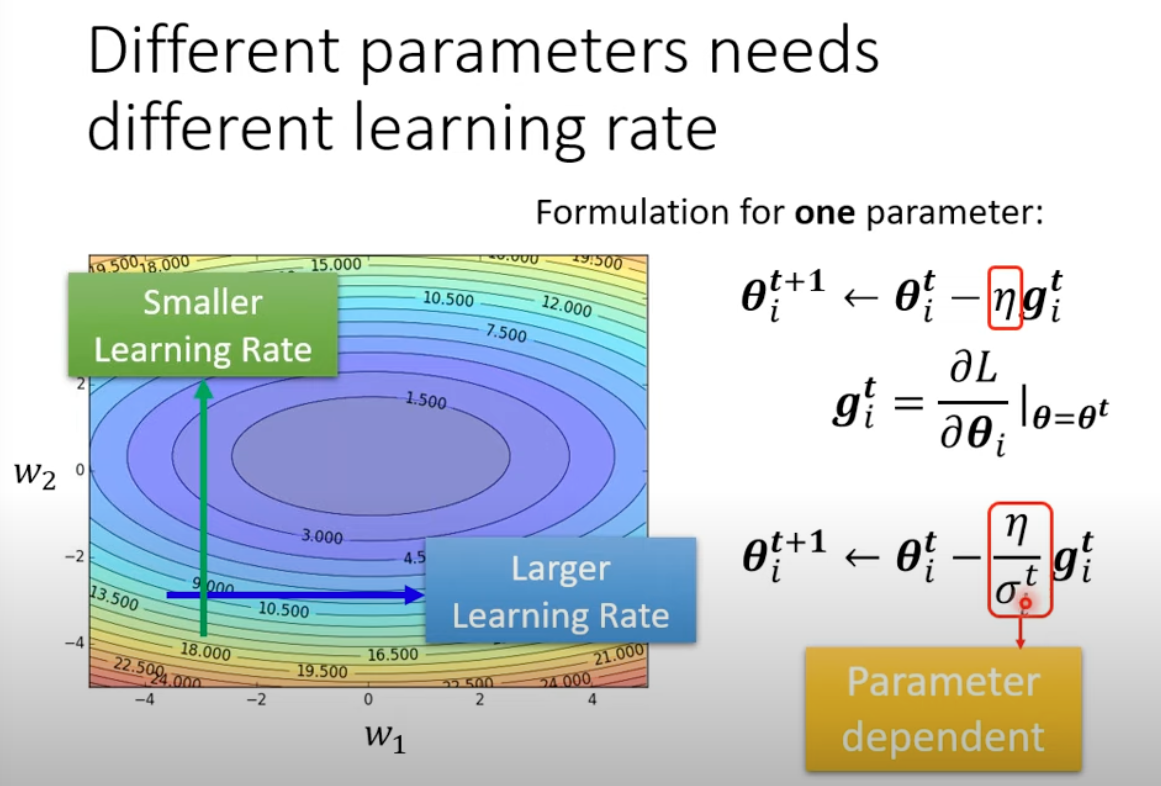
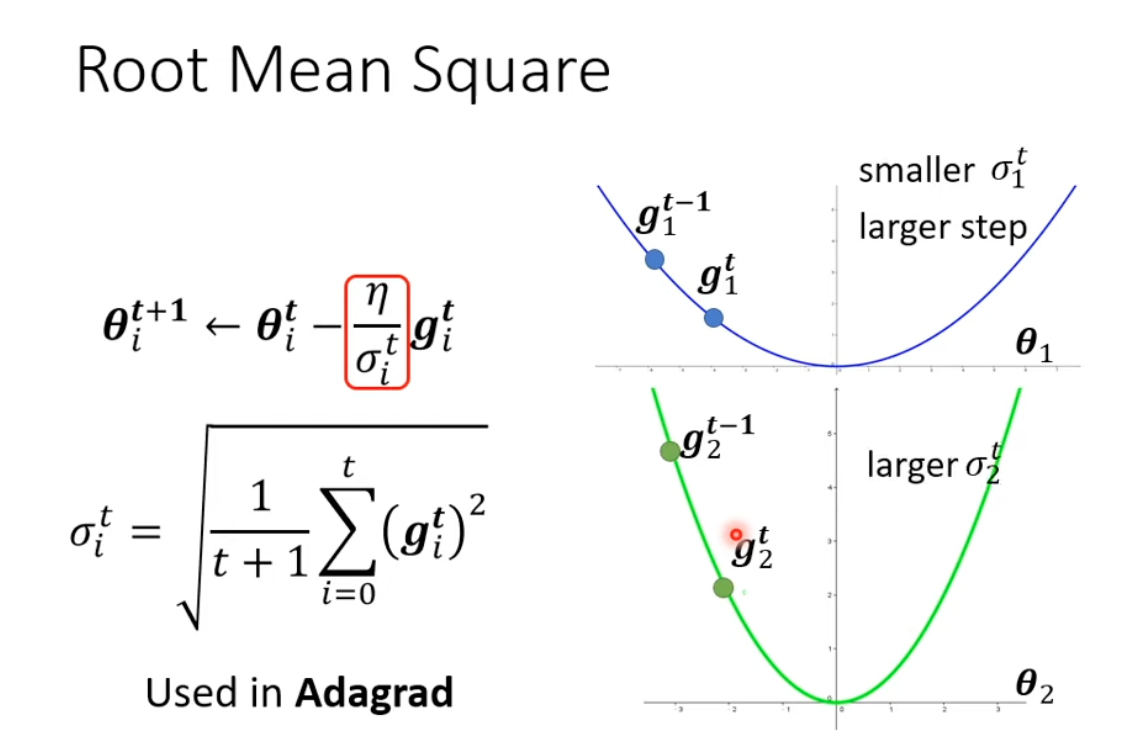
1 AdaGrad
Adapted learning rate, learing rate is customized based on values of gradient.
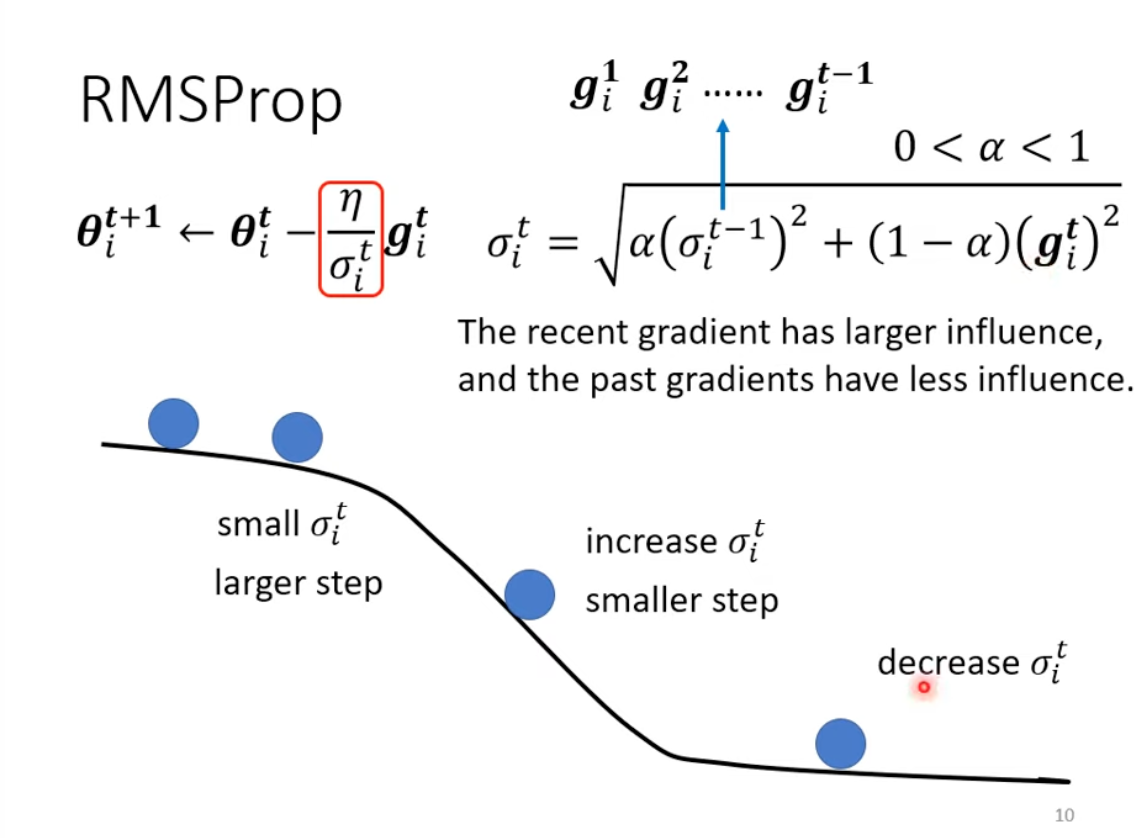
2 RMSProp
There is no paper reference to this method, interesting. The key idea is to add weight on top of AdaGrad.
3 Adam
OK, this is the most popular optimizer. and it’s simply is the combination of two preivous methods.
Adam = RMSProp + Momentum

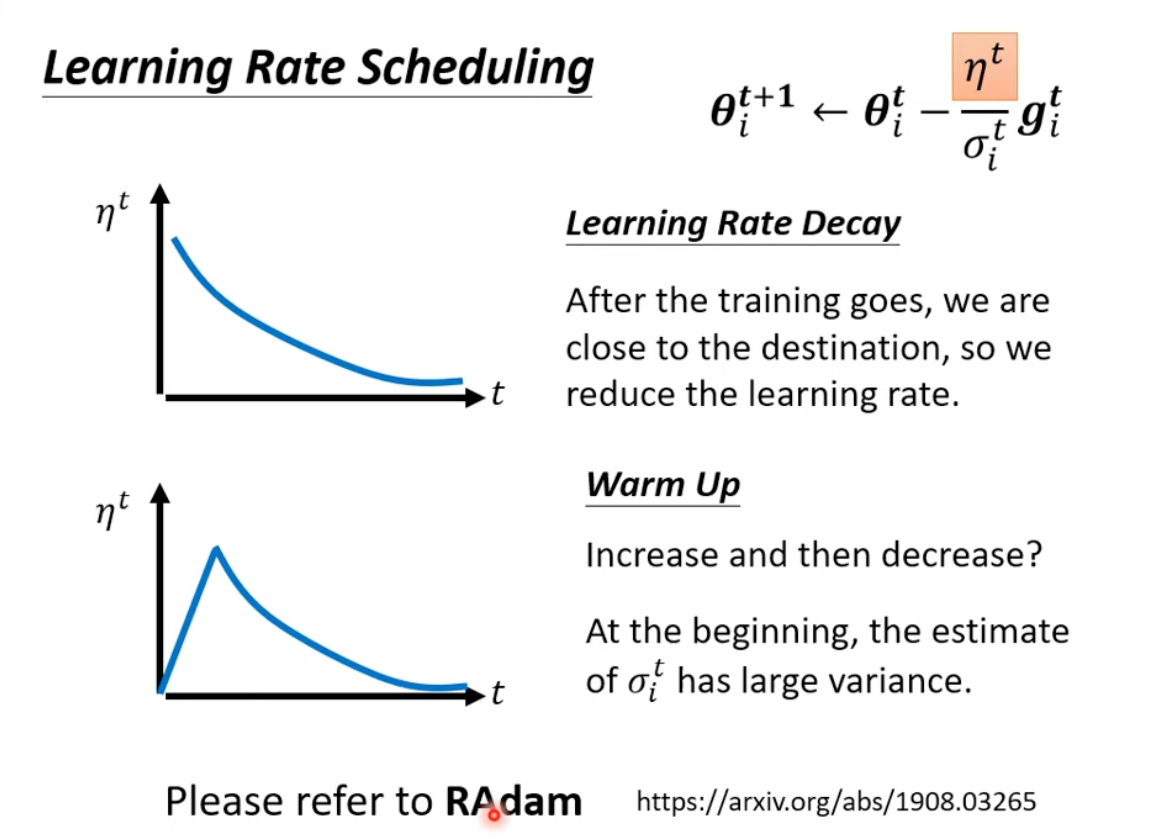
4 Learning rate scheduling: Warm up
Warm up has been used in ancient papers like Residual Network and Transformers.
 and RAdam paper have more details
and RAdam paper have more details
5 Summary
All these methods here are focusing on how to avoid local min in grooved surface.
Next chaper will focus on how to smooth the surface
