ML101 -3
Start with Regression vs Classification. and introduce softmax
It seems there are long stories behind softmax, rather than normalization
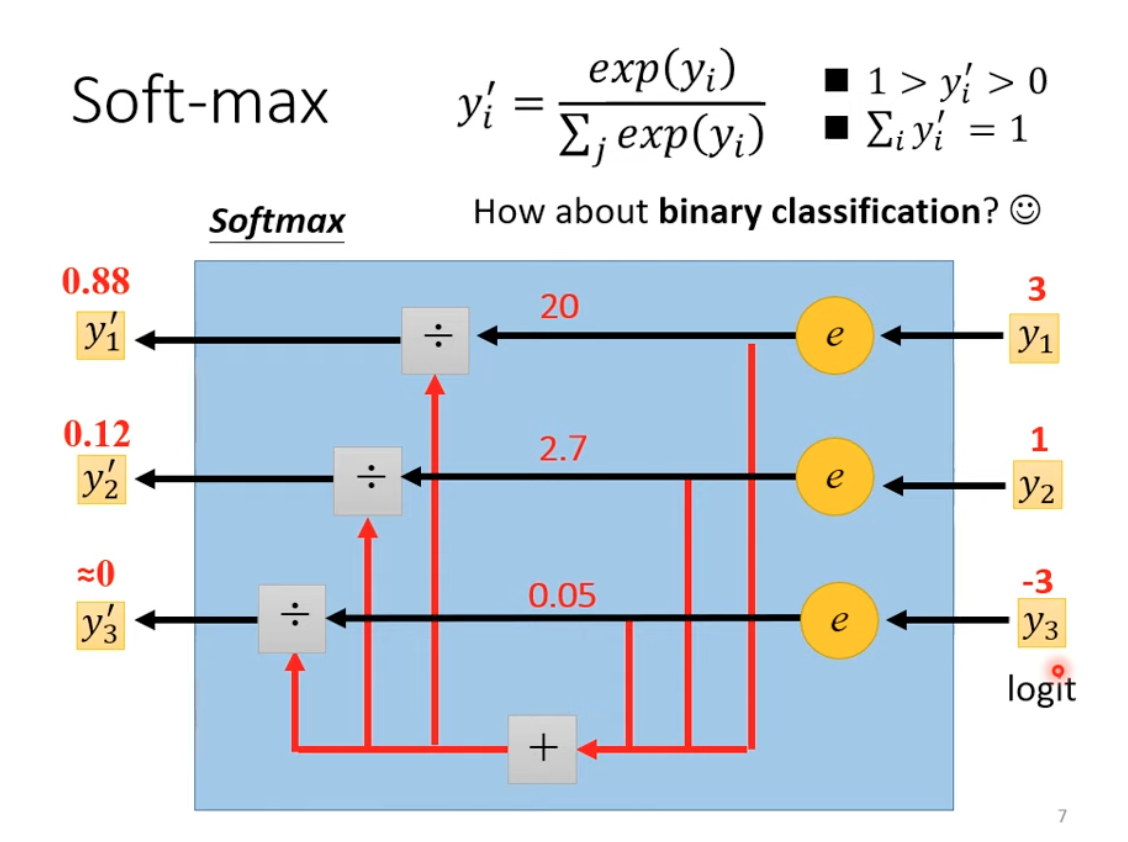 (Answer: Use Sigmoid for binary classification, which is equivalenet to Softmax in this case)
(Answer: Use Sigmoid for binary classification, which is equivalenet to Softmax in this case)
1 Loss functions
Cross-entropy is actually based on maximizing likelihood method
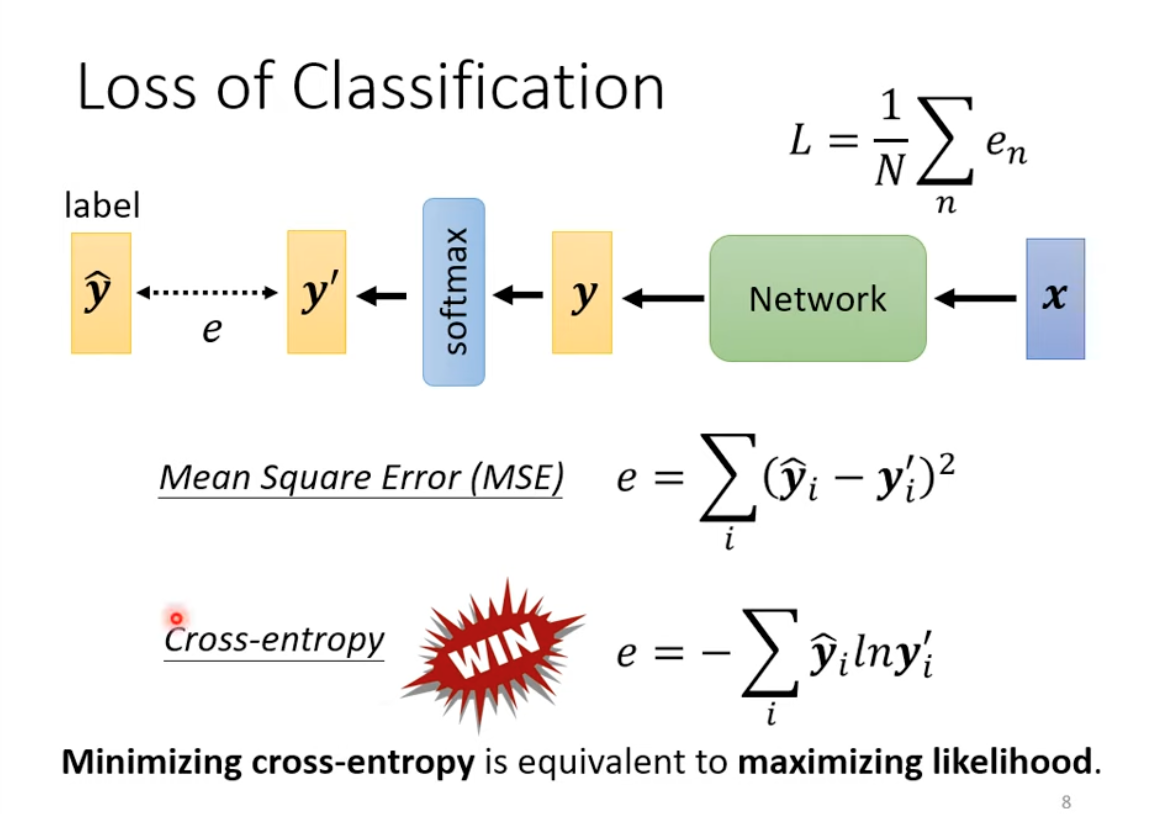
Cross-entropy surface is more smooth and not easy to be trapped by local min.
2 Batch Normalization
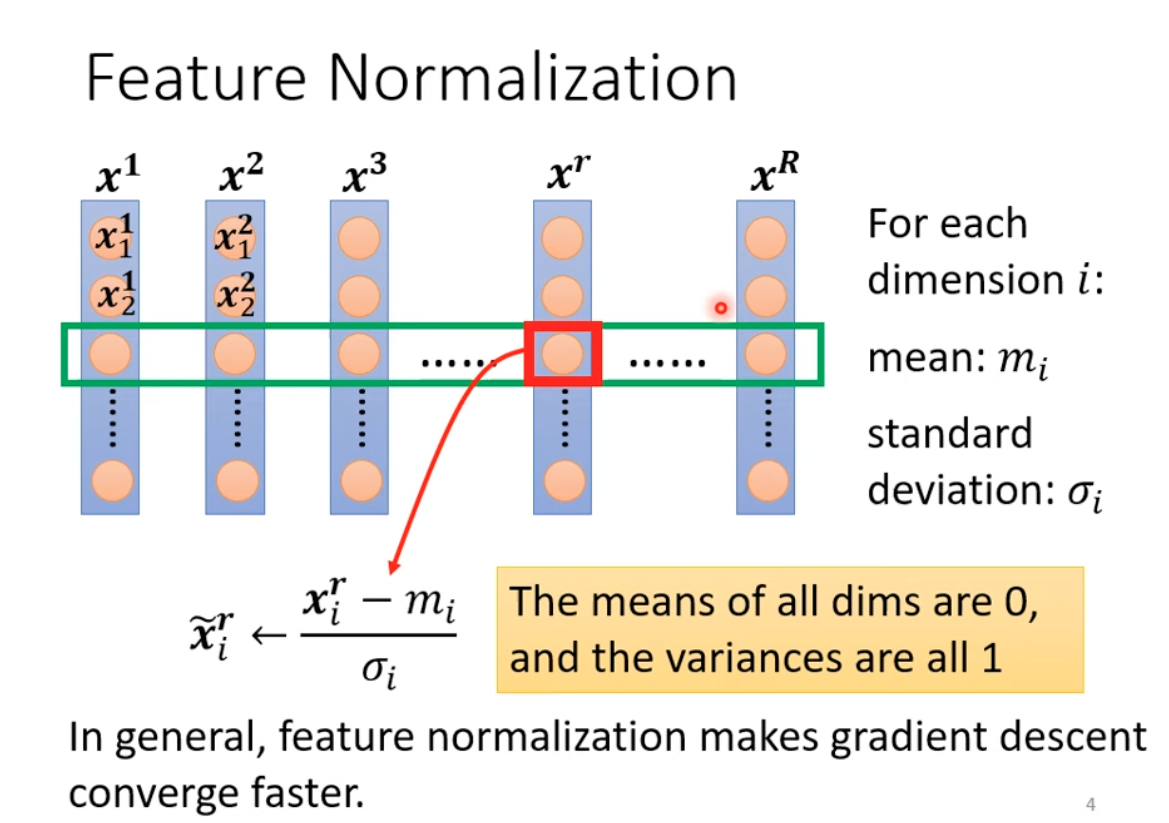
Feature normalization is important when different feature have different range. In general, it makes gradient descent converge faster.
Even if you have feature normalized, after first layer of networks, the output are no longer normalized. So we’d better normalize them again, with different sample data, in another word, with in a batch. That’s where batch normaliztion applies.
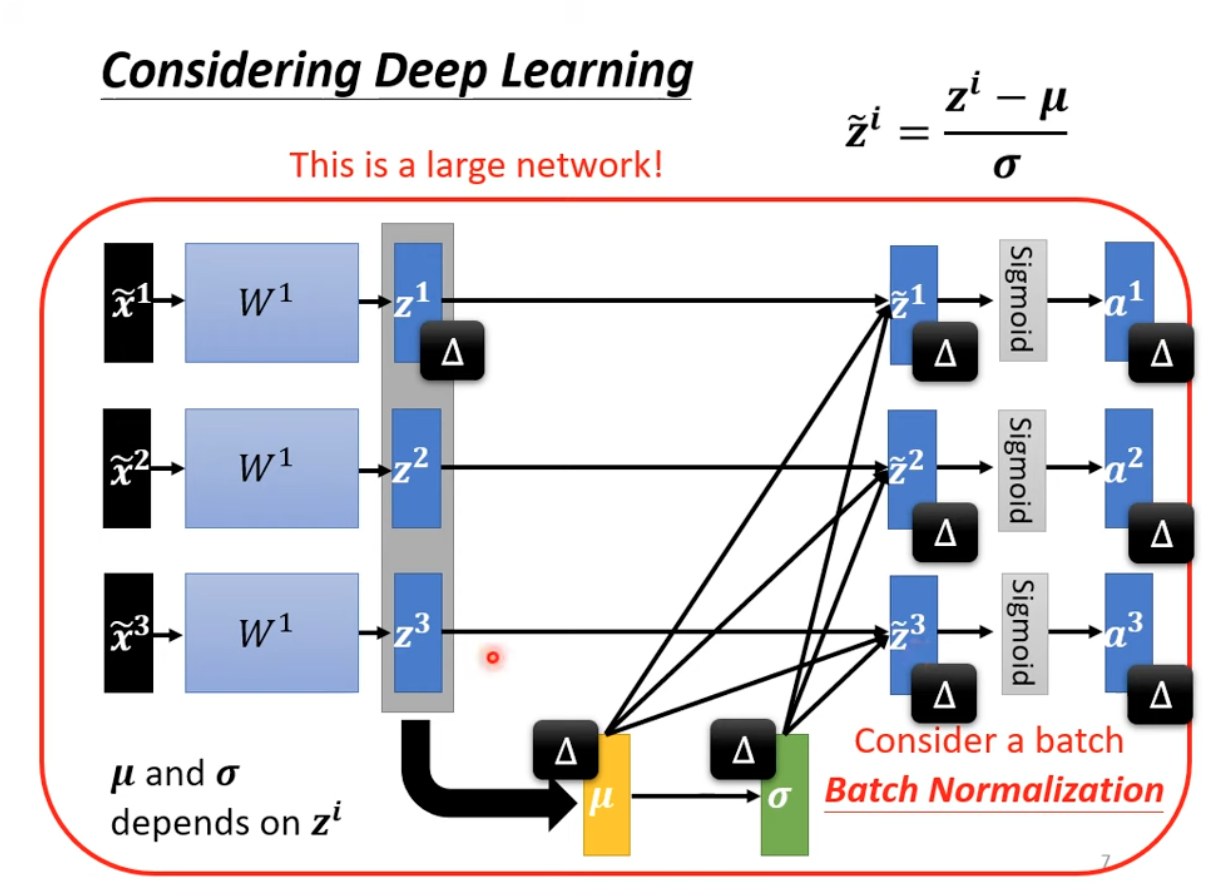
During inferences, we don’t always have a batch, and we can’t simplily use the norm/var from the whole training data like feature norm, so the weight norm/var are the solution here.

Why batch norm helps?
Internal Covariate shift doesn’t NOT supported by data, even though sounds making sense.
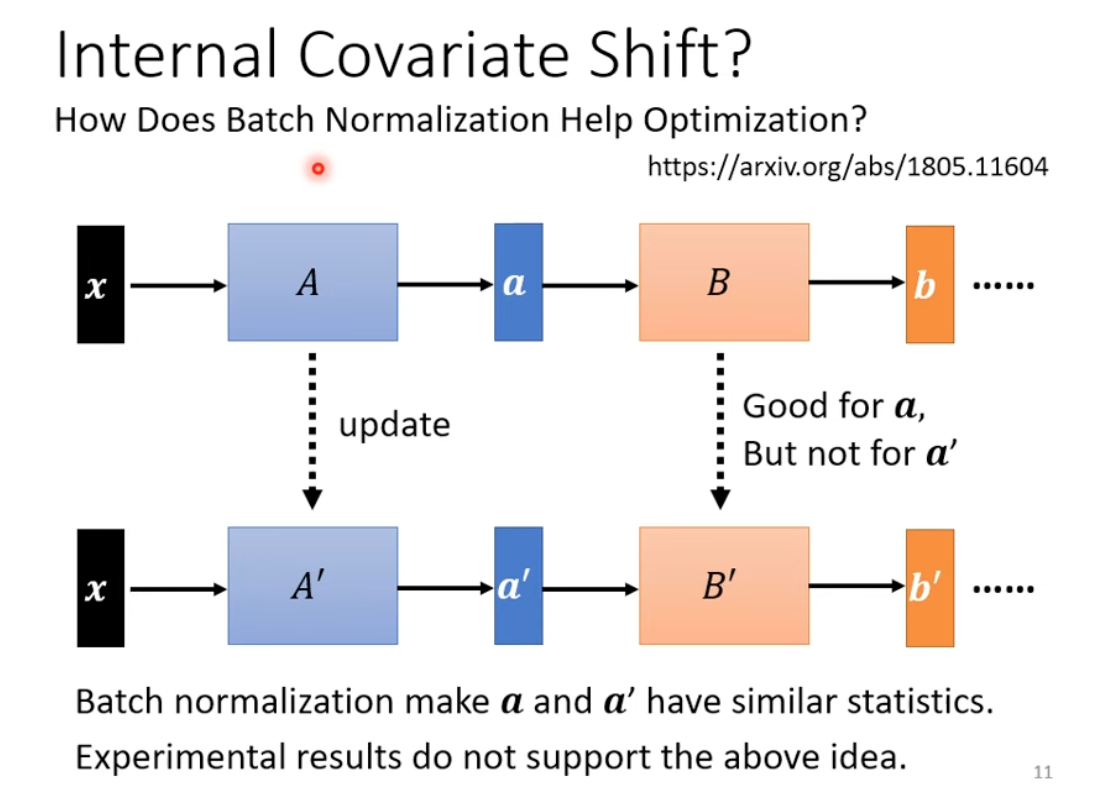
The data and theoretical analysis is due to changng the landscape of error surface, but somewhat serendipitous.
