ML101 - Self Attention
One more good resource for this introduction is here
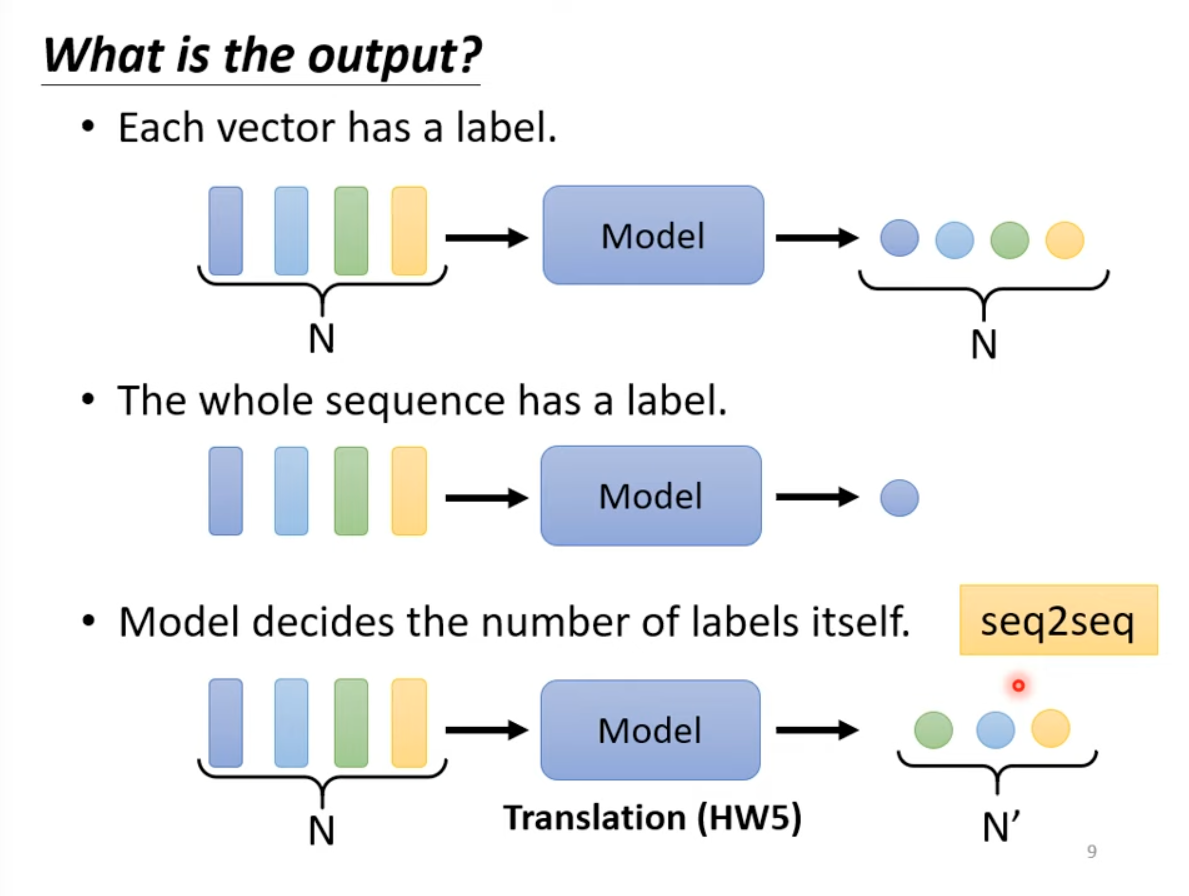
What the output could be for a vector input sent to a model. “Sequence labeling” is #input=#output.
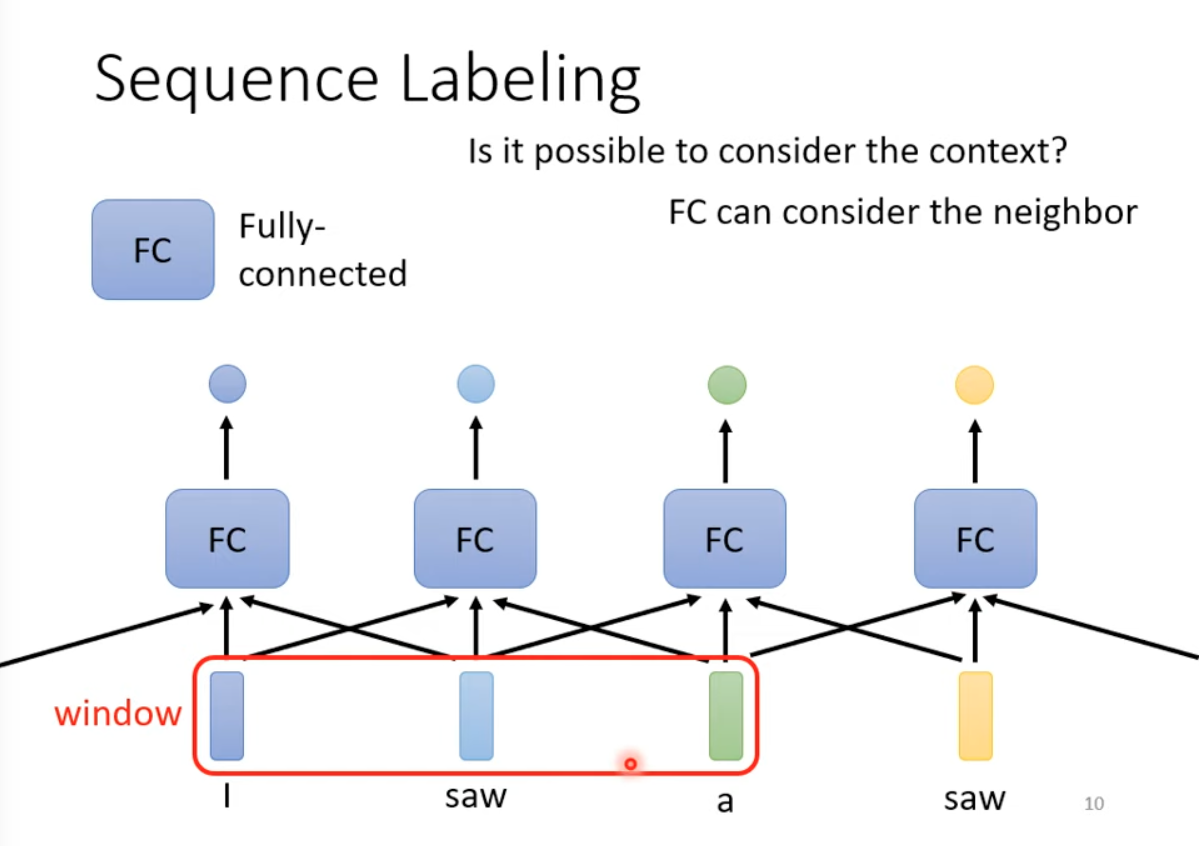
FC can consider a limited length context.
Self-attention is the solution to use full input as context.
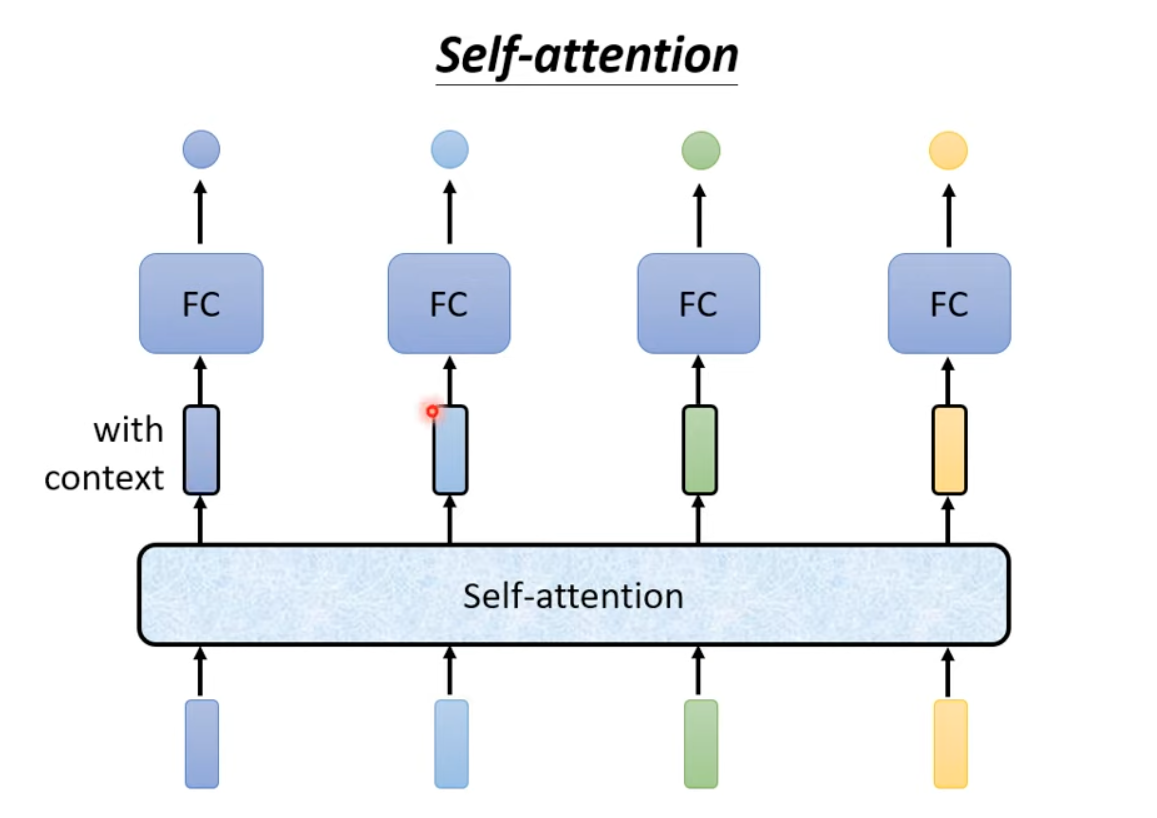
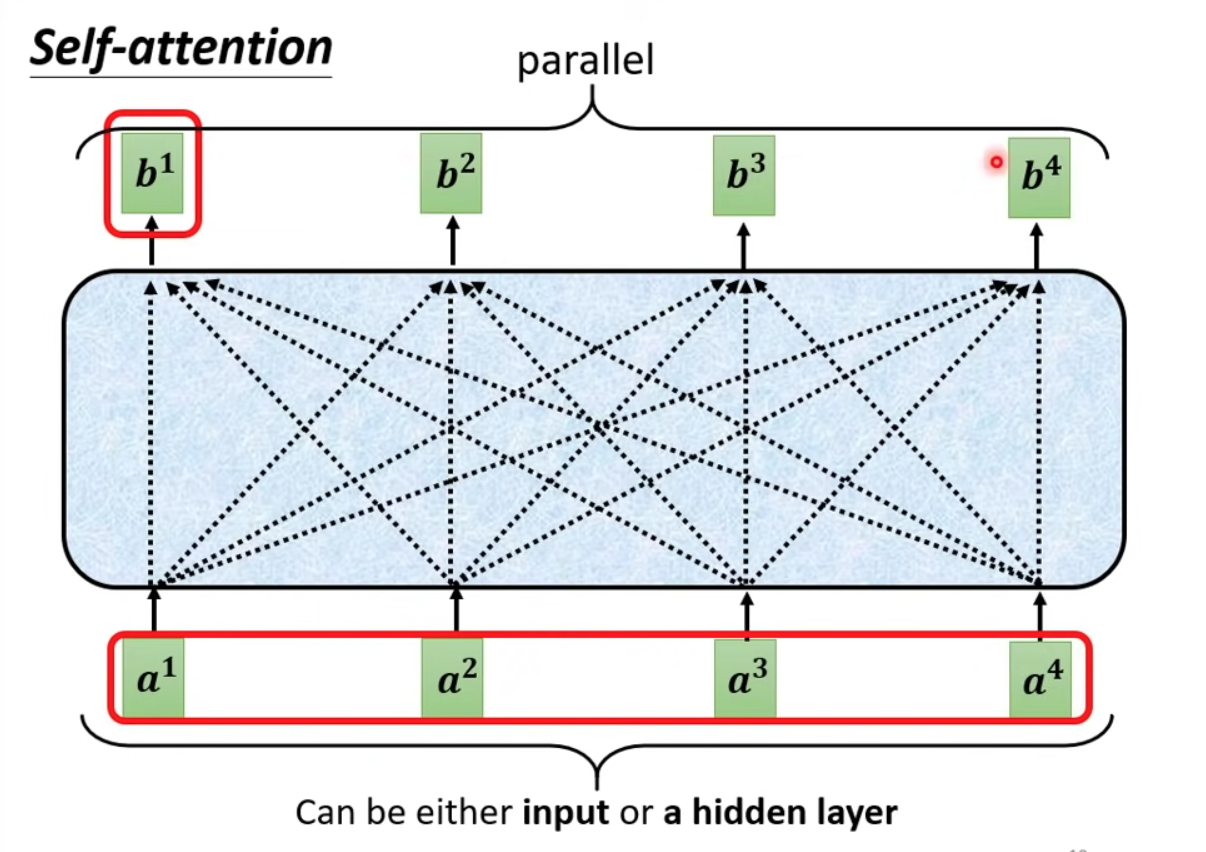
The self-attention can be used directly on input or on middle layers. and can be processed in parallel!!!
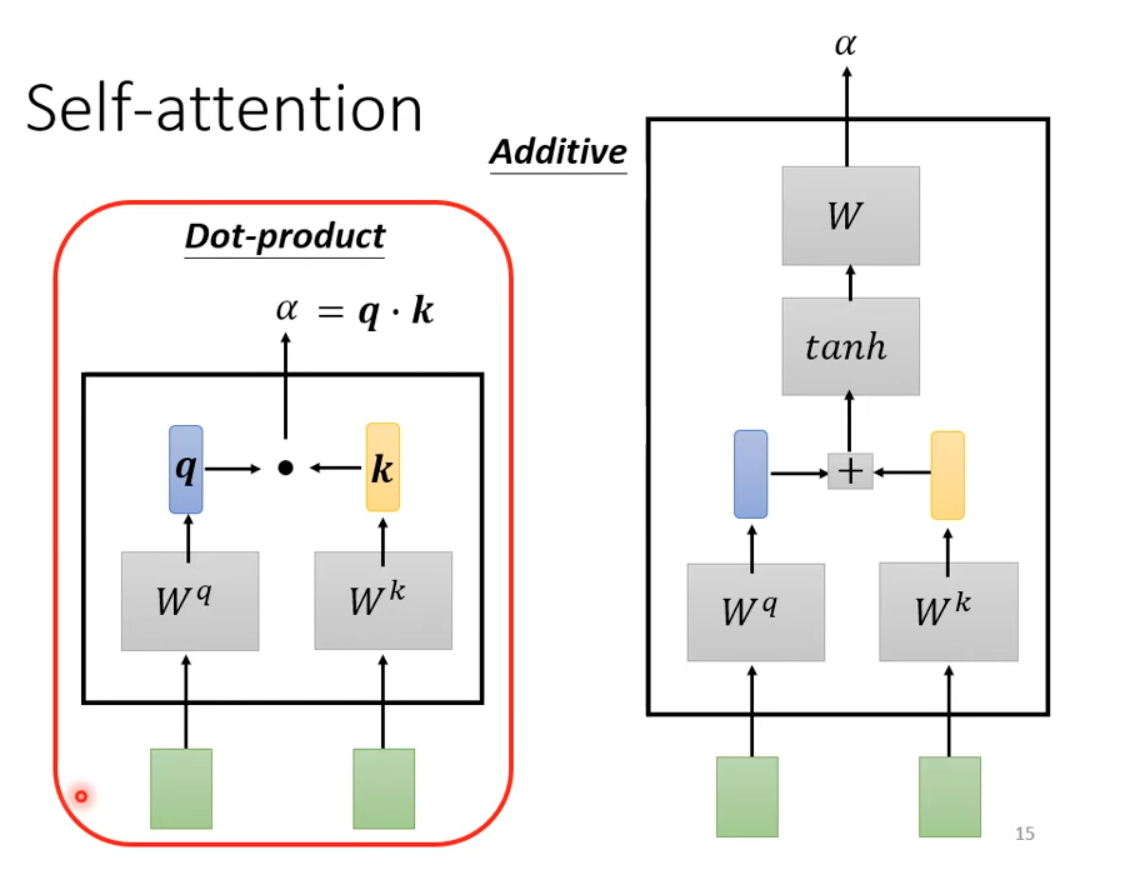
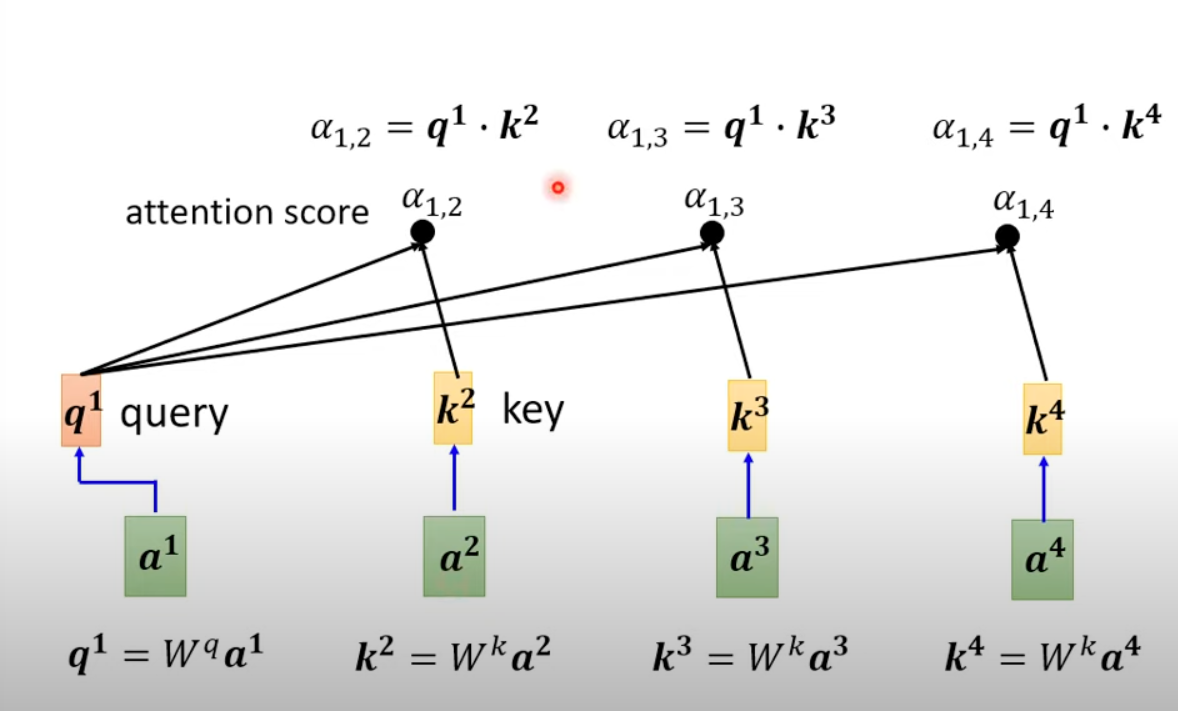
First get Query and Key matrix
Get Attention scores by multiply Q and V
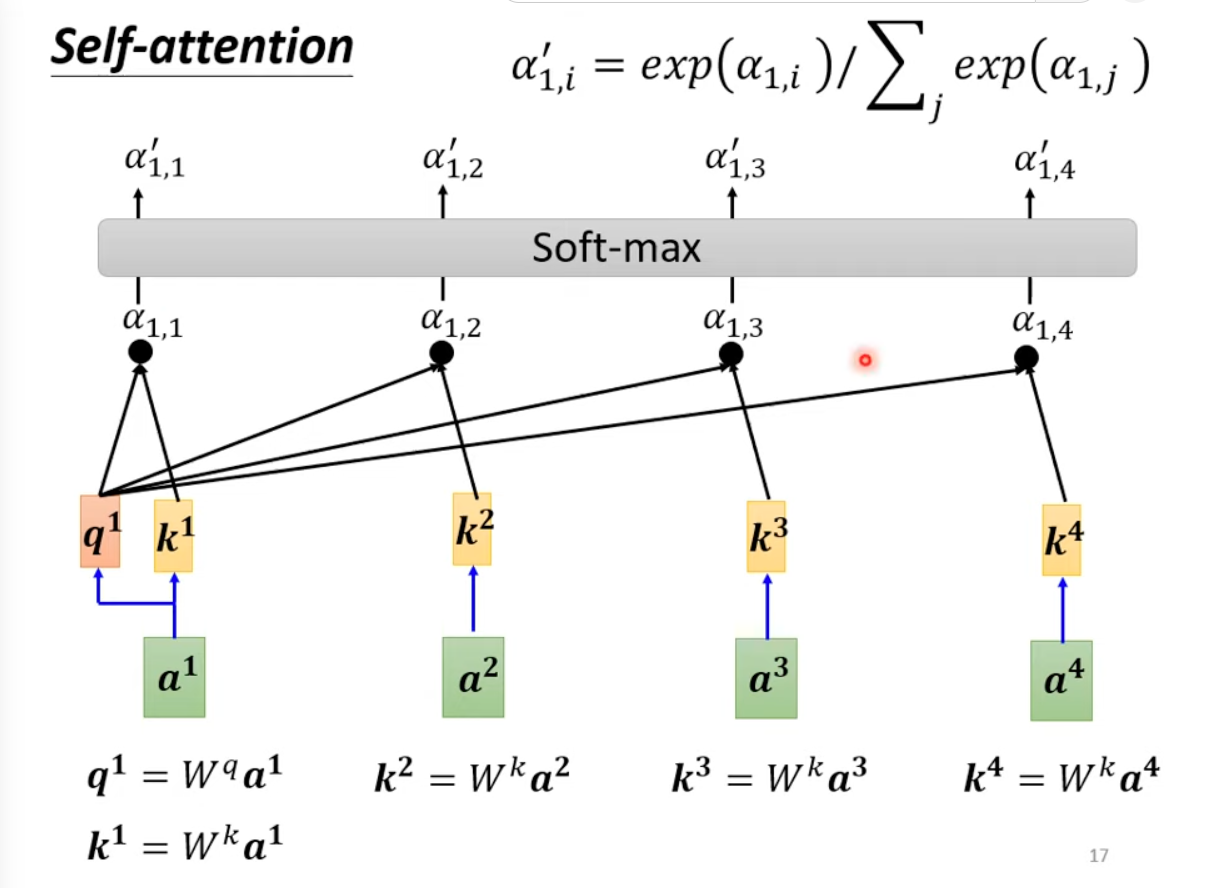
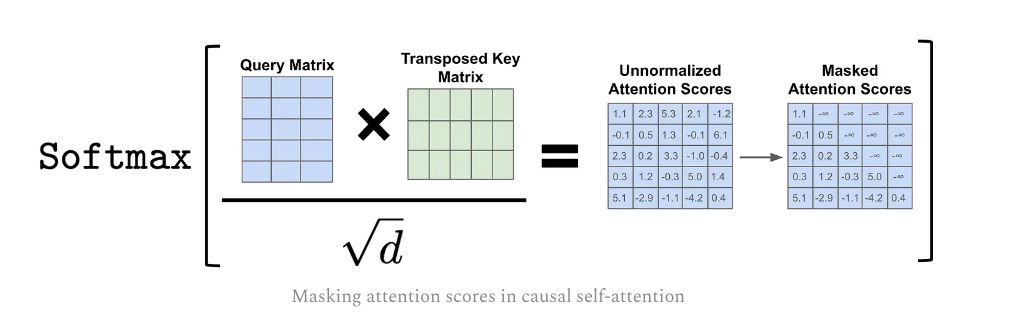
Adding Softwax(Can replaced by ReLU.), and normalization. A masked version could be used here to achieve causality.
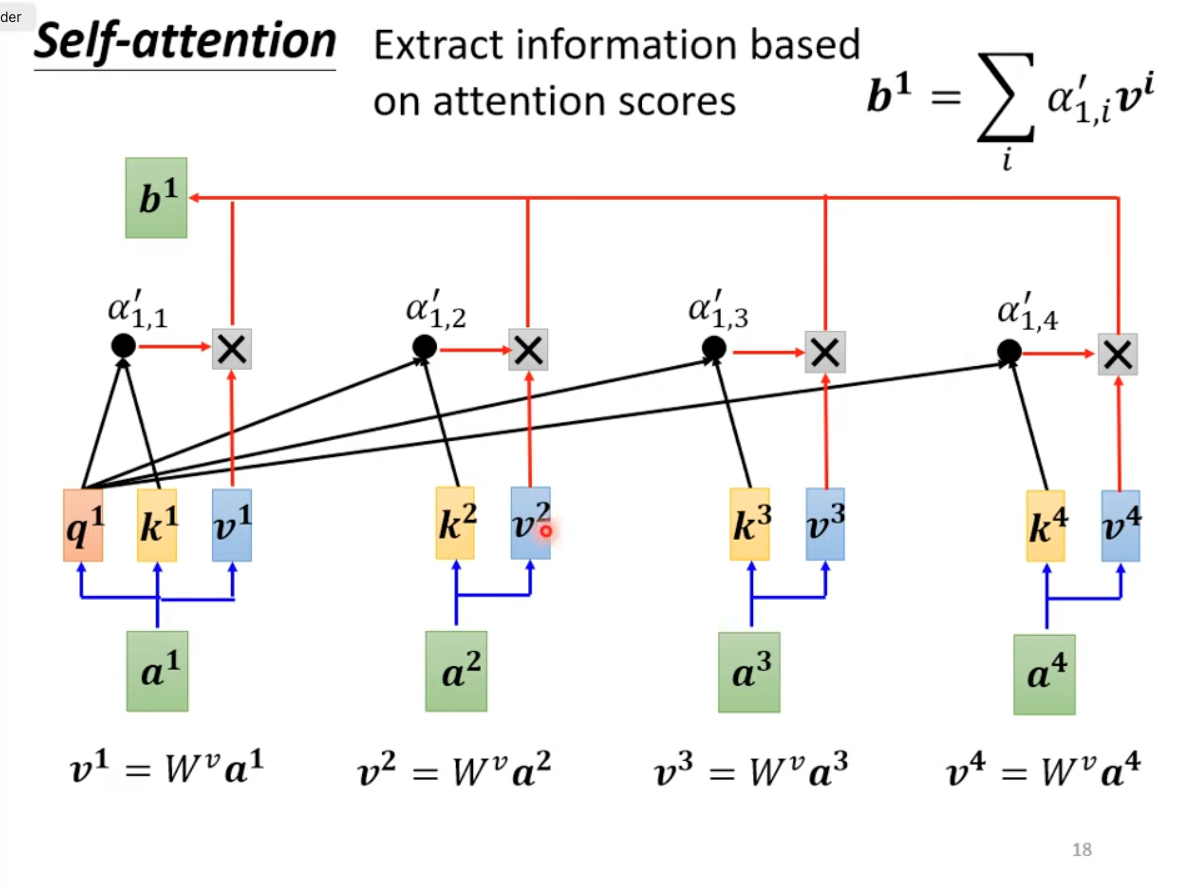
Use attention scores as weights, and the output the weighted sum on V matrix
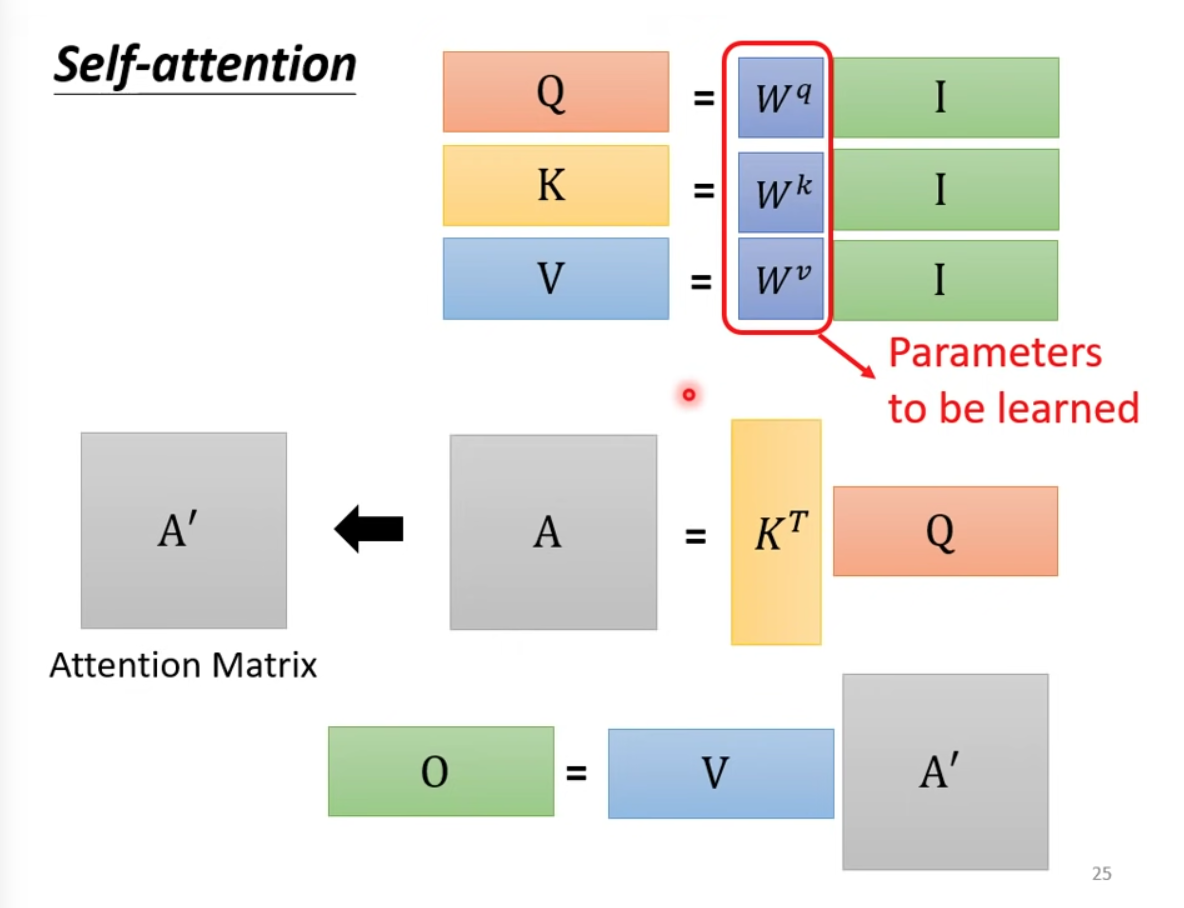
Matrix view of the steps above.Q/K/V matrix are the paramters to be learnt.
Single head limits the ability of self-attention to focus on multiple positions within the sequence—the probability distribution can easily be dominated by one (or a few) words.
Now let’s expand it to multi-head attention. Use the previous results as $b^{i,1}$
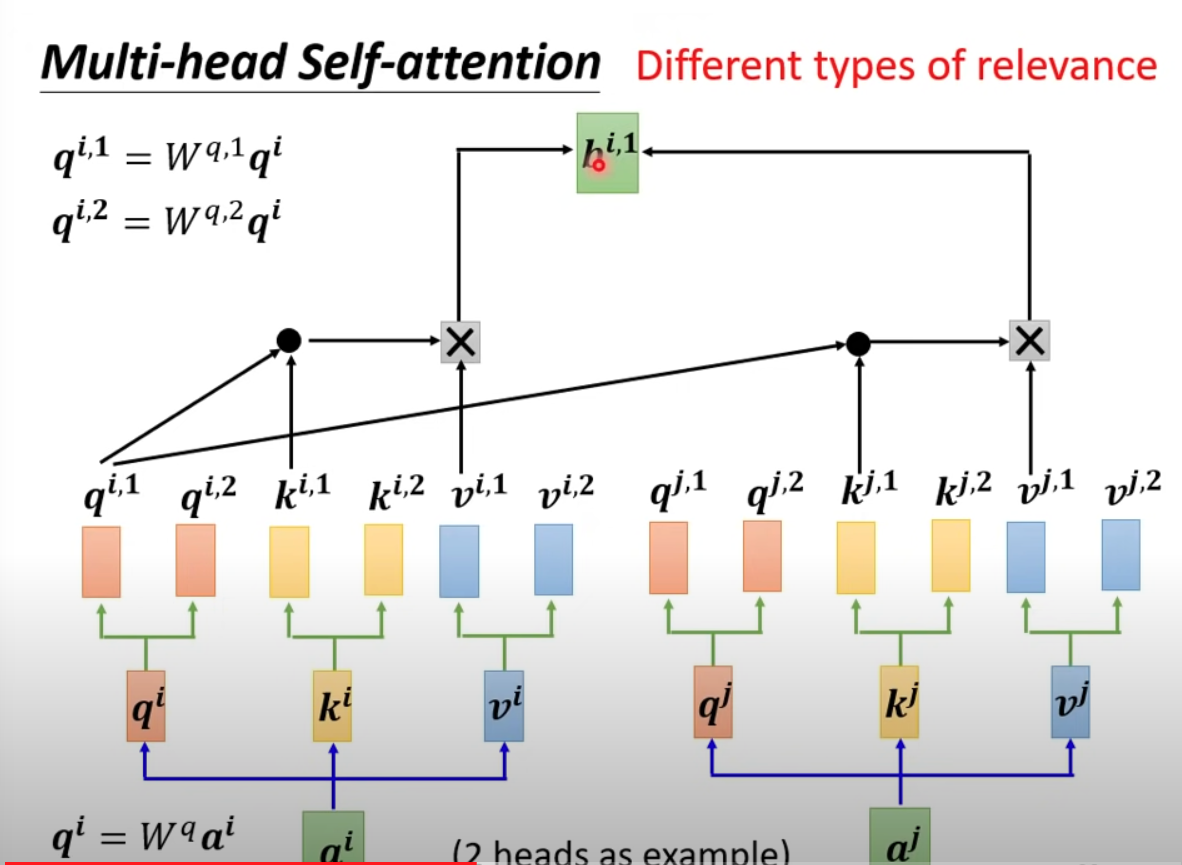
And use another set of matrix to get $b^{i,2}$
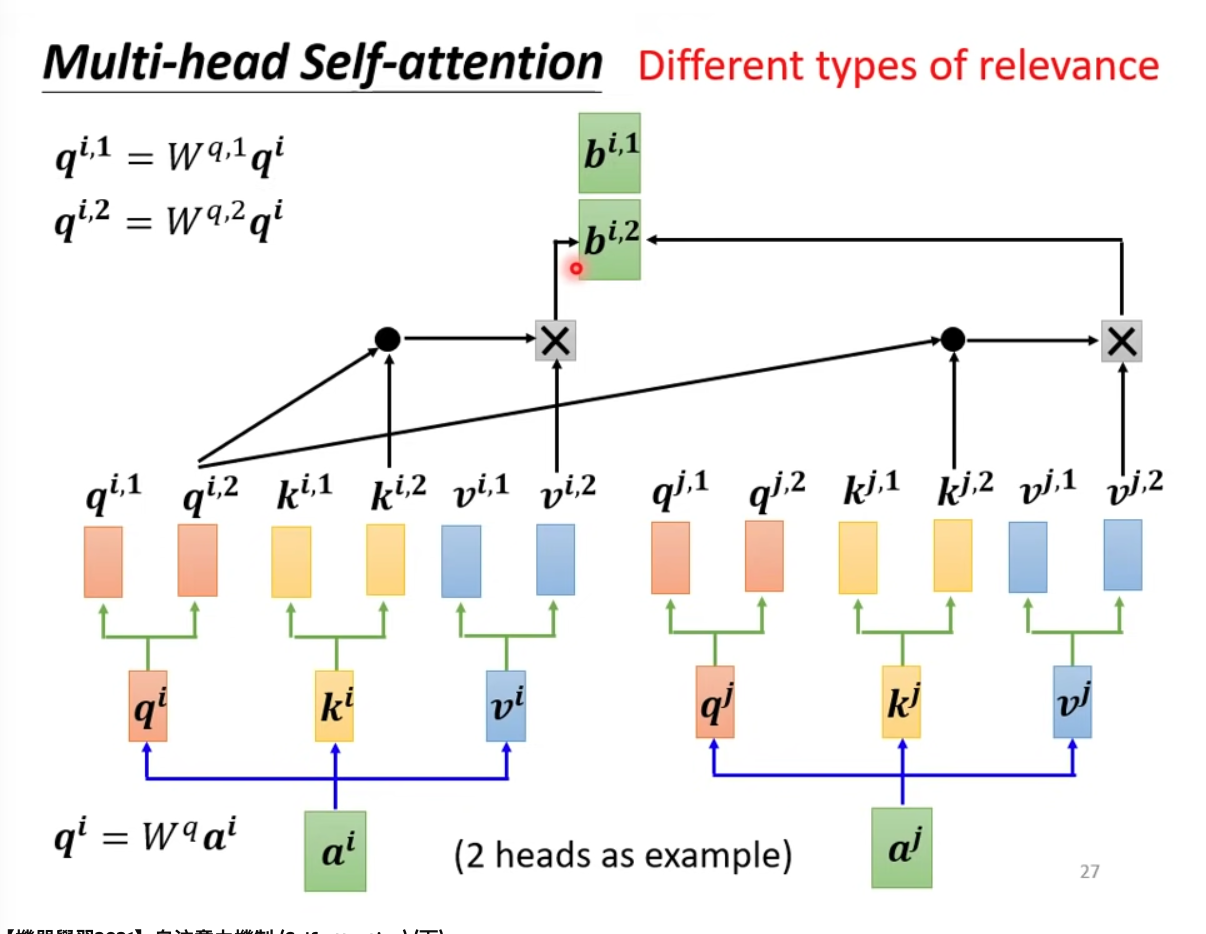
Concatentate multi head results and times a matrix to get the final output $b^i$. Because each attention head outputs token vectors of dimension $d // H$, the concatenated output of all attention heads has dimension $d$
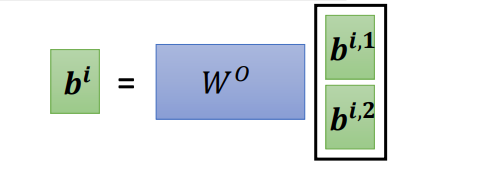
Adding position vector created by positial encoding. $sin$ encoding is hand crafted, and can be learnt as well.
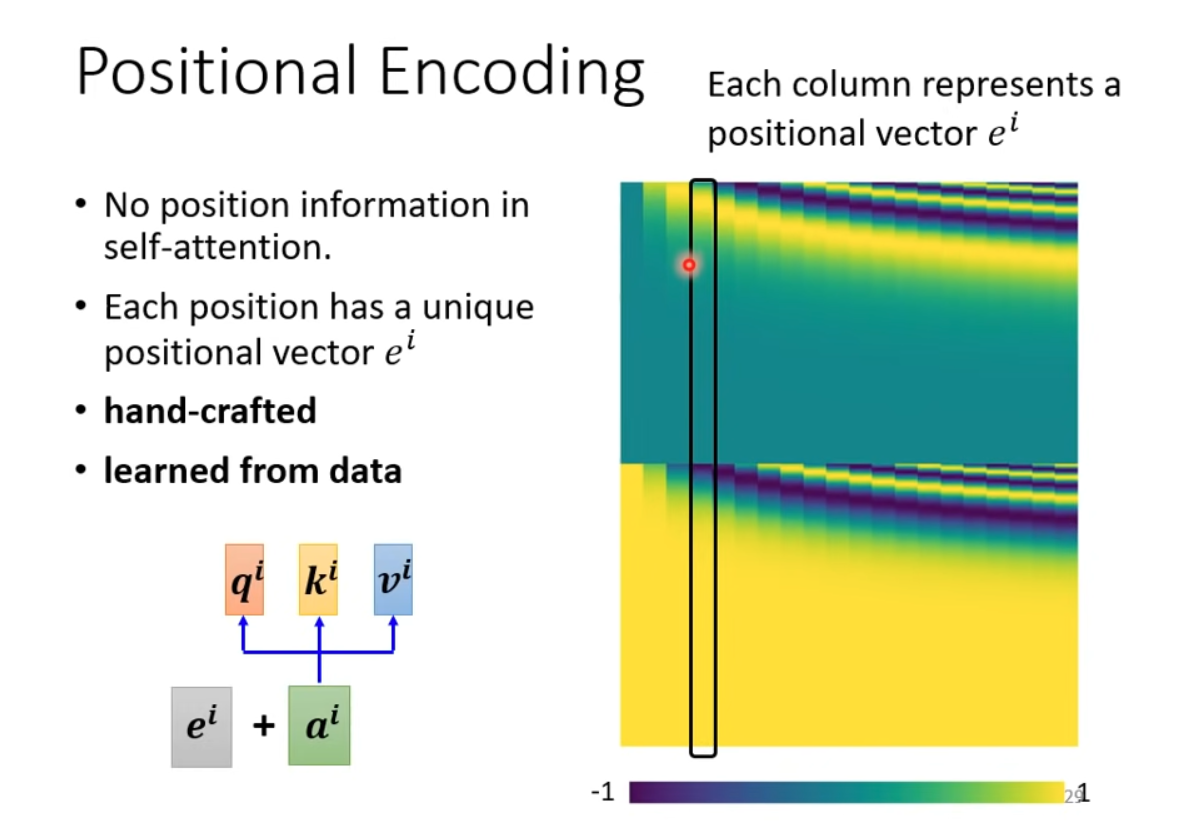
For speech, the vector seq. could be VERY long, 1 second signal is 100 vectors, and the complexity is square to the length.
Image can be seens as a long vector sequence as well.
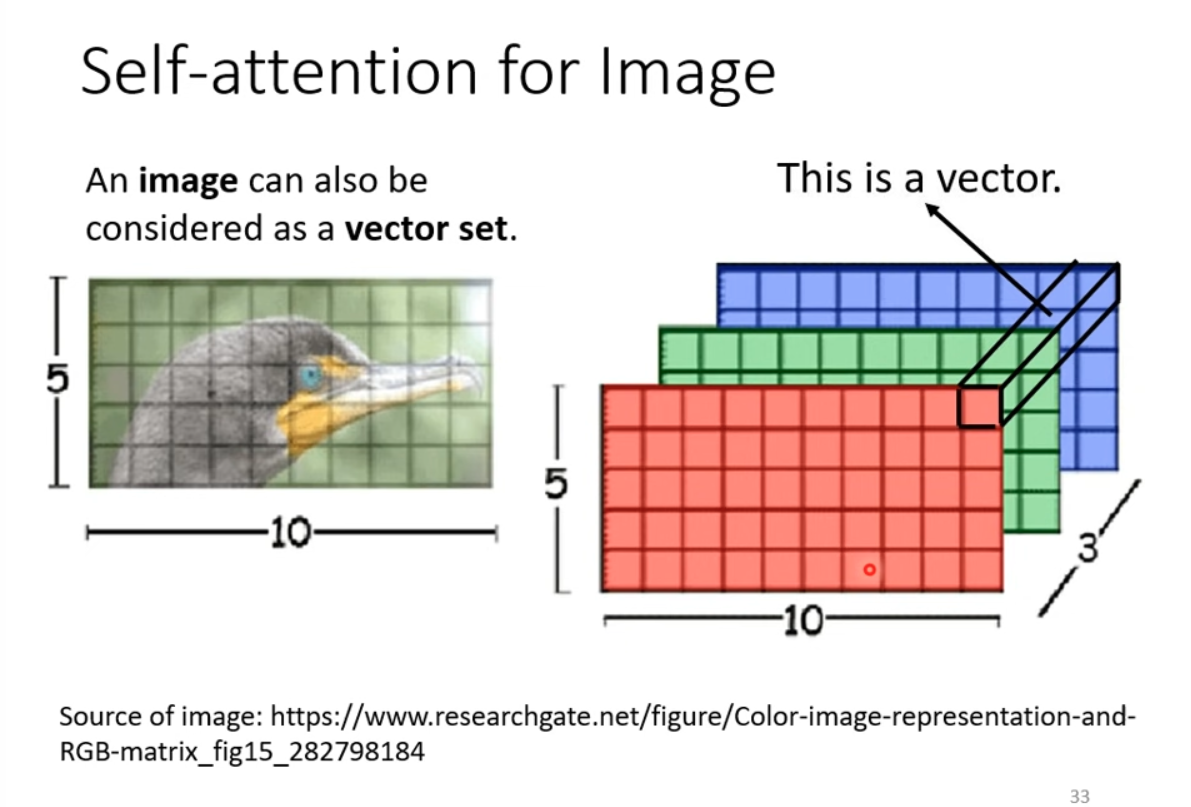
CNN is simplified SA(self-attention) with limited receptive field.
SA is CNN with leanable receptive field.

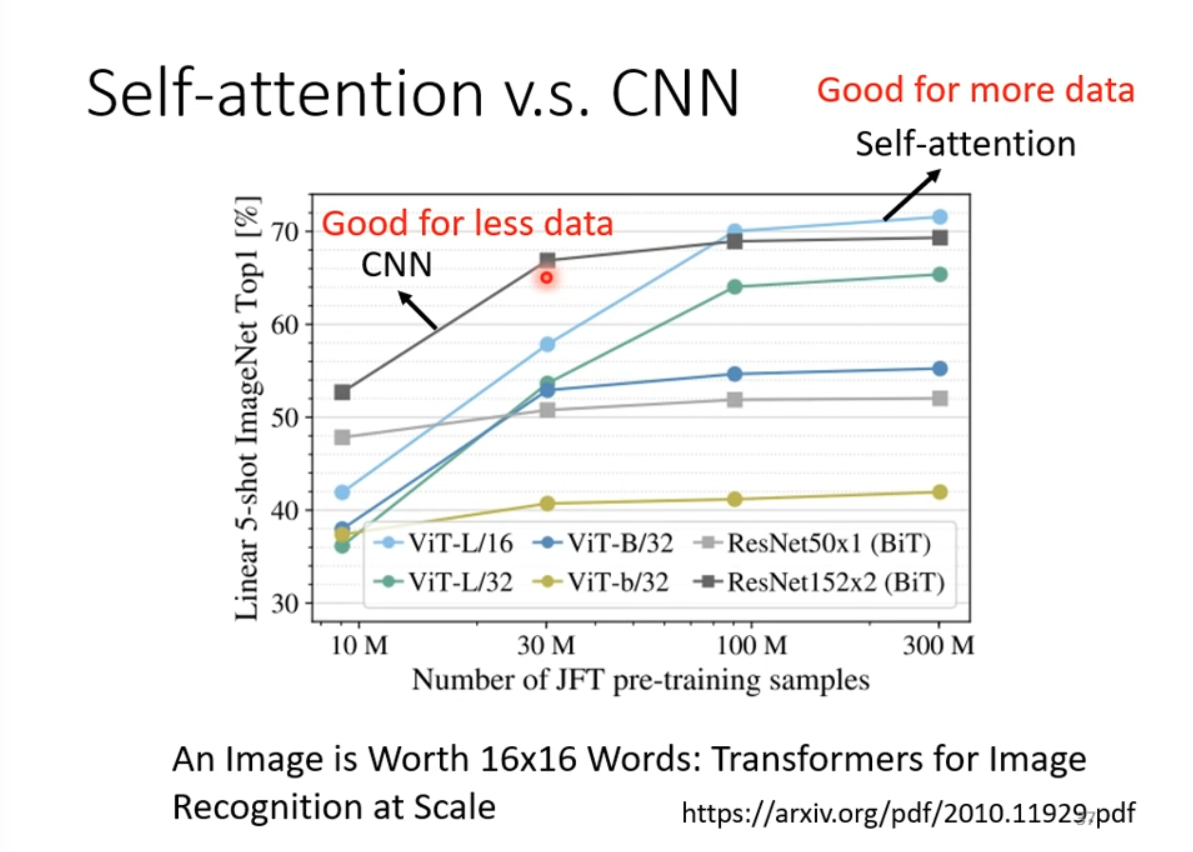
SA needs more data to train than CNN. (Results from ViT paper, An image is worith 16x16 word)
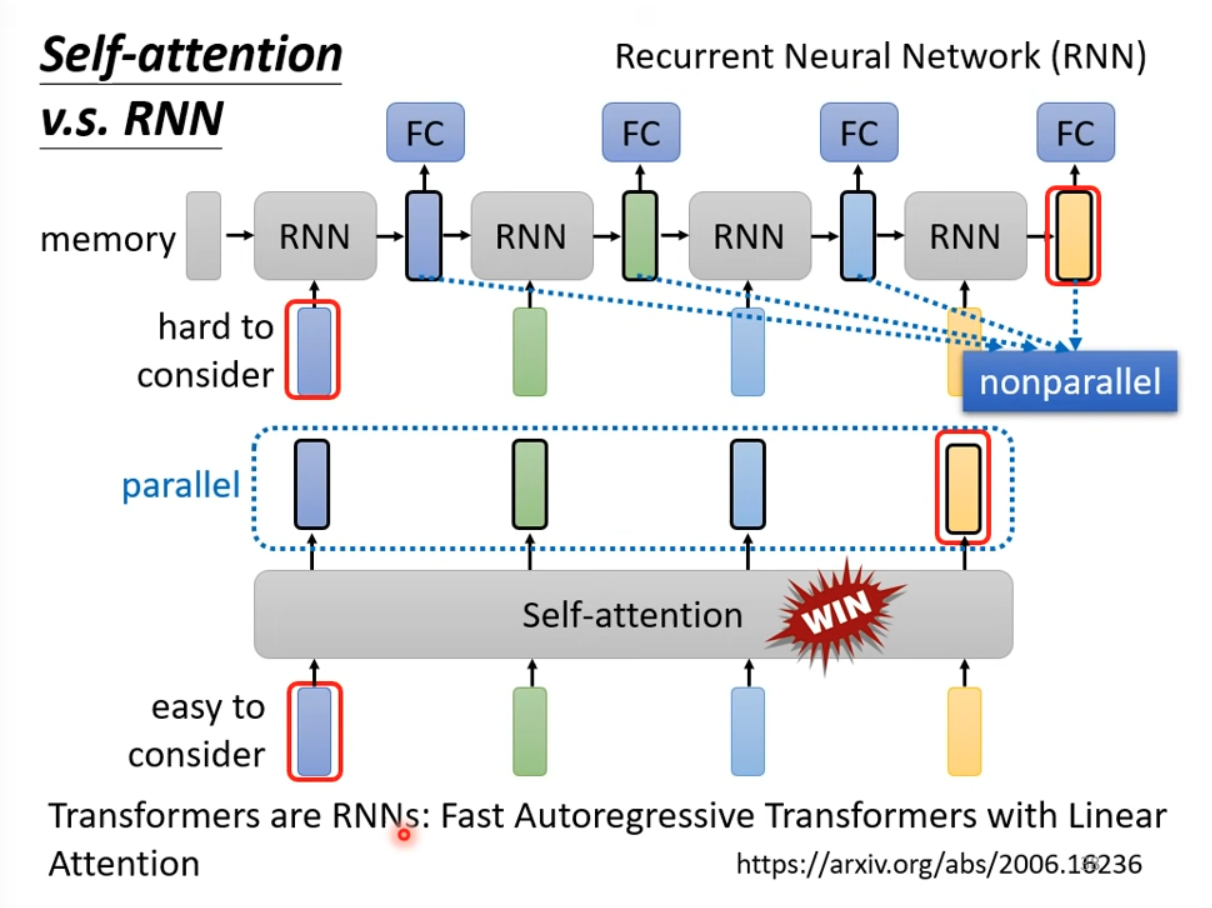
RNN can NOT be parallel processed and easy to forgot early input.
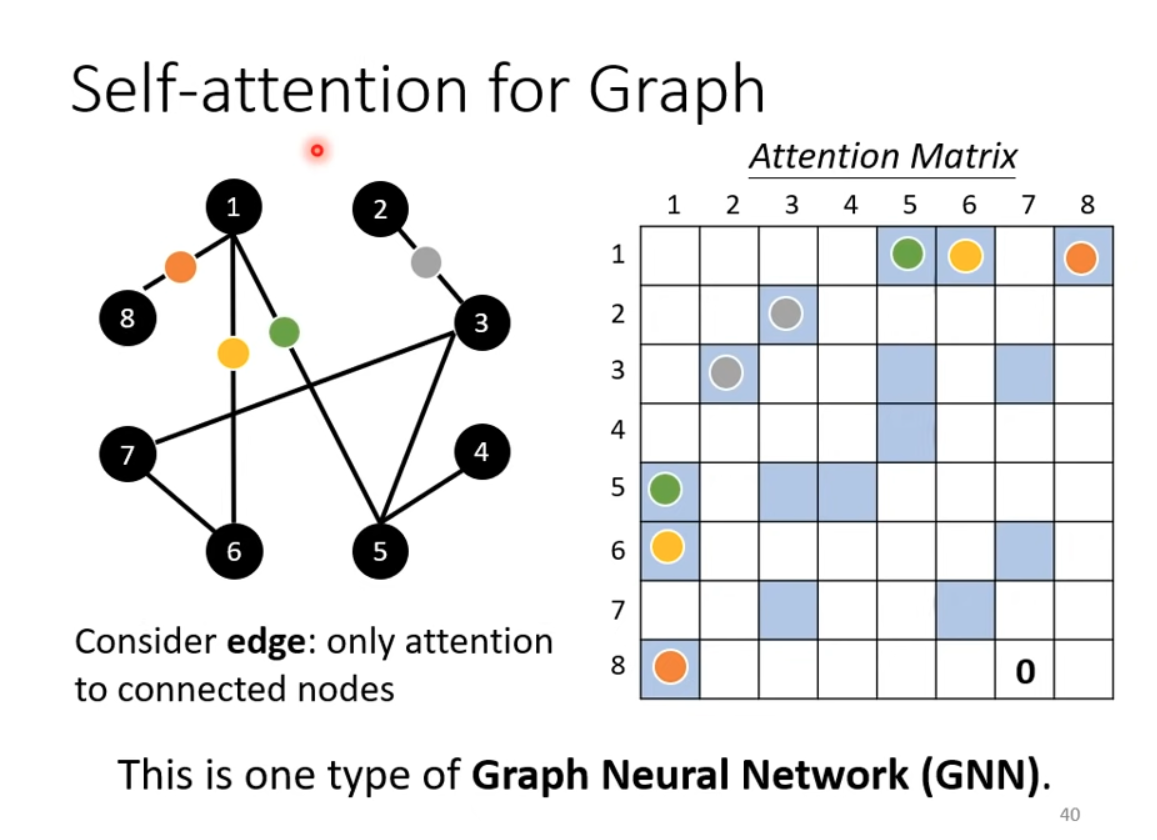
Use SA on graph, only consider the connected edge. and this is one type of GNN