Mamba
I finally reached the last part of this Mamba intro after going through HiPPO and this video from Umal Jamil.
0 Motivations
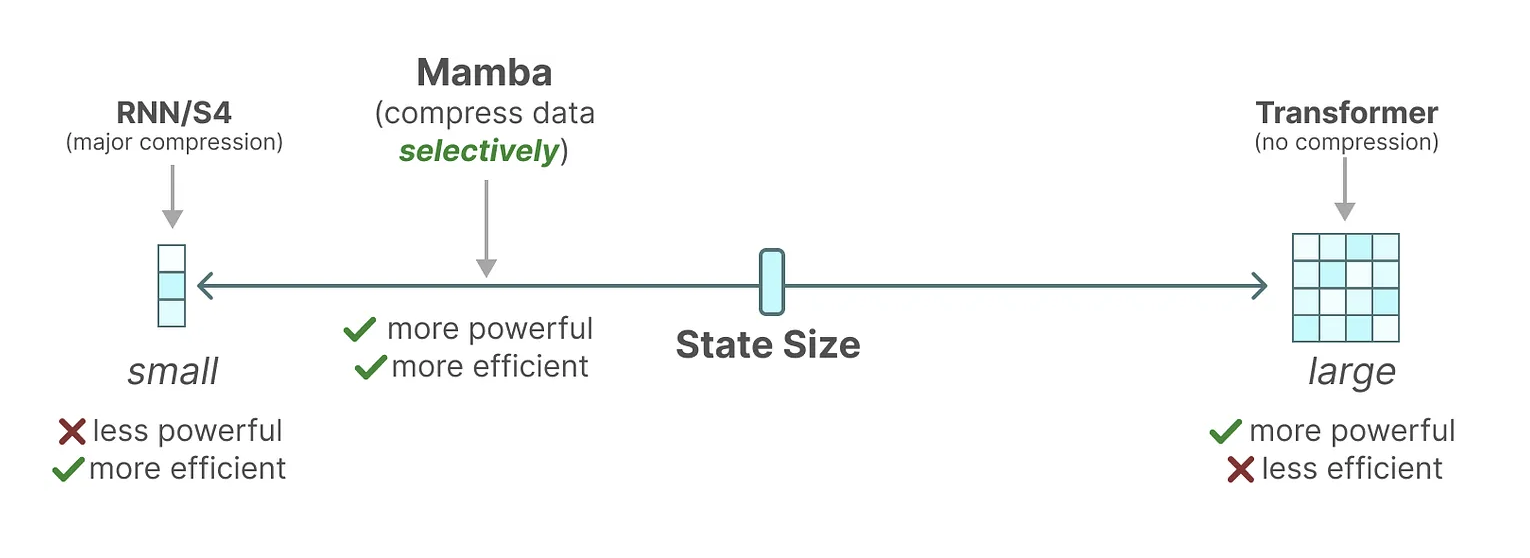
The issues from S4 is that it can’t not handel selective copying
 and induction heads which is essential for one/few-shot learning
and induction heads which is essential for one/few-shot learning
 That’s b/c A/B/C matrix are the same for each token
The author proposed Mamba as a solution to have content-awareness, in the mean time, efficient at state calculation.
That’s b/c A/B/C matrix are the same for each token
The author proposed Mamba as a solution to have content-awareness, in the mean time, efficient at state calculation.
1 Selective SSM
The solution is to make A/B/C are all input dependent
 But this makes the SSM time variant and can NOT use CNN representations to accelerate the computation
Thus it use some hardware accelerate techniques to improve
But this makes the SSM time variant and can NOT use CNN representations to accelerate the computation
Thus it use some hardware accelerate techniques to improve
2 Hardware-aware Algorithms
-
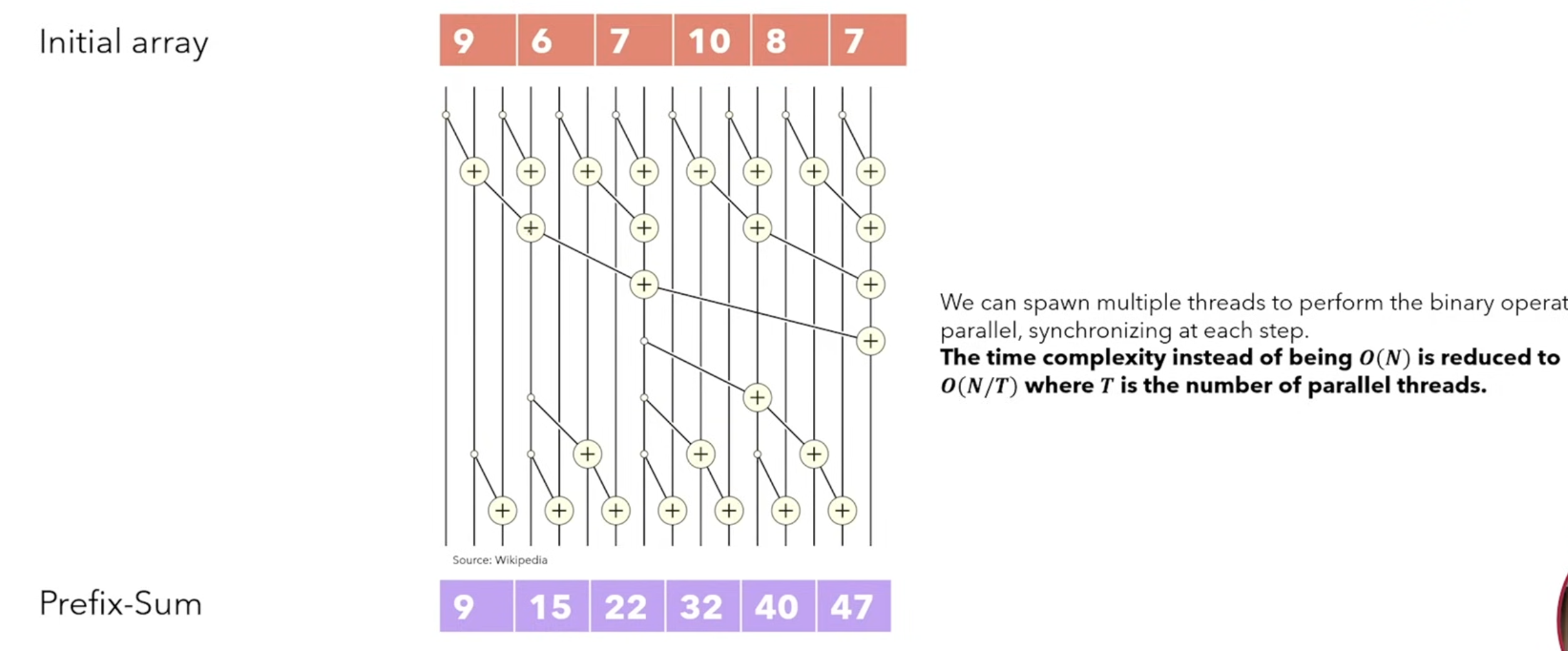
Parallel scan
The SSM is similar to prefix-sum array, which can be easily calculated in linear time
|9|6|7|10|…| |-|-|-|-|-| |9|15|22|32|…|This can be parallelized by sweep down and sweep up operations
- Kernel fusion
Due to speed difference of HBM(DRAM) and SRAM, try to combine(fusion) multiple step in kernal
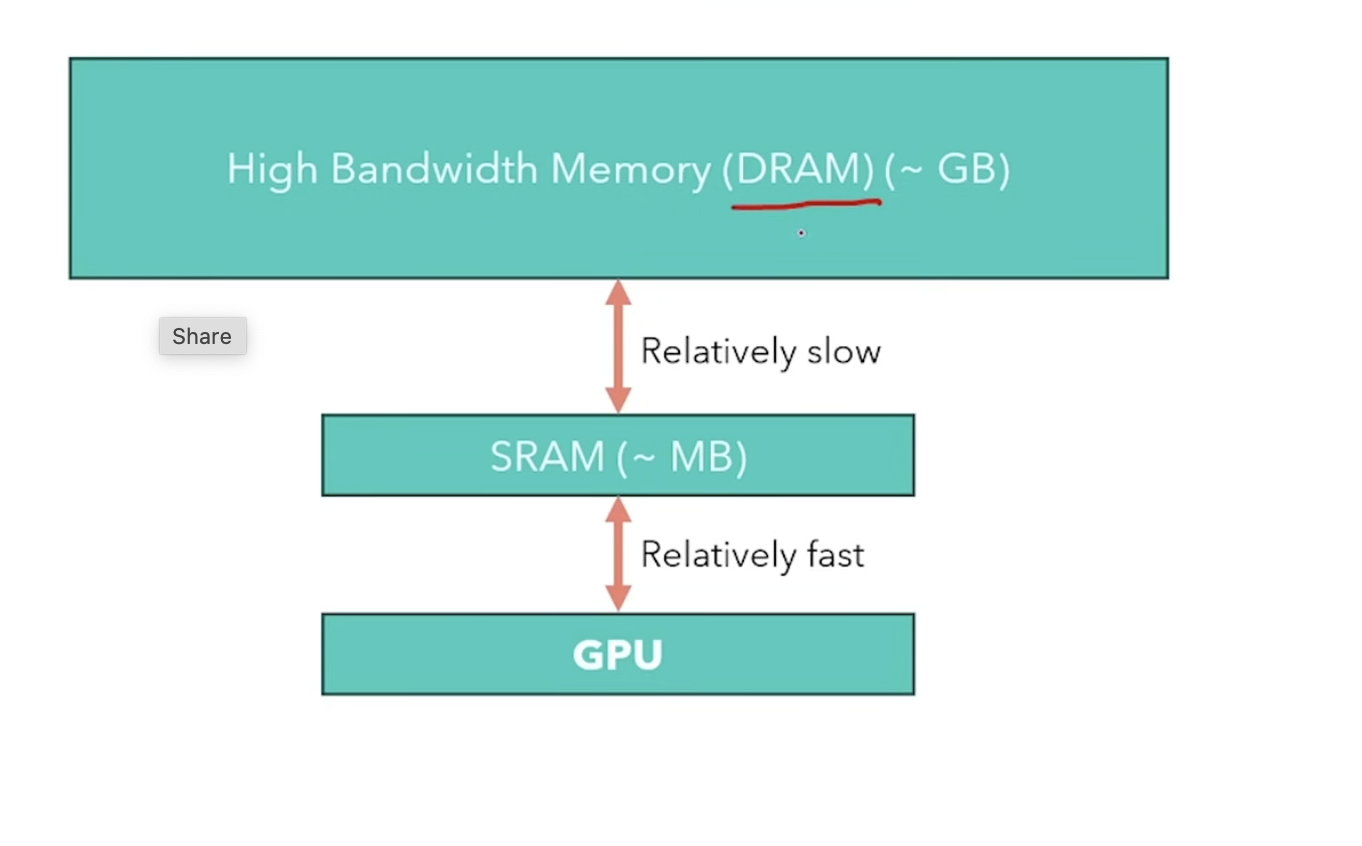 It’s 1000x different in size ,and 6x in speed
It’s 1000x different in size ,and 6x in speed
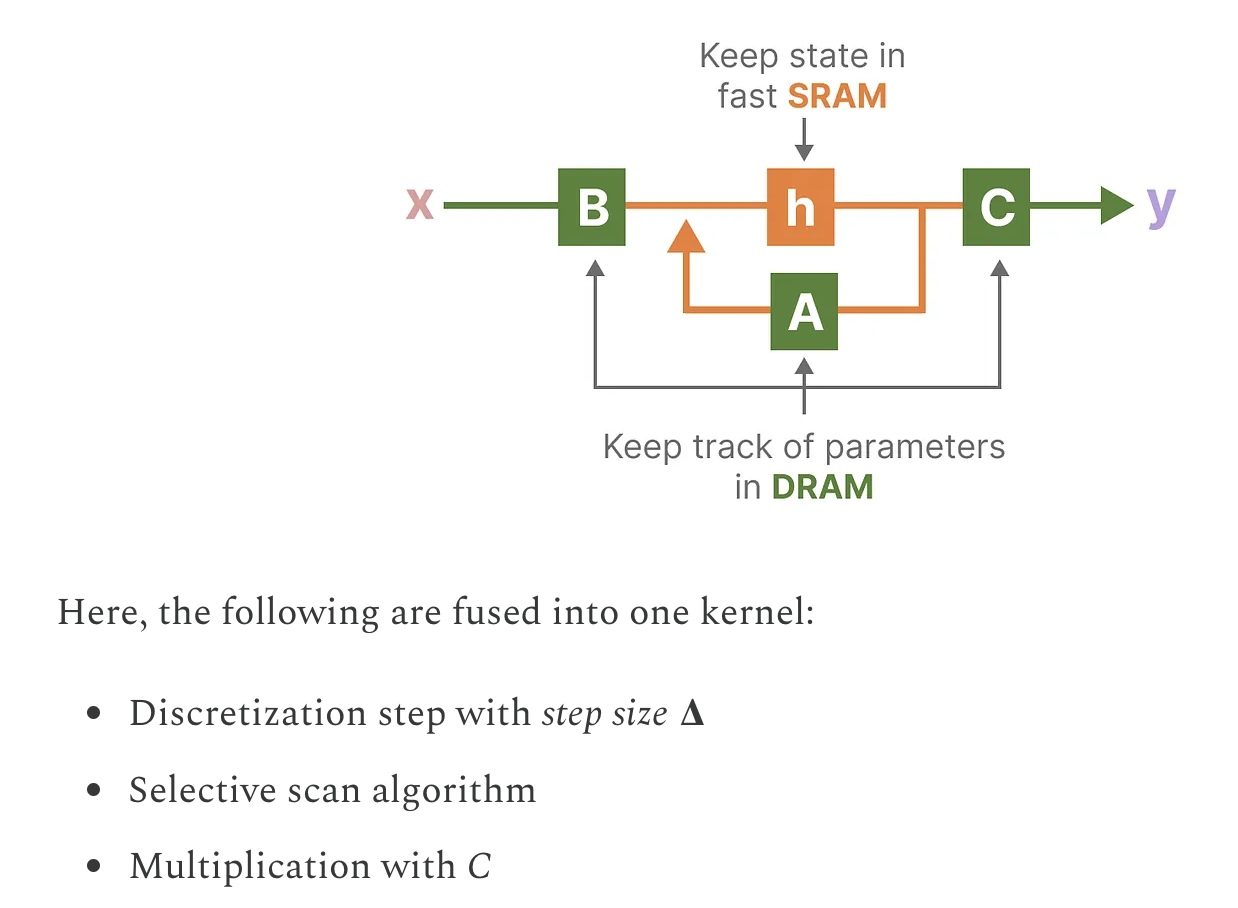 . This is similiar to FlashAttention operations
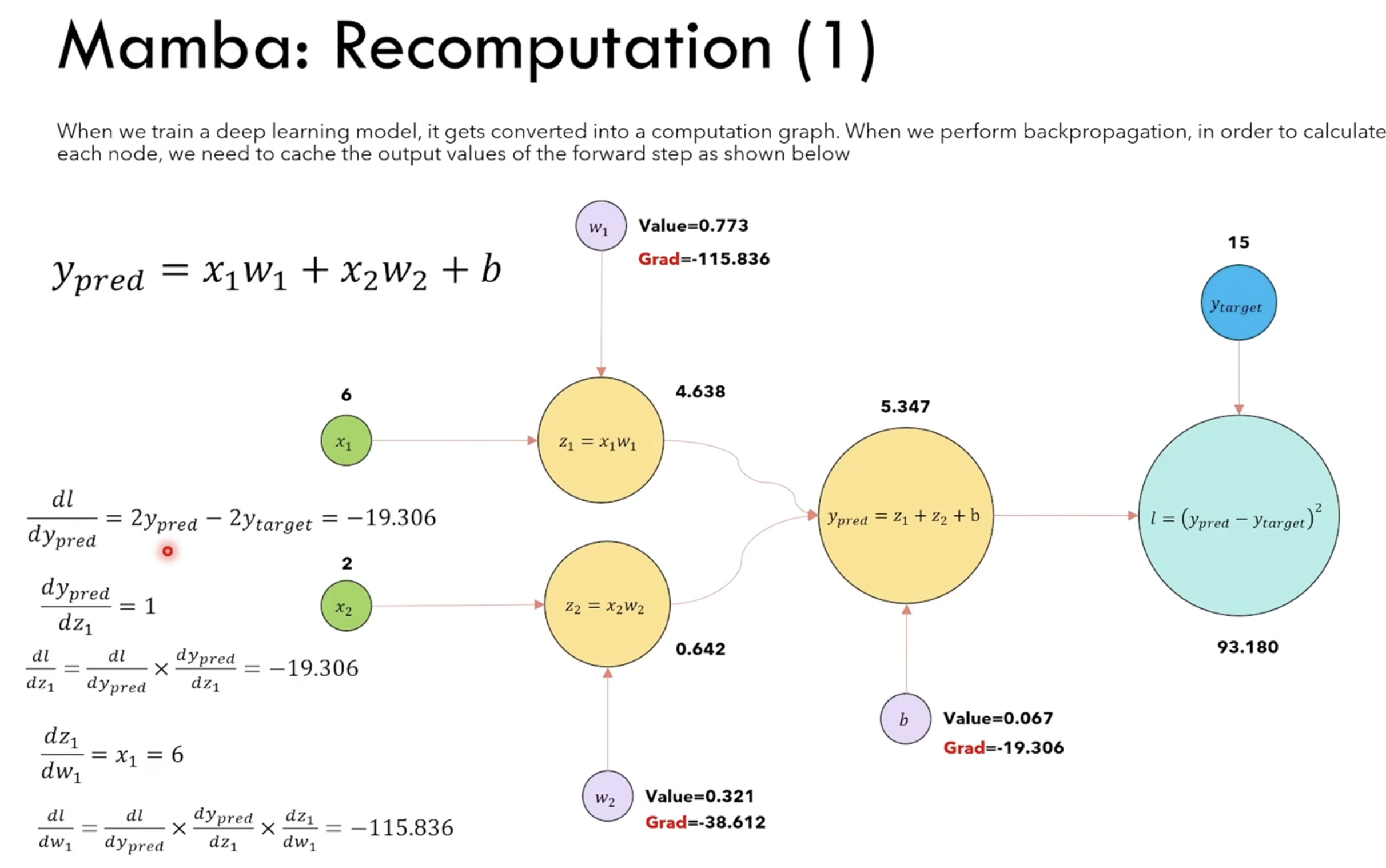
. This is similiar to FlashAttention operations - Recomputation
Calculatoin is actually faster than memory IO. so instead of memorize the compute graph, rather re-compute at each step.
For A100, F32 can be done ~20 TFlops, and HBM copying is 2000 GB/s.
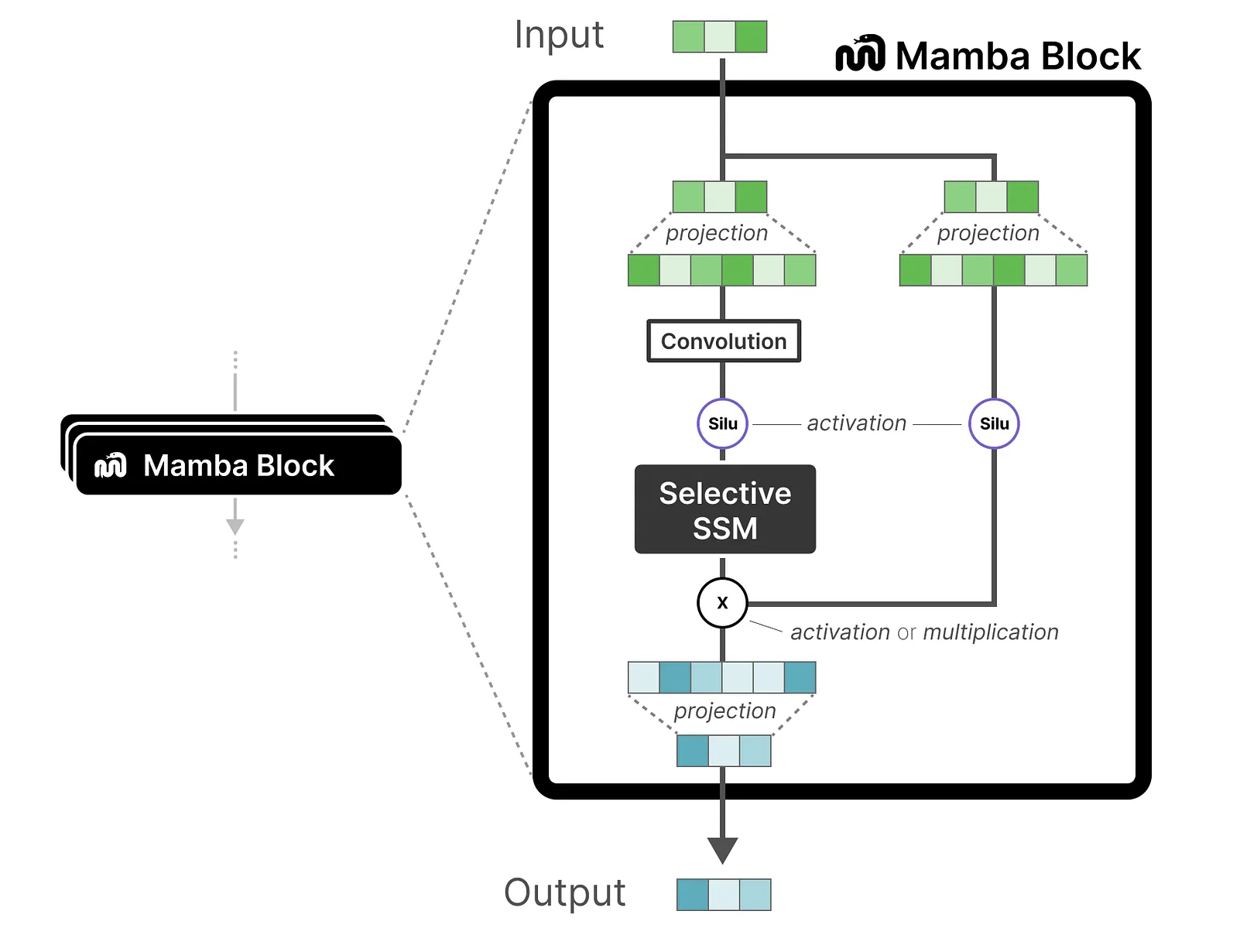
3 Mamba Block
Now based on H3 and adding gated MLP, we have mamba block defined as below
 .
.