Medusa and EAGLE
Both are speculative decoding technologies used to accelerate decoding. There are lookahead, and ReDrafter as well.
0 Review of Speculative Decoding
Blockwise Parallel Decoding was introduced by Noam Shazeer(paper link) , initially designed for greedy decoding, use auxiliary models to predict extra models.
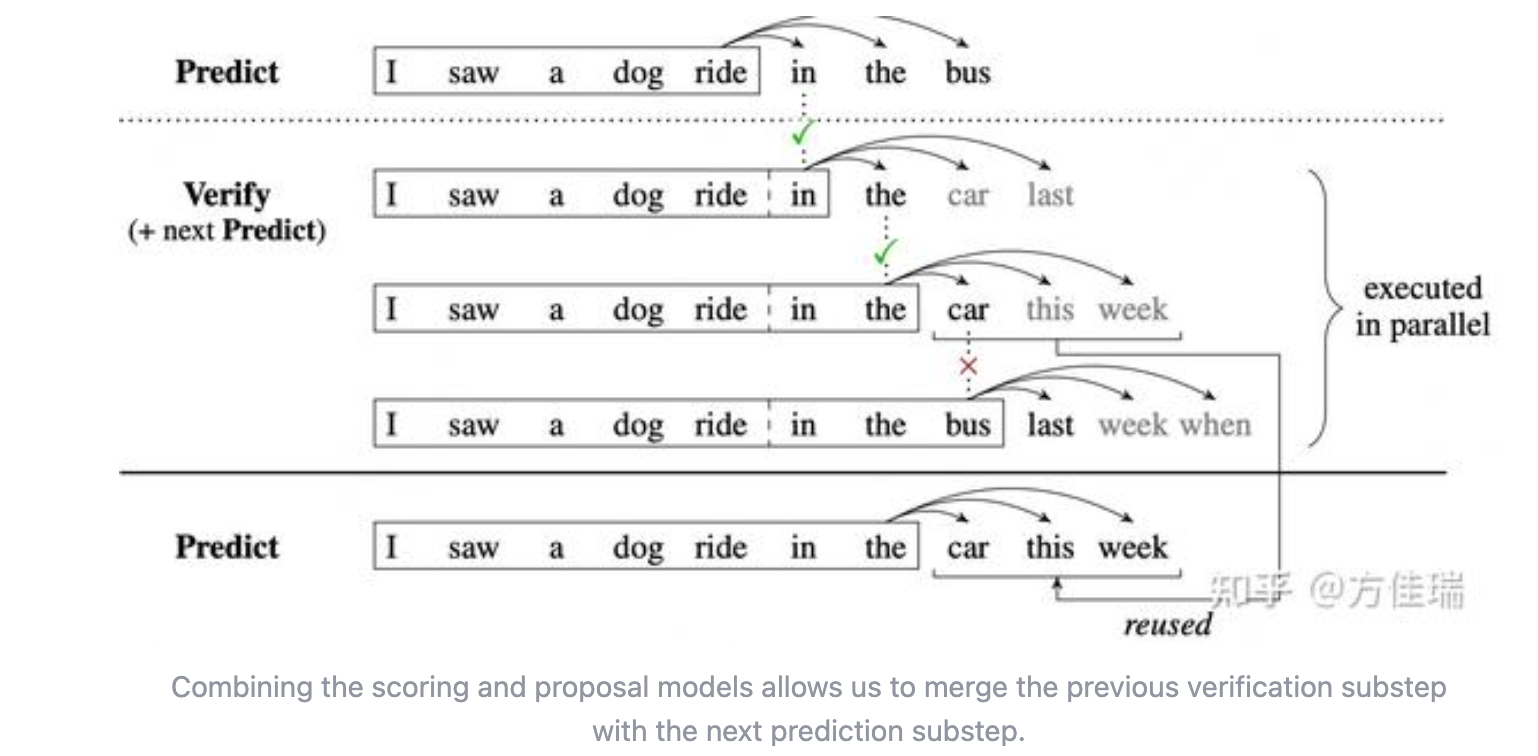 In implementation, you don’t really need auxiliary models but by modifying the TF iwht multi-output feedforward layers.
In implementation, you don’t really need auxiliary models but by modifying the TF iwht multi-output feedforward layers.
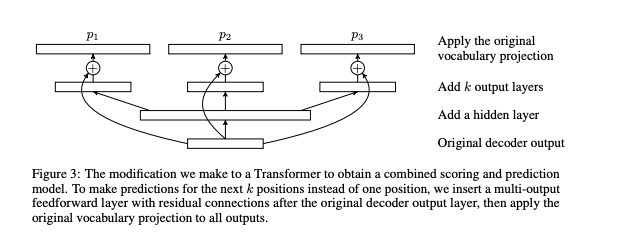 This idea leads to Medusa.
This idea leads to Medusa.
1 MEDUSA
Medusa uses ONLY one model as both draft and target models, but with multiple Medusa heads.
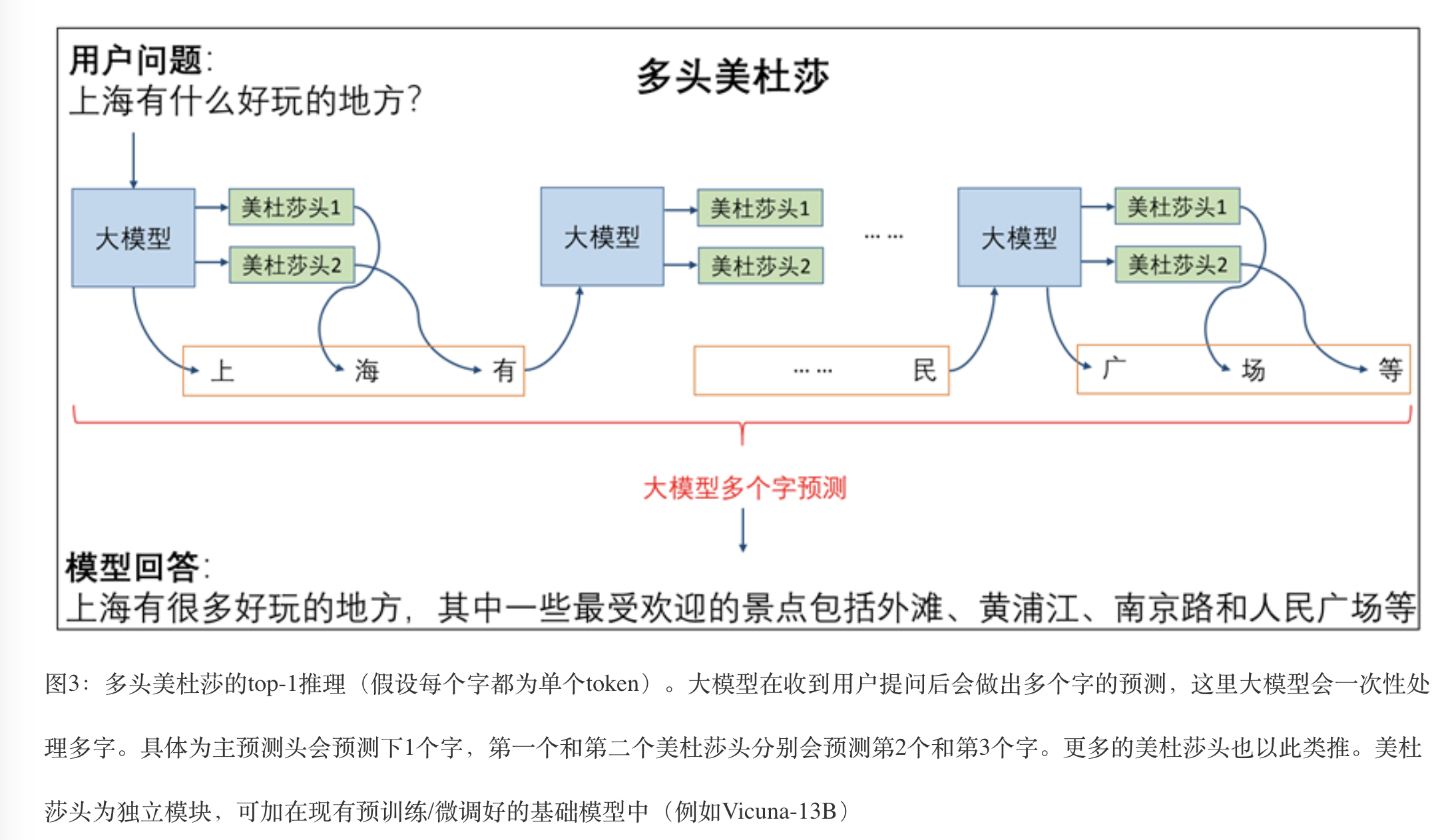 With top-k for each Medusa head, you will have $nk_1k_2…*k_n$ tokens to choose from.
With top-k for each Medusa head, you will have $nk_1k_2…*k_n$ tokens to choose from.

1.1 Structure
There is a typo in the original paper that $W_2$ should be initialized as the original model head, NOT $W_1$

# Medusa Block
class ResBlock(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.linear = nn.Linear(hidden_size, hidden_size) # W1, dxd, init to zeros
torch.nn.init.zeros_(self.linear.weight)
self.act = nn.SiLU()
def forward(self, x):
return x + self.act(self.linear(x))
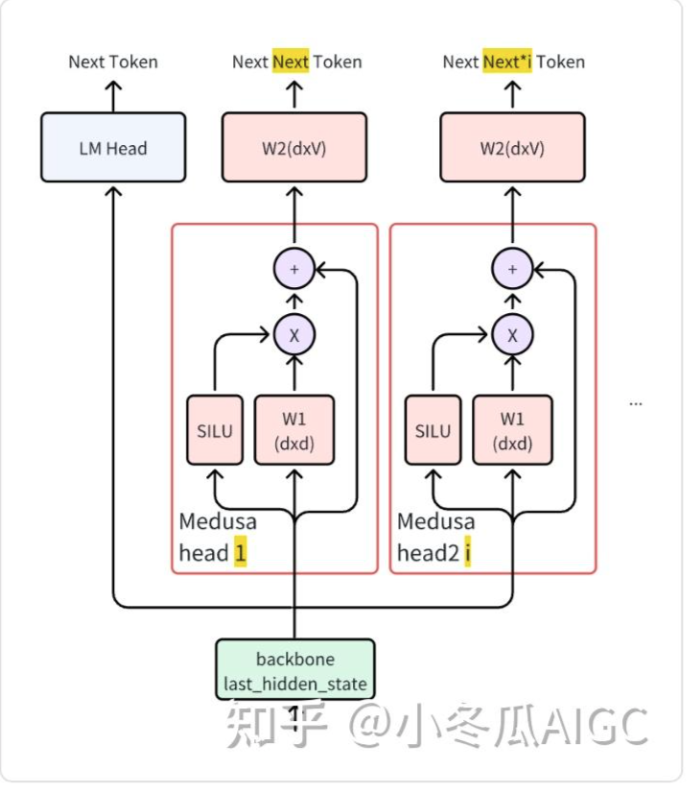
# Medusa Model
class MedusaModel(nn.Module):
def __init__(
self, base_model, medusa_num_heads=4, medusa_num_layers=1,
base_model_name_or_path=None,
):
# LLM Model
self.base_model = base_model
# Medusa Blocks and Medusa Heads
self.medusa_head = nn.ModuleList(
[
nn.Sequential(
*([ResBlock(self.hidden_size)] * medusa_num_layers),
nn.Linear(self.hidden_size, self.vocab_size, bias=False), # W2 dxv
)
for _ in range(medusa_num_heads)
]
)
# ...
model = MedusaModel(
llama_model,
medusa_num_heads=4,
medusa_num_layers=1,
base_model_name_or_path='./min_llama',
)
1.2 Training
For Medusa 1, the training would fix the original model but find loss from all Medusa heads (The original output is ignored, that’s why starts from $t+1+1$). Medusa 2 would train for LLM backend as well.
# medusa/train/train.py
def compute_loss(self, model, inputs, return_outputs=False):
logits = model(input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"])
labels = inputs["labels"]
loss = 0
# Shift so that tokens < n predict n
for i in range(medusa):
medusa_logits = logits[i, :, : -(2 + i)].contiguous()
medusa_labels = labels[..., 2 + i :].contiguous()
medusa_logits = medusa_logits.view(-1,logits.shape[-1])
medusa_labels = medusa_labels.view(-1)
medusa_labels = medusa_labels.to(medusa_logits.device)
loss_i = CrossEntropyLoss(medusa_logits, medusa_labels)
loss += loss_i
1.3 Inference
During infenernce, first around you will get output from origin head and Medusa heads(4).
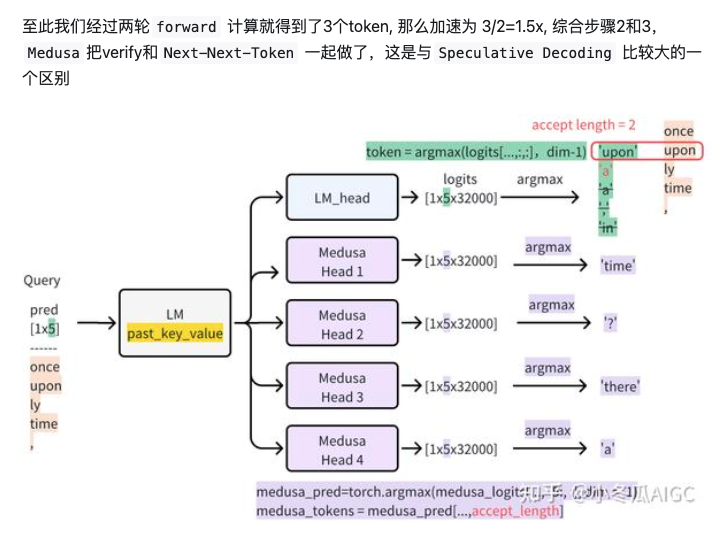
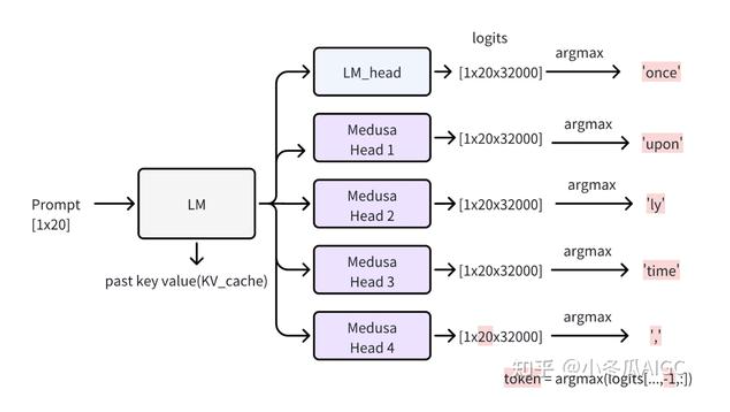 The verify phase will use the predicted results go over the heads and get 5 next tokens.
After comparison, you will get original token, accepted tokens, and token at the accept_length,like a bonus
The verify phase will use the predicted results go over the heads and get 5 next tokens.
After comparison, you will get original token, accepted tokens, and token at the accept_length,like a bonus
1.4 Tree Attention
The modified tree structure can reduce the tokens to $k_1+k_1k_2+k_1k_2k_3+…+k_1…*k_n. $